

讲讲Micrium全家桶的uC-CRC算法
描述
前言
我们这一篇来讲讲Micrium全家桶的uC-CRC。该代码库提供了CRC算法进行错误检测EDC,使用HAMMING算法实现ECC错误纠正。ECC算法在NAND的TFL中使用。
修改版本,去掉对uC-LIB,uC-CPU等的依赖,可以直接单独使用,方便移植。
文件介绍
│ LICENSE
│ NOTICE
│ readme.md
│
├─Cfg
│ └─Template
│ crc_cfg.h
│
├─Ports
│ ├─ARM
│ │ └─IAR
│ │ ecc_hamming_a.asm
│ │ edc_crc_a.asm
│ │
│ └─ARM-Cortex-M3
│ └─IAR
│ ecc_hamming_a.asm
│ edc_crc_a.asm
│
└─Source
crc_util.c
crc_util.h
ecc.h
ecc_hamming.c
ecc_hamming.h
edc_crc.c
edc_crc.h
| 文件 | 说明 |
| LICENSE/NOTICE/readme.md | LICENSE使用的APACHE-2.0 |
| crc_cfg.h | 配置文件 |
| ecc_hamming_a.asm |
使用汇编实现 Hamming_ParCalcBitWord_32 默认提供了ARM和ARM-Cortex-M3架构IAR编译器的版本 crc_cfg.h中#define EDC_CRC_CFG_OPTIMIZE_ASM_EN DEF_ENABLED时使用,默认不使 |
| edc_crc_a.asm |
使用汇编实现 CRC_ChkSumCalcTbl_16Bit CRC_ChkSumCalcTbl_16Bit_ref CRC_ChkSumCalcTbl_32Bit CRC_ChkSumCalcTbl_32Bit_ref 默认提供了ARM和ARM-Cortex-M3架构IAR编译器的版本 crc_cfg.h中#define EDC_CRC_CFG_OPTIMIZE_ASM_EN DEF_ENABLED时使用,默认不使用 |
| crc_util.c/h |
实现CRCUtil_PopCnt_32 算法来自于http://en.wikipedia.org/wiki/Hamming_weight |
| ecc_hamming.c/h | Ecc算法代码 |
| edc_crc.c/h | Crc算法代码 |
添加代码到自己的工程
添加uC-CRCCfgTemplatecrc_cfg.h
uC-CRCSource下所有文件到自己的工程目录uC-CRC下
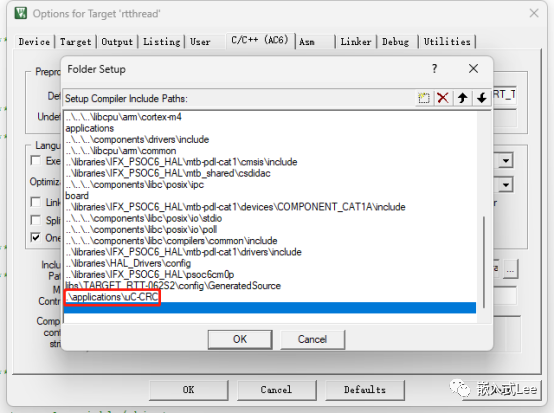
并配置头文件包含路径uC-CRC
依赖
| 文件 | 内容 |
|
cpu.h cpu_core.h lib_def.h lib_mem.h |
CPU_BOOLEAN CPU_INT08U CPU_INT16U CPU_INT32U CPU_ADDR CPU_DATA CPU_SIZE_T CPU_WORD_SIZE_32 DEF_NO DEF_YES DEF_DISABLED DEF_ENABLED DEF_INVALID DEF_VALID DEF_OCTET_NBR_BITS DEF_BIT DEF_BIT_00~DEF_BIT_12 DEF_BIT_13 DEF_BIT_15 DEF_BIT_17 DEF_BIT_19 DEF_BIT_21 DEF_BIT_23 DEF_BIT_25 DEF_BIT_27 DEF_BIT_29 DEF_BIT_31 DEF_BIT_SET DEF_BIT_IS_SET CPU_SW_EXCEPTION MEM_VAL_COPY_GET_INT32U MEM_VAL_COPY_GET_INTU MEM_VAL_COPY_SET_INT32U Mem_Clr |
修改代码
注释掉crc_util.h下的
#include#include
改为
#include
注释掉ecc.h下的
#include#include
注释掉ecc_hamming.h下的
#include#include #include #include
注释掉edc_crc.h下的
#include#include #include
注释掉
ecc_hamming.c下的
Mem_Clr((void *)p_ecc, HAMMING_LEN_OCTET_ECC); /* Init ECC buf for err(s) (see Note #6). */
改为
memset((void *)p_ecc, 0, HAMMING_LEN_OCTET_ECC);
前面添加
#include
crc_cfg.h中实现以下依赖
/*
*********************************************************************************************************
* PORT
