

 深入理解Cortex-M内存管理(Keil)
深入理解Cortex-M内存管理(Keil)
描述
在讨论Cortex-M的内存之前,先来看看Cortex-M的存储器系统,我们知道,Cortex-M系列的处理器,大都可以对32的存储器进行寻址,因此存储器的寻址空间能够达到4G,这就意味着指定和数据共用相同的地址空间,也就是将程序存储器、数据存储器、寄存器和输入输出端口被组织在同一个4GB的线性地址空间内。数据字节以小端格式存放在存储器中。一个字里的最低地址字节被认为是该字的最低有效字节,而最高地址字节是最高有效字节。
1 Cortex-M存储器架构
4G的地址空间就是地址编码的范围。所谓编码就是对每一个程序存储器、数据存储器、寄存器和输入输出端口(一个字节)分配一个唯一的地址号码,这个过程又叫做“编址”或者“地址映射”。这个过程就好像在日常生活中我们给每家每户分配一个地址门牌号。与编码相对应的是“寻址”过程——分配一个地址号码给一个存储单元的目的是为了便于找到它,完成数据的读写,这就是“寻址”,因此地址空间有时候又被称作“寻址空间”。
有了4G的可寻址空间,我们就可通过寻址来操作相应的地址对象。这就需要将程序存储器、数据存储器、寄存器和输入输出端口进行统一编号,也就是存储器映射。
存储器映射是指把芯片中或芯片外的FLASH,RAM,外设,BOOTBLOCK等进行统一编址。即用地址来表示对象。这个地址绝大多数是由厂家规定好的,用户只能用而不能改。用户只能在挂外部RAM或FLASH的情况下可进行自定义。
如下图,是Cortex-M3存储器映射结构图。
Cortex-M3是32位的内核,因此其PC指针可以指向2^32=4G的地址空间,也就是0x0000_0000——0xFFFF_FFFF这一大块空间。根据图中描述,Cortex-M3内核将0x0000_0000——0xFFFF_FFFF这块4G大小的空间分成8大块:代码、SRAM、外设、外部RAM、外部设备、专用外设总线-内部、专用外设总线-外部、特定厂商等,因此使用该内核的设计者必须按照这个进行各自芯片的存储器结构设计。
首先,我们对比一下Cortex-M3存储器结构和STM32存储器结构:
图中可以很清晰的看到,STM32的存储器结构和Cortex-M3的很相似,不同的是,STM32加入了很多实际的东西,如:Flash、SRAM等。只有加入了这些东西,才能成为一个拥有实际意义的、可以工作的处理芯片——STM32。
STM32的存储器地址空间被划分为大小相等的8块区域,每块区域大小为512MB。
| 地址范围 | 描述 |
|---|---|
| 0x0000 0000 ~0x2000 0000 | 根据启动引脚的状态决定哪个存储空间被映射到此处。 片内系统存储区起始地址:0x1fff0000(2K字节的空间) |
| 0x2000 0000 ~0x4000 0000 | SRAM区,64K,其中位带别名区首地址为:0x2200 0000 |
| 0x4000 0000 ~0x6000 0000 | 用于片内外设,外设寄存器的别名区首地址:0x4200 0000 |
| 0x6000 0000 ~0x8000 0000 | |
| 0x8000 0000 ~0xa000 0000 | 片上flash存储区512M |
| 0xa000 0000 ~0xc000 0000 | |
| 0xc000 0000 ~0xe000 0000 | |
| 0xe000 0000 ~0xffff ffff |
对STM32存储器知识的掌握,实际上就是对Flash和SRAM这两个区域知识的掌握。由STM32的系统结构可以看出,Flash和SRAM这两个区域分别由ICode总线和DCode总线与处理器通信,以此完成相应的数据交换。
当然啦,其他Cortex-M的处理和STM32的也是类似的,比如GD32、CH32等。
下面将重点描述Flash和SRAM的知识。
1.2 Cortex-M的SRAM
RAM随机存储器(Random Access Memory)表示既可以从中读取数据,也可以写入数据。当机器电源关闭时,存于其中的数据就会丢失。比如电脑的内存条。
RAM有两大类,一种称为静态RAM(Static RAM/SRAM),SRAM速度非常快,是目前读写最快的存储设备了,但是它也非常昂贵,所以只在要求很苛刻的地方使用,譬如CPU的一级缓冲,二级缓冲。另一种称为动态RAM(Dynamic RAM/DRAM),DRAM保留数据的时间很短,速度也比SRAM慢,不过它还是比任何的ROM都要快,但从价格上来说DRAM相比SRAM要便宜很多,计算机内存就是DRAM的。
