

ECS实例——Arm芯片的 Python-AI算力优化
描述
深度学习技术在图像识别、搜索推荐等领域得到了广泛应用。近年来各大 CPU 厂商也逐渐把 AI 算力纳入了重点发展方向,通过《Arm 芯片 Python-AI 算力优化》我们将看到龙蜥社区 Arm 架构 SIG(Special Interest Group) 利用最新的 Arm 指令集优化 Python-AI 推理 workload 的性能。
倚天 ECS 实例的 AI 推理软件优化
阿里云推出的倚天 Arm ECS 实例,拥有针对 AI 场景的推理加速能力,我们将了解加速的原理以及以及相关的软件生态适配。
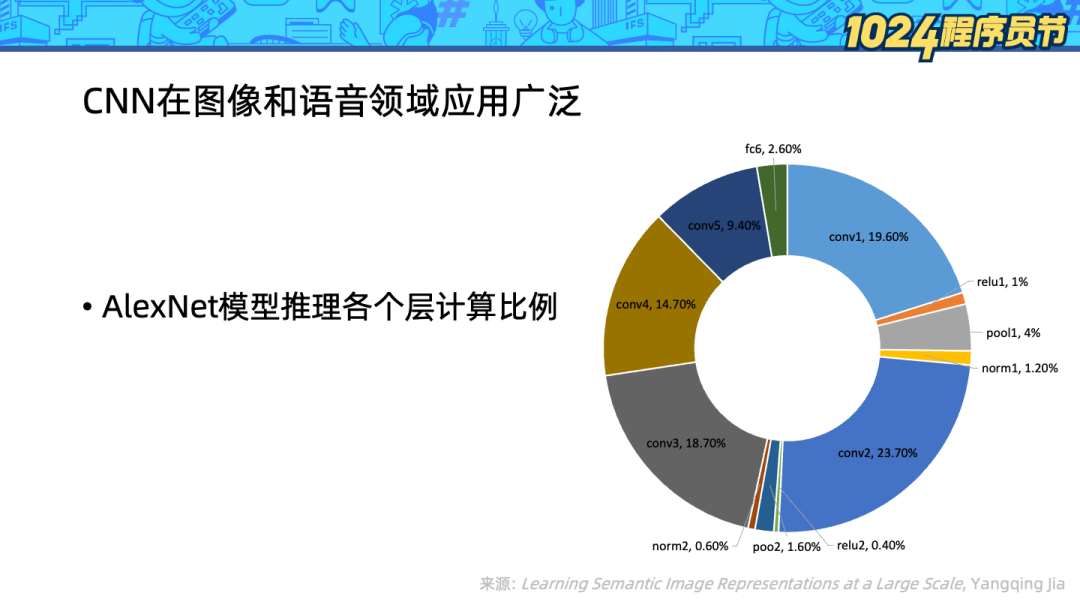
卷积神经网络(CNN)在图像和语音领域使用广泛,神经网络算法相比传统的算法消耗了更多算力。为了探索对计算的优化,我们进一步看到 AlexNet 模型(一种 CNN)的推理过程的各个层的计算资源消耗占比。
可以看到名为 conv[1-5] 的 5 个卷积层消耗了 90% 的计算资源,因此优化 CNN 推理的关键就是优化卷积层的计算。
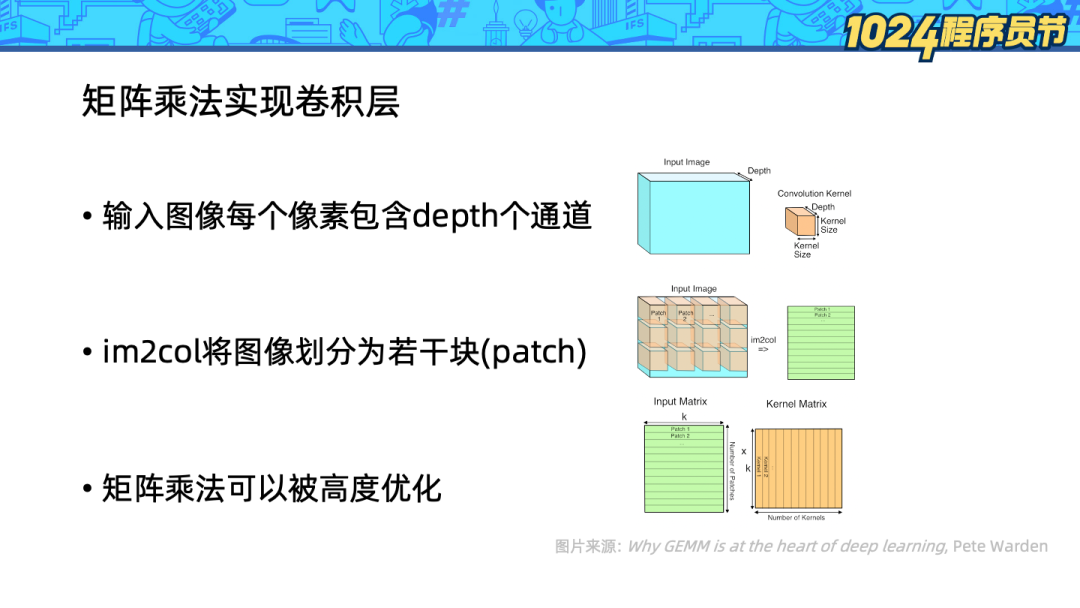
3、对由图像块组成的矩阵和由多个卷积核展开组成的矩阵应用矩阵乘法。

上面一页的计算应用了矩阵乘法操作,为什么我们不采用更加直接的迭代计算方式,而是采用需要额外内存的矩阵乘法呢?这里有两个关键因素:
-
深度学习的卷积计算量很大,典型计算需要涉及 5000 万次乘法和加法操作,因此对计算的优化十分重要。
-
计算机科学家们已经深入探索了矩阵乘法操作,矩阵乘法操作可以被优化得非常快。
在 fortran 世界中,GEMM(general matrix multiplication)已经成为一个通用操作: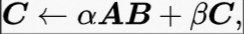 该操作通过对数据重新排列,精心设计计算过程,利用多线程和向量指令,可以比自己实现的朴素版本快十倍以上。因此使用矩阵运算带来的收益相比额外的开销是值得的。
