

一种非自回归的预训练方法
描述
概览
市面上的标题党往往会采用夸张的文字,例如:ChatGPT被淘汰,AutoGPT来袭。但是对于行业内的人来说,这种标题很明显是标题党。这两个模型都是基于GPT-3或者GPT-4的技术,它们在技术上本质上没有太大的区别。
虽然GPT模型在自然语言处理领域中表现出色,但是它们仍然存在一些问题。例如,GPT模型的自回归设计导致它在生成新单词或短语时需要等待整个序列生成完成,这样的过程显然会减缓生成速度。
由于这些问题,一些研究人员开始探索非自回归模型的设计,这种方法可以提高生成速度。
但非自回归模型的输出结果可能会出现不连贯的情况,这种情况需要更多的研究和解决方案。
总之,非自回归模型是一种很有前途的技术,可以成为未来颠覆GPT的重要技术之一。虽然这些方法仍然需要更多的研究和开发,但是应该持续关注它们的发展。
三种文本生成方式
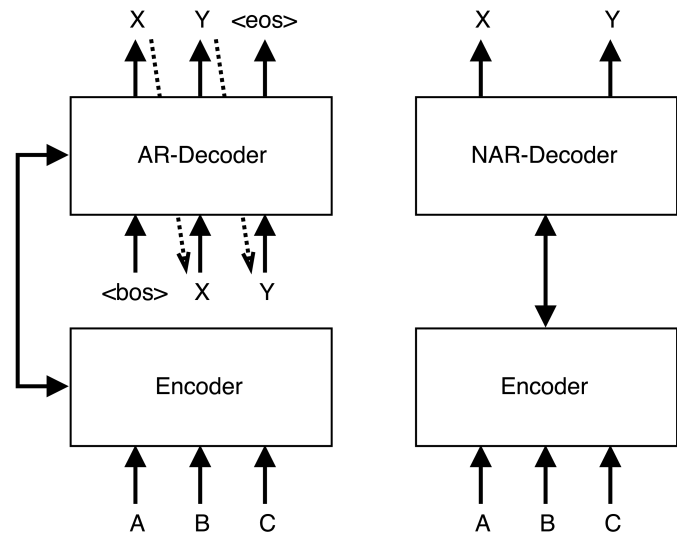
自回归(AR)
生成模型基于从左到右的输出文本,其中每个标记yt是基于输入文本X和前面的标记y
非自回归(NAR)
与AR模型相比,文本生成模型同时预测输出文本中的每个标记,而不对前向或后向标记依赖进行建模。其中每个标记yt仅根据输入文本X进行预测。独立性假设使NAR生成过程可并行化,从而显著加快了推理速度。然而,在没有token依赖的情况下,NAR模型的生成质量低于AR模型。
半自回归(Semi-NAR)
半NAR生成在AR和NAR生成之间形式化,其中每个标记yt以输入文本X和输出文本Y的可见部分Yct为条件。
本文主要关注NAR方法,并同时考虑文本生成模型的有效性和效率。
一种非自回归的预训练方法
本文介绍的方法ELMER是基于Transformer编码器-解码器架构构建的。解码器和编码器都由多个堆叠组成,每个层包含多个子层(例如,多头自注意力和前馈网络)。与原始Transformer解码器自回归生成文本不同,模型使用NAR方式同时生成标记。给定一对输入-输出文本〈X,Y〉,X被馈送到编码器中并被处理为隐藏状态S = 〈s1,...,sn〉。然后将一系列“[MASK]”标记序列馈送到NAR解码器中以并行生成输出文本Y中的每个标记。
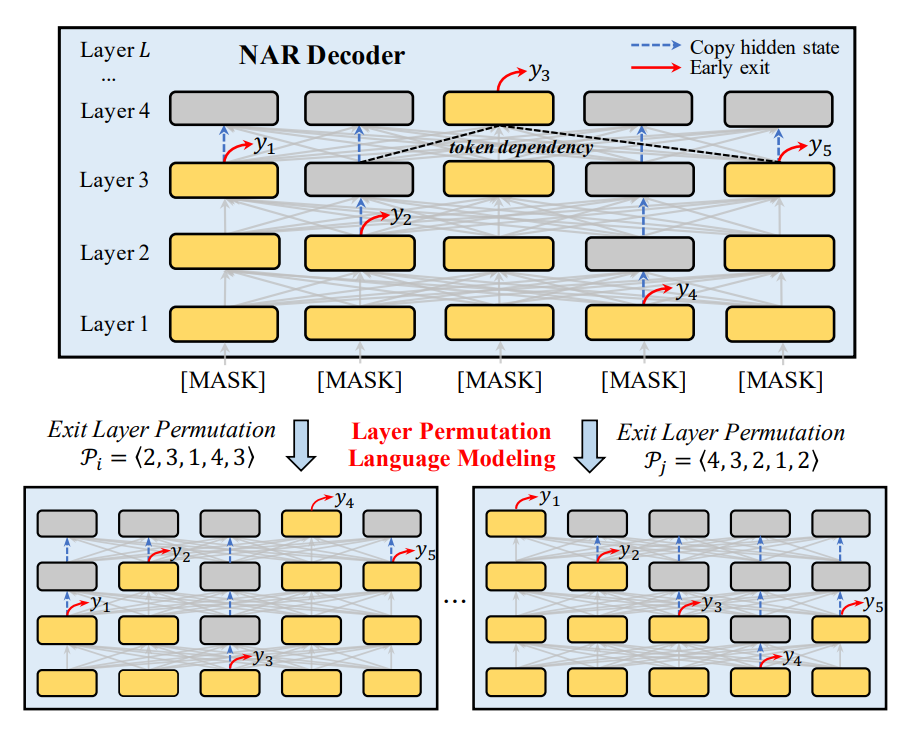
提前退出机制
通常情况下,大多数NAR模型只在最后一层同时预测token,因此,token预测不知道其他位置生成的token。为了解决这个问题,ELMER在不同层生成token。上层token的生成可以依赖于从左侧和右侧生成的下层token。通过这种方式,模型可以明确地学习来自不同层标记之间的依赖关系,并且在NAR解码中享受完全的并行性,如上图所示。如果在较低层生成token时有足够的置信度,则允许模型在该层退出并进行预测,而不经过上层。
层排列预训练
