

边缘AI的模型压缩技术
描述
深度学习在模型及其数据集方面正以惊人的速度增长。在应用方面,深度学习市场以图像识别为主,其次是光学字符识别,以及面部和物体识别。根据 Allied 市场研究,6 年全球深度学习市场价值为 85.2020 亿美元,预计到 179 年将达到 96.2030 亿美元,39 年至 2 年的复合年增长率为 2021.2030%。
在某个时间点,人们认为大型和复杂的模型表现更好,但现在它几乎是一个神话。随着边缘AI的发展,越来越多的技术将大型复杂模型转换为可以在边缘上运行的简单模型,所有这些技术结合起来执行模型压缩。
什么是模型压缩?
模型压缩是在计算能力和内存较低的边缘设备上部署SOTA(最先进的)深度学习模型的过程,而不会影响模型在准确性、精度、召回率等方面的性能。模型压缩大致减少了模型中的两件事,即大小和延迟。减小大小的重点是通过减少模型参数来简化模型,从而降低执行中的 RAM 要求和内存中的存储要求。延迟减少是指减少模型进行预测或推断结果所花费的时间。模型大小和延迟通常同时存在,大多数技术都会减少两者。
流行的模型压缩技术
修剪:
修剪是最流行的模型压缩技术,它通过删除冗余和无关紧要的参数来工作。神经网络中的这些参数可以是连接器、神经元、通道,甚至是层。它很受欢迎,因为它同时减小了模型的大小并改善了延迟。
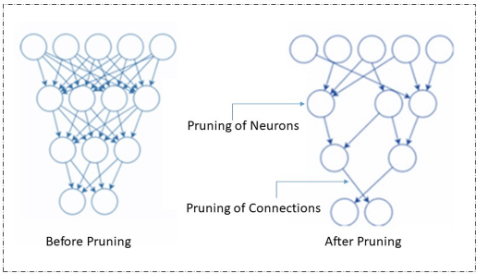
修剪
修剪可以在训练模型时或训练后完成。有不同类型的修剪技术,即权重/连接修剪、神经元修剪、过滤器修剪和层修剪。
量化:
当我们删除神经元、连接、过滤器、层等时。在修剪以减少加权参数的数量时,权重的大小在量化期间减小。在此过程中,大型集中的值将映射到较小集中的值。与输入网络相比,输出网络的值范围较窄,但保留了大部分信息。有关此方法的更多详细信息,您可以在此处阅读我们关于模型量化的深入文章。
知识蒸馏:
在知识蒸馏过程中,在一个非常大的数据集上训练一个复杂而庞大的模型。微调大型模型后,它可以很好地处理看不见的数据。一旦获得,这些知识就会转移到较小的神经网络或模型中。同时使用教师网络(较大的模型)和学生网络(较小的模型)。这里存在两个方面,知识蒸馏,我们不调整教师模型,而在迁移学习中,我们使用精确的模型和权重,在一定程度上改变模型,并根据相关任务进行调整。
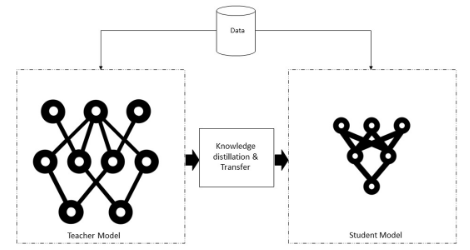
知识蒸馏系统
知识、蒸馏算法和师生架构模型是典型知识蒸馏系统的三个主要部分,如上图所示。
低矩阵分解:
矩阵构成了大多数深度神经结构的大部分。该技术旨在通过应用矩阵或张量分解并将它们制成更小的矩阵来识别冗余参数。这种技术应用于密集的DNN(深度神经网络)时,降低了CNN(卷积神经网络)层的存储要求和分解,并缩短了推理时间。具有二维且秩为 r 的权重矩阵 A 可以分解为更小的矩阵,如下所示。
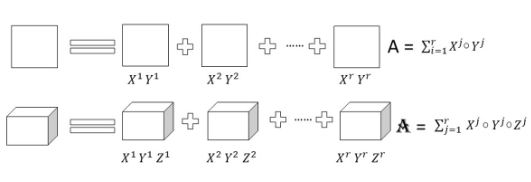
低矩阵分解
模型的准确性和性能在很大程度上取决于适当的分解和秩选择。低秩分解过程中的主要挑战是更难实现,并且是计算密集型的。总体而言,与全秩矩阵表示相比,密集层矩阵的因式分解可产生更小的模型和更快的性能。
由于边缘人工智能,模型压缩策略变得非常重要。这些方法是相互补充的,可以在整个 AI 管道的各个阶段使用。像TensorFlow和Pytorch这样的流行框架现在包括修剪和量化等技术。最终,该领域使用的技术数量将会增加。
审核编辑:郭婷
-
腾讯 AI Lab 开源世界首款自动化模型压缩框架PocketFlow2018-09-18 5152
-
模型压缩技术,加速AI大模型在终端侧的应用2023-04-24 4147
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 1682
-
cubemx ai导入onnx模型后压缩失败了怎么解决?2024-03-19 629
-
AI模型部署边缘设备的奇妙之旅:如何实现手写数字识别2024-12-06 3529
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1543
-
Deepseek海思SD3403边缘计算AI产品系统2025-04-28 8035
-
EdgeBoard FZ5 边缘AI计算盒及计算卡2020-08-31 2730
-
【HarmonyOS HiSpark AI Camera】边缘计算安全监控系统2020-09-25 1283
-
网络边缘实施AI的原因2021-02-23 1319
-
嵌入式边缘AI应用开发指南2022-11-03 1486
-
压缩模型会加速推理吗?2023-01-29 636
-
ST MCU边缘AI开发者云 - STM32Cube.AI2023-02-02 1314
-
边缘AI的模型压缩技术2022-10-19 2292
-
如何利用NPU与模型压缩技术优化边缘AI2025-11-07 1526
全部0条评论

快来发表一下你的评论吧 !
