

你知道你写的代码是怎样跑起来的吗(下)
电子说
描述
四、execve 加载用户程序
具体加载可执行文件的工作是由 execve 系统调用来完成的。
该系统调用会读取用户输入的可执行文件名,参数列表以及环境变量等开始加载并运行用户指定的可执行文件。该系统调用的位置在 fs/exec.c 文件中。
//file:fs/exec.c
SYSCALL_DEFINE3(execve, const char __user *, filename, ...)
{
struct filename *path = getname(filename);
do_execve(path->name, argv, envp)
...
}
int do_execve(...)
{
...
return do_execve_common(filename, argv, envp);
}
execve 系统调用到了 do_execve_common 函数。我们来看这个函数的实现。
//file:fs/exec.c
static int do_execve_common(const char *filename, ...)
{
//linux_binprm 结构用于保存加载二进制文件时使用的参数
struct linux_binprm *bprm;
//1.申请并初始化 brm 对象值
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
bprm->file = ...;
bprm->filename = ...;
bprm_mm_init(bprm)
bprm->argc = count(argv, MAX_ARG_STRINGS);
bprm->envc = count(envp, MAX_ARG_STRINGS);
prepare_binprm(bprm);
...
//2.遍历查找合适的二进制加载器
search_binary_handler(bprm);
}
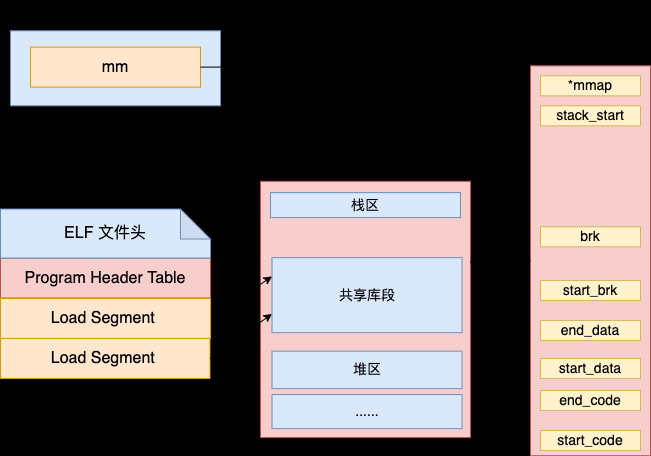
这个函数中申请并初始化 brm 对象的具体工作可以用下图来表示。
在这个函数中,完成了一下三块工作。
第一、使用 kzalloc 申请 linux_binprm 内核对象。该内核对象用于保存加载二进制文件时使用的参数。在申请完后,对该参数对象进行各种初始化。
第二、在 bprm_mm_init 中会申请一个全新的 mm_struct 对象,准备留着给新进程使用。
第三、给新进程的栈申请一页的虚拟内存空间,并将栈指针记录下来。
第四、读取二进制文件头 128 字节。
我们来看下初始化栈的相关代码。
//file:fs/exec.c
static int __bprm_mm_init(struct linux_binprm *bprm)
{
bprm->vma = vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
vma->vm_end = STACK_TOP_MAX;
vma->vm_start = vma->vm_end - PAGE_SIZE;
...
bprm->p = vma->vm_end - sizeof(void *);
}
在上面这个函数中申请了一个 vma 对象(表示虚拟地址空间里的一段范围),vm_end 指向了 STACK_TOP_MAX(地址空间的顶部附近的位置),vm_start 和 vm_end 之间留了一个 Page 大小。 也就是说默认给栈申请了 4KB 的大小 。最后把栈的指针记录到 bprm->p 中。
另外再看下 prepare_binprm,在这个函数中,从文件头部读取了 128 字节。之所以这么干,是为了读取二进制文件头为了方便后面判断其文件类型。
//file:include/uapi/linux/binfmts.h
#define BINPRM_BUF_SIZE 128
//file:fs/exec.c
int prepare_binprm(struct linux_binprm *bprm)
{
......
