

VirtIO Networking虚拟网络设备实现架构
描述
VirtIO
VirtIO 由 Rusty Russell 开发,最初是为了支持自己开发的 lguest Hypervisor,其设计目标是在虚拟化环境下提供与物理设备相近的 I/O 功能和性能,并且避免在虚拟机中安装额外的驱动程序。基于这一目标,后来通过开源的方式将 VirtIO 延伸为一种虚拟化设备接口标准,并广泛地支持 KVM、QEMU、Xen 和 VMware 等虚拟化解决方案。
为了追求更高的性能和更低的开销表现,VirtIO 采用了 Para-virtualizaiton(半虚拟化/准虚拟化)技术路线,本质区别于性能低下的 Full-virtualizaiton(e.g. QEMU I/O Emulation)。这也意味着使用 VirtIO 的 GuestOS 需要经过一定的代码修改(安装非原生的 Device Driver),这也是为什么需要将 VirtIO 定位于 “虚拟化设备接口标准“ 的原因,其整体的集成架构需要由 Front-end(GuestOS Kernel Device Driver)和 Back-end(VMM Provider)共同遵守统一的传输协议。
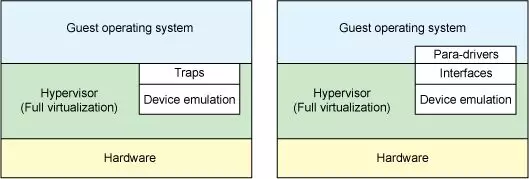
在应用 VirtIO 的场景中,除了 GuestOS 需要安装额外的 VirtIO Front-end Device Driver 这一点不足之外(通常在制作 QCOW2 镜像时会安装好),相对地带来了下列诸多好处:
高性能:VirtIO 省去了 Full-virtualizaiton 模式下的 Traps(操作捕获)环节,GuestOS 通过 VirtIO Interfaces 可以直接与 Hypervisor 中的 Device Emulation 进行交互。
低开销:VirtIO 优化了 CPU 在内核态和用户态之间频繁切换,以及 CPU 在 VM Exit 和 VM Entry 之间频繁陷入陷出所带来的性能开销。
标准化:VirtIO 实现了统一的虚拟设备接口标准,可以应用在多种虚拟化解决方案中。
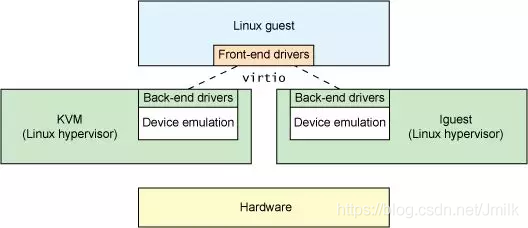
VirtIO 虚拟设备接口标准
为了抑制 Para-virtualizaiton 所具有的跨平台兼容性缺点,VirtIO 明智地走上了开源之路,通过构建标准而统一的生态来争取最小化的兼容性排斥问题,反而让其逆转成为了一种优势。
在 VirtIO 提出的虚拟化设备接口标准中,包括多个子系统,每个子系统都定义了一组虚拟设备类型和协议。例如:
VirtIO-Block(块设备):提供虚拟磁盘设备的接口。
VirtIO-Net(网络设备):提供虚拟网络设备的接口。
VirtIO-Serial(串口设备):提供虚拟串口设备的接口。
VirtIO-Memory(内存设备):提供虚拟内存设备的接口。
VirtIO-Input(输入设备):提供虚拟输入设备的接口。
