

从Cache验证参考模型对比来谈复杂度权衡
描述
一直以来对MTK北京团队做的关于Cache一致性验证的方案有深刻印象,2019年当时的一篇论文“An Enhanced Stimulus and Checking Mechanism on Cache Verification”(接下来该论文简称PP-MESH)采用的是MESH预测的方法,对cache的数据做好准确预测和检查。
2022年的时候我们V3课程中的联发科学员,还跟着我们一同回顾了这篇论文中涉及到的一些技术,给当时正在做cache一致性验证的其他同学提供了思路。我们以往做的各个方向的技术分享和论文回顾,都有保存在V3课程视频中。
这次我们要谈的论文DVCon 2022 “CAMEL: A Flexible Cache Model for Cache Verification”(接下来该论文简称PP-CAMEL),其背景正是基于PP-MESH做的更新,我们也可以借此以了解对于一个复杂设计而言,如何考虑规划其参考模型,在实际项目中有哪些需要权衡的地方。
总体而言,在验证L1 cache system (L1SYS)的过程中,L1SYS的机构被拆分为多个模块,包括shadow command buffer, store buffer, sram, line filling buffer, evinction buffer, prefetch buffer,而根据不同thread访问数据时的cache hit/miss的情况和数据经过L1SYS各个模块的流向,又将L1SYS的不同数据读写行为定义为了各种情况(例如in-order, out-of-order, with-losses, any-in-order, either-in-order, MISO, with-redundancy等)。