memset(bprm->buf, 0, BINPRM_BUF_SIZE);
return kernel_read(bprm->file, 0, bprm->buf, BINPRM_BUF_SIZE);
}
在申请并初始化 brm 对象值完后,最后使用 search_binary_handler 函数遍历系统中已注册的加载器,尝试对当前可执行文件进行解析并加载。
在 3.1 节我们介绍了系统所有的加载器都注册到了 formats 全局链表里了。函数 search_binary_handler 的工作过程就是遍历这个全局链表,根据二进制文件头中携带的文件类型数据查找解析器。找到后调用解析器的函数对二进制文件进行加载。
//file:fs/exec.c
int search_binary_handler(struct linux_binprm *bprm)
{
...
for (try=0; try<2; try++) {
list_for_each_entry(fmt, &formats, lh) {
int (*fn)(struct linux_binprm *) = fmt->load_binary;
...
retval = fn(bprm);
//加载成功的话就返回了
if (retval >= 0) {
...
return retval;
}
//加载失败继续循环以尝试加载
...
}
}
}
在上述代码中的 list_for_each_entry 是在遍历 formats 这个全局链表,遍历时判断每一个链表元素是否有 load_binary 函数。有的话就调用它尝试加载。
回忆一下 3.1 注册可执行文件加载程序,对于 ELF 文件加载器 elf_format 来说, load_binary 函数指针指向的是 load_elf_binary。
//file:fs/binfmt_elf.c
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
......
};
那么加载工作就会进入到 load_elf_binary 函数中来进行。这个函数很长,可以说所有的程序加载逻辑都在这个函数中体现了。我根据这个函数的主要工作,分成以下 5 个小部分来给大家介绍。
在介绍的过程中,为了表达清晰,我会稍微调一下源码的位置,可能和内核源码行数顺序会有所不同。
4.1 ELF 文件头读取
在 load_elf_binary 中首先会读取 ELF 文件头。
文件头中包含一些当前文件格式类型等数据,所以在读取完文件头后会进行一些合法性判断。如果不合法,则退出返回。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//定义结构题并申请内存用来保存 ELF 文件头
struct {
struct elfhdr elf_ex;
struct elfhdr interp_elf_ex;
} *loc;
loc = kmalloc(sizeof(*loc), GFP_KERNEL);
//获取二进制头
loc->elf_ex = *((struct elfhdr *)bprm->buf);
//对头部进行一系列的合法性判断,不合法则直接退出
if (loc->elf_ex.e_type != ET_EXEC && ...){
goto out;
}
...
}
4.2 Program Header 读取
在 ELF 文件头中记录着 Program Header 的数量,而且在 ELF 头之后紧接着就是 Program Header Tables。所以内核接下来可以将所有的 Program Header 都读取出来。
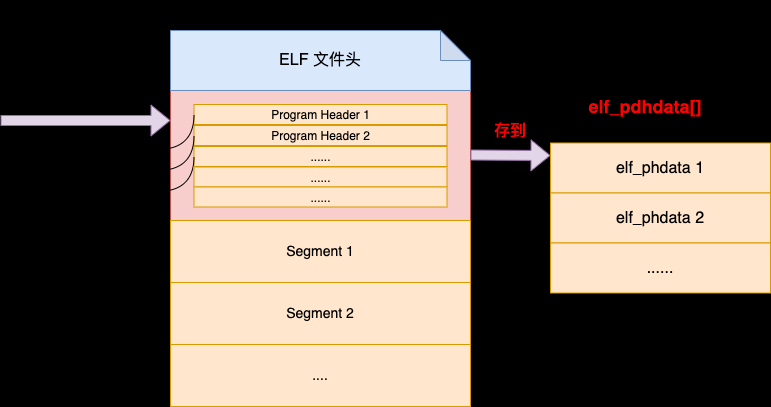
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
// elf_ex.e_phnum 中保存的是 Programe Header 数量
// 再根据 Program Header 大小 sizeof(struct elf_phdr)
// 一起计算出所有的 Program Header 大小,并读取进来
size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
elf_phdata = kmalloc(size, GFP_KERNEL);
kernel_read(bprm->file, loc->elf_ex.e_phoff,
(char *)elf_phdata, size);
...
