

AI大语言模型的原理、演进及算力测算专题报告
电子说
描述
核心观点:
机器学习中模型及数据规模增加有利于提高深度神经网络性能。人工智能致力于研究能够模拟、延伸和扩展人类智能的理论方法及技术,并开发相关应用系统;其最终目标是使计算机能够模拟人的思维方 式和行为。机器学习是一门专门研究计算机如何模拟或实现人类的学习行为、以获取新的知识或技能、重新组织已有的知识结构使之不断改 善自身性能的学科,广泛应用于数据挖掘、计算机视觉、自然语言处理等领域。深度学习是机器学习的子集,主要由人工神经网络组成。与 传统算法及中小型神经网络相比,大规模的神经网络及海量的数据支撑将有效提高深度神经网络的表现性能。
Transformer模型架构是现代大语言模型所采用的基础架构。Transformer模型是一种非串行的神经网络架构,最初被用于执行基于上下文的机器翻译任务。Transformer模型以Encoder-Decoder架构为基 础,能够并行处理整个文本序列,同时引入“注意机制”(Attention),使其能够在文本序列中正向和反向地跟踪单词之间的关系,适合在 大规模分布式集群中进行训练,因此具有能够并行运算、关注上下文信息、表达能力强等优势。
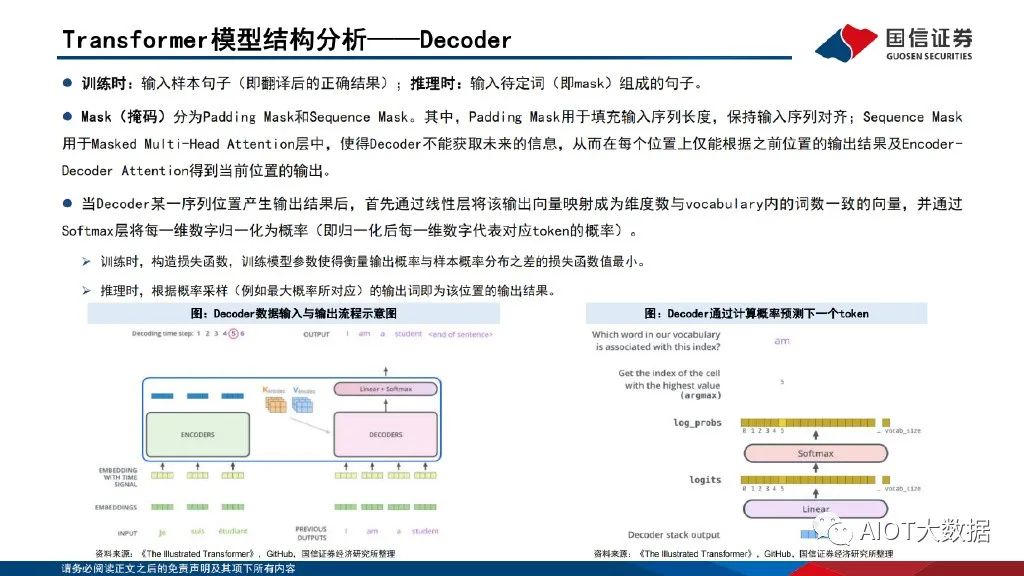
Transformer模型以词嵌入向量叠加位置编码 作为输入,使得输入序列具有位置上的关联信息。编码器(Encoder)由Self-Attention(自注意力层)和 Feed Forward Network(前馈网 络)两个子层组成,Attention使得模型不仅关注当前位置的词语,同时能够关注上下文的词语。解码器(Decoder)通过Encoder-Decoder Attention层,用于解码时对于输入端编码信息的关注;利用掩码(Mask)机制,对序列中每一位置根据之前位置的输出结果循环解码得到当 前位置的输出结果。
GPT是基于Transformer架构的大语言模型,近年迭代演进迅速。构建语言模型是自然语言处理中最基本和最重要的任务之一。GPT是基于Transformer架构衍生出的生成式预训练的单向语言模型,通过对大 量语料数据进行无监督学习,从而实现文本生成的目的;在结构上仅采用Transformer架构的Decoder部分。自2018年6月OpenAI发布GPT-1模 型以来,GPT模型迭代演进迅速。GPT-1核心思想是采用“预训练+微调”的半监督学习方法,服务于单序列文本的生成式任务;GPT-2在预训 练阶段引入多任务学习机制,将多样化的自然语言处理任务全部转化为语言模型问题;GPT-3大幅增加了模型参数,更能有效利用上下文信息, 性能得到跨越式提高;GPT-3.5引入人类反馈强化学习机制,通过使用人类反馈的数据集进行监督学习,能够使得模型输出与人类意图一致。