这种数据从点到点的流向,就构成了DVCon 2019的这篇论文中数据检查思想的框架,即根据每一个data stream的不同特征,分别对input stream, output stream做数据流向的标注。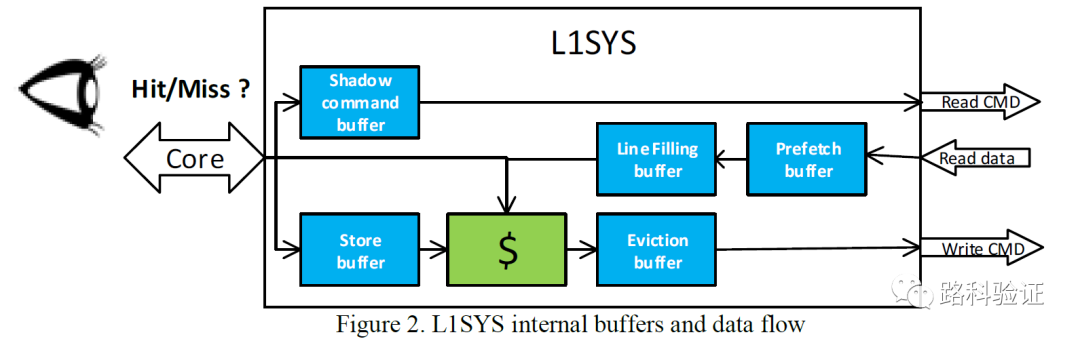
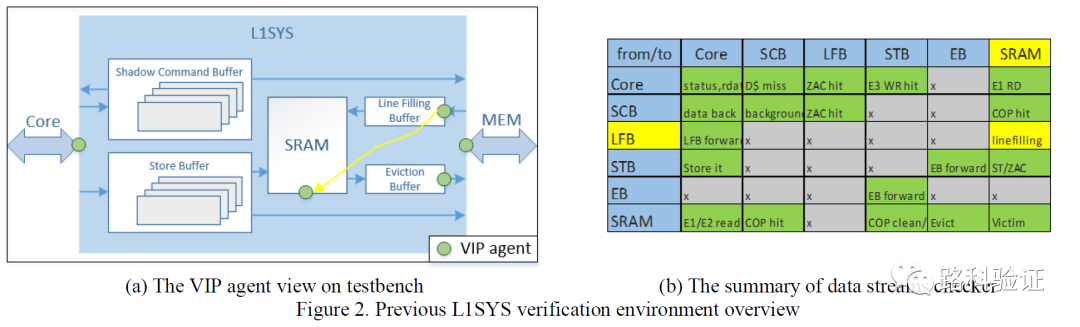
由于这种精细规划和预测的方式,MESH检查可以做到周期级的准确(cycle-accurate),从下面这个图也可以看到,L1SYS模型中的每一部分(STB/EB/LFB/PB/SRAM等)都需要监测L1SYS设计外部和内部数据,从PP-CAMEL的回顾来看,MESH方案需要连接5个VIP monitor,而且从VIP monitor监测到的数据需要根据需要组合为stream,再按照MESH表格对这些stream进行独立的处理和检查。
PP-CAMEL对以前的这部分工作评价是,尽管可以做到cycle-accurate的细致检查,但带来的一个烦恼是由于MESH方案需要与设计行为深度耦合,而且对验证人员提出较高的维护要求,如果设计发生变化,那么MESH方案作为一个整体都将需要花费较大人力去更新MESH验证环境。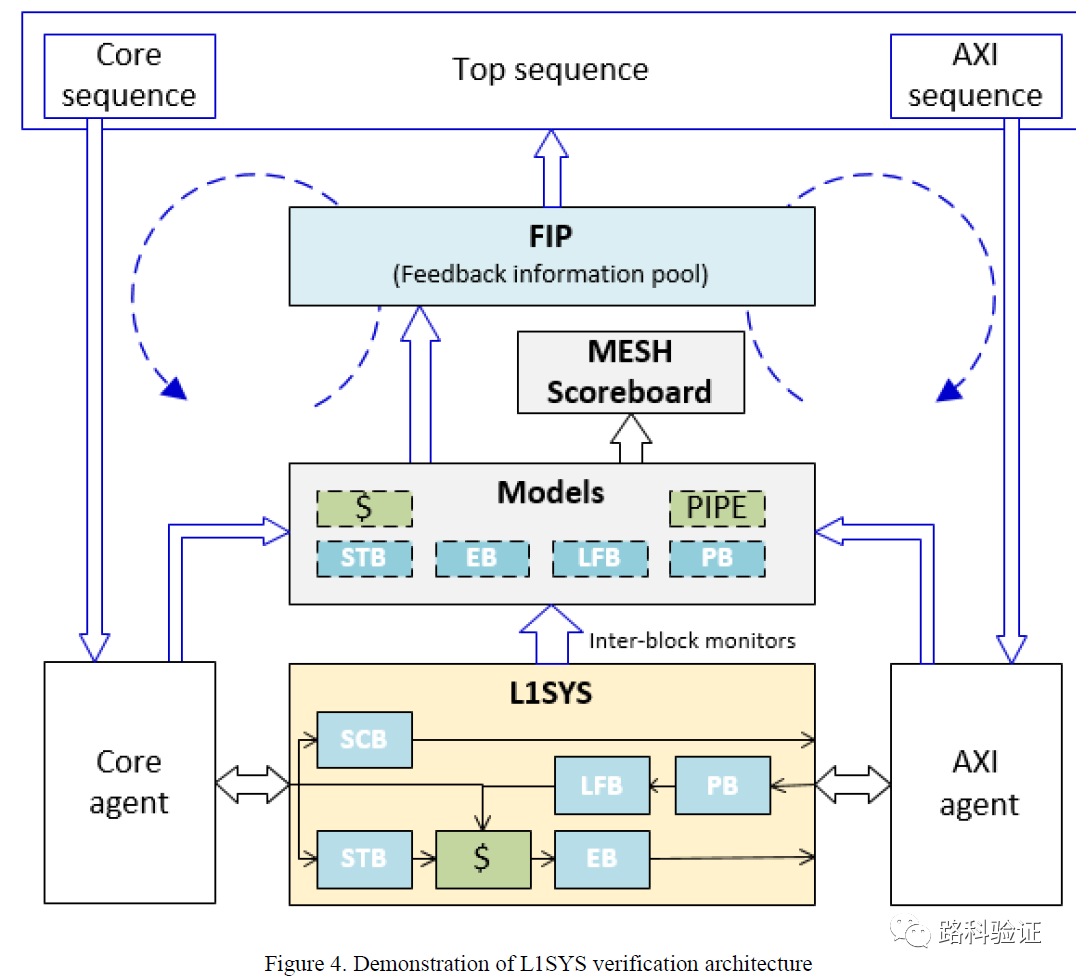
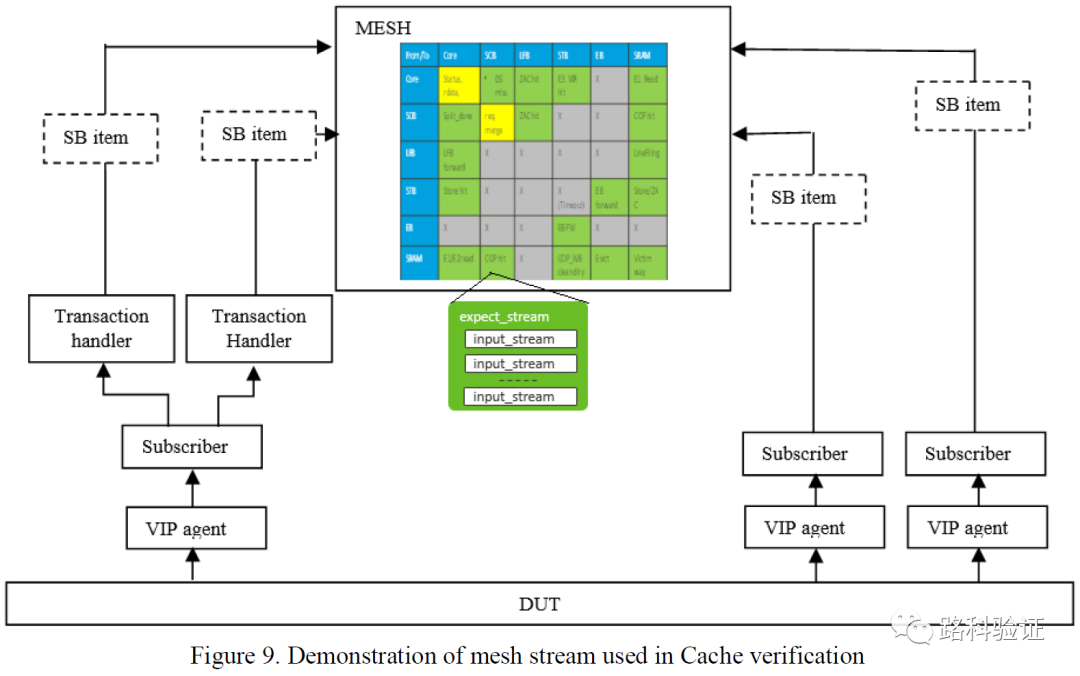
上面来自PP-CAMEL的评价便于理解,这就像如果我们把设计的模型做成一个big synthesized model,那么设计的每一处更新都会使得让我们去维护这个大模型,而大模型越来越大、复杂、乃至趋于臃肿的情况下,设计可能打补丁式的修改,也可能会让参考模型去做类似的补丁式修改。