}
4.3 清空父进程继承来的资源
在 fork 系统调用创建出来的进程中,包含了不少原进程的信息,如老的地址空间,信号表等等。这些在新的程序运行时并没有什么用,所以需要清空处理一下。
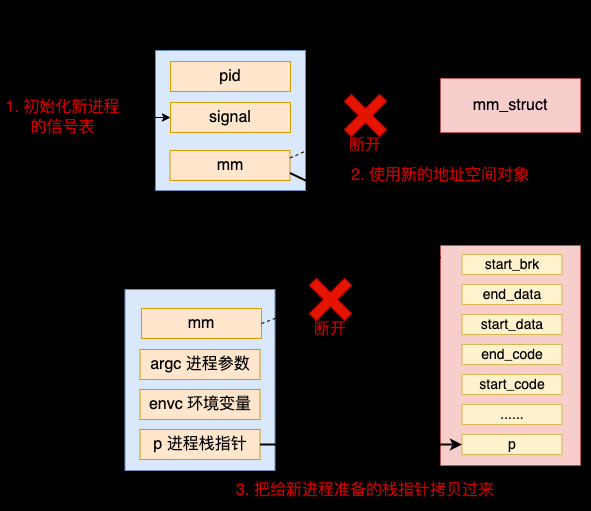
具体工作包括初始化新进程的信号表,应用新的地址空间对象等。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
retval = flush_old_exec(bprm);
...
current->mm->start_stack = bprm->p;
}
在清空完父进程继承来的资源后(当然也就使用上了新的 mm_struct 对象),这之后,直接将前面准备的进程栈的地址空间指针设置到了 mm 对象上。这样将来栈就可以被使用了。
4.4 执行 Segment 加载
接下来,加载器会将 ELF 文件中的 LOAD 类型的 Segment 都加载到内存里来。使用 elf_map 在虚拟地址空间中为其分配虚拟内存。最后合适地设置虚拟地址空间 mm_struct 中的 start_code、end_code、start_data、end_data 等各个地址空间相关指针。
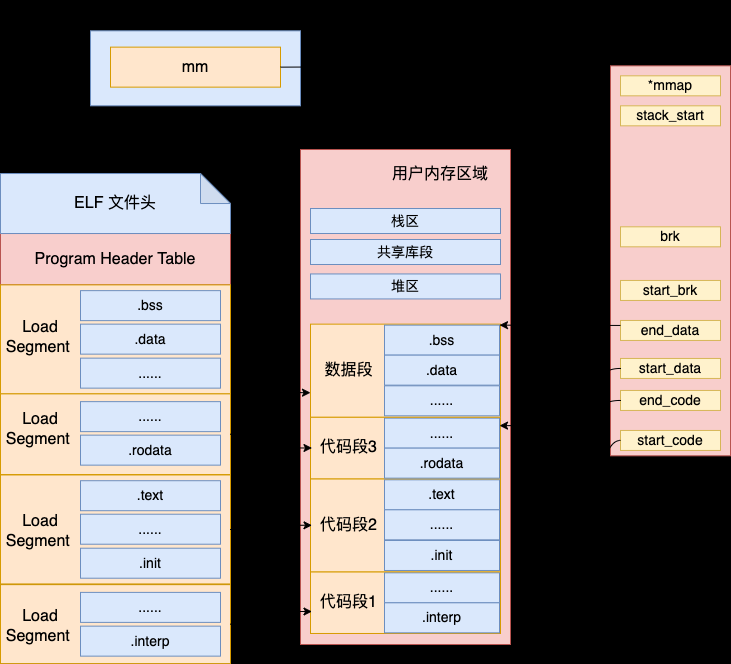
我们来看下具体的代码:
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载过程
//遍历可执行文件的 Program Header
for(i = 0, elf_ppnt = elf_phdata;
i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
//只加载类型为 LOAD 的 Segment,否则跳过
if (elf_ppnt->p_type != PT_LOAD)
continue;
...
