

502问题怎么排查?
电子说
描述
刚工作那会,有一次,上游调用我服务的老哥说,你的服务报"502错误了,快去看看是为什么吧"。
当时那个服务里正好有个调用日志,平时会记录各种200,4xx状态码的信息。于是我跑到服务日志里去搜索了一下502这个数字,毫无发现。于是跟老哥说,"服务日志里并没有502的记录,你是不是搞错啦?"
现在想来,多少有些不好意思。
不知道有多少老哥是跟当时的我是一样的,这篇文章,就来聊聊502错误是什么?
我们从状态码是什么开始聊起。
HTTP状态码
我们平时在浏览器里逛的某宝和某度,其实都是一个个前端网页。
一般来说,前端并不存储太多数据,大部分时候都需要从后端服务器那获取数据。
于是前后端之间需要通过TCP协议去建立连接,然后在TCP的基础上传输数据。
而TCP是基于数据流的协议,传输数据时,并不会为每个消息加入数据边界,直接使用裸的TCP进行数据传输会有"粘包"问题。
因此需要用特地的协议格式去对数据进行解析。于是在此基础上设计了HTTP协议。详细的内容可以看我之前写的《既然有HTTP协议,为什么还要有RPC》。
比如,我想要看某个商品的具体信息,其实就是前端发的HTTP请求中传入商品的id,后端返回的HTTP响应中返回商品的价格,商店名,发货地址的信息等。
通过id获取商品详情
这样,表面上,我们是在刷着各种网页,实际上背后正有多次HTTP消息在不断进行收发。

用户在网上浏览商品
但问题就来了,上面提到的都是正常情况,如果有异常情况呢,比如前端发的数据,根本就不是个商品id,而是一张图片,这对于后端服务端来说是不可能给出正常响应的,于是就需要设计一套HTTP状态码,用来标识这次HTTP请求响应流程是否正常。通过这个可以影响浏览器的行为。
比方说一切正常,那服务端返回个200状态码,前端收到后,可以放心使用响应的数据。但如果服务端发现客户端发的东西异常,就响应个4xx状态码,意思是这是个客户端的错误,4xx里头的xx可以根据错误的类型,再细分成各种码,比如401是客户端没权限,404是客户端请求了一个根本不存在的网页。反过来,如果是服务器有问题,就返回5xx状态码。

4xx和5xx的区别
但问题就来了。
服务端都有问题了,搞严重点,服务器可能直接就崩溃了,那它还怎么给你返回状态码?
是的,这种情况,服务端是不可能给客户端返回状态码的。所以说,一般情况下5xx的状态码其实并不是服务器返回给客户端的。
它们是由网关返回的,常见的网关,比如nginx。
nginx的作用