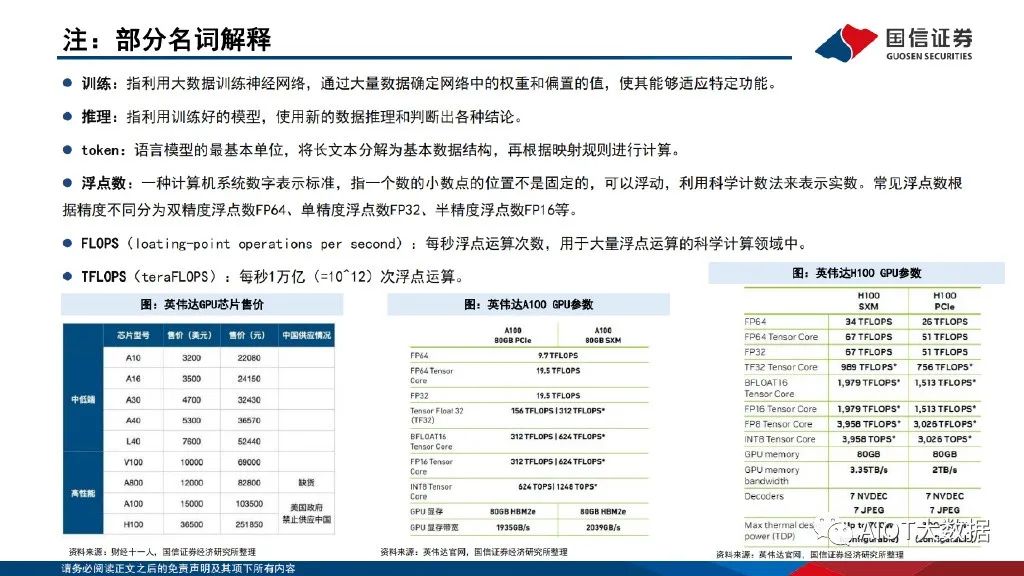
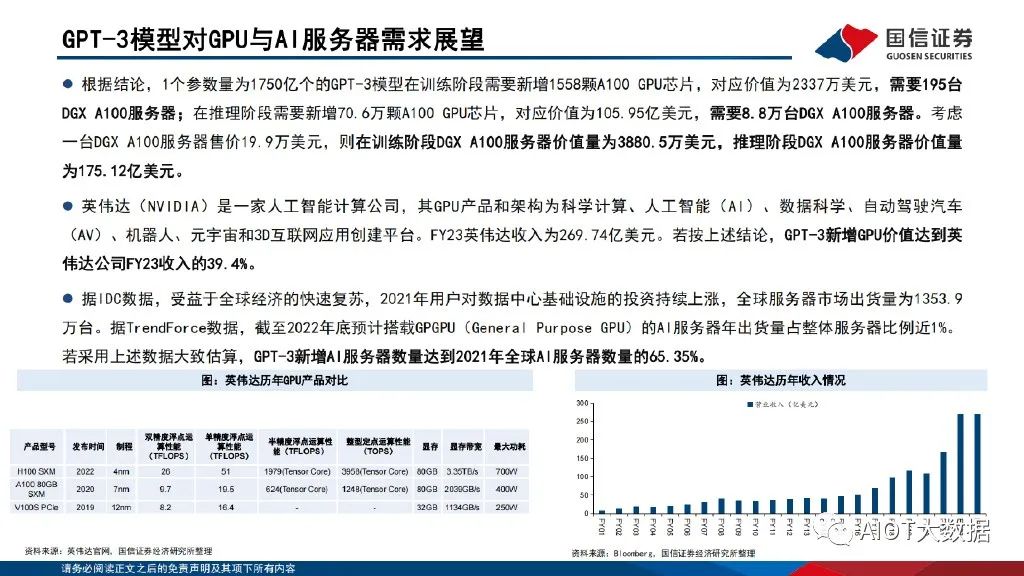
大语言模型的训练及推理应用对算力需求带来急剧提升。以GPT-3为例,GPT-3参数量达1750亿个,训练样本token数达3000亿个。考虑采用精度为32位的单精度浮点数数据来训练模型及进行谷歌级访 问量推理,假设GPT-3模型每次训练时间要求在30天完成,对应GPT-3所需运算次数为3.15*10^23FLOPs,所需算力为121.528PFLOPS,以A100 PCle芯片为例,训练阶段需要新增A100 GPU芯片1558颗,价值量约2337万美元;对应DGX A100服务器195台,价值量约3880.5万美元。假设推 理阶段按谷歌每日搜索量35亿次进行估计,则每日GPT-3需推理token数达7.9万亿个,所需运算次数为4.76*10^24FLOPs,所需算力为 55EFLOPs,则推理阶段需要新增A100 GPU芯片70.6万颗,价值量约105.95亿美元;对应DGX A100服务器8.8万台,价值量约175.12亿美元。
01、人工智能、机器学习与神经网络简介
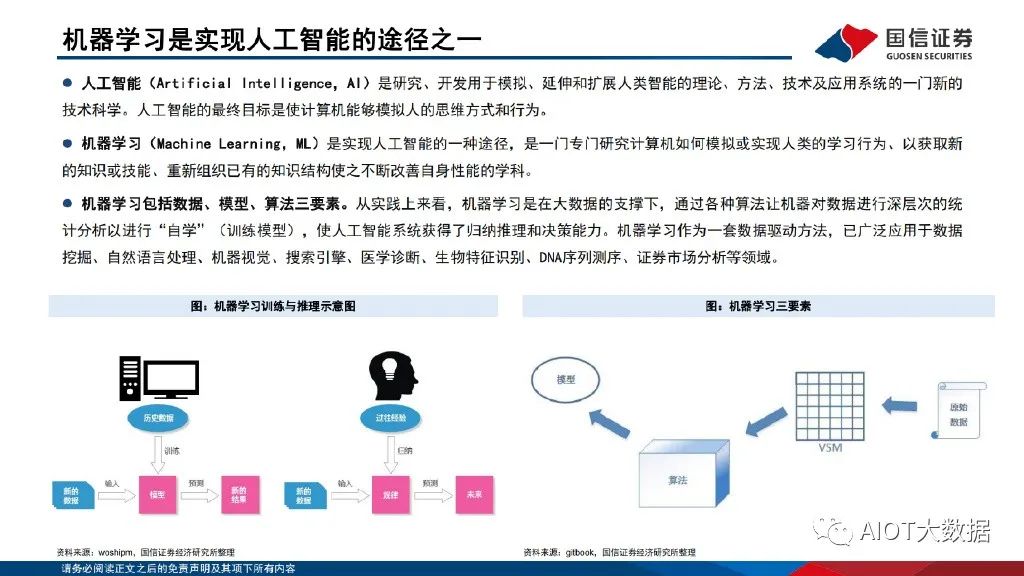
机器学习是实现人工智能的途径之一
人工智能(Artificial Intelligence,AI)是研究、开发用于模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的一门新的 技术科学。人工智能的最终目标是使计算机能够模拟人的思维方式和行为。机器学习(Machine Learning,ML)是实现人工智能的一种途径,是一门专门研究计算机如何模拟或实现人类的学习行为、以获取新 的知识或技能、重新组织已有的知识结构使之不断改善自身性能的学科。机器学习包括数据、模型、算法三要素。从实践上来看,机器学习是在大数据的支撑下,通过各种算法让机器对数据进行深层次的统 计分析以进行“自学”(训练模型),使人工智能系统获得了归纳推理和决策能力。机器学习作为一套数据驱动方法,已广泛应用于数据 挖掘、自然语言处理、机器视觉、搜索引擎、医学诊断、生物特征识别、DNA序列测序、证券市场分析等领域。