//为 Segment 建立内存 mmap, 将程序文件中的内容映射到虚拟内存空间中
//这样将来程序中的代码、数据就都可以被访问了
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, 0);
//计算 mm_struct 所需要的各个成员地址
start_code = ...;
start_data = ...
end_code = ...;
end_data = ...;
...
}
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
...
}
其中 load_bias 是 Segment 要加载到内存里的基地址。这个参数有这么几种可能
- 值为 0,就是直接按照 ELF 文件中的地址在内存中进行映射
- 值为对齐到整数页的开始,物理文件中可能为了可执行文件的大小足够紧凑,而不考虑对齐的问题。但是操作系统在加载的时候为了运行效率,需要将 Segment 加载到整数页的开始位置处。
4.5 数据内存申请&堆初始化
因为进程的数据段需要写权限,所以需要使用 set_brk 系统调用专门为数据段申请虚拟内存。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载过程
//4.5 数据内存申请&堆初始化
retval = set_brk(elf_bss, elf_brk);
......
}
在 set_brk 函数中做了两件事情:第一是为数据段申请虚拟内存,第二是将进程堆的开始指针和结束指针初始化一下。
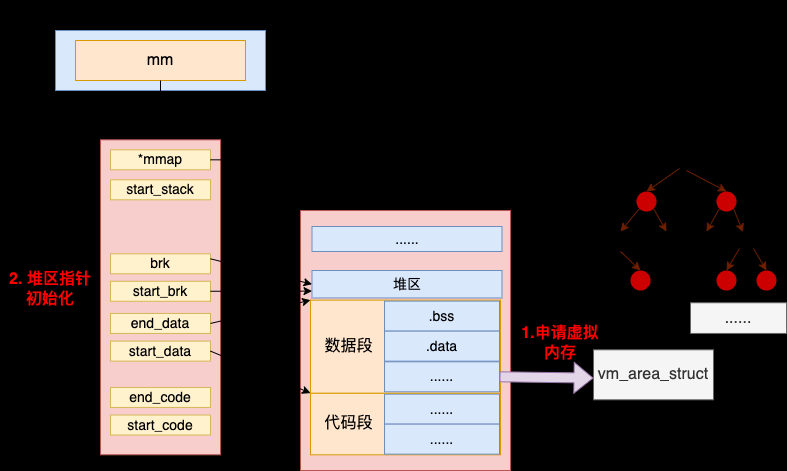
//file:fs/binfmt_elf.c
static int set_brk(unsigned long start, unsigned long end)
{
//1.为数据段申请虚拟内存
start = ELF_PAGEALIGN(start);
end = ELF_PAGEALIGN(end);
if (end > start) {
unsigned long addr;
addr = vm_brk(start, end - start);
}
//2.初始化堆的指针
current->mm->start_brk = current->mm->brk = end;
return 0;
}
因为程序初始化的时候,堆上还是空的。所以堆指针初始化的时候,堆的开始地址 start_brk 和结束地址 brk 都设置成了同一个值。
4.6 跳转到程序入口执行
在 ELF 文件头中记录了程序的入口地址。如果是非动态链接加载的情况,入口地址就是这个。
但是如果是动态链接,也就是说存在 INTERP 类型的 Segment,由这个动态链接器先来加载运行,然后再调回到程序的代码入口地址。
# readelf --program-headers helloworld
......