DRAM分为很多种,常见的主要有FPRAM/FastPage、EDORAM、SDRAM、DDR RAM、RDRAM、SGRAM以及WRAM等,这里介绍其中的一种DDR RAM。
DDR RAM(Date-Rate RAM)也称作DDR SDRAM,这种改进型的RAM和SDRAM是基本一样的,不同之处在于它可以在一个时钟读写两次数据,这样就使得数据传输速度加倍了。这是目前电脑中用得最多的内存,而且它有着成本优势,事实上击败了Intel的另外一种内存标准-Rambus DRAM。在很多高端的显卡上,也配备了高速DDR RAM来提高带宽,这可以大幅度提高3D加速卡的像素渲染能力。
为什么需要RAM,因为相对FlASH而言,RAM的速度快很多,所有数据在FLASH里面读取太慢了,为了加快速度,就把一些需要和CPU交换的数据读到RAM里来执行。
STM32单片机内部的 RAM 为 SRAM。不同类型的Cortex-M单片机的SRAM大小是不一样的,但起始地址都是0x2000 0000,终止地址都是0x2000 0000+其固定的容量大小。SRAM相对容量小,速度快,掉电数据丢失,其作用是用来存取各种动态的输入输出数据、中间计算结果以及与外部存储器交换的数据和暂存数据。设备断电后,SRAM中存储的数据就会丢失。
1.3 Cortex-M的Flash
Cortex-M的Flash,严格说,应该是Flash模块。该Flash模块包括: Flash主存储区(Main memory)、Flash信息区(Information block),以及Flash存储接口寄存器区(Flash memory interface) 。三个组成部分分别在0x0000 0000——0xFFFF FFFF不同的区域。下面介绍STM32的Flash,如下表所示。
STM32的闪存模块由:__主存储器、信息块和闪存储器块__3部分组成。
主存储器 ,该部分用来存放代码和数据常数(如加const类型的数据)。对于大容量产品,其被划分为256页,每页2K,注意,小容量和中容量产品则每页只有1K字节。主存储起的起始地址为0X08000000,B0、B1都接GND的时候,就从0X08000000开始运行代码。
信息块 ,该部分分为2个部分,其中启动程序代码,是用来存储ST自带的启动程序,用于串口下载,当B0接3.3V,B1接GND时,运行的就这部分代码,用户选择字节,则一般用于配置保护等功能。
闪存储器块 ,该部分用于控制闪存储器读取等,是整个闪存储器的控制机构。
对于主存储器和信息块的写入有内嵌的闪存编程管理;编程与擦除的高压由内部产生。
在执行闪存写操作时,任何对闪存的读操作都会锁定总线,在写完成后才能正确进行,在进行读取或擦除操作时,不能进行代码或者数据的读取操作。
2 C程序内存分析
在C/C++程序中,编译的程序占用内存分为5个区,分别为__栈区、堆区、全局/静态存储区、常量存储区、代码区__。
1.Text段(Code Segment/Text Segment,代码段) :通常是指用来存放程序执行代码的一块内存区域,也就是存放CPU执行的机器指令(machine instructions)。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
2.全局初始化数据区/静态数据区(Initialized data segment/Data segment) :该区包含了在程序中明确被初始化的全局变量、静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。数据段属于静态内存分配。static声明的变量放在data段。
3.BSS段(Block Started by Symbol) :BSS段通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS段属于静态内存分配。
4.堆(heap) :堆是用于存放程序运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。也就是常说的用malloc,calloc, realloc 等函数分配的变量空间是在堆上。当程序调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