模型及数据规模增加有利于提高深度神经网络性能
深度学习(Deep Learning,DL)是机器学习的子集,由人工神经网络(ANN)组成。深度学习模仿人脑中存在的相似结构, 其学习是通过相互关联的“神经元”的深层的、多层的“网络”来进行的。典型的神经网络从结构上可以分为三层:输入层、隐藏层、输出层。其中,输入层(input layer)是指输入特征向量;隐藏 层(hidden layer)是指抽象的非线性中间层;输出层(output layer)是指输出预测值。深层神经网络即包含更多隐藏层的神 经网络。相比于传统机器学习模型,深度学习神经网络更能在海量数据上发挥作用。若希望获得更好的性能,不仅需要训练一个规模 足够大的神经网络(即带有许多隐藏层的神经网络,及许多参数及相关性),同时也需要海量的数据支撑。数据的规模及神经网 络的计算性能,需要有强大的算力作为支撑。
CNN和RNN是常见的神经网络模型
传统常见的神经网络模型包括卷积神经网络(CNN)和循环神经网络(RNN)等。其中,卷积神经网络(Convolutional Neural Network, CNN)多用于计算机视觉、自动驾驶、人脸识别、虚拟现实、医学领域、人机交互、智能安防等图像应用;相比于标准神经网络,CNN能够 更好地适应高纬度的输入数据,卷积设计有效减少了模型的参数数量。循环神经网络(Recurrent Neural Network,RNN)常用于处理序列数据,获取数据中的时间依赖 性。由于语言都是逐个出现的,同时语言是时序前后相互关联的数据,因此语言作为最自然表达出来的 序列数据,适合应用RNN进行语音识别、情感分类、机器翻译、语言生成、命名实体识别等应用。
循环神经网络(RNN)曾是自然语言处理的首选解决方案。RNN能够在处理单词序列时,将处理第一个词的结果反馈到处理下一个词的层, 使得模型能够跟踪整个句子而非单个单词。但RNN存在缺点:由于这种串行结构,RNN无法对于长序列文本进行有效处理,甚至可能当初始 单词过远时“遗忘”相关信息。
02、Transformer模型结构分析
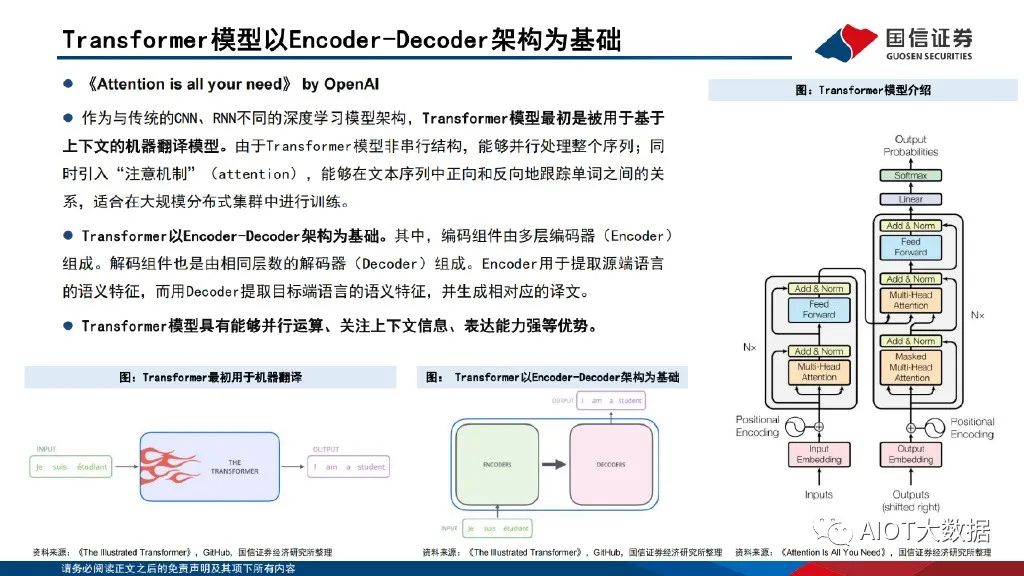
Transformer模型以Encoder-Decoder架构为基础