理想情况下,如果维护这个模型的人是同一个人(大公司里这种情况较多)那么还好一些,但是如果一旦人员发生变动,模型当时设定的好坏、代码结构是否合理、模型是否方便维护这些问题就随之而来了。 从PP-CAMEL最后的代码对比来看,也能证实这个问题,CAMEL模型的代码量大概只有MESH模型的1/3。
但这并不是简单说明,CAMEL既轻量化,又能完成MESH模型可以做的cycle-accurate的细致检查。熊掌与鱼难以兼得,CAMEL模型是在将功能检查做了分层、分类以后,才将MESH模型原来可以一股脑完成的事情解耦合成CAMEL模型和其它模型,并且CAMEL模型能做的事情,也是分为了多种任务的。
一句话,那就是CAMEL模型做了检查任务的规划,没有一来就试图去构建一个大而全的模型,而是一开始就打算将验证分成了多个步骤,逐一将从基础功能到高级功能再到边界情况的检查分为了多个任务去实现的。
那么,PP-CAMEL为什么不采用PP-MESH中的大模型呢?难道是不需要做准确预测了吗?其实从论文一开始的背景阐述来看,即他们开始在做多核多线程的架构(RISC-V)。这意味他们尽管可以参考原来PP-MESH中的L1SYS设计,但同时要适配多核ACE协议和snoop memory 请求(对于L1SYS而言属于新的外部请求/响应)。
我能猜想到的是,当时也应该是考虑过MESH方案复用的,但这意味着需要理解原有的方案,而且要修改MESH中的代码。如果是同一位工程师修改维护他原来的方案,那么思路大概还能跟得上拍子,但如果是不同的工程师打算要做这件事情,那么他还会考虑另外一种可能,就是在原有MESH思路的基础上,做一些检查的优化。