此外还有 VirtIO-SCSI、VirtIO-NVMe、VirtIO-GPU、VirtIO-FS、VirtIO-VSock 等等虚拟设备类型和协议。
VirtIO 的前后端分层架构
VirtIO 虚拟设备接口标准的分层软件架构如下图所示:
Front-end:是一组通用的,安装在 GuestOS Kernel 中的 VirtIO Device Driver,通过 Hyper-call 的方式对 Back-end 进行调用。
Back-end:是一组 Hypervisor 专用的,运行在 VMM 中的设备模拟程序,提供了 Hyper-call 调用接口。
Transport:是一组标准的传输层接口,基于环形队列的方式来批量处理 I/O 请求。
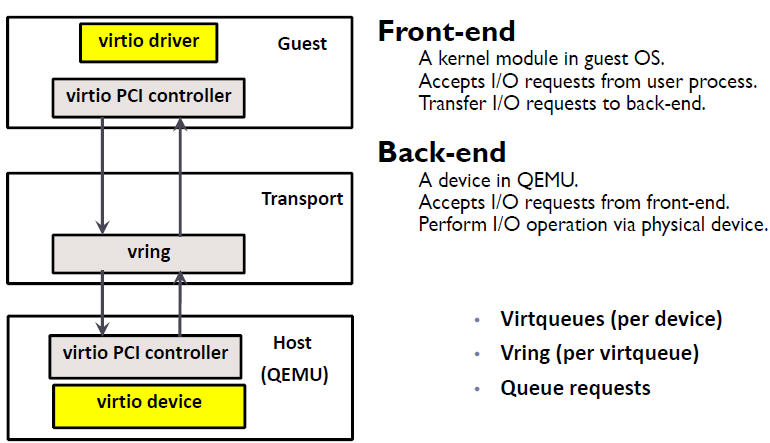
VirtIO 的数控路径分离架构
VirtIO 还定义了 “控制路径” 和 “数据路径” 的分离架构,两者的侧重各有不同,控制平面追求尽可能的灵活以兼容不用的设备和厂商,而数据平面则追求更高的转发效率以快速的交换数据包。
控制路径:控制建立或删除 Front-end 和 Back-end 之间的数据路径,提供可管理的灵活性。
数据路径:在 Front-end 和 Back-end 之间进行数据传输,追求性能。
对应地,VirtIO 标准也可以分为两个部分:
VirtIO Spec:定义了如何在 Front-end 和 Back-end 之间构建控制路径和数据路径的标准,例如:数据路径规定采用环形队列缓冲区布局。
Vhost Protocol:定义了如何降数据路径的高性能实现标准,例如:基于 Kernel、DPDK、SmartNIC Offloading 的实现方式。
以 QEMU 为例,其根据 VirtIO Spec 实现了控制路径,而数据路径则可以 Bypass QEMU,使用 vhost-net、vhost-user 等实现。
VirtIO Networking
VirtIO Networking 是一种高功能、高性能、可扩展的虚拟化网络设备,支持多种网络功能和虚拟网络技术,并可以通过多种实现方式进行部署。
网络功能:MAC 地址、流量限制、流量过滤、多队列收发等;
虚拟网络技术:VLAN、GRE、VXLAN 等;
多种实现方式:Kernel、DPDK、硬件网卡等。
virtio-net Driver 和 virtio-net Device(由 QEMU 模拟的后端)
virtio-net 是 VirtIO Networking 的默认实现。其中,Front-end 是 virtio-net Driver(虚拟网卡驱动程序);Back-end 是由 QEMU 软件模拟的 virtio-net Device。
QEMU 会在 VM 启动时,为 VM 创建好相应的 virtio-net Device(虚拟设备),并在 VM 启动后,通过在 GuestOS Kernel 中安装的 virtio-net Driver 来 Probe(探知)到该 virtio-net Device。