《Attention is all your need》 by OpenAI 。作为与传统的CNN、RNN不同的深度学习模型架构,Transformer模型最初是被用于基于 上下文的机器翻译模型。由于Transformer模型非串行结构,能够并行处理整个序列;同 时引入“注意机制”(attention),能够在文本序列中正向和反向地跟踪单词之间的关 系,适合在大规模分布式集群中进行训练。Transformer以Encoder-Decoder架构为基础。其中,编码组件由多层编码器(Encoder) 组成。解码组件也是由相同层数的解码器(Decoder)组成。Encoder用于提取源端语言 的语义特征,而用Decoder提取目标端语言的语义特征,并生成相对应的译文。Transformer模型具有能够并行运算、关注上下文信息、表达能力强等优势。
Transformer模型结构分析——词嵌入(Embedding)
词嵌入是NLP最基础的概念之一,表示来自词汇表的单词或者短语被映射成实数向量。最早的词嵌入模型是word2vec等神经网络模型, 属于静态词嵌入(不关注上下文)。例如大模型诞生前常用的RNN模型所用的输入便是预训练好的词嵌入。词向量能够将语义信息与空间 向量关联起来(例如经典的词类比例子:king、queen、man、woman对应词向量的关系)。词嵌入产生要素及步骤:Vocabulary:所有的token组成集合。词向量表:token与词向量的一一对应关系。词向量可以由预训练产生,也可以是模型参数。查表:输入的token都对应一个固定维度的浮点数向量(词嵌入向量)。位置编码:表示序列中词的顺序,具体方法为为每个输入的词添加一个位置向量。根据位置编码对应计算公式,pos表示位置,i表示维度。位置编码能够让模型学习到token之间的相对位置关系。
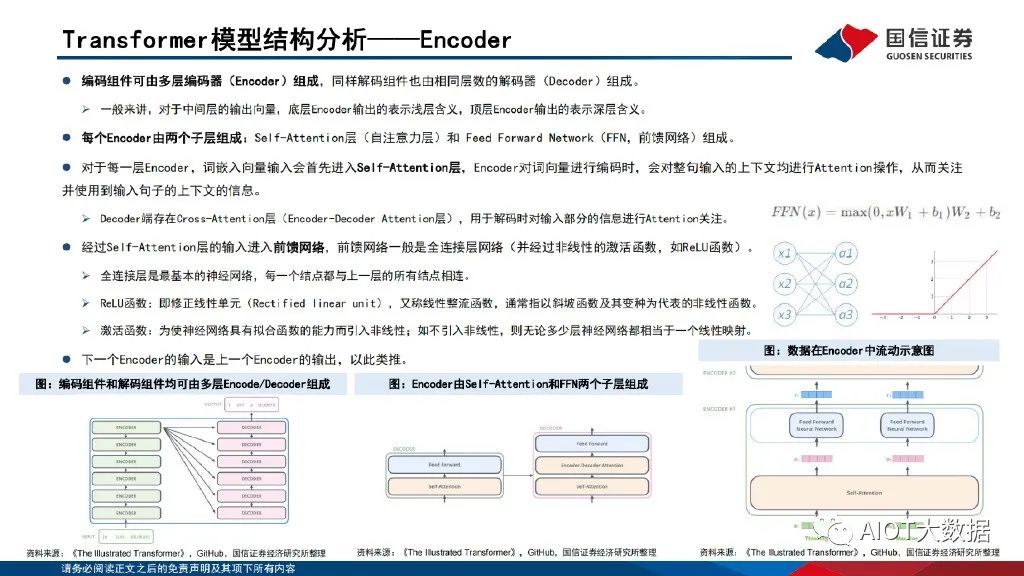
Transformer模型结构分析——Encoder
编码组件可由多层编码器(Encoder)组成,同样解码组件也由相同层数的解码器(Decoder)组成。一般来讲,对于中间层的输出向量,底层Encoder输出的表示浅层含义,顶层Encoder输出的表示深层含义。每个Encoder由两个子层组成:Self-Attention层(自注意力层)和 Feed Forward Network(FFN,前馈网络)组成。对于每一层Encoder,词嵌入向量输入会首先进入Self-Attention层,Encoder对词向量进行编码时,会对整句输入的上下文均进行Attention操作,从而关注 并使用到输入句子的上下文的信息。Decoder端存在Cross-Attention层(Encoder-Decoder Attention层),用于解码时对输入部分的信息进行Attention关注。