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
INTERP 0x00000000000002a8 0x00000000004002a8 0x00000000004002a8
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
对于是动态加载器类型的,需要先将动态加载器(本文示例中是 ld-linux-x86-64.so.2 文件)加载到地址空间中来。
加载完成后再计算动态加载器的入口地址。这段代码我展示在下面了,没有耐心的同学可以跳过。反正只要知道这里是计算了一个程序的入口地址就可以了。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载
//4.5 数据内存申请&堆初始化
//4.6 跳转到程序入口执行
//第一次遍历 program header table
//只针对 PT_INTERP 类型的 segment 做个预处理
//这个 segment 中保存着动态加载器在文件系统中的路径信息
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
...
}
//第二次遍历 program header table, 做些特殊处理
elf_ppnt = elf_phdata;
for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++){
...
}
//如果程序中指定了动态链接器,就把动态链接器程序读出来
if (elf_interpreter) {
//加载并返回动态链接器代码段地址
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias);
//计算动态链接器入口地址
elf_entry += loc->interp_elf_ex.e_entry;
} else {
elf_entry = loc->elf_ex.e_entry;
}
//跳转到入口开始执行
start_thread(regs, elf_entry, bprm->p);
...
}
五、总结
看起来简简单单的一行 helloworld 代码,但是要想把它运行过程理解清楚可却需要非常深厚的内功的。
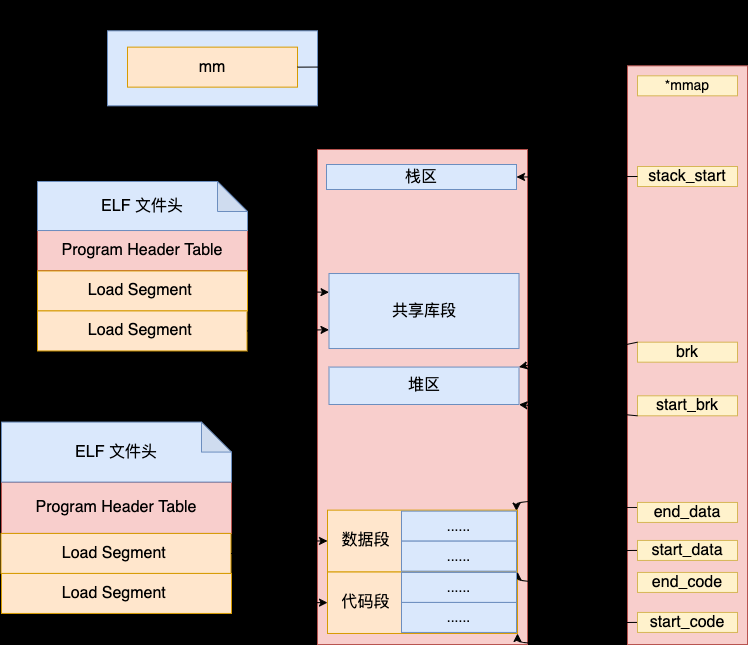
本文首先带领大家认识和理解了二进制可运行 ELF 文件格式。在 ELF 文件中是由四部分组成,分别是 ELF 文件头 (ELF header)、Program header table、Section 和 Section header table。
Linux 在初始化的时候,会将所有支持的加载器都注册到一个全局链表中。对于 ELF 文件来说,它的加载器在内核中的定义为 elf_format,其二进制加载入口是 load_elf_binary 函数。
一般来说 shell 进程是通过 fork + execve 来加载并运行新进程的。执行 fork 系统调用的作用是创建一个新进程出来。不过 fork 创建出来的新进程的代码、数据都还是和原来的 shell 进程的内容一模一样。要想实现加载并运行另外一个程序,那还需要使用到 execve 系统调用。
在 execve 系统调用中,首先会申请一个 linux_binprm 对象。在初始化 linux_binprm 的过程中,会申请一个全新的 mm_struct 对象,准备留着给新进程使用。还会给新进程的栈准备一页(4KB)的虚拟内存。还会读取可执行文件的前 128 字节。
接下来就是调用 ELF 加载器的 load_elf_binary 函数进行实际的加载。大致会执行如下几个步骤:
- ELF 文件头解析
- Program Header 读取
- 清空父进程继承来的资源,使用新的 mm_struct 以及新的栈
- 执行 Segment 加载,将 ELF 文件中的 LOAD 类型的 Segment 都加载到虚拟内存中
- 为数据 Segment 申请内存,并将堆的起始指针进行初始化
- 最后计算并跳转到程序入口执行
当用户进程启动起来以后,我们可以通过 proc 伪文件来查看进程中的各个 Segment。