值得注意的是,PP-CAMEL论文中提到了PP-MESH原本在数据激励方面的layer层次规划清晰、各个方法接口也很丰富,这些有关激励部分思想和接口仍然可以复用下来。
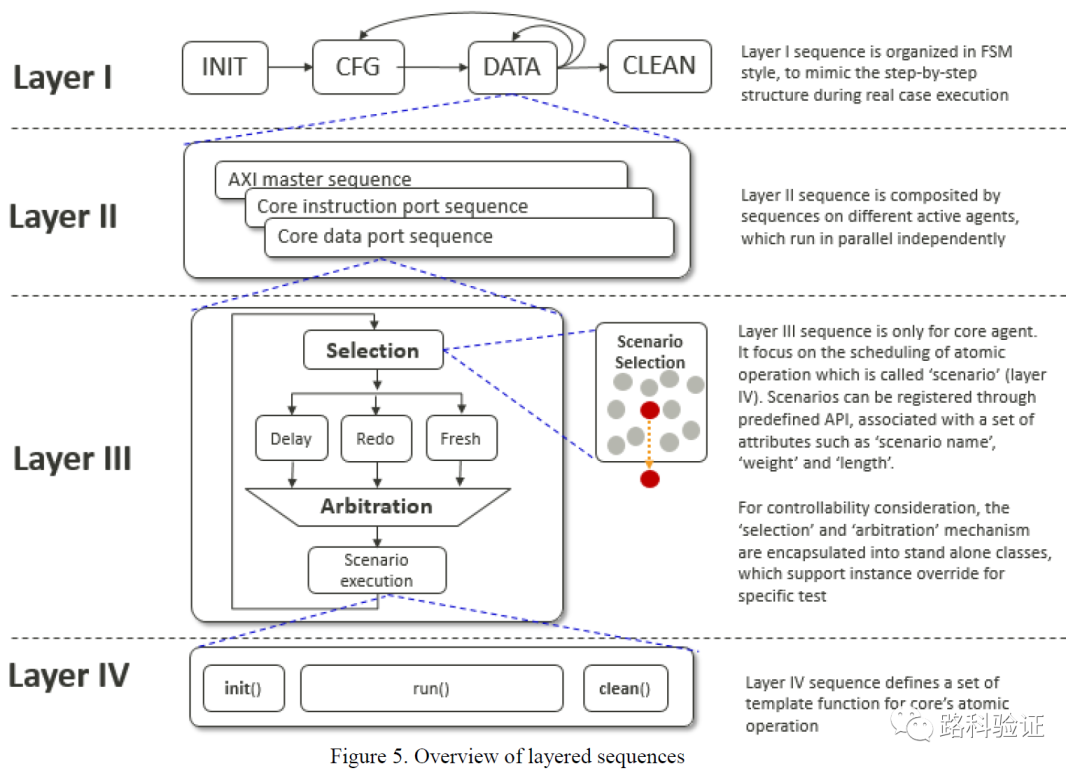
所以可能更符合当时实际情况的是,已经经历过PP-MESH“高精度”模型带来验证环境与设计高度绑定以后的晃动带来的痛苦之后,PP-CAMEL决定采取一个“循序渐进”的方案,即它的初衷是构建一个更为快速能够对新的L1SYS设计进行检查的验证环境(如果能够复用以前的一些激励、测试序列那就更好)。
所以它一开始并没有求全,而是把检查的重心放在数据完整性上面,即data correctness check。这一点跟我们常规的数据流检查类似,比如DMA数据搬迁或者数据打包解包操作等功能检查,都是先完成数据完整性检查,再去就设计的行为、时序做更为细致的检查。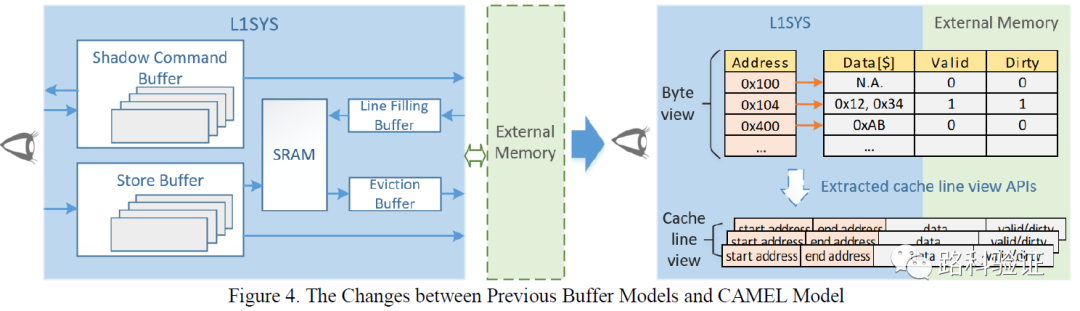

它的模型中的数据存放是较为模糊的,因为它不会准确预测数据,而是会存放所有可能从目标地址读出去的数据(stores all possible values of the same address),这种方式仍然可以在设计早期阶段帮助验证做数据(模糊)检查。它的优点在于更快部署、不依赖于具体的设计、时序,与设计可以解耦。
如果检查方案里有配置按钮(configuration knob),那么这种检查方式可以给起个名字(rough level check)。 接下来PP-CAMEL也提到了,如果要进一步做到准确的数据预测检查,那么就需要获得额外的信息,比如对cache hit/miss check和rationality read/write command to external memory(对外部存储读写请求的合理性检查,关系到cache hit/miss的预测和模型准确度)。