*
* Note(s) : (1) 以下添加依赖部分移植
*
*
*********************************************************************************************************
*/
/* ------------------ CPU WORD-ENDIAN ORDER ------------------- */
#define CPU_ENDIAN_TYPE_NONE 0u
#define CPU_ENDIAN_TYPE_BIG 1u /* Big- endian word order (see Note #1a). */
#define CPU_ENDIAN_TYPE_LITTLE 2u /* Little-endian word order (see Note #1b). */
#define CPU_CFG_ENDIAN_TYPE CPU_ENDIAN_TYPE_LITTLE
typedef unsigned char CPU_BOOLEAN; /* 8-bit boolean or logical */
typedef unsigned char CPU_INT08U; /* 8-bit unsigned integer */
typedef unsigned short CPU_INT16U; /* 16-bit unsigned integer */
typedef unsigned int CPU_INT32U; /* 32-bit unsigned integer */
typedef CPU_INT32U CPU_ADDR; /* CPU address type based on address bus size. */
typedef CPU_INT32U CPU_DATA; /* CPU data type based on data bus size. */
typedef CPU_ADDR CPU_SIZE_T; /* Defines CPU standard 'size_t' size. */
#define CPU_WORD_SIZE_32 4u /* 32-bit word size (in octets). */
/* ----------------- BOOLEAN DEFINES ------------------ */
#define DEF_NO 0u
#define DEF_YES 1u
#define DEF_DISABLED 0u
#define DEF_ENABLED 1u
#define DEF_INVALID 0u
#define DEF_VALID 1u
#define DEF_OCTET_NBR_BITS 8u
#define DEF_BIT(bit) (1uL << (bit))
/* ------------------- BIT DEFINES -------------------- */
#define DEF_BIT_00 0x01u
#define DEF_BIT_01 0x02u
#define DEF_BIT_02 0x04u
#define DEF_BIT_03 0x08u
#define DEF_BIT_04 0x10u
#define DEF_BIT_05 0x20u
#define DEF_BIT_06 0x40u
#define DEF_BIT_07 0x80u
#define DEF_BIT_08 0x0100u
#define DEF_BIT_09 0x0200u
#define DEF_BIT_10 0x0400u
#define DEF_BIT_11 0x0800u
#define DEF_BIT_12 0x1000u
#define DEF_BIT_13 0x2000u
#define DEF_BIT_15 0x8000u
#define DEF_BIT_17 0x00020000u
#define DEF_BIT_19 0x00080000u
#define DEF_BIT_21 0x00200000u
#define DEF_BIT_23 0x00800000u
#define DEF_BIT_25 0x02000000u
#define DEF_BIT_27 0x08000000u
#define DEF_BIT_29 0x20000000u
#define DEF_BIT_31 0x80000000u
#define DEF_BIT_SET(val, mask) ((val) = ((val) | (mask)))
#define DEF_BIT_IS_SET(val, mask) (((((val) & (mask)) == (mask)) && ((mask) != 0u)) ? (DEF_YES) : (DEF_NO))