# cat /proc/46276/maps
00400000-00401000 r--p 00000000 fd:01 396999 /root/work_temp/helloworld
00401000-00402000 r-xp 00001000 fd:01 396999 /root/work_temp/helloworld
00402000-00403000 r--p 00002000 fd:01 396999 /root/work_temp/helloworld
00403000-00404000 r--p 00002000 fd:01 396999 /root/work_temp/helloworld
00404000-00405000 rw-p 00003000 fd:01 396999 /root/work_temp/helloworld
01dc9000-01dea000 rw-p 00000000 00:00 0 [heap]
7f0122fbf000-7f0122fc1000 rw-p 00000000 00:00 0
7f0122fc1000-7f0122fe7000 r--p 00000000 fd:01 1182071 /usr/lib64/libc-2.32.so
7f0122fe7000-7f0123136000 r-xp 00026000 fd:01 1182071 /usr/lib64/libc-2.32.so
......
7f01231c0000-7f01231c1000 r--p 0002a000 fd:01 1182554 /usr/lib64/ld-2.32.so
7f01231c1000-7f01231c3000 rw-p 0002b000 fd:01 1182554 /usr/lib64/ld-2.32.so
7ffdf0590000-7ffdf05b1000 rw-p 00000000 00:00 0 [stack]
......
虽然本文非常的长,但仍然其实只把大体的加载启动过程串了一下。如果你日后在工作学习中遇到想搞清楚的问题,可以顺着本文的思路去到源码中寻找具体的问题,进而帮助你找到工作中的问题的解。
最后提一下,细心的读者可能发现了,本文的实例中加载新程序运行的过程中其实有一些浪费,fork 系统调用首先将父进程的很多信息拷贝了一遍,而 execve 加载可执行程序的时候又是重新赋值的。所以在实际的 shell 程序中,一般使用的是 vfork。其工作原理基本和 fork 一致,但区别是会少拷贝一些在 execve 系统调用中用不到的信息,进而提高加载性能。
- 相关推荐
- 热点推荐
- Linux
- 代码
- helloworld
-
Linux 下交叉编译实战:跑起来你的第一个 STM32 程序2025-11-24 1431
-
智能车浅谈——手把手让车跑起来(电磁篇)2025-05-22 3483
-
MotorControl Workbench生成的代码是开环的吗,为什么电机跑起来很容易受到外力导致停机?2024-03-21 490
-
STM32如何区分程序跑起来用的是HSE还是HSI呢?2023-05-05 1405
-
你写的代码是如何跑起来的?2022-12-08 1743
-
如何让你的ESP32跑起来呢2022-02-10 1738
-
如何让u-boot跑起来?2022-01-26 1865
-
程序能跑起来就是很好的c代码吗2021-11-23 1074
-
怎样让自己编译的uboot跑起来2021-11-08 1078
-
如何让你的ESP32跑起来2021-07-16 1811
-
windows安装ubuntu并让pioneer1应用程序跑起来的过程2020-10-23 3427
-
FreeRTOS_003 _让系统在板子上跑起来2020-03-14 4045
-
Zynq 7015 linux跑起来之导入之BOOT.bin生成详解2018-06-27 8764
-
请问HVMotorCtrl+PfcKit_v1.7/HVPM_sensorless_2833x代码能不能让电机跑起来?需要修改哪些参数?2018-06-13 4196
全部0条评论

快来发表一下你的评论吧 !