该操作通过对数据重新排列,精心设计计算过程,利用多线程和向量指令,可以比自己实现的朴素版本快十倍以上。因此使用矩阵运算带来的收益相比额外的开销是值得的。
因为 AI 推理大量使用了矩阵乘法,如今也有许多硬件对矩阵运算进行了加速:
- NVIDIA Volta 架构引入了 tensor core,可以高效地以混合精度处理矩阵乘。
-
Intel AMX(Advanced Matrix Extensions) 通过脉动阵列在硬件层面支持矩阵乘。
-
Arm SME(Scalable Matrix Extension) 支持向量外积运算,加速矩阵乘。
虽然在 AI 算力上 GPU 要远高于 CPU,但是 CPU 因为其部署方便,且无需在主机-设备间拷贝内存,在 AI 推理场景占有一席之地。目前市面上尚没有可以大规模使用的支持 AMX 或者 SME 的硬件,在这个阶段我们应该如何优化 CPU 上的 AI 推理算力?我们首先要了解 BF16 数据类型。

BF16(Brain Float 16)是由 Google Brain 开发设计的 16 位浮点数格式。相比传统的 IEEE16 位浮点数,BF16 拥有和 IEEE 单精度浮点数(FP32)一样的取值范围,但是精度较差。研究人员发现,在 AI 训练和推理中,使用 BF16 可以节约一半的内存,获得和单精度浮点数接近的准确率。
根据右图,BF16 指数的位数和 FP32 是一致的,因此 BF16 和 FP32 的相互转换只要截断尾数即可,左下角图上便是 tensorflow 源码中的转换实现。
引入 BF16 的一大价值是如今的很多硬件计算的瓶颈在寄存器宽度或者访问内存的速度上,更紧凑的内存表示往往可以获得更高的计算吞吐,在理想情况下,BF16 相比 FP32 可以提高一倍的吞吐(FLOPS)。
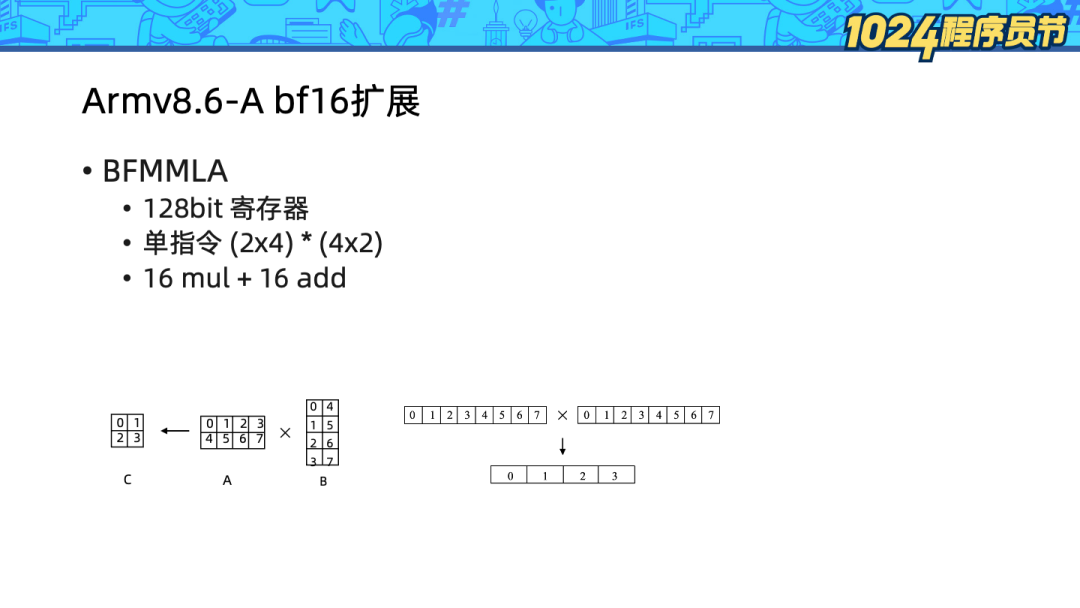