5.栈(stack) :栈又称堆栈,是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出(FIFO)特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
一个程序本质上都是由 __bss段、data段、text段__三个组成的。
在C/C++程序编译完成之后,已初始化的全局变量保存在data 段中,未初始化的全局变量保存在bss 段中。
text和data段都在可执行文件中(在嵌入式系统里一般是固化在镜像文件中),由系统从可执行文件中加载;而bss段不在可执行文件中,由系统初始化。
3 STM32程序的存储分配
3.1 程序所占RAM和Flash大小分析
为例调试方便,这里使用一个裸机串口例子,关于串口的使用请参看笔者博文:
串口通信:https://bruceou.blog.csdn.net/article/details/79341769
使用Keil编译代码,编译信息如下:
其中:
- Code 代表执行的代码,程序中所有的函数都位于此处。即上述的text段。
- RO-data (Read Only)代表只读数据,程序中所定义的全局常量数据和字符串都位于此处,如const型。
- RW-data (Read Write) 代表已初始化的读写数据,程序中定义并且初始化的全局变量和静态变量位于此处。
- ZI-data (Zero Initialize) 代表未初始化的读写数据,程序中定义了但没有初始化的全局变量和静态变量位于此处。Keil编译器默认是把你没有初始化的变量都赋值为例0。即上述的bss段。
值得注意的是,这些参数的单位是Byte。
Code和RO-Data两个段统称为RO段,它们和RW段,需要烧录到FLASH等非易失性器件中。
RW段需要烧录到FLASH中,而ZI段则不用,但在运行时,它们都必须装载到可读可写的RAM中。
因此我们可以计算出FLASH和RAM的大小:
Flash = Code + RO Data + RW Data
RAM = RW-data + ZI-data
这就要涉及到程序的两种状态:加载域和运行域。
加载域 :向Flash中下载程序时,其实仅仅下载的是CODE+RO-data+RW-data的内容,意思就是说,在掉电情况下,Flash里面的内存仅包含CODE+RO-data+RW-data这三块。
运行域 :当上电后,程序运行时,首先程序会从特定的地址进行启动,启动时会将RW-data的数据加载到SRAM中,单片机的 RO区域不需要加载到 SRAM,内核直接从 FLASH 读取指令运行。那ZI-data的数据怎么办呢?对于初始值为0全局变量来说,因为要在Code区要调用该全局变量,所以肯定要对其进行描述,程序运行时就知道了,原来你是初始值为0的全局变量呀,然后就在SRAM区给你分配了一段固定区域的地址;对于局部变量来说,会自动分配大小。ZI-data有统计作用,并且SRAM中一段特定的区域是运行ZI-data数据,RW-DATA+ZI-DATA就是程序运行总共会占用SRAM的长度,生成局部变量的栈空间包含在ZI-data区的范围。
3.2 MAP 文件剖析
程序后成功编译后,通过编译信息可以查看程序空间分配情况,而map文件更加详细的描述了程序编译信息。
map文件是程序的全局符号、源文件和代码行号信息的唯一的文本表示方法,它可以在任何地方、任何时候使用,不需要有额外的程序进行支持。
在MDK5中,在项目中双击Target就能自动打开.map文件。
3.2.1 Section Cross References
该部分主要是不同文件中函数的调用关系。
这个以main.c中的main()函数为例,调用了stm32f1_bsp_led.c中的BSP_LED_Init()函数,其他函数也都列出来了。
3.2.2 Removing Unused input sections
MDK优化会删除的冗余的函数。
以stm32f10x_gpio.c文件为例,很多函数没有用到,因此这里就会时删除冗余的函数,减少代码空间。
当然啦,这部分和编译器相关,不一定会删除,这里想要最大可能删除冗余函数,需要都选相应的选项,如下图所示。