经过Self-Attention层的输入进入前馈网络,前馈网络一般是全连接层网络(并经过非线性的激活函数,如ReLU函数)。全连接层是最基本的神经网络,每一个结点都与上一层的所有结点相连。ReLU函数:即修正线性单元(Rectified linear unit),又称线性整流函数,通常指以斜坡函数及其变种为代表的非线性函数。激活函数:为使神经网络具有拟合函数的能力而引入非线性;如不引入非线性,则无论多少层神经网络都相当于一个线性映射。下一个Encoder的输入是上一个Encoder的输出,以此类推。
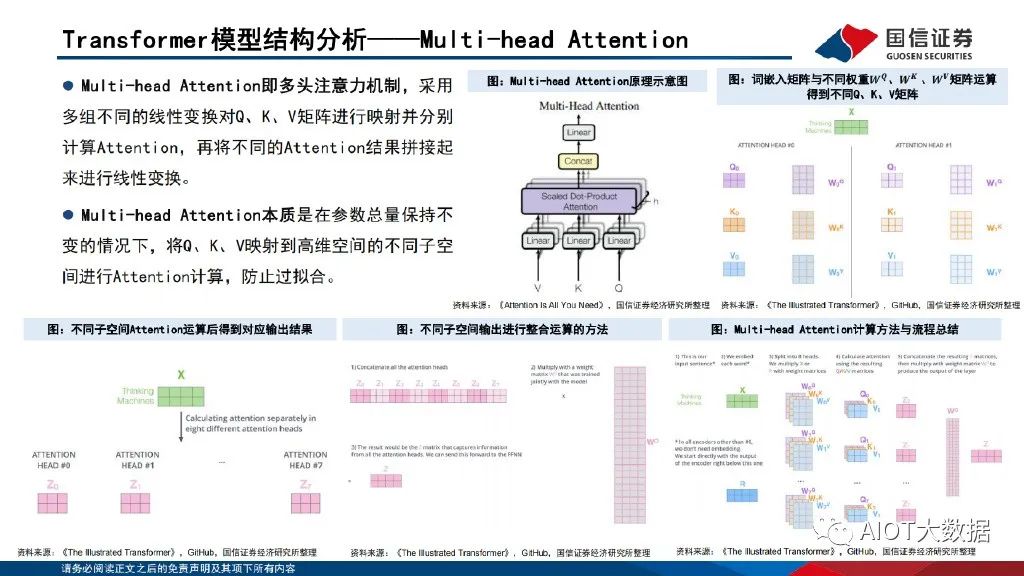
Transformer模型结构分析——Multi-head Attention
Multi-head Attention即多头注意力机制,采用 多组不同的线性变换对Q、K、V矩阵进行映射并分别 计算Attention,再将不同的Attention结果拼接起 来进行线性变换。Multi-head Attention本质是在参数总量保持不 变的情况下,将Q、K、V映射到高维空间的不同子空 间进行Attention计算,防止过拟合。
03、大规模语言模型算力需求测算(以GPT-3为例)
BERT和GPT是基于Transformer架构的两种大规模语言模型
构建语言模型(Language Model,LM)是自然语言处理(Natural Language Processing,NLP)中最基本和最 重要的任务之一,自然语言处理基于Transformer架构衍生出了两种主流大语言模型(Large Language Model, LLM)——BERT和GPT。二者都是无监督预训练的大语言模型。BERT(Bidirectional Encoder Representations from Transformer)能够生成深度双向语言表征,是采用带 有掩码(mask)的大语言模型,类似于完形填空,根据上下文预测空缺处的词语。结构上,BERT仅采用Transformer 架构的Encoder部分。
GPT(Generative Pre-training Transformer)是生成式预训练的单向语言模型。通过对大量语料数据进行无 监督学习,从而实现文本生成的目的。结构上,GPT仅采用Transformer架构的Decoder部分。自2018年6月起OpenAI发布GPT-1模型以来,GPT更新换代持续提升模型及参数规模。随着OpenAI于2022年11月30 日发布ChatGPT引爆AI领域,海内外科技公司纷纷宣布发布大语言模型。用户爆发式增长对大语言模型的算力需求带 来挑战。