回到前后端交互数据的话题上,如果前端用户少,那后端处理起请求来,游刃有余。但随着用户越来越多,后端服务器受资源限制,cpu或者内存都可能会严重不足,这时候解决方案也很简单,多搞几台一样的服务器,这样就能将这些前端请求均摊给几个服务器,从而提升处理能力。
但要实现这样的效果,前端就得知道后端具体有哪些个服务器,并一一跟他们建立TCP连接。
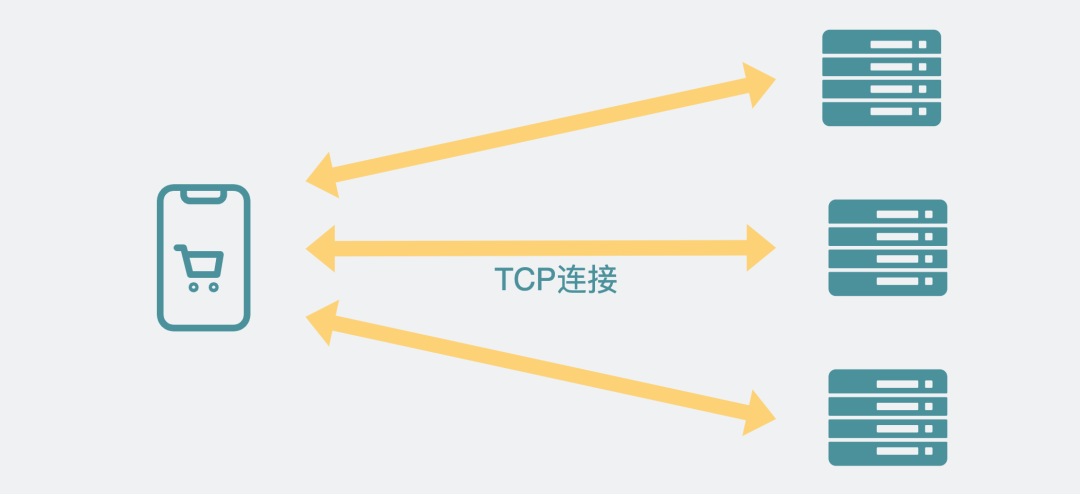
前端与多个服务器之间建立连接
也不是不行,但就是麻烦。
但这时候如果能有个中间层挡在它们中间就好了,这样客户端只需要跟中间层连接,中间层再和服务器建立连接。
于是,这个中间层就成了这帮服务器的一个代理人一样,客户端有啥事都找代理人,只管发出自己的请求,再由代理人去找某个服务器去完成响应。整个过程下来,客户端只知道自己的请求被代理人帮忙搞定了,但代理人具体找了那个服务器去完成,客户端并不知道,也不需要知道。
像这种,屏蔽掉具体有哪些服务器的代理方式就是所谓的反向代理。
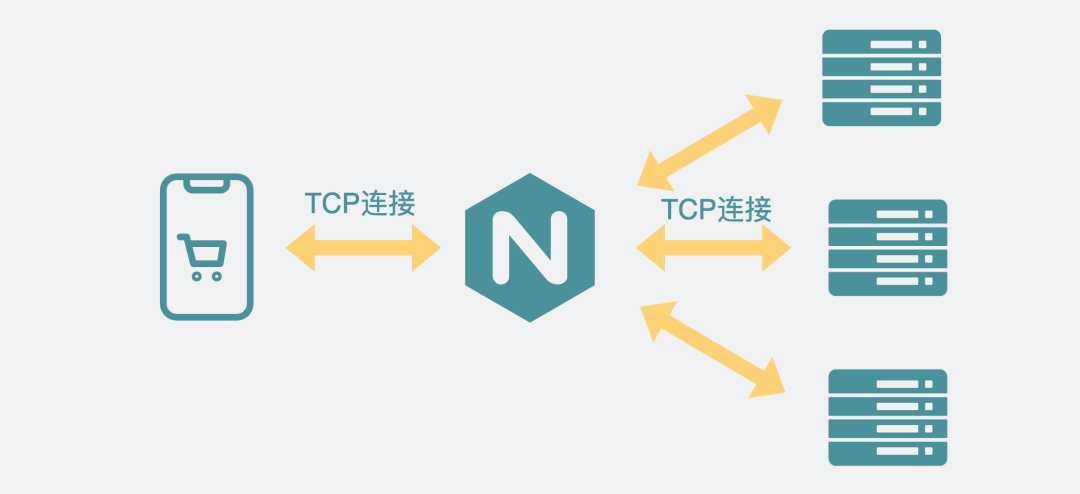
反向代理
反过来,屏蔽掉具体有哪些客户端的代理方式,就是所谓的正向代理。
而这个中间层的角色,一般由nginx这类网关来充当。
另外,由于背后的服务器可能性能配置各不相同,有些4核8G,有些2核4G,nginx能为它们加上不同的访问权重,权重高的多转发点请求,通过这个方式实现不同的负载均衡策略。
nginx返回5xx状态码
有了nginx这一中间层后,客户端从直连服务端,变成客户端直连nginx,再由nginx直连服务端。从一个TCP连接变成两个TCP连接。
于是,当服务器发生异常时,nginx发送给服务器的那条TCP连接就不能正常响应,nginx在得到这一信息后,就会返回5xx错误码给客户端,也就是说5xx的报错,其实是由nginx识别出来,并返回给客户端的,服务端本身,并不会有5xx的日志信息。所以才会出现文章开头的一幕,上游收到了我服务的502报错,但我在自己的服务日志里却搜索不到这一信息。
产生502的常见原因
在rfc7231中有关于502错误码的官方解释是
502 Bad Gateway The 502 (Bad Gateway) status code indicates that the server, while acting as a gateway or proxy, received an invalid response from an inbound server it accessed while attempting to fulfill the request.