#define CPU_SW_EXCEPTION(err_rtn_val) do {
;
} while (1)
#define MEM_VAL_COPY_GET_INT32U(addr_dest, addr_src) do {
CPU_INT08U *destptr = (CPU_INT08U *)(addr_dest);
CPU_INT08U *srcptr = (CPU_INT08U *)(addr_src);
(*((destptr) + 0)) = (*((srcptr) + 0));
(*((destptr) + 1)) = (*((srcptr) + 1));
(*((destptr) + 2)) = (*((srcptr) + 2));
(*((destptr) + 3)) = (*((srcptr) + 3)); } while (0)
#define MEM_VAL_COPY_GET_INTU(addr_dest, addr_src, val_size) do {
CPU_SIZE_T _i;
for (_i = 0; _i < (val_size); _i++) {
(*(((CPU_INT08U *)(addr_dest)) + _i)) = (*(((CPU_INT08U *)(addr_src)) + _i));
}
} while (0)
#define MEM_VAL_COPY_SET_INT32U(addr_dest, addr_src) MEM_VAL_COPY_GET_INT32U(addr_dest, addr_src)
测试
ECC
用户代码中#include ”ecc_hamming.h”
调用以下接口
Hamming_Calc
Hamming_Chk
Hamming_Correct
详见test.c
#include#include #include "ecc_hamming.h" typedef struct { ECC_ERR err; char* str; }err_str; err_str s_err_str[]= { {ECC_ERR_NONE,"No error."}, {ECC_ERR_CORRECTABLE,"Correctable error detected in data."}, {ECC_ERR_ECC_CORRECTABLE,"Correctable error detected in ECC."}, {ECC_ERR_INVALID_ARG,"Argument passed invalid value. "}, {ECC_ERR_INVALID_LEN,"Len argument passed invalid length."}, {ECC_ERR_NULL_PTR,"Pointer argument passed NULL pointer."}, {ECC_ERR_UNCORRECTABLE,"Uncorrectable error detected in data."} }; uint8_t s_buffer[33]; uint8_t s_ecc[4]; int ecc_main(int argc, char* argv[]) { CPU_INT08U ecc[4]; ECC_ERR_LOC err_loc[2]={{0,0},{0,0}}; ECC_ERR err; for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { s_buffer[i] = i+1; } /* 打印原始数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); CPU_SIZE_T len = (sizeof(s_buffer)/sizeof(s_buffer[0])); CPU_SIZE_T len_buf = (len / 32)*32; CPU_SIZE_T len_buf_ext = len % 32; CPU_INT08U* p_buf_ext = (CPU_INT08U *)s_buffer + len_buf; Hamming_Calc(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,&err); if(ECC_ERR_NONE != err) { printf("Hamming_Calc err:%d ",err); return -1; } printf("Hamming_Calc:ecc %#x %#x %#x %#x ",s_ecc[0],s_ecc[1],s_ecc[2],s_ecc[3]); /* * 1位数据错误 */ /* DATA注入错误 */ printf(" [DATA err test] "); s_buffer[0] ^= 0x80; /* 