GPT-1:预训练+微调的半监督学习模型
《Improving Language Understanding by Generative Pre-Training》 by OpenAI。GPT-1是生成式预训练模型,核心思想是“预训练+微调”的半监督学习方法,目标是服务于单序列文本的生成式任务。生成式:表示模型建模的是一段句子出现的概率,可以分解为基于语言序列前序已出现单词条件下后一单词出现的条件概率之乘积。四大常见应用:分类、蕴含、相似、选择,分类:每段文本具有对应标号,将文本按标 号进行分类 ,蕴含:给出一段文本和假设,判断该段文本 中是否蕴含该假设,相似:判断两段文本是否相似(用于搜索、 查询、去重等) ,选择:对有多个选项的问题进行回答。
GPT-2:强调多任务的预训练模型
《Language Models are Unsupervised Multitask Learners》 by OpenAI,预训练+微调的范式只能对于特定自然语言处理任务(例如问答、机器翻译、阅读理解、提取摘要等)使用特定的数据集 进行有监督学习,单一领域数据集缺乏对多种任务训练的普适性。GPT-2在预训练阶段便引入多任务学习机制,通过加入各种NLP 任务所需要的数据集,在尽可能多的领域和上下文中收集属于对 应任务的自然语言。由此得到的GPT-2模型可以以zero-shot的方 式被直接应用于下游任务,而无需进行有监督的精调。GPT-2将多样化的的NLP任务全部转化为语言模型问题。语言提 供了一种灵活的方式来将任务,输入和输出全部指定为一段文本。对文本的生成式建模就是对特定任务进行有监督学习。
GPT-3:能够举一反三的大语言模型
《Language Models are Few-Shot Learners》 by OpenAI。相比GPT-2,GPT-3大幅增加了模型参数。GPT-3是具有1750亿个参数的自回归语言模型,更能有效利用上下文 信息。对于特定的下游任务,GPT-3无需进行任何梯度更新或微调,仅需通过与模型交互并提供少量范例即可。特点:1、模型规模急剧增加(使得模型性能提升迅猛);2、实现few-shot learning。in-context learning:对模型进行引导,使其明白应输出什么内容。Q:你喜欢吃苹果吗?A1:我喜欢吃。A2:苹果是什么?A3:今天天气真好。A4:Do you like eating apples? 采用prompt提示语:汉译英:你喜欢吃苹果吗?请回答:你喜欢吃苹果吗?