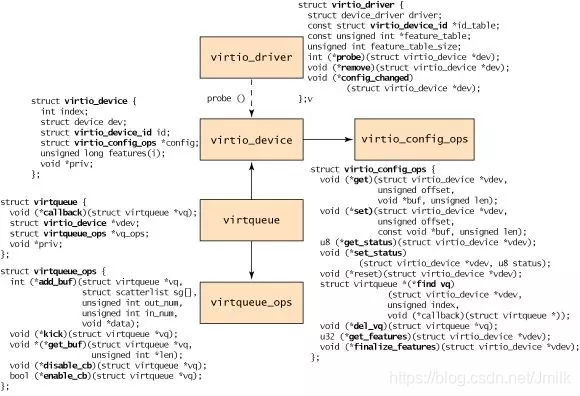
virtio-net Driver 和 virtio-net Device 的软件架构如下图所示,我们需要关注 3 个方面:
Control Plane:virtio-net Driver 和 virtio-net Device 之间使用了 PCI 传输协议,如下图中蓝线部分。
Data Plane:virtio-net Driver 和 virtio-net Device 之间使用了 Virtqueues 和 Vrings,如下图中红虚线部分。而 virtio-net Device 和 Kernel Network Stack 之间使用了 Tap 虚拟网卡设备,作为 User space(QEMU)和 Kernel space(Network Stack)之间的数据传输通道,如下图中红实线部分。
Notification:作为 virtio-net Driver、virtio-net Device 和 KVM 之间交互方式,用于实现 “vCPU 硬中断“ 的功能。
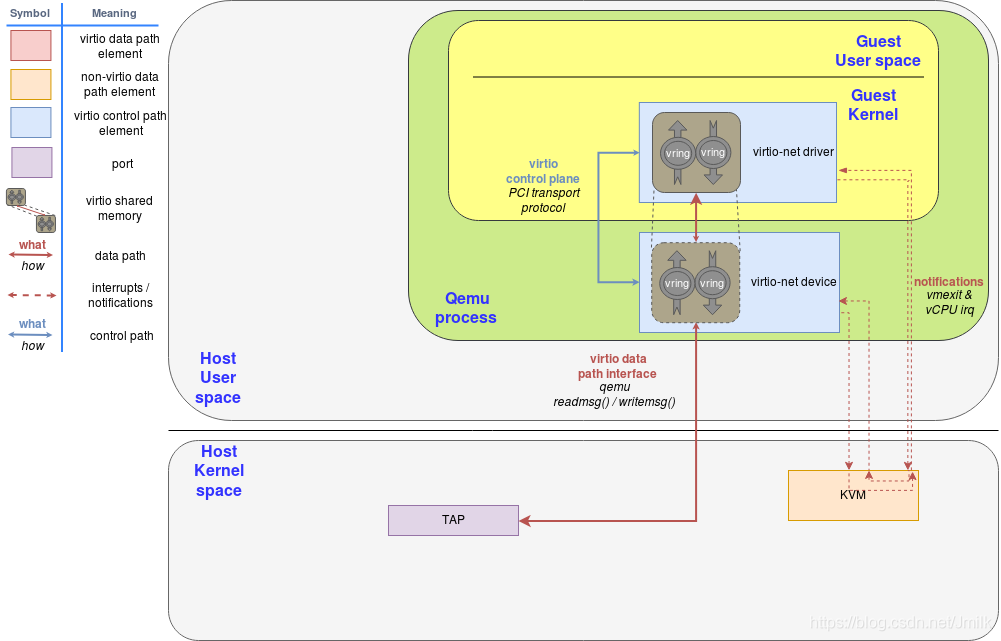
其中值得细究的就是 virtio-net Driver 和 virtio-net Device 之间的 Transport(传输层)实现。virtio-net Transport 采用了非常类似于物理网卡设备(NIC Rx/Tx Queues 和 Kernel Rx/Tx Rings)的设计思路。
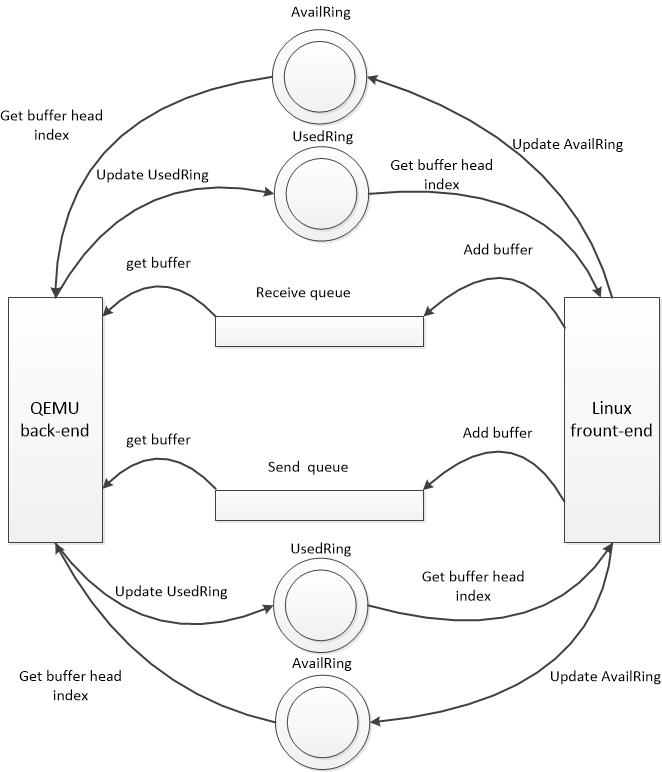
Front-end 和 Back-end 之间存在 2 个 Virtqueues,对应到 NIC 的 Rx/Tx Queues。Virtqueues 的底层利用了 IPC 共享内存技术,在 HostOS 和 GuestOS 之间建立直接的传输通道,绕开了 VMM 的低效处理。
Receive Queue:是一块 Buffer 内存空间,存放具体的由 Back-end 发送到 Front-end 数据。
Send Queue:是一块 Buffer 内存空间,存放具体的由 Front-end 发送到 Back-end 数据。
同时,每个 Virtqueue 都具有 2 个 Vrings,对应到 Kernel 的 Rx/Tx Rings:
Available Ring:存放 Front-end 向 Back-end 发送的 Queue 中可用的 Buffer 内存地址。
Used Ring:存放 Back-end 向 Front-end 发送的 Queue 中已使用的 Buffer 内存地址。
当然,Front-end 和 Back-end 之间还需要一种双向通知机制,对应到 NIC 和 CPU 之间的硬中断信号:
Available Buffer Notification:Front-end 使用此信号通知 Back-end 存在待处理的缓冲区。
Used Buffer Notification:Back-end 使用此信号标志已完成处理某些缓冲区。