如今我们虽然无法大规模使用到支持 AMX/SME 的硬件,但是 Armv8.6-A 提供了 bf16 扩展,该扩展利用了有限的 128bit 向量寄存器,通过 BFMMLA 指令执行矩阵乘法运算:
-
输入 A:大小为 2*4 的 BF16 矩阵,按行存储。
-
输入 B:大小为 4*2 的 BF16 矩阵,按列存储。
-
输出 C:大小为 2*2 的 FP32 矩阵。
该指令单次执行进行了 16 次浮点数乘法和 16 次浮点数加法运算,计算吞吐非常高。
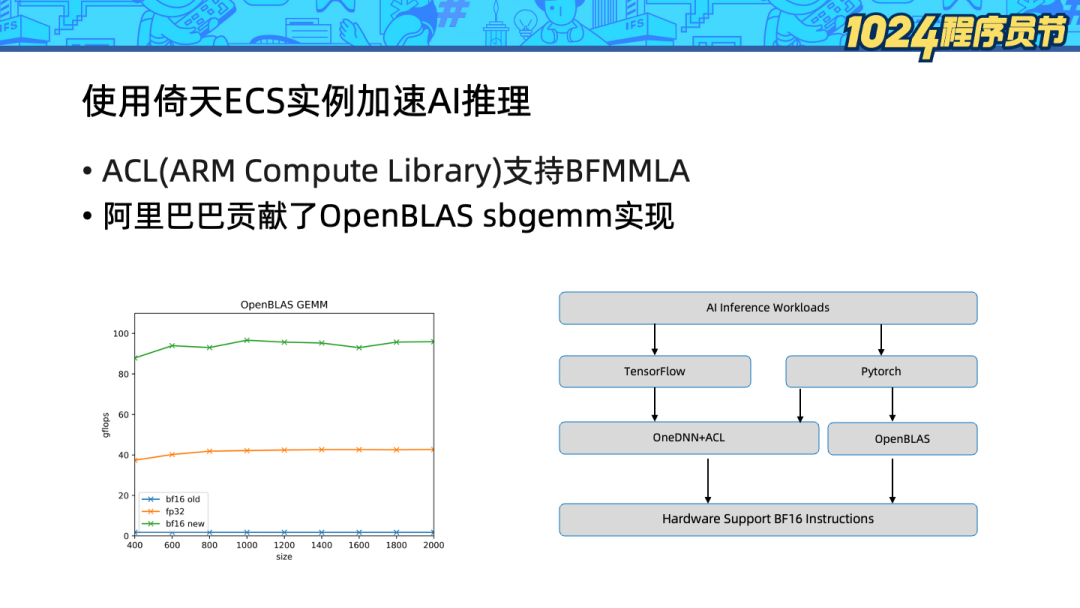
阿里巴巴向 OpenBLAS 项目贡献了 sbgemm(s 表示返回单精度,b 表示输入 bf16)的硬件加速实现,从 GEMM 吞吐上看,BF16 相比 FP32 GEMM 吞吐提升超过100%。
倚天 ECS 实例是市面上少数可以支持 bf16 指令扩展的 Arm 服务器。目前已经支持了 Tensorflow 和 Pytorch 两种框架的 AI 推理:
-
Tensorflow下可以通过OneDNN + ACL(Arm Compute Library)来使用 BFMMLA 加速。
-
Pytorch 已经支持了 OneDNN + ACL,但是目前还在试验状态,无法很好地发挥性能。但是 Pytorch 同时支持 OpenBLAS 作为其计算后端,因此可以通过 OpenBLAS 来享受 ARM bf16 扩展带来的性能收益。

可以看到相比默认的 eigen 实现,开启 OneDNN + ACL 后,perf 获得的计算热点已经从 fmla(向量乘加)转换到了 bfmmla,算力显著提升。
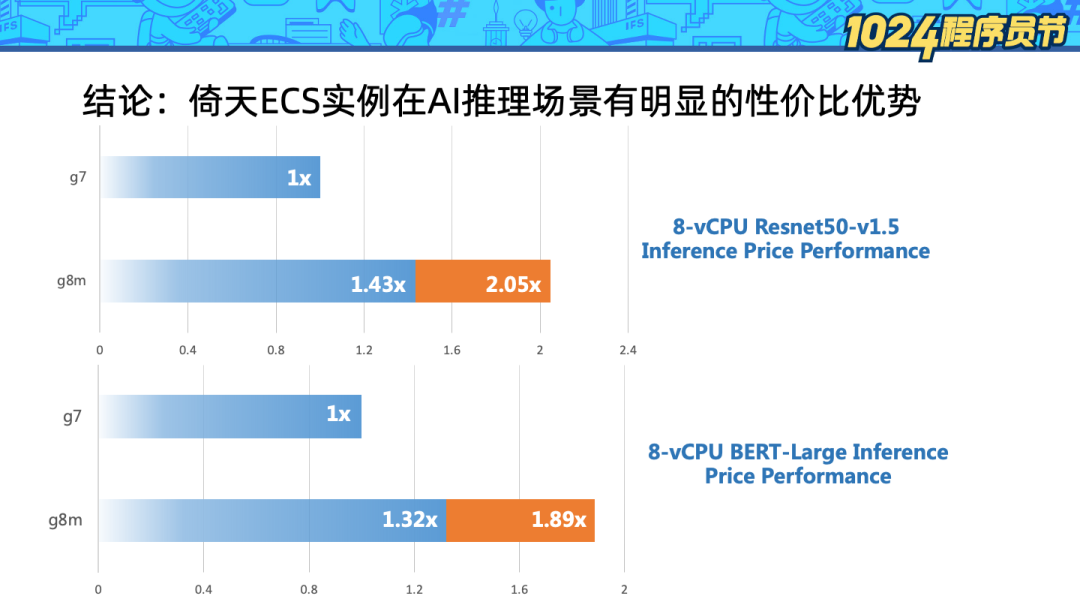
从 workload 角度评测,上图对比了两种机型:
-
g7:Intel IceLake 实例。
-
g8m:倚天 Arm 服务器。
左边柱状图中蓝色柱子表示算力对比,橙色柱子表示考虑性价比后使用倚天处理器获得的收益。可以看到在 Resnet50 和 BERT-Large 模型的推理场景下,软件优化后的倚天处理器皆可获得一倍左右的性价比收益。