翻译一下就是,502 (Bad Gateway) 状态代码表示服务器在充当网关或代理时,在尝试满足请求时从它访问的入站服务器接收到无效响应。
汝听,人言否?
这对于大部分编程小白来说,不仅没解释到问题,反而只会冒出更多的问号。比如,这上面提到的无效响应到底指的是什么?
我来解释下,它其实是说,502其实是由网关代理(nginx)发出的,是因为网关代理把客户端的请求转发给了服务端,但服务端却发出了无效响应,而这里的无效响应,一般是指TCP的RST报文或四次挥手的FIN报文。
四次挥手估计大家背的很熟了,所以略过,我们来重点说下RST报文是什么。
RST是什么?
我们都知道TCP正常情况下断开连接是用四次挥手,那是正常时候的优雅做法。
但异常情况下,收发双方都不一定正常,连挥手这件事本身都可能做不到,所以就需要一个机制去强行关闭连接。
RST 就是用于这种情况,一般用来异常地关闭一个连接。它是TCP包头中的一个标志位,在收到置这个标志位的数据包后,连接就会被关闭,此时接收到 RST的一方,在应用层会看到一个 connection reset 或 connection refused 的报错。
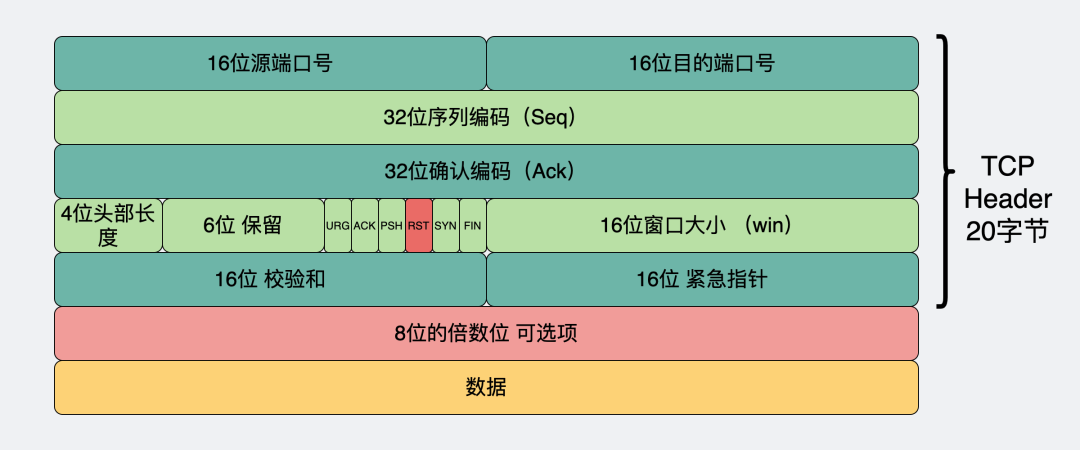
TCP报头RST位
而之所以发出RST报文,一般有两个常见原因。
服务端过早断开连接
nginx与服务端之间有一条TCP连接,在nginx将客户端请求转发给服务端时,他两之间按道理会一直保持这条连接,直到服务端将结果正常返回后,再断开连接。
但如果服务端过早断开连接,而nginx却还继续发消息过去,nginx就会收到服务端内核返回的RST报文或四次挥手的FIN报文,迫使nginx那边的连接结束。
过早断开连接的原因常见的有两个。