具体的,当 GuestOS 发送数据时,Front-end 将数据填充到 Send Queue 内存空间,然后将地址记录到 Available Ring,并在适当的时候向 Back-end 发送 Available Buffer Notification;QEMU 接收到通知后,从 Available Ring 中获取到数据的数据,完成数据接收,然后记录 New Buffer Head Index 到 Used Ring,并在适当的时候向 Front-end 发送一个 Used Buffer Notification。Front-end 接收到通知后释放对应的 Send Queue 内存空间,Available Ring 指针指向下一位。
当 GuestOS 接收数据时,Front-end 首先分配好 NULL 的 Receive Queue 内存空间,然后将地址记录到 Available Ring,并在适当的时候向 Back-end 发送 Available Buffer Notification;QEMU 接收到通知后,从 Available Ring 中获取到数据填充入口地址,完成数据填充,然后记录 New Buffer Head Index 到 Used Ring,并在适当的时候向 Front-end 发送一个 Used Buffer Notification。Front-end 接收到通知后从 Receive Queue 中读取数据,Available Ring 指针指向下一位。
值得注意的是,在 PCI Passthrough 场景中,可以使用 virtio-pci(更多的是使用 VFIO)。虽然此时依旧会沿用了 Available/Used buffer notification 这一控制面的双向通知机制,但实际的数据面,则是由 DMA 和专用队列来完成的,具有更高的性能。这体现了数控分离带来的好处。
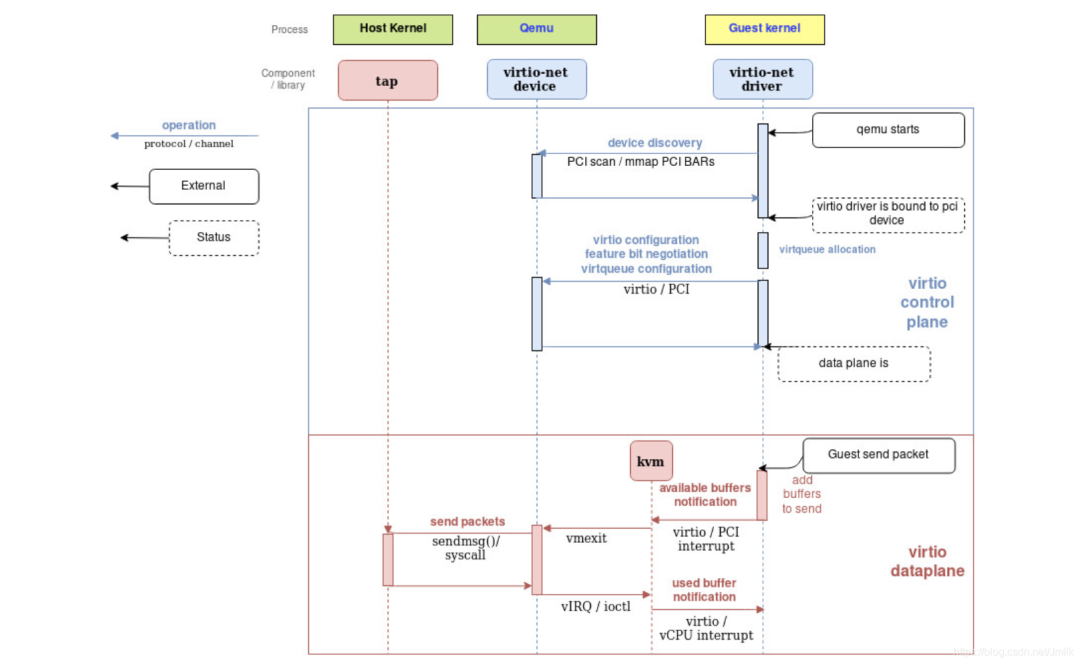
综上所述,下述流程图总结了 2 个关键流程:
virtio-net Device 初始化流程:包括 Device discovery 和 Device configuration。对于 virtio-net Driver 而言,virtio-net Device 就是一个 PCI 设备,遵守标准的 PCI 设备初始化流程,并且 Driver 和 Device 使用 PCI 协议进行通信。
virtio-net Driver 发包流程:
当 virtio-net Driver 发送数据包时,将数据包放入 Send Queue,将数据包的访问地址放入 Available Ring,触发一次 Available Buffer Notification 到 KVM,然后 VM Exit,由 QEMU 接管 CPU,执行 I/O 控制逻辑,将此数据包传递到 virtio-net Device,然后 virtio-net Device 降数据包通过 Tap 设备传入 Kernel Network Stack;