在上文中,我们看到使用倚天处理器若想获得较高收益,软件版本的选择十分重要。随意选择 tensorflow 或者 Pytorch 包可能遭遇:
- 未适配 Arm 架构,安装失败。
- 软件未适配 bf16 扩展或者环境参数有误,无法发挥硬件的全部算力,性能打折。
-
需要精心选择计算后端,例如目前 Pytorch 下 OpenBLAS 较快。
因此我们提供了 Docker 镜像,帮助云上的用户充分使用倚天 710 处理器的 AI 推理性能:
-
accc-registry.cn-hangzhou.cr.aliyuncs.com/tensorflow/tensorflow
- accc-registry.cn-hangzhou.cr.aliyuncs.com/pytorch/pytorch
通过 Serverless 能力充分释放算力
除了使能更多的硬件指令,另一种充分释放硬件算力的方式就是通过 Serverless 架构提高 CPU 利用率。Python 作为动态语言,其模块是动态导入的,因此启动速度不是 Python 的强项,这也制约了 Python workload 在 Serverless 场景的普及。

3、执行代码对象。
其中的第二步在首次加载模块时,要对 .py 文件进行编译,获得 code_object, 为了降低将来加载的开销,Python 解释器会序列化并缓存 code_object 到 .pyc 文件。
即便模块导入过程已经通过缓存机制优化过了,但是读取 .pyc 文件并反序列化依旧比较耗时。
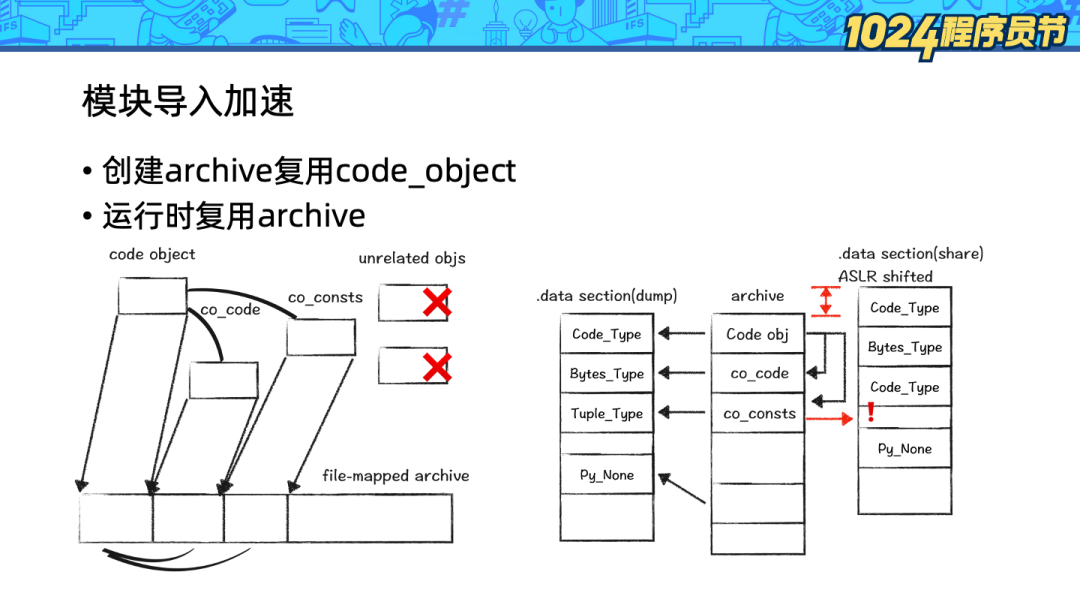
在这里我们借助了 OpenJDK 的 AppCDS 的思路:将 heap 上的 code_object 复制到内存映射文件中(mmap)。在下次加载模块时,直接使用 mmap 中的 code_object。
这种框架下有两个难点:
1、Python 的 code_object 是散落在 heap 的各处且不连续的,因此 mmap 复制整个 heap 是行不通的。我们采用的方式是以 code_object 为根,遍历对象图,对感兴趣的内容复制并紧凑排布。
2、Python 的 code_object 会引用 .data 段的变量,在 Linux 的随机地址安全机制下,.data 段的数据的地址在每次运行时都会随机变化,这样 mmap 中的指针就失效了。我们的解决方式是遍历所有对象,针对 .data 段的指针进行偏移量修复。
因为该项目共享了 Python 的 code_object,因此名字是 code-data-share-for-python,简称 pycds。
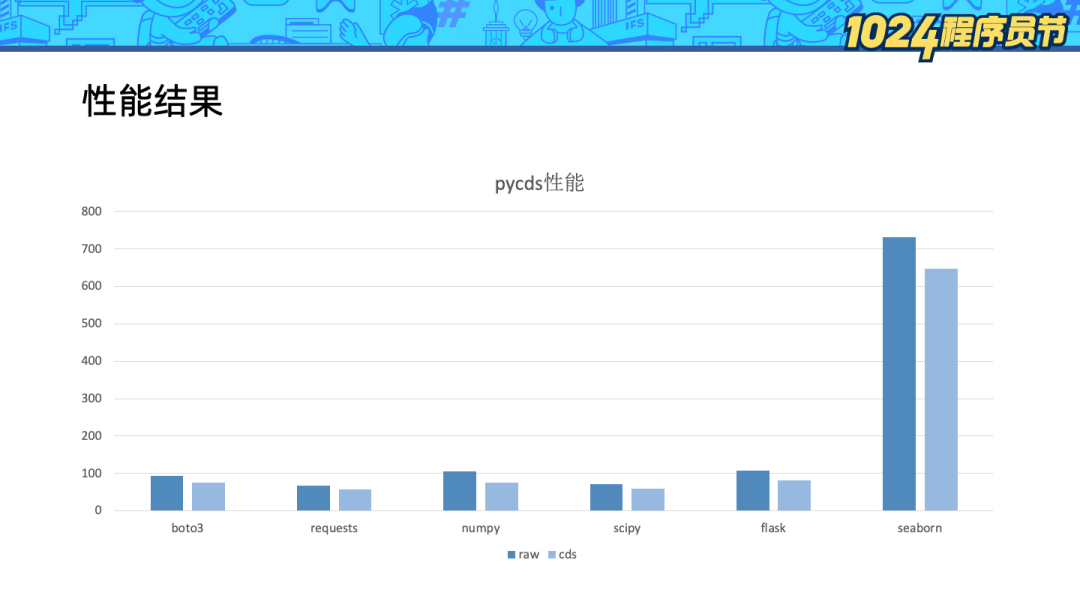
我们测试了 bota3、numpy、flask 等常用的 Python 库,平均可以节省 20% 的模块导入耗时。
对于现有的 Python 应用可以轻易地使用 pycds,且无需修改任何代码:
# 安装pycds
pip install code-data-share # 安装pycds
# 生成模块列表
PYCDSMODE=TRACE PYCDSLIST=mod.lst python -c 'import numpy’
# 生成 archive
python -c 'import cds.dump; cds.dump.run_dump("mod.lst", "mod.img")’
# 使用archive
time PYCDSMODE=SHARE PYCDSARCHIVE=mod.img python -c 'import numpy'
real 0m0.090s
user 0m0.180s
sys 0m0.339s
# 对比基线
time python -c 'import numpy'
real 0m0.105s
user 0m0.216s
sys 0m0.476s