打印错误数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); if(ECC_FAULT == Hamming_Chk(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,err_loc,sizeof(err_loc)/sizeof(err_loc[0]),&err)) { printf("Hamming_Chk err:%d ",err); return -2; } printf("Hamming_Chk:loc B[%d].b[%d] B[%d].b[%d] ",err_loc[0].LocOctet,err_loc[0].LocBit,err_loc[1].LocOctet,err_loc[1].LocBit); printf("%s",s_err_str[err].str); Hamming_Correct(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,&err); /* 打印修复后的数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); printf("Hamming_Correct:ecc %#x %#x %#x %#x ",s_ecc[0],s_ecc[1],s_ecc[2],s_ecc[3]); printf("%s",s_err_str[err].str); /* * 1位ECC错误 */ /* DATA注入错误 */ printf(" [ECC err test] "); s_ecc[1] ^= 0x02; /* 打印错误数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); if(ECC_FAULT == Hamming_Chk(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,err_loc,sizeof(err_loc)/sizeof(err_loc[0]),&err)) { printf("Hamming_Chk err:%d ",err); return -2; } printf("Hamming_Chk:loc B[%d].b[%d] B[%d].b[%d] ",err_loc[0].LocOctet,err_loc[0].LocBit,err_loc[1].LocOctet,err_loc[1].LocBit); printf("%s",s_err_str[err].str); Hamming_Correct(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,&err); /* 打印修复后的数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); printf("Hamming_Correct:ecc %#x %#x %#x %#x ",s_ecc[0],s_ecc[1],s_ecc[2],s_ecc[3]); printf("%s",s_err_str[err].str); /* * 2位数据错误 */ /* DATA注入错误 */ printf(" [2DATA err test] "); s_buffer[2] ^= 0x04; s_buffer[5] ^= 0x10; /* 打印错误数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); if(ECC_FAULT == Hamming_Chk(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,err_loc,sizeof(err_loc)/sizeof(err_loc[0]),&err)) { printf("Hamming_Chk err:%d ",err); return -2; } printf("Hamming_Chk:loc B[%d].b[%d] B[%d].b[%d] ",err_loc[0].LocOctet,err_loc[0].LocBit,err_loc[1].LocOctet,err_loc[1].LocBit); printf("%s",s_err_str[err].str); Hamming_Correct(s_buffer,len_buf,p_buf_ext,len_buf_ext,s_ecc,&err); /* 打印修复后的数据 */ for(int i=0; i< sizeof(s_buffer)/sizeof(s_buffer[0]); i++) { if(i % 16 == 0) { printf(" "); } printf("%#x ",s_buffer[i]); } printf(" "); printf("Hamming_Correct:ecc %#x %#x %#x %#x ",ecc[0],ecc[1],ecc[2],ecc[3]); printf("%s",s_err_str[err].str); return 0; }