完成后,QEMU 将 New Buffer Head Index 放入到 Used Ring 中,同时 virtio-net Device 发出一个 vIRQ 中断注入到 KVM,然后 KVM 发出一个 Used Buffer Notification 到 virtio-net Driver,此时 virtio-net Driver 就会从 Used Ring 中取出 Buffer Head Index;
至此一次发送操作就完成了。
另外,由于 Tap 设备支持 Tx/Rx 多队列,所以实际上也会存在 N 个 Virtqueues Peer 进行一一映射。
vhost-net(由 Kernel 提供的后端)
由 QEMU 模拟的 virtio-net Device 显然性能不佳,具有频繁的模式和上下文切换、低效的数据拷贝、线程间同步等性能问题。于是,VirtIO 社区在 Kernel 中实现了一个新的 vhost-net 后端,以解决上述问题。
更低的延迟(latency):比普通 virtio-net 低 10%。
更高的吞吐量(throughput):比普通 virtio-net 高 8 倍,达到 7~8 Gigabits/Sec。
vhost-net 的核心思想就是将 Data Path Bypass QEMU,定义了一种新的 Data Path 传输方式,使得 GuestOS virtio-net Driver 和 HostOS Kernel vhost-net 可以直接通信。如下图所示:
Control Plane:virtio-net Driver 和 virtio-net Device 之间使用了 PCI 传输协议,virtio-net Device 和 vhost-net 之间使用 ioctl() 接口,如下图中蓝线部分。
Data Plane:virtio-net Driver 和 vhost-net 直通,如下图中虚线部分。而 vhost-net 和 Kernel Network Stack 之间使用了 Tap 虚拟网卡设备连接,如下图中红实线部分。
Notification:作为 virtio-net Driver、vhost-net 和 KVM 之间交互方式,用于实现 “vCPU 硬中断“ 的功能。
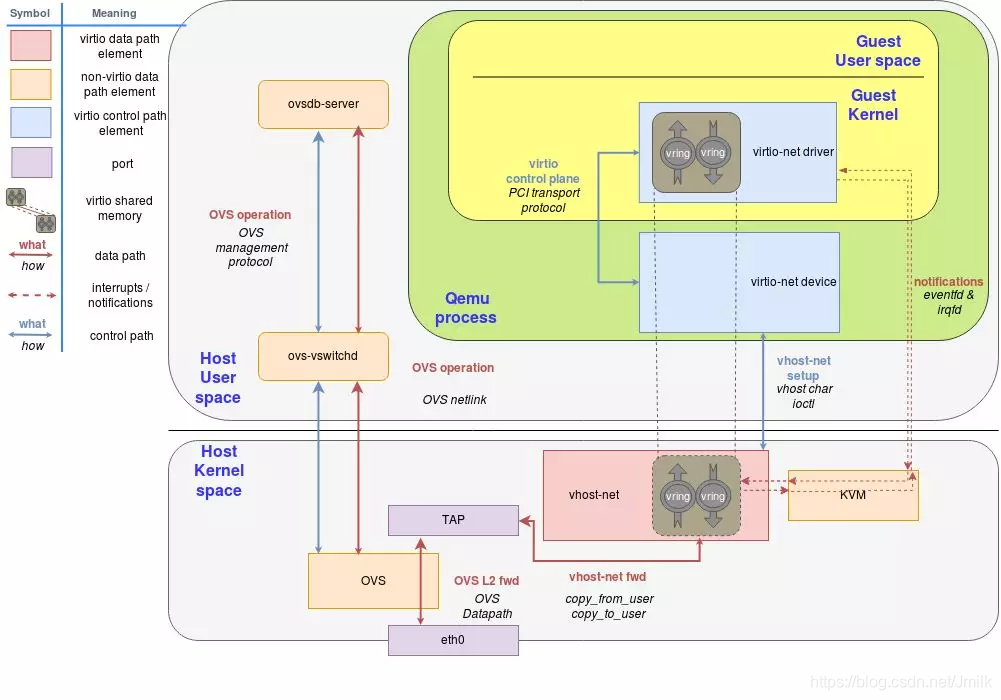
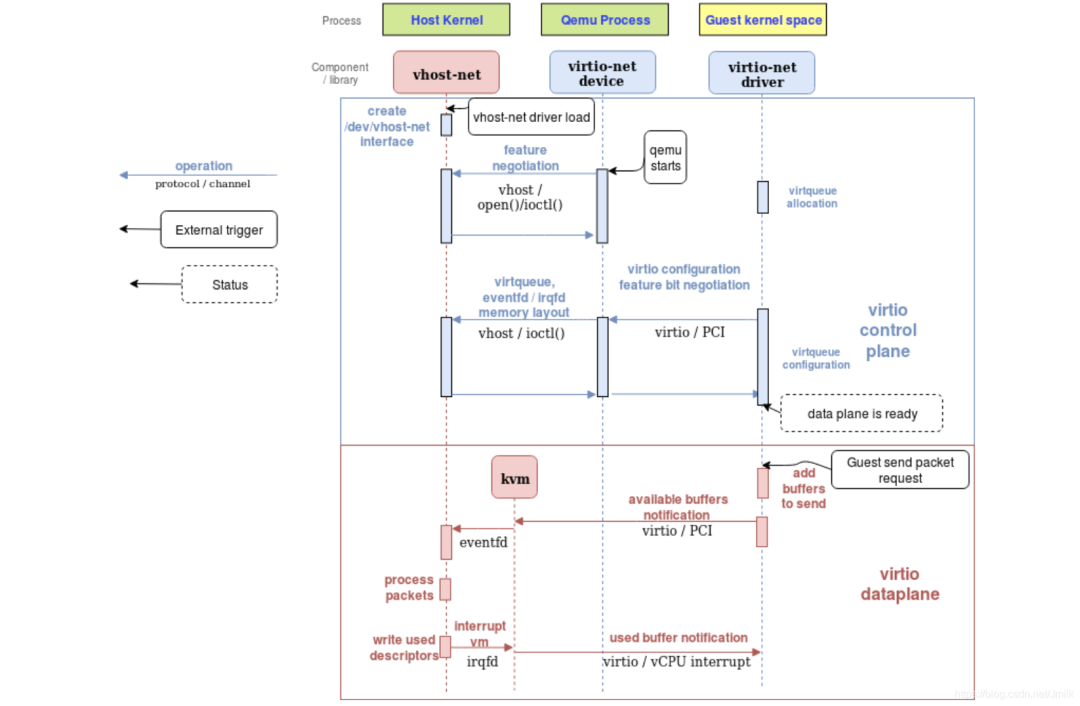
vhost-net 的本质是一个 HostOS Kernel Module,实现了 vhost-net Protocol 标准,当 Kernel 加载 vhost-net 后,会暴露一个设备接口文件 /dev/vhost-net。
当 QEMU 在 vhost-net 模式下启动时,QEMU(virtio-net Device)首先会 open() 该文件,并通过 ioctl() 与 vhost-net 进行交互,继而完成 vhost-net 实例的 Setup(初始化)。初始化的核心是建立 virtio-net Driver 和 vhost-net 之间的 Data Path 以及 Notification,包括:
Hypervisor Memory Layout(虚拟化内存布局):用于 Data Path 传输,让 vhost-net 可以在 KVM 的内存空间中找到特定 VM 的 Virtqueues 和 Vrings 的地址空间。
ioeventfd 和 irqfd(文件描述符):用于 Notification 传输,让 vhost-net 和 KVM 之间可以在 Kernel space 中完成 Notification 的直接交互,不再需要通过 User space 中的 QEMU。
同时,在 vhost-net 实例初始化的过程中,vhost-net 会创建一个 Kernel Thread(vhost worker thread),名为 vhost-$pid(pid 是 QEMU 进程 PID),QEMU 进程就和 vhost-net 实例以此建立了联系。vhost worker thread 用于处理 I/O Event(异步 I/O 模式),包括:
使用 ioeventfd 轮询 Tap 事件和 Notify 事件,并转发数据。
使用 irqfd 允许 vhost-net/KVM 通过对其进行写入来将 vCPU 的 vIRQ 注入到 virtio-net Driver。
综上,在 vhost-net 实例初始化完成之后,virtio-net Device 将不再负责数据包的处理(对 Virtqueues 和 Vrings 的读/写操作),取而代之的是 vhost-net。vhost-net 可以直接访问 VM 的 Virtqueues 和 Vrings 内存空间,也可以通过 KVM 与 virtio-net Driver 进行 Notification 交互。
最后需要注意的是,vhost-net 在某些应用场景中的性能未必就会比 virtio-net Device 更好。例如:从 HostOS 传输到 GuestOS 的 UDP 流量,如果 GuestOS 接受 UDP 数据包的速度比 HostOS 发送的速度要慢,在这种情况下使用 vhost-net 将会导致 GuestOS UDP Socket Receive Buffer 更容易溢出,导致丢包,继而使得 GuestOS 的整体性能出现下降。此时使用慢速的 virtio-net,让 HostOS 和 GuestOS 之间的传输速度稍微慢一点,反而会提高整体的性能。
可见,在虚拟机场景中,全链路的性能均衡需要给予更加全面的考虑。
vhost-user(由 DPDK 实现的用户态后端)
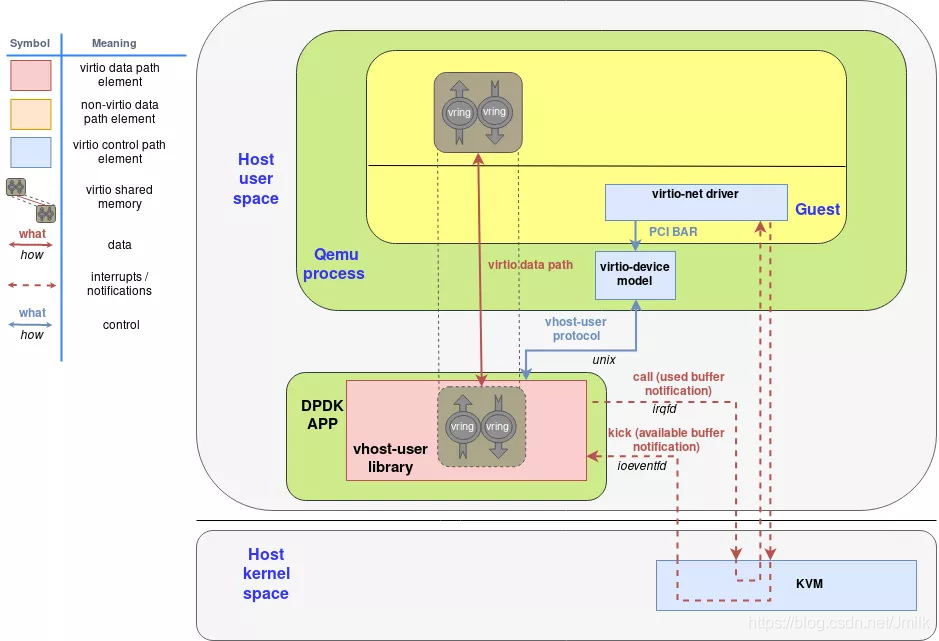
vhost-user 是一个基于 DPDK vhost-user Library 开发的后端,运行在 User space,应用了 DPDK 所提供的 CPU 亲和性,大页内存,轮询模式驱动等数据面转发加速技术。