第一个是,服务端设置的超时时间过短。不管是用的哪种编程语言,一般都有现成的HTTP库,服务端一般都会有几个timeout参数,比如golang的HTTP服务框架里有个写超时(WriteTimeout),假设设置了2s,那它的含义就是,服务端在收到请求后需要在2s内处理完并将结果写到响应中,如果等不到,就会将连接给断掉。
比如你的接口处理时间是5s,而你的WriteTimeout却只有2s,在没等到响应写完之前,HTTP框架就会主动将连接给断开。nginx此时就有可能收到四次挥手的FIN报文(有些框架也可能发RST报文),然后断开连接,于是客户端就会收到一个502报错。
遇到这种问题,将WriteTimeout的时间调大一些就好了。
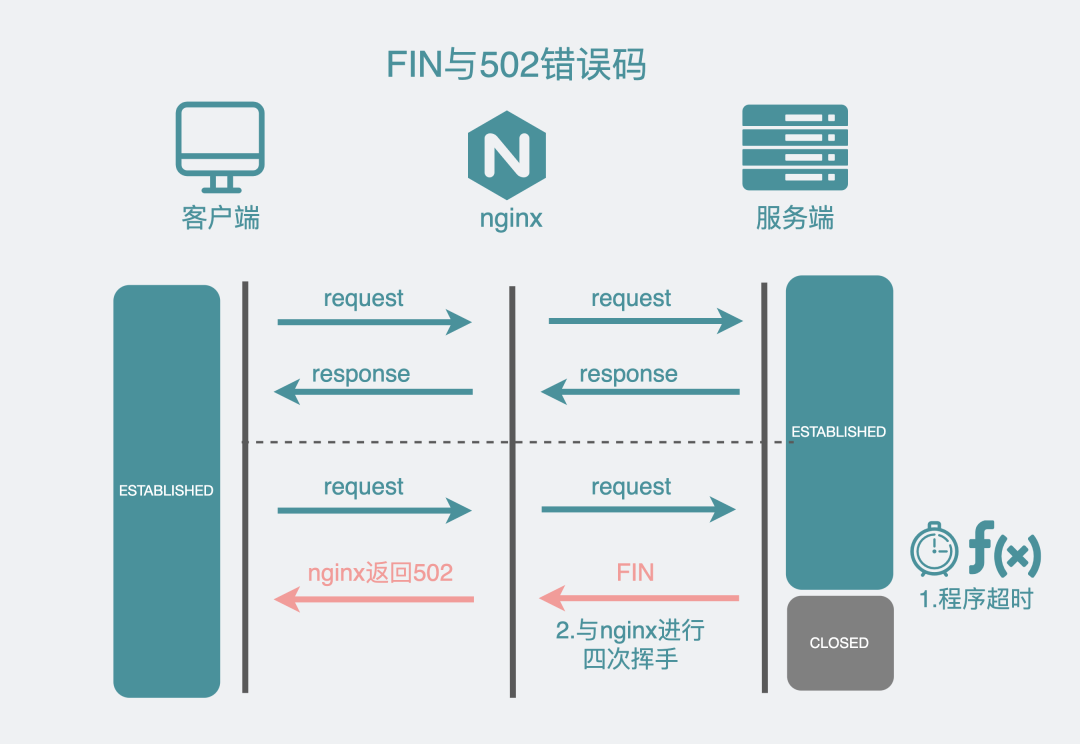
FIN与502的关系
第二个原因,也是造成502状态码最常见的原因,就是服务端应用进程崩了(crash)。
服务端崩了,也就是当前没有一个进程在监听服务器端口,而此时你却尝试向一个不存在的端口发数据,服务器的linux内核协议栈就会响应一个RST数据包。同样,这时候nginx也会给客户端一个502。
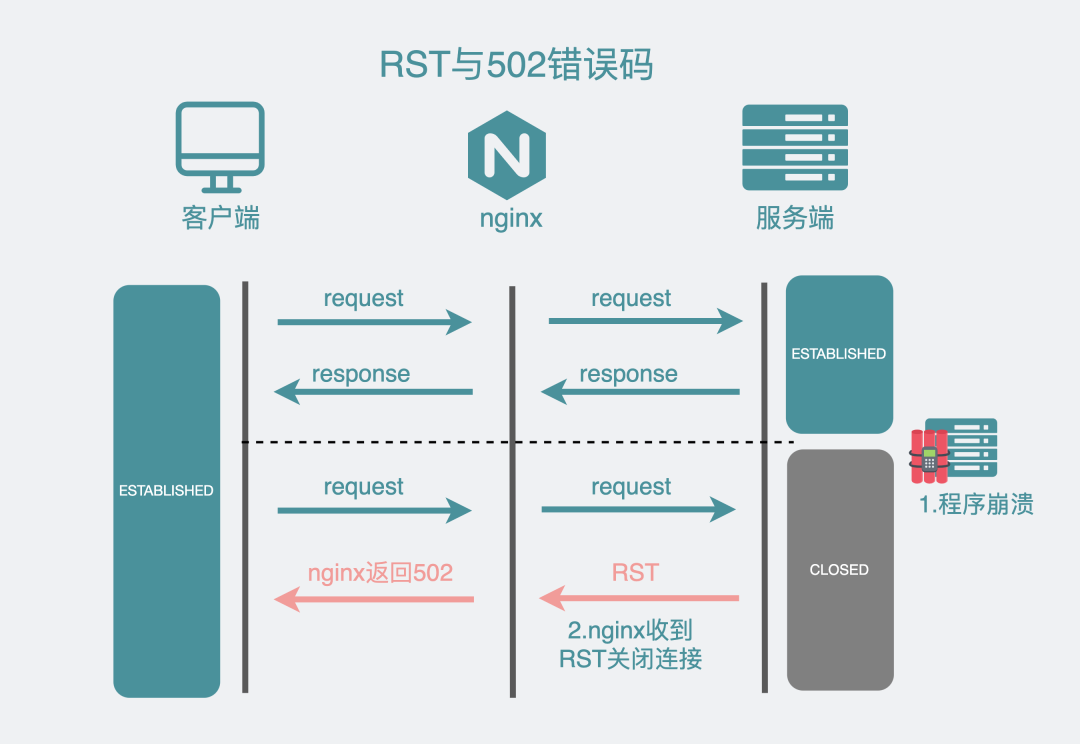
RST和502
在开发过程中,这种情况是最常见的。
现在我们大部分的服务器都会将挂掉的服务重启,因此我们需要判断下服务是否曾经崩溃过。
如果你有对服务端的cpu或者内存做过监控,可以看下CPU或内存的监控图是否出现过断崖式的突然下跌。如果有,十有八九百,就是你的服务端应用程序曾经崩溃过。
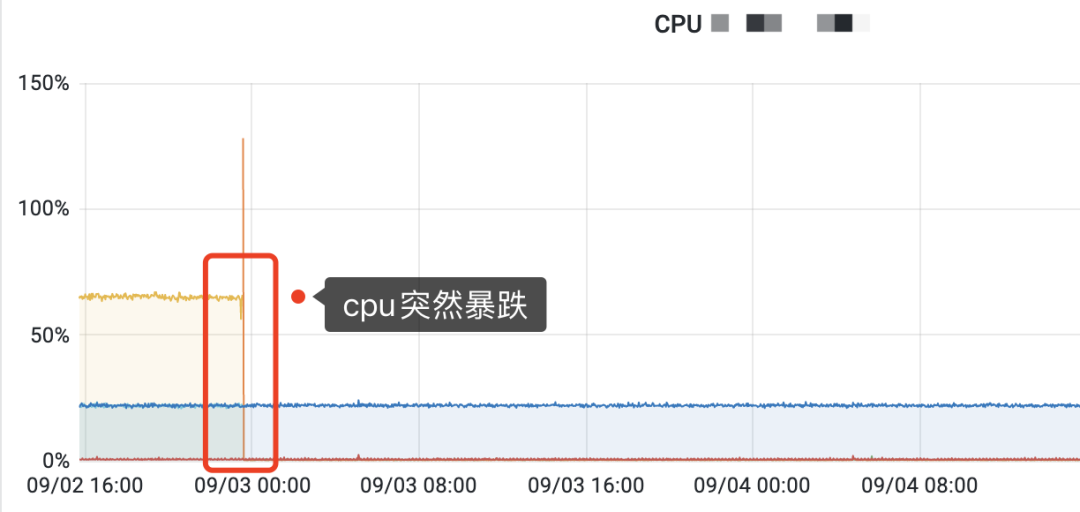
cpu突然暴跌
除此之外你还通过下面的命令,看下进程上次的启动时间是什么时候。
ps -o lstart {pid}