在 Removing Unused input sections from the image 的最后会列出删除的冗余函数的大小,如果在MDK上改变上图所示的配置,下图中的删除总代码会有变化。
3.2.3 Image Symbol Table
Symbol Table会有两个部分:Local Symbols和Global Symbols。
Local Symbols
该部分是Static声明的全局变量以及C文件中函数的地址和static声明的函数。
Global Symbols
该部分是全局变量以及C文件中函数。
3.2.4 Memory Map of the image
映像文件可以分为加载域(Load Region)和运行域(Execution Region):加载域反映了ARM可执行映像文件各个段存放在存储器中时的位置关系。关于加载域和运行域前文已经介绍过了。
这部分为两块,一部分是Flash的,另外一部分是RAM的。
Flash中存放的是text段,代码段不用加载到RAM中执行,程序在运行时MCU会直接从Flash中读取指令。
第842行:Flash加载域的基本信息,这里size表示Code + RO Data + RW Data的大小,也就是文件后面ROM Size。
第844行:Flash运行域的基本信息,这里size表示Code + RO Data的大小,也就是文件后面RO Size。运行域的大小比加载域少了RW Data部分,这部分会在运行时候加载到RAM中。
另外还可以看到Flash的大小时512 Kb。
RAM中存放的是data段和bss段,该部分是需要从Flash中加载进来。
这里只有运行域,这里的size包含RW Data + ZI Data,也就是RW Size,RAM的大小是64 Kb。该部分的最后两行就是堆栈大小。
3.2.5 Image component sizes
这部分就是各个文件中各个数据段的大小。
在xxx.map文件的最后也会有不同数据段的信息统计。
3.3 程序堆栈使用分析
我们知道,程序运行需要占用的大小是RAM = RW-data + ZI-data,而堆栈的大小是程序开始运行后才能确定的,堆栈的内存占用就是在上面RAM分配给RW-data + ZI-data之后的地址开始分配的。
那么堆和栈到底能占用多大呢,堆栈的大小是在startup_stm32fxxx.s中设置的,这里以STM32F103ZET6为例进行分析,其内部栈的大小为1KB,堆的大小为0.5KB。
startup_stm32fxxx.s文件是系统的启动文件,主要包括堆和栈的初始化配置、中断向量表的配置以及将程序引导到main( )函数等。
startup_stm32fxxx.s主要完成三个工作:栈和堆的初始化、定位中断向量表、调用Reset Handler。
避免产生这类错误的产生,程序设计时就应该考虑变量大小和堆栈大小是否合适。一个是减少过大的临时变量和动态申请内存,另一个是在SRAM空间允许的情况下增大堆栈大小,如上图中栈大小是1024字节,堆大小是512字节。
我们知道,堆栈的设置是在startup_stm32fxxx.s中设置的,但是startup_stm32fxxx.s文件是只读的,无法修改,只需要设置一下该文件的属性,把只读取消即可修改。
另外,FLASH和SRAM起始地址在Options中可以查看:
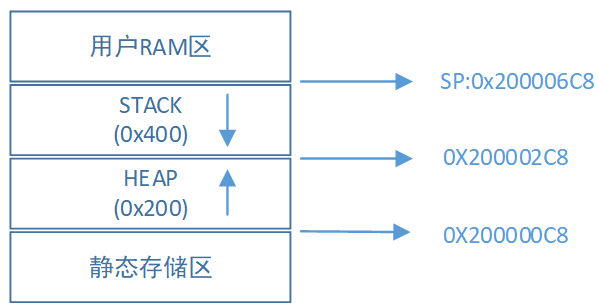
还是在xxx.mp中,我们可以看到SRAM的分配,如下图所示。
从上图中可以看出SRAM空间用来存放:
1.各个文件中声明和定义的全局变量、静态数据和常量;
2.未初始化的全局变量;
3.HEAP区;
4.STACK区。
堆在使用时会从低地址往上加,而栈是从__initial_sp开始往下减。以上图中的堆栈地址为例,malloc会从0x200000C8开始往上加,局部变量的分配会从0x200002C8开始往下减。如果入栈元素过大,使得入栈元素的地址访问到了0x2000068C之后的内容,就发生了栈溢出,首先会改变堆中的元素值,如果入栈元素够大,可能会直接改变HEAP后面的全局变量。同理,当动态申请的内存过大时,堆中变量越界到栈中,此时就发送堆溢出。
【注】栈:向低地址扩展,堆:向高地址扩展。如果依次定义变量,先定义的栈变量的内存地址比后定义的栈变量的内存地址要大,先定义的堆变量的内存地址比后定义的堆变量的内存地址要小。