区别于 vhost-net Protocol,vhost-user Library 实现了一种新的 vhost-user Protocol,两者间最大的区别体现在通信信道的实现方式上。
vhost-net:使用 /dev/vhost-net 字符设备和 ioctl() 实现了 User Process(QEMU)和 Kernel(vhost-net)之间的 Control Plane 通信信道。
vhost-user:使用 Unix Socket 实现了 User Process(QEMU 和 DPDK App)之间的 Control Plane 通信信道。
QEMU 通过 Unix Socket 来完成对 vhost-user 的 Data Plane 配置,包括:
特性协商配置:QEMU(virtio-net Device)与 vhost-user 协商两者间功能特性的交集,确认哪些功能特性是有效的。
内存区域配置:vhost-user 使用 mmap() 来映射分配给 QEMU 的内存区域,建立两者间的直接数据传输通道。
Virtqueues/Vrings 配置:QEMU 将 Virtqueues/Vrings 的数量和访问地址发送给 vhost-user,以便 vhost-user 访问。
Notification 配置:vhost-user 仍然使用 ioeventfd 和 irqfd 来完成和 KVM 之间的通知交互。
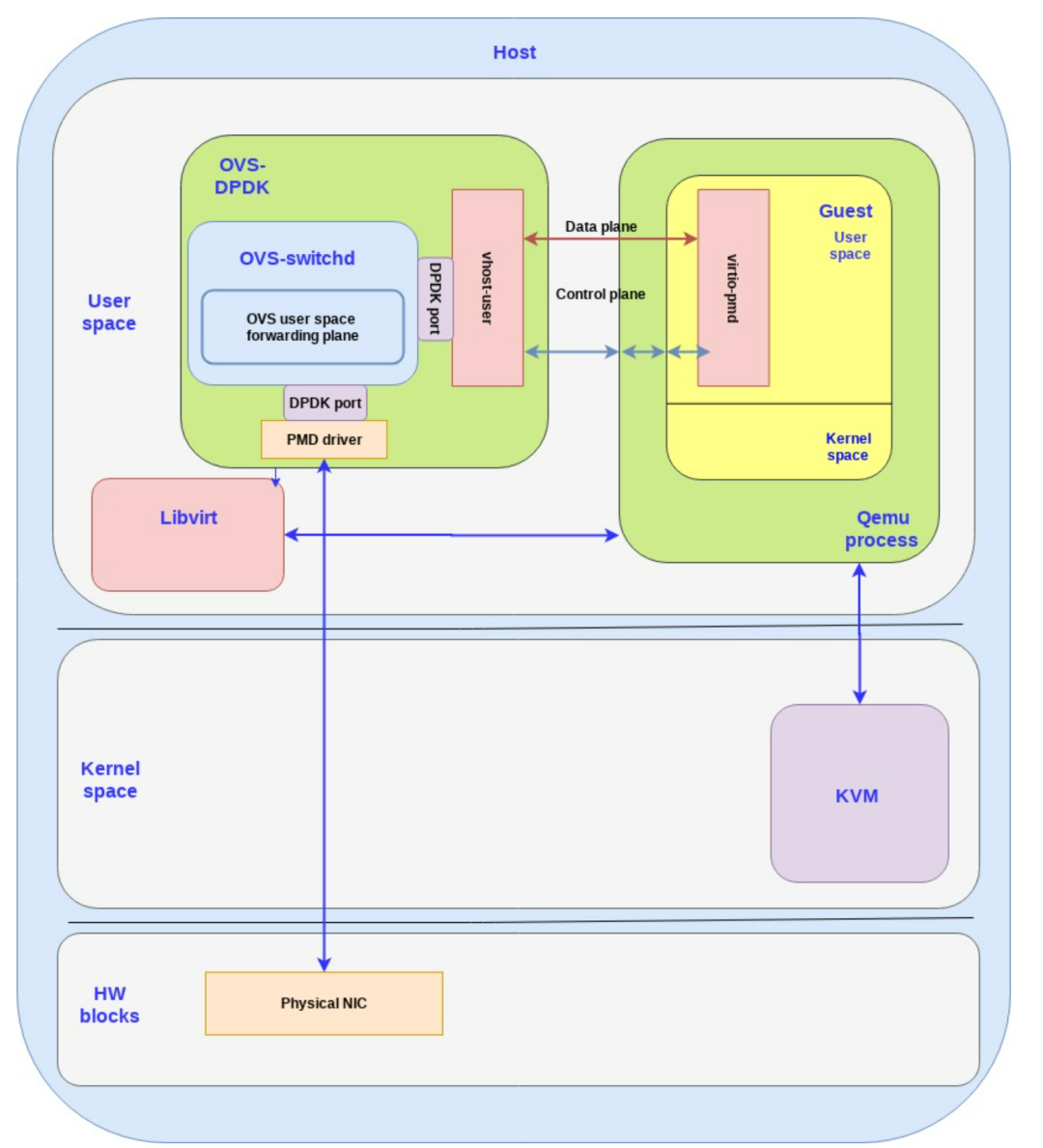
目前最常见的 vhost-user DPDK App 就是 OVS-DPDK,除了支持 vhost-user Back-end 之外,还支持 virtio-pmd Front-end。在追求极致性能的 vhost-user / virtio-pmd 架构中,HostOS User space 和 GuestOS User space 都运行着 DPDK。
用户可以自由选择创建 vhost-user 类型的 vSwitch Port(对应一个 vhost-user 实例)。如下图所示。
HW vDPA(使用硬件加速的后端)
目前性能最好的 Data Plane 无疑是 SR-IOV VF Passthrough,但原生的 SR-IOV 缺少控制面逻辑,在实际使用中多有不便。
HW vDPA(Hardware vhost Data Path Acceleration,硬件 vhost 数据面加速)就是一种使用 SR-IOV VF 来充当 Data Plane、使用 vDPA Framework 来充当控制面的软硬件融合加速技术,能够同时兼具软件的可管理性、灵活性以及硬件的高性能。同时也解决了 VF Passthrough 虚拟机不支持热迁移的难题。
NOTE:SW vDPA(e.g. vDPA on OVS-DPDK)不在本文讨论范围中。
下图中展示了 OVS-DPDK 和 HW vDPA 的性能对比。
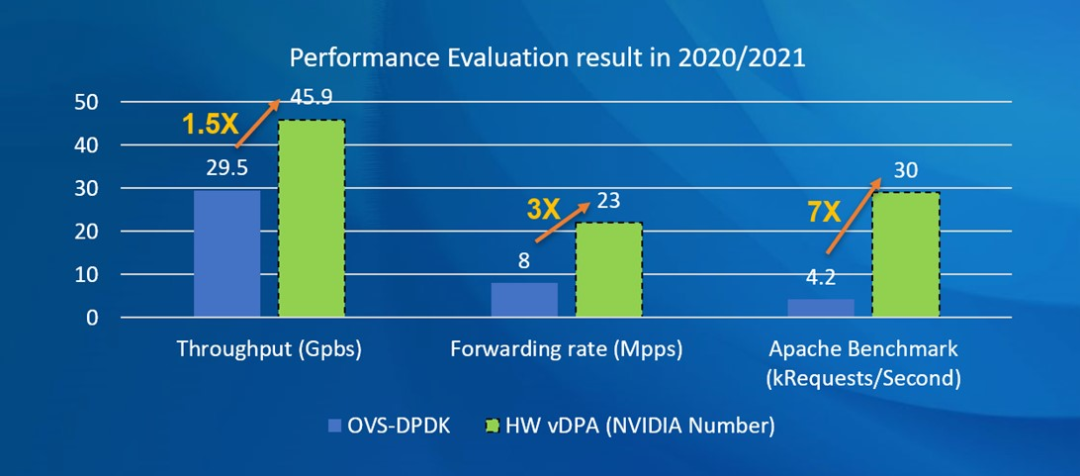