那么就需要添加诸如location/SCB data/SRAM data这样的属性。而这些属性又当来自于各个VIP monitor。当从monitor获得的信息越多,那么CAMEL模型也将越复杂,而用于做data correctness check, hit/miss check, rationality check of request to external memory等也将越准确。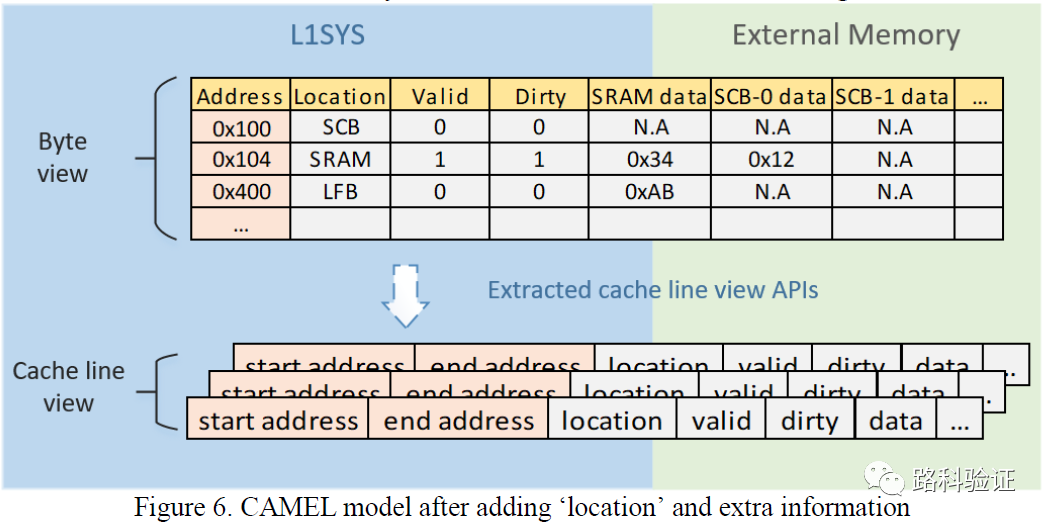
这个道理我们似乎都懂,但是PP-CAMEL恰恰给出了与原有PP-MESH不同的验证环境实现步骤,下面这段话我认为是整篇论文中要着重表达的验证工程思想。我们能够理解,一个simple testbench不可能做到precise check,但我们能不能理解如果要设计一个complex testbench,是否有能力让它做到simple check,或者做到different precision of check?对于MESH模型,PP-CAMEL给出的回顾似乎在说维护这样一个大模型很耗神,尤其在PP-CAMEL背景中遇到一个新的L1SYS设计的时候,需要修改的内容恐怕很多,尤其是面对8000+行的MESH模型。
将模型先从简单做起,有的时候也是一种妥协。这种妥协可能是来自于项目的压力,可能是来自于对复杂设计逻辑和时序,也可能是为了将来以后便于维护。PP-CAMEL的模型核心是围绕着地址和数据的,它本身不复杂,而在此基础之上添加了一些必要的属性,即能够创造出条件做不同精确度的检查。最终,检查精度还会落回到模型复杂性上。