我们仅仅通过安装 PyPI,修改环境变量运行和使用 cds API 做 dump 即可对现有的应用启动进行加速了。
code-data-share-for-python 是一个新项目,需要大家的参与和反馈,欢迎通过以下链接了解和使用:
https://github.com/alibaba/code-data-share-for-python
https://pypi.org/project/code-data-share-for-python
ARM 架构 SIG链接地址:
https://openanolis.cn/sig/ARM_ARCH_SIG
审核编辑 :李倩
-
大算力芯片的生态突围与算力革命2025-04-13 3693
-
国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?2025-10-27 2591
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 915
-
将AI算力送上太空,是终极方案还是疯狂幻想?评论区说出你的阵营!江苏易安联 2026-01-06
-
ECS控制台实例搜索的优化与改进2018-03-26 3308
-
解读最佳实践:倚天 710 ARM 芯片的 Python+AI 算力优化2022-12-23 1423
-
深度解析AI算力的现状和趋势2018-08-01 9912
-
华为发布最外那个算力AI芯片2019-08-23 4609
-
昆仑芯AI芯片以AI算力服务实体经济 筑底算力经济新基建2022-10-19 3967
-
ai芯片和算力芯片的区别2023-08-09 10427
-
阿里云倚天实例已为数千家企业提供算力,性价比提升超30%2023-11-03 1515
-
浅谈为AI大算力而生的存算-体芯片2023-12-06 984
-
Python在AI中的应用实例2024-07-19 4163
-
企业AI算力租赁是什么2024-11-14 3544
全部0条评论

快来发表一下你的评论吧 !