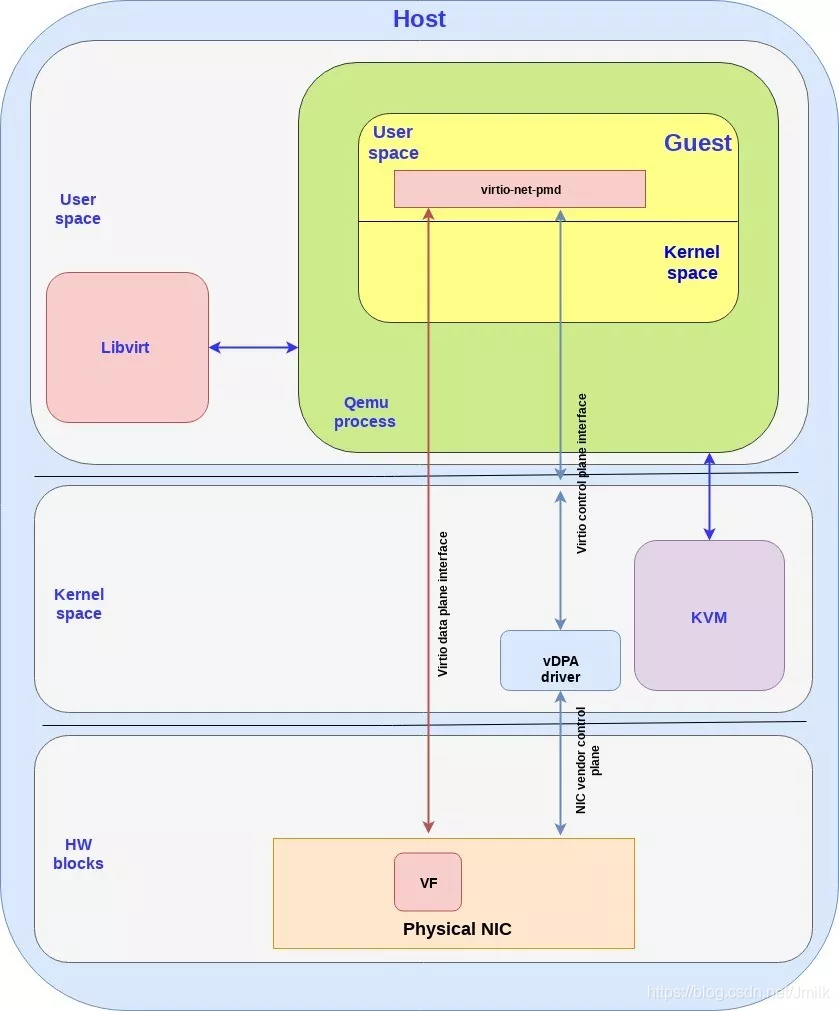
目前 vDPA Framework 的底层实现方式还尚未统一,从 QEMU 的角度来看,主要有 2 种方式:
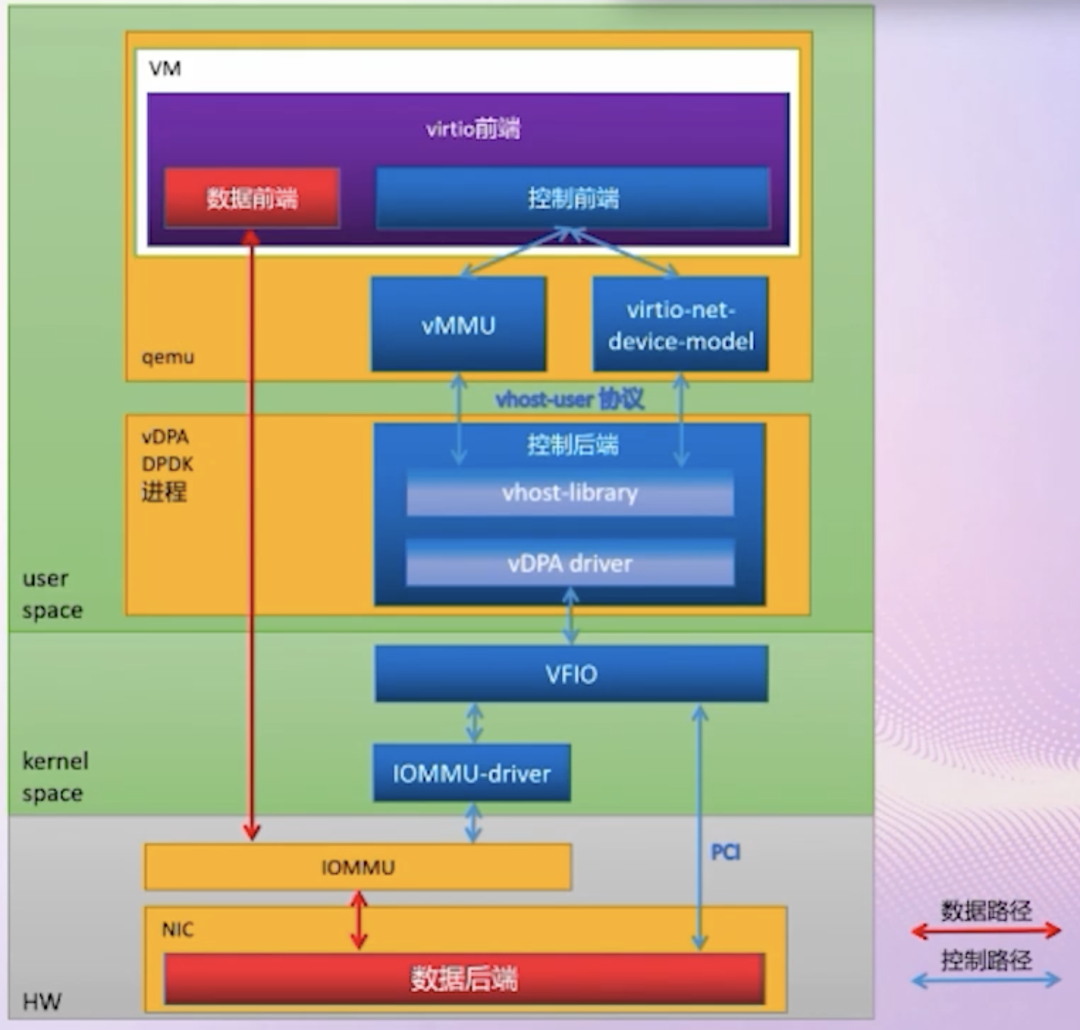
适应性更好的 vhost-user + vDPA Driver:在 DPDK vhost-user Library 的基础之上,再实现一个 vDPA Driver 适配层。由 vDPA Driver 完成与 HW Device(e.g. SmartNIC、DPU)之间的交互。从下图中可以看到 QEMU 与 HW 的 Control Plane 通过 vDPA driver 进行传递,并配置好 HW 与 VM 之间的 Passthrough Data Plane。目前 Mellanox MLX5 和 Intel IFC 对应的 vDPA Driver 都已经合入到 DPDK 和 Kernel 社区。(注:IOMMU/VFIO 实现原理请浏览《虚拟化技术 — 硬件辅助的虚拟化技术》。)
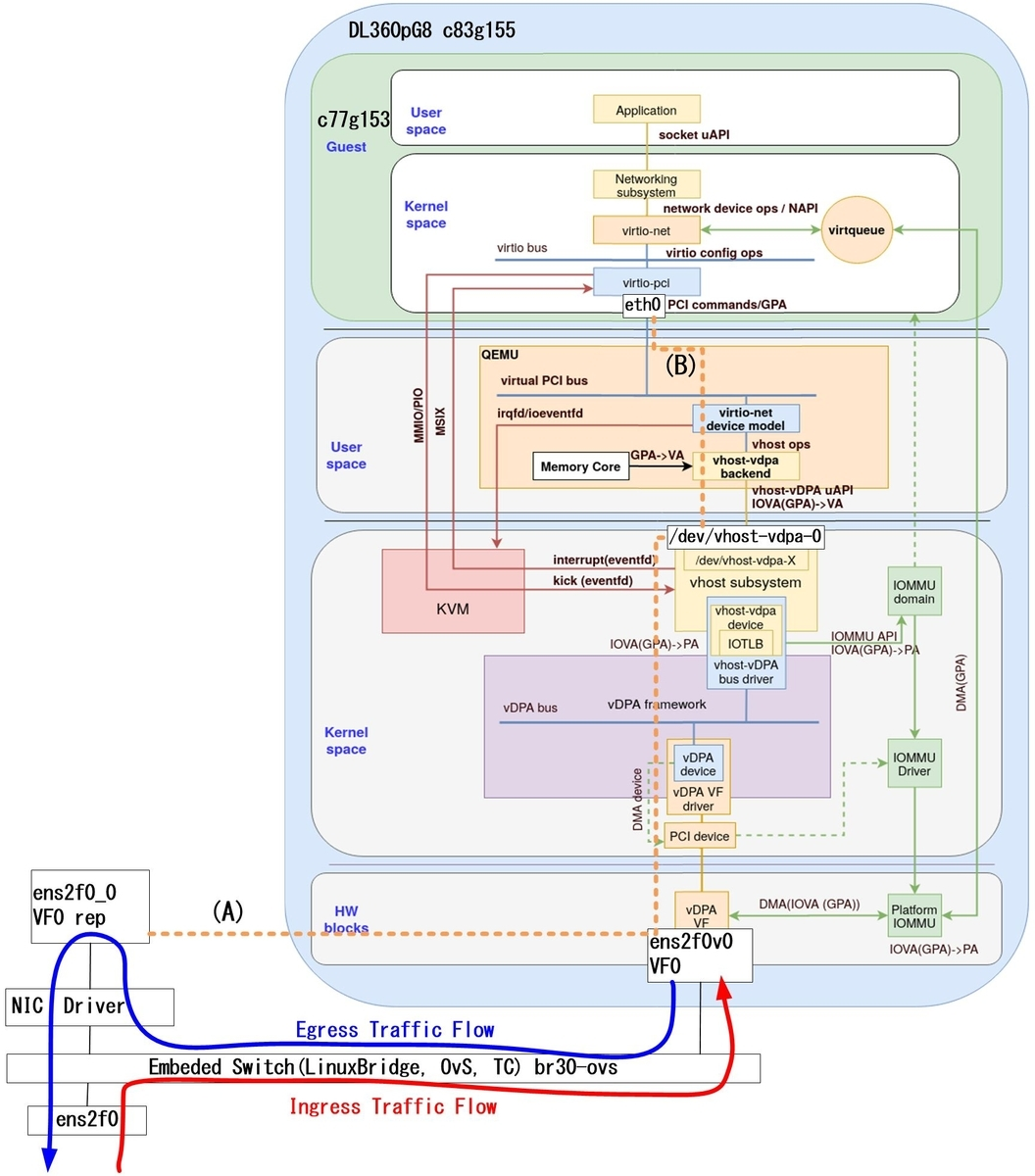
架构更合理的 vhost-vdpa:实现一种新的 vhost-vdpa Protocol,QEMU 通过 ioctl() 调用 Kernel 中的 vDPA Module,再由 vDPA Module 通过 vDPA Driver 完成与 HW Device 之间的交互。
目前,随着 SmartNIC / DPU 的快速发展,一种结合了 SW vDPA 和 HW vDPA 特性的 HW vDPA on OVS-DPDK 方案也逐渐成熟中,其实现会更加复杂、但功能也更加完备。值得期待。
审核编辑:刘清
-
使用Python批量连接华为网络设备2024-08-12 1748
-
适用于基于FPGA的网络设备的IEEE 1588透明时钟架构2023-11-23 2014
-
panabit加载virtio网卡驱动2023-11-17 2642
-
探究I/O虚拟化及Virtio接口技术(上)2023-04-04 5510
-
StratoVirt 中的虚拟网卡是如何实现的?2022-08-10 20929
-
StratoVirt 的 virtio-blk 设备是如何实现的?2022-06-29 1947
-
virtio I/O通信流程及设备框架的实现2022-03-10 8454
-
怎么实现智能网络设备开发中的硬件的设计?2021-05-26 978
-
系统虚拟化技术virtio总体设计思想2021-05-07 6036
-
linux设备中virtio组织关系及设备初始化调用流程2020-09-25 5992
-
Linux常用网络设备2019-07-25 1956
-
各类网络设备2017-11-29 3482
-
家用网络设备简介2009-08-05 1287
-
网络设备监管系统的设计与实现2009-06-23 939
全部0条评论

快来发表一下你的评论吧 !