比如我要看的进程id是13515,命令就需要像下面这样。
# ps -o lstart 13515 STARTED Wed Aug 31 1453 2022
可以看到它上次的启动时间是8月31日,这个时间如果跟你印象中的操作时间有差距,那说明进程可能是崩了之后被重新拉起了。
遇到这种问题,最重要的是找出崩溃的原因,崩溃的原因就多种多样了,比如,对未初始化的内存地址进行写操作,或者内存访问越界(数组arr长度明明只有2,代码却读arr[3])。
这种情况几乎都是程序有代码逻辑问题,崩溃一般也会留下代码堆栈,可以根据堆栈报错去排查问题,修复之后就好了。比如下面这张图是golang的报错堆栈信息,其他语言的也类似。
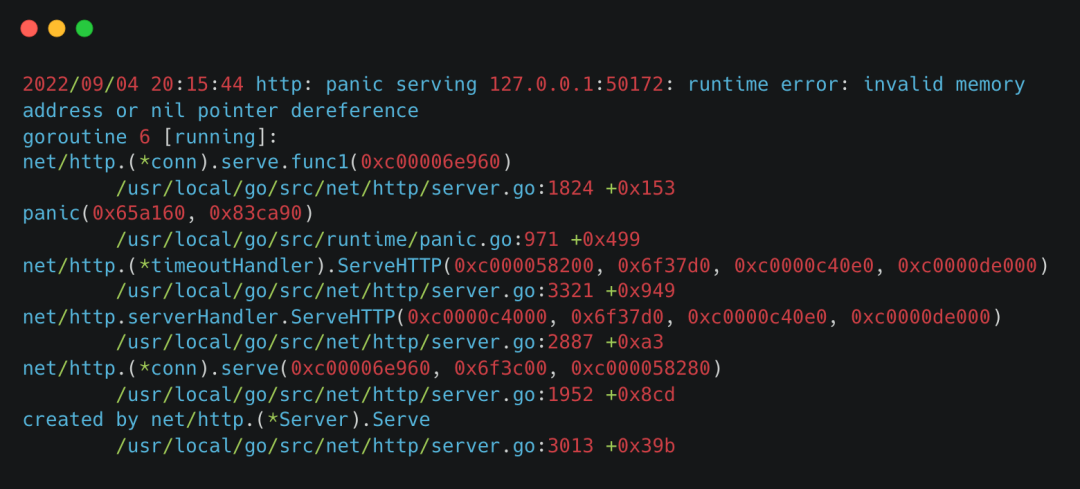
报错堆栈
不打印堆栈的情况
但有一些情况,有时候根本不留下堆栈。
比如内存泄露导致进程占用内存越来越多,最后导致超过服务器的最大内存限制,触发OOM(out of memory), 进程直接就被操作系统kill掉。
还有更隐蔽的,代码逻辑里隐藏了主动退出进程的操作。比如golang的日志打印里有个方法叫log.Fatalln(),打印完日志还会顺便执行os.Exit()直接退出进程,对源码不了解的新手很容易犯这个错。

打印完顺便还退出进程
如果你很明确,你的服务没有崩过。那继续往下看。
网关将请求打到了一个不存在的IP上
nginx是通过配置的形式来代理多个服务器。这个配置一般是放在 /etc/nginx/nginx.conf 中。
打开它,你可能会看到类似下面这样的信息。
upstream xiaobaidebug.top { server 10.14.12.19:9235 weight=2; server 10.14.16.13:8145 weight=5; server 10.14.12.133:9702 weight=8; server 10.14.11.15:7035 weight=10; }