与大多数先前工作专注于为特定任务(如翻译)设计小规模NAR模型不同,ELMER使用大规模语料库对通用大规模PLM进行预训练。这使得ELMER能够适应各种下游任务。
首先将损坏的文本输入编码器,然后使用上述LPLM以NAR方式由解码器重建原始文本来训练模型。主要采用两种有用的文档损坏方法:
洗牌:首先将原文按照句号分成句子,然后对这些句子进行随机洗牌。
文本填充:基于打乱的文本,从泊松分布(λ = 3)中抽取长度的15%跨度进行采样。在BART之后,每个span都被替换为单个“[MASK]” token,模型可以学习应该预测一个span中的多少个token。
下游微调
预训练模型可用于微调各种下游文本生成任务。在微调阶段,可以使用小规模和特定任务的数据集,精确估计每个token的输出层。在这里主要考虑两种提前停止方式,即硬提前停止和软提前停止。
硬提前退出是最直接的方法,它通过计算每个标记的预测置信度,并设置一个阈值来决定是否提前退出。如果某个标记的预测置信度低于阈值,则不会进行提前退出。
软提前退出则是一种更加灵活的方法,它允许模型在生成文本时动态地调整每个标记的预测置信度阈值。具体来说,在软提前退出中,模型会根据当前已经生成的文本内容和上下文信息来动态地调整每个标记的预测置信度阈值。这种方法可以使得模型更加灵活地适应不同的文本生成任务,并且可以在不同任务之间共享已经学习到的知识。
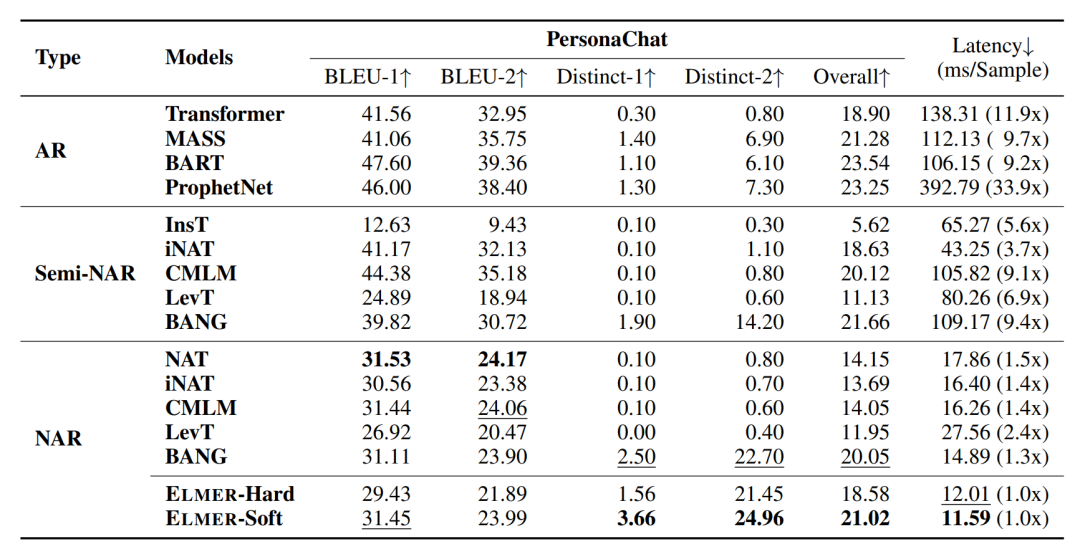
比较
虽然效果上还完全比不上自回归,但一旦这个方向成熟,从效率上会彻底颠覆现在的GPT系列模型。
引用
https://arxiv.org/pdf/2210.13304.pdf
审核编辑 :李倩
-
ai大模型训练方法有哪些?2024-07-16 5607
-
谷歌模型训练软件有哪些功能和作用2024-02-29 1769
-
混合专家模型 (MoE)核心组件和训练方法介绍2024-01-13 3508
-
基于生成模型的预训练方法2023-08-11 2484
-
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?2023-07-24 1624
-
ELMER: 高效强大的非自回归预训练文本生成模型2023-03-13 2644
-
优化神经网络训练方法有哪些?2022-09-06 1781
-
现代交互技术下的儿童语言表达训练方法2021-06-27 850
-
一种侧重于学习情感特征的预训练方法2021-04-13 1237
-
检索增强型语言表征模型预训练2020-09-27 2833
-
微软在ICML 2019上提出了一个全新的通用预训练方法MASS2019-05-11 4318
-
研究人员提出一种基于哈希的二值网络训练方法 比当前方法的精度提高了3%2018-02-08 5993
-
一种新的记忆多项式预失真器2009-08-08 4426
全部0条评论

快来发表一下你的评论吧 !