只不过,从trade-off来看,PP-CAMEL提出的思路,使得在验证L1SYS过程中,得以找到一条从简单到复杂的路,使得可以对L1SYS的各个功能逐一做从基础到复杂的检查。另外,在PP-CAMEL中可以看到,与PP-MESH的验证思路联系紧密,尽管模型的实现方式发生了较大变化,但激励层次的组织和复用、以及原有的各个API的复用仍然带来了帮助。
这种有历史衔接的论文前后研究起来也很有收获,而这两篇论文也可以启发我们在实现参考模型时,究竟是按照大模型来实现,还是按照分层(由易到难)模型来实现,需要考虑诸多工程因素。
审核编辑:刘清
-
业务复杂度治理方法论--十年系统设计经验总结2024-09-05 2170
-
PCB与PCBA工艺复杂度的量化评估与应用初探!2024-06-14 11639
-
如何计算时间复杂度2023-10-13 5239
-
算法时空复杂度分析实用指南12023-04-12 1303
-
常见机器学习算法的计算复杂度2022-10-02 1310
-
算法之空间复杂度2022-08-31 2723
-
如何求递归算法的时间复杂度2022-07-13 2443
-
深度剖析时间复杂度2022-03-18 2850
-
时间复杂度是指什么2021-07-22 1926
-
JEM软件复杂度的增加情况2019-07-19 2125
-
一种基于贝叶斯网络的随机测试方法在Cache一致性验证中的设计与实现2017-11-17 1082
-
图像复杂度对信息隐藏性能影响分析2017-11-14 1110
-
基于RNS的低复杂度DDS的设计与实现_张凤君2017-01-08 779
-
基于纹理复杂度的快速帧内预测算法2010-05-06 3772
全部0条评论

快来发表一下你的评论吧 !