测试结果如下可以看到,1位的数据错误校正过来了,ECC编码本身的1位错误认为是不可校正错误,两位数据错误也是不可校正错误

CRC
接口如下,下篇再单讲
CRC_Open_16Bit CRC_WrBlock_16Bit CRC_WrOctet_16Bit CRC_Close_16Bit CRC_Open_32Bit CRC_WrBlock_32Bit CRC_WrOctet_32Bit CRC_Close_32Bit CRC_Reflect_08Bit CRC_Reflect_16Bit CRC_Reflect_32Bit CRC_ChkSumCalc_16Bit CRC_ChkSumCalc_32Bit
汉明码
冗余位
假设有m位数据,至少要添加n位冗余位才能检测出错误(只考虑只有1个bit错误的情况)。
m位数据,n位冗余数据错1位的情况有m+n种,还有一种情况是无错。
需要用n位冗余位去标志是哪一位错了,所以要满足2^n >= m+n+1。
奇偶校验
奇校验:数据和校验位一起,1的个数为奇数
偶校验:数据和校验位一起,1的个数为偶数
奇偶校验只能发现奇数个位翻转,因为偶数个位翻转奇偶性不变。
汉明码
即奇偶校验的升级,组合。
先根据2^n >= m+n+1计算需要多少个校验位,
然后确认校验位的位置在2^n索引位上(索引从1开始)。
比如7位数据需要4位校验位,2^4 >= 7+4+1,一共11位,从1~11编号索引
写为二进制
0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011
将bit0是1的划分为一组 0001 0011 0101 0111 1001 1011
即1 3 5 7 9 11, 将对应数据位奇校验,放在2^0校验位
将bit1是1的划分为一组 0010 0011 0110 0111 1010 1011
即2 3 6 7 10 11, 将对应数据位奇校验,放在2^1校验位
将bit2是1的划分为一组 0100 0101 0110 0111
即4 5 6 7, 将对应数据位奇校验,放在2^2校验位
将bit3是1的划分为一组 0100 0101 0110 0111
即8 9 10 11, 将对应数据位奇校验,放在2^3校验位
纠错,如果2^0校验位不对bit0写1,如果2^1校验位不对bit1写1,得到的二进制数就是出错位的的索引。
比如以上如果bit5翻转了,索引5是在2^0和2^2组的所以,是101,即索引5的数据有错。
汉明距离
在一个码组集合中,任意两个码字之间对应位上码元取值不同的位的数目定义为这两个码字之间的汉明距离d。例如:(00)与(01)的距离是1,(110)和(101)的距离是2。在一个码组集合中,任意两个编码之间汉明距离的最小值称为这个码组的最小汉明距离。最小汉明距离越大,码组越具有抗干扰能力,即差异越大,冗余越多。即编码只用了一部分,剩余的空着,如果出现了错误则肯定是变成了空着的编码。
比如两位的编码实际可以编码为00 01 10 11,但是我们只用00代表A,10代表B,
那么收到01后,我们知道出错了,那么是哪个出错了呢,00变为01需要变化1位,10变为01需要变化2位,所以所以我们更倾向于是00变化了一位即是A出错了,
所以我们可以认为00和01都代表A
10 11 都代表B
这样实际就是用冗余来提高抗干扰能力,我们粗暴的发两次也是冗余,但是冗余太多了浪费空间,所以可以选择不冗余这么多,这个汉明距离d就是冗余的多少,d越大冗余越大,d越小冗余越小。
l当码组用于检测错误时,设可检测e个位的错误,则d ≥ e + 1
l若码组用于纠错,设可纠错t个位的错误,则 d ≥ 2 ∗ t + 1
即AB之间的距离至少是1才能区分AB, 剩余的空间2t划分一半,靠近A的一半t认为是A,靠近B的一半t认为是B。
l如果码组用于纠正t个错,检测e个错,则d ≥ e + t + 1
NAND中的硬件ECC
这里以W25N01GVZEIG芯片为例,不同芯片略有差异
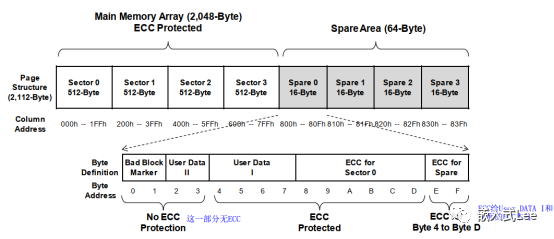
一个PAGE大大小是2112字节其中用户区域2048字节+额外区域64字节
将PAGE的用户区域和额外区域都分成4份即Sector,
则512字节用户区域对应16字节额外区域。
16字节额外区域如上图
0- 1 :2字节位坏块标记
2- 3 :2字节用户数据II
4-7 : 4字节用户数据I
8-D: 6字节前面Sector数据的ECC校验值
E-F:4-D对应的10字节的ECC校验值
问题:ECC for Sector 0本身有误码可以通过ECC for Spare检测出来,但是如果ECC for Spare本身有误码呢?