上面配置的含义是,如果客户端访问xiaobaidebug.top域名,nginx就会将客户端的请求转发到下面的4个服务器ip上,ip边上还有个weight权重,权重越高,被转发到的次数就越多。
可以看出,nginx具有相当丰富的配置能力。但要注意的是,这些个文件是需要自己手动配置的。对于服务器少,且不怎么变化的情况,这当然没问题。
但现在已经是云原生时代了,很多公司内部都有自己的云产品,服务自然也会上云。一般来说每次更新服务,都可能会将服务部署到一台新的机器上。而这个ip也会随着改变,难道每发布一次服务,都需要手动去nginx上改配置吗?这显然不现实。
如果能在服务启动时,让服务主动将自己的ip告诉nginx,然后nginx自己生成这样的一个配置并重新加载,那事情就简单多了。
为了实现这样一个服务注册的功能,不少公司都会基于nginx进行二次开发。
但如果这个服务注册功能有问题,比方说服务启动后,新服务没注册上,但老服务已经被销毁了。这时候nginx还将请求打到老服务的IP上,由于老服务所在的机器已经没有这个服务了,所以服务器内核就会响应RST,nginx收到RST后回复502给客户端。
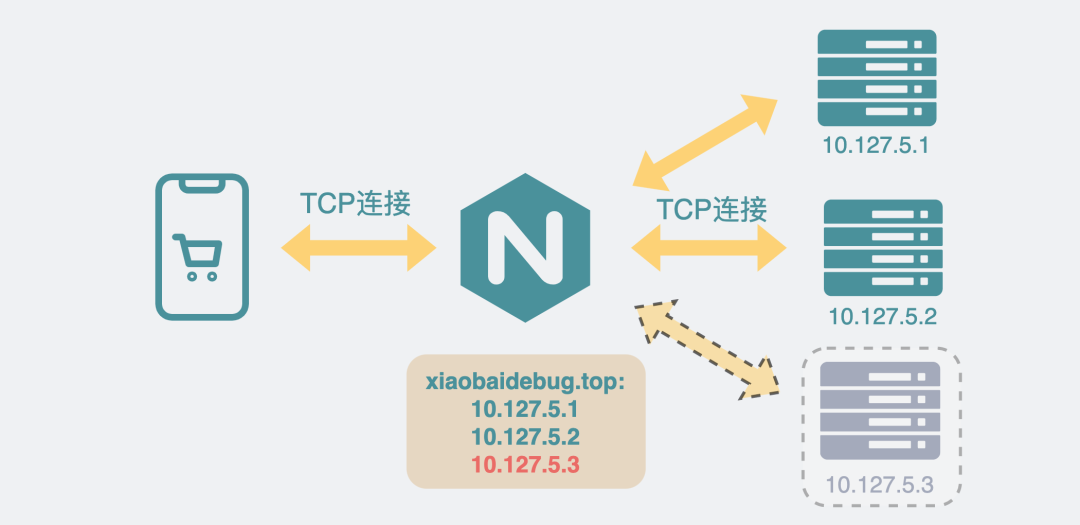
实例已经销毁但配置没删IP
要排查这种问题也不难。
这个时候,你可以看下nginx侧是否有打印相关的日志,看下转发的IP端口是否符合预期。
如果不符合预期,可以去找找做这个基础组件的同事,进行一波友好的交流。
总结
HTTP状态码用来表示响应结果的状态,其中200是正常响应,4xx是客户端错误,5xx是服务端错误。