GPT-3模型对GPU与AI服务器需求展望
根据结论,1个参数量为1750亿个的GPT-3模型在训练阶段需要新增1558颗A100 GPU芯片,对应价值为2337万美元,需要195台 DGX A100服务器;在推理阶段需要新增70.6万颗A100 GPU芯片,对应价值为105.95亿美元,需要8.8万台DGX A100服务器。考虑 一台DGX A100服务器售价19.9万美元,则在训练阶段DGX A100服务器价值量为3880.5万美元,推理阶段DGX A100服务器价值量 为175.12亿美元。英伟达(Nvidia)是一家人工智能计算公司,其GPU产品和架构为科学计算、人工智能(AI)、数据科学、自动驾驶汽车 (AV)、机器人、元宇宙和3D互联网应用创建平台。FY23英伟达收入为269.74亿美元。若按上述结论,GPT-3新增GPU价值达到英 伟达公司FY23收入的39.4%。
据IDC数据,受益于全球经济的快速复苏,2021年用户对数据中心基础设施的投资持续上涨,全球服务器市场出货量为1353.9 万台。据TrendForce数据,截至2022年底预计搭载GPGPU(General Purpose GPU)的AI服务器年出货量占整体服务器比例近1%。若采用上述数据大致估算,GPT-3新增AI服务器数量达到2021年全球AI服务器数量的65.35%。
报告节选:
















审核编辑 :李倩
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 771
-
什么是AI算力模组?2025-09-19 1033
-
积算科技上线赤兔推理引擎服务,创新解锁FP8大模型算力2025-07-30 1045
-
AI 算力报告来了!2025中国AI算力市场将达 259 亿美元2025-03-07 2675
-
开启全新AI时代 智能嵌入式系统快速发展——“第六届国产嵌入式操作系统技术与产业发展论坛”圆满结束2024-08-30 3922
-
大模型时代的算力需求2024-08-20 1112
-
央媒关注 |《“东数西算”发力》专题报道:算力兴黔2023-06-08 1733
-
央媒关注 |《“东数西算”发力》专题报道:算力商机2023-06-06 2089
-
音乐分离AI模型研发成功,浪潮信息以AI算力服务助力2023-04-25 1951
-
2021年功率半导体专题报告.zip2023-01-13 575
全部0条评论

快来发表一下你的评论吧 !