当然啦,如果使用J-link调试程序,也能查看堆栈大小,栈顶指针就是使用SRAM的大小。
【Tips】
1、堆栈的大小在编译器编译之后是不知道的,只有运行的时候才知道,所以需要注意一点,就是别造成堆栈溢出了,不然就会发生hardfault错误。
2、所有在处理的函数,包括函数嵌套,递归,等等,都是从这个“栈”里面,来分配的。所以,如果栈大小为2K,一个函数的局部变量过多,比如在函数里面定义一个char buf[512],这一下就占了1/4的栈大小了,再在其他函数里面来搞两下,程序崩溃是很容易的事情,这时候,一般你会进入到hardfault…。
3、STM32的栈,是向下生长的。事实上,一般CPU的栈增长方向,都是向下的。而堆的生长方向,都是向上的。堆和栈,只是他们各自的起始地址和增长方向不同,他们没有一个固定的界限,所以一旦堆栈冲突,系统就到了崩溃的时候了。
4、程序中的常量,如果没加const也会编译到SRAM里,加了const会被编译到flash中。
3.4 实例代码分析
前面分析了那么多,下面通过一个实例来验证前面的分析。
main.c函数代码如下:
/* Includes ------------------------------------------------------------------*/
#include "stm32f1_bsp_usart.h"
#include "stm32f1_bsp_led.h"
#include "stm32f1_bsp_systick.h"
/* Private typedef -----------------------------------------------------------*/
/* Private define ------------------------------------------------------------*/
/* Private macro -------------------------------------------------------------*/
/* Private variables ---------------------------------------------------------*/
uint8_t buffer[10];//声明了一个初始化为0的全局数组
uint8_t data = 1;//初始化的全局变量
/* Private function prototypes -----------------------------------------------*/
/* Private functions ---------------------------------------------------------*/
/**
* @brief mian
* @param None
* @retval int
*/
int main(void)
{
ST_BSP_LED_Dev BSP_LED_Dev0 = LED_DEV0_CONFIG;
ST_BSP_LED_Dev BSP_LED_Dev1 = LED_DEV1_CONFIG;
ST_BSP_LED_Dev BSP_LED_Dev2 = LED_DEV2_CONFIG;
ST_BSP_USART_Dev BSP_USART_Dev0 = USART_DEV0_CONFIG;
uint8_t stack_i; //未初始化的局部变量,
uint8_t stack_j = 1; //初始化的局部变量
uint8_t *pHeap1 = (uint8_t *)malloc(10);//指针pHeap指向堆区分配了一个uint8_t类型10大小的空间
uint8_t *pHeap2 = (uint8_t *)malloc(10);
/* Configure the NVIC Preemption Priority Bits */
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);
/*Systick init*/
SysTick_Init();
/*LED init*/
BSP_LED_Init(&BSP_LED_Dev0);
BSP_LED_Init(&BSP_LED_Dev1);