客户端和服务端之间加入nginx,可以起到反向代理和负载均衡的作用,客户端只管向nginx请求数据,并不关心这个请求具体由哪个服务器来处理。
后端服务端应用如果发生崩溃,nginx在访问服务端时会收到服务端返回的RST报文,然后给客户端返回502报错。502并不是服务端应用发出的,而是nginx发出的。因此发生502时,后端服务端很可能没有没有相关的502日志,需要在nginx侧才能看到这条502日志。
如果发现502,优先通过监控排查服务端应用是否发生过崩溃重启,如果是的话,再看下是否留下过崩溃堆栈日志,如果没有日志,看下是否可能是oom或者是其他原因导致进程主动退出。如果进程也没崩溃过,去排查下nginx的日志,看下是否将请求打到了某个不知名IP端口上。
审核编辑 :李倩
-
Nginx 502报错的常见根因和排查步骤2026-05-27 464
-
Nginx 502 Bad Gateway错误的成因和排查方法2026-05-06 774
-
Nginx日志分析命令实践和常见问题排查思路2026-04-15 456
-
IG502怎么管理MQTT?2025-08-05 3507
-
最大502 ADI2023-10-11 45
-
502数据表2023-04-19 371
-
Fluke 190-502 二通道手持示波表|福禄克示波表190-502|福禄克190-5022022-02-23 766
-
DC502A DC502A评估板2021-09-06 528
-
DC502A-模式2021-04-26 486
-
DC502A-设计文件2021-04-11 405
-
***功放VSX-C5022019-11-15 3640
-
502瞬干胶使用2009-09-15 821
-
OPA502应用电路2008-12-17 1590
全部0条评论

快来发表一下你的评论吧 !