芯片自带的ECC校验使能通过寄存器配置(有些型号是默认使能的)
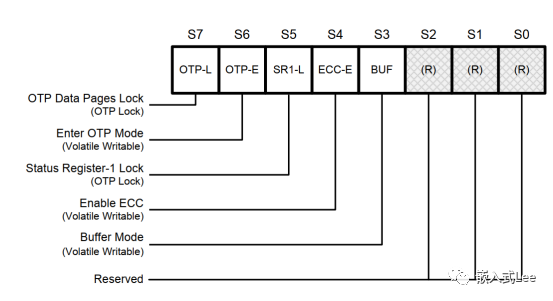

写数据时自动计算ECC并更新到64字节额外区域,读数据时自动校验ECC并进行校正,返回校正完后的正确值。
读数据时可以读状态寄存器确认ECC状态
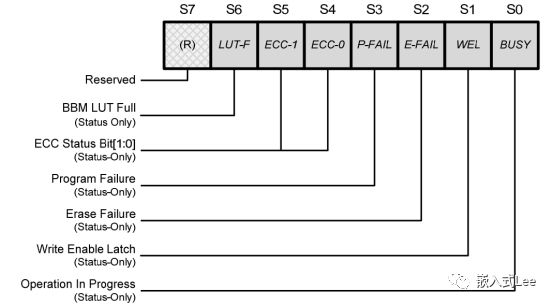

NAND中的软件ECC
256字节2048位,检测1位错误理论上只需要12位校验位即可,
2^12 >= 2048 + 12 + 1。
但是实际一半是纠正1位错误,检测2位错误
所以d ≥ e + t + 1=4
汉明距离至少要是4.
NAND实际应用中是按照行列分别校验的
按照一个字节8位x256字节
组成256x8,256行8列的矩阵
256行 16个校验位
8列 6个校验位
总共22位,3个字节,剩余两个bit未用放在高位
如下所示
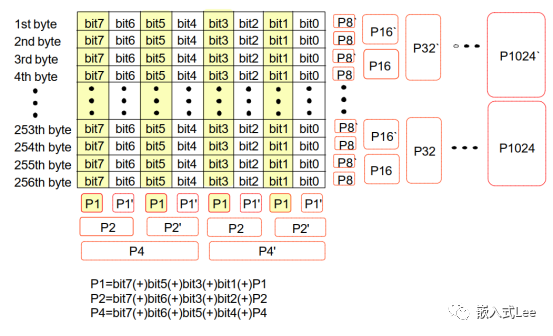
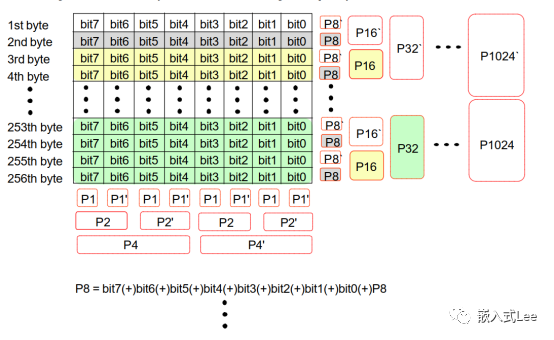
待办
以上Micrium和Linux的实现实际都没有实现检测ECC码自身错误的情况,都只能校正数据的1位错误,对于ECC码本身错误一位认为是不可校正错误,这里后续可以考虑优化。
总结
以上介绍了Micrium全家桶的uC-CRC组件,并修改成无其他依赖,比较好移植使用。其中的ECC在NAND中使用,所以重点进行了介绍。不仅仅介绍代码库的使用,同时也分析了原理,只有理论结合实践才能真的用好。CRC部分下次可以单独再讲讲。
审核编辑:刘清
-
新紫光集团三大领域全家桶正式发布2026-05-15 465
-
8种常用的CRC算法分享2025-11-13 200
-
Micrium全家桶之uC-FS: 0x02 NAND FTL算法原理详解2023-06-08 4898
-
云米家电推出AI智能产品“全家桶”2022-04-08 2468
-
相比React全家桶选择Vue2有何优劣?2020-06-01 1326
-
如何使用SMART编写CRC的校验算法程序2019-10-24 1435
-
加拿大肯德基推出比特币全家桶顾客可以用比特币支付2018-10-31 2397
-
嵌入式开发的crc算法知识精选2017-11-08 5212
-
在FPGA上实现CRC算法的程序2016-06-07 1150
-
这段CRC算法是什么意思2014-04-25 3058
-
基于SATAⅡ协议的CRC32并行算法的研究2012-11-07 2329
-
CRC算法原理及C语言实现2009-09-23 964
全部0条评论

快来发表一下你的评论吧 !