BSP_LED_Init(&BSP_LED_Dev2);
/* USART1 配置模式为 115200 8-N-1,中断接收 */
BSP_USART_Init(&BSP_USART_Dev0, 115200, 0, 1);
printf("未初始化的全局变量 buffer 的首地址:0x%p\\r\\n", buffer);
printf("初始化的全局变量 data 的地址:0x%p\\r\\n", &data);
printf("未初始化的局部变量 stack_i 的地址:0x%p\\r\\n", &stack_i);
printf("初始化的局部变量 stack_j 的地址:0x%p\\r\\n", &stack_j);
printf("pHeap1 在堆区首地址:0x%p\\r\\n", pHeap1);
printf("pHeap2 在堆区首地址:0x%p\\r\\n", pHeap2);
free(pHeap1);
free(pHeap2);
while(1)
{
BSP_LED_Toggle(&BSP_LED_Dev0);
Delay_ms(500);
BSP_LED_Toggle(&BSP_LED_Dev1);
Delay_ms(500);
BSP_LED_Toggle(&BSP_LED_Dev2);
Delay_ms(500);
}
}
编译后map文件中内存分配如下:
运行程序,打印信息如下:
data是初始化的全局变量,在.data区;buffer是未初始化的全局变量,在.bss区;pHeap是通过malloc分配的空间,在堆区,逐渐增加;局部变量都在栈区,增加减小。
4 堆栈的使用总结
堆的使用:
1、堆的使用是要结合malloc函数,即使用一次malloc所得到的内存空间既是属于堆的空间。
2、堆的增长方向是向上,所以malloc申请的地址也是越来越大的,前提是连续申请且在最后一次申请后再释放内存(free)。则第一次申请的地址永远小于后面申请的地址。
3、堆是不连续的,由于RAM中还存在局部变量,代码段和栈等等,所以动态分配的内存是取暂时空闲的内存,而不是预先划出一块区域,这就是动态分配内存的好处。
4、使用堆的坏处,由于使用malloc申请内存时,不单只申请了所需的大小空间,还要额外暂用管理这部分空间的内存,而释放时又只释放申请的内存,所以使用堆会引入内存碎片。当然如果不是在短时间内频繁的使用malloc申请和free释放内存,那么操作系统就有足够的时间来回收碎片空间。
栈的使用:
1、由编译器分配,目的是将RAM划分处一块区域供程序运行时的局部变量参数等使用;
2、栈是一块连续的内存空间,由上往下增长,即使用栈时地址是会越来越小的,如先声明的局部变量比后声明的地址要高;
3、栈是由程序(操作系统)自动分配,不会有内存碎片的问题;
4、栈的坏处:栈是固定且连续的一个大小,如果使用局部变量等超出了栈的大小则会造成内存溢出,而编译器通常是发现不了的,只有当程序运行到那个函数时才会发生的。这就会引入很难查找的bug。另外如如果使用malloc申请的内存不规范使用,当释放内存后,没将指针地址清空,仍指向那个地址刚好是栈的地址,则会造成越界访问。
-
Cortex-M产品的特色2025-11-26 195
-
如何使用Ozone分析Cortex-M异常2024-11-29 2930
-
深入理解Cortex-M内存管理(GCC)2023-04-27 4700
-
ARM Cortex-M之KEIL MDK调试技术简介2022-05-07 6884
-
为什么要深入理解栈2022-02-15 1081
-
一点理解之 CmBacktrace: ARM Cortex-M 系列 MCU 错误追踪库2021-11-30 802
-
深入理解STM322021-08-12 1572
-
Cortex-M内核的MPU内存保护单元2020-03-04 4915
-
深入理解C指针(C/C++程序员进阶必备,透彻理解指针与内存管理)pdf2018-03-21 2714
-
《深入理解LINUX内存管理》学习笔记2016-11-07 3431
-
深入理解Linux虚拟内存管理_爱尔兰/戈尔曼著2015-02-09 332
-
深入理解和实现RTOS_连载2014-05-29 5948
-
深入理解Android2012-08-20 3320
全部0条评论

快来发表一下你的评论吧 !
