

如何通过PyTorch实现卷积GAN构建?
人工智能
描述
译者 | Sambodhi
生成对抗网络(Generative Adversarial Network,GAN)由 Goodfellow 等人在 2014 年提出,它彻底改变了计算机视觉中的图像生成领域:没有人能够相信这些令人惊叹而生动的图像实际上是纯粹由机器生成的。
事实上,人们曾经认为生成的任务是不可能的,并且被 GAN 的力量所震惊,因为传统上,根本没有任何事实可以比较我们生成的图像。
本文介绍了创建 GAN 背后的简单直觉,然后介绍了通过 PyTorch 实现的卷积 GAN 及其训练过程。
GAN 背后的直觉
不同于传统分类方法,我们的网络预测可以直接与事实的正确答案相比较,而生成图像的“正确性”是很难定义和衡量的。Goodfellow 等人在他们的原创论文《生成对抗网络》(Generative Adversarial Network)中提出了一个有趣的想法:使用经过训练的分类器来区分生成的图像和实际图像。如果存在这样的分类器,我们可以创建并训练一个生成器网络,直到它输出的图像能完全骗过分类器。
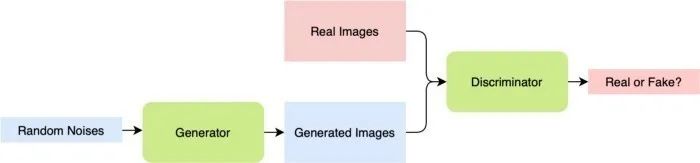
图 1 GAN 管道
GAN 是这一过程的产物:它包含一个根据给定的数据集生成图像的生成器,以及一个区分图像是真实的还是生成的判别器(分类器)。GAN 的详细管道见图 1。
损失函数
对生成器和判别器进行优化都很困难,因为正如你所想象的那样,这两个网络的目标完全相反:生成器希望尽可能地创造出真实的东西,但判别器希望区分生成的材料。
为了说明这一点,我们让 D(x) 是判别器的输出,也就是 x 是真实图像的概率,而 G(z) 是我们的生成器的输出。判别器类似于一个二元分类器,因此判别器的目标是使函数最大化:
本质上是二元交叉熵损失,没有开头的负号。另一方面,生成器的目标是使判别器做出正确判断的机会最小化,因此它的目标是最小化函数。所以,最终的损失函数将是两个分类器之间的一个极小极大博弈(minimax game),具体如下:
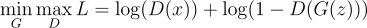
从理论上讲,这将收敛到判别器,预测所有事件的概率为 0.5。
但在实践中,极小极大博弈往往会导致网络无法收敛,因此仔细调整训练过程非常重要。像学习率这样的超参数对于训练 GAN 时显然更为重要:一个微小的变化会导致 GAN 产生一个输出,而与输入噪声无关。
运算环境
库
我们通过 PyTorch 库(包括 torchvision)来构建整个程序。GAN 的生成结果的可视化是通过 Matplotlib 库绘制的。下面的代码导入了所有的库:
importGAN.py
""" Import necessary libraries to create a generative adversarial network The code is mainly developed using the PyTorch library """ import time import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import transforms from model import discriminator, generator import numpy as np import matplotlib.pyplot as plt
数据集
在 GAN 训练中,数据集是一个重要方面。图像的非结构化性质意味着任何给定的类别(如狗、猫或手写的数字)都可以有一个可能的数据分布,而这种分布最终是 GAN 生成内容的基础。
为了演示,本文将使用最简单的 MNIST 数据集,其中包含 60000 张从 0 到 9 的手写数字图像。事实上,像 MNIST 这样的非结构化数据集可以在 Graviti 上找到。这是一家年轻的创业公司,他们希望通过非结构化数据集为社区提供帮助,在他们的 平台 上有一些最好的公共非结构化数据集,包括 MNIST。
硬件要求
最好的方法是用 GPU 训练神经网络,它可以显著地提高训练速度。但是,如果只有 CPU 可用,你仍然可以测试程序。要使你的程序能够自行确定硬件,你可以使用以下方法:
torchDevice.py
"""
Determine if any GPUs are available
"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
实施
网络架构
由于数字的简单性,这两种架构——判别器和生成器,都是由全连接层构建的。请注意,在某些情况下,全连接的 GAN 也比 DCGAN 略微容易收敛。
以下是两种架构的 PyTorch 实现:
GANArchitecture.py
"""
Network Architectures
The following are the discriminator and generator architectures
"""
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 1)
self.activation = nn.LeakyReLU(0.1)
def forward(self, x):
x = x.view(-1, 784)
x = self.activation(self.fc1(x))
x = self.fc2(x)
return nn.Sigmoid()(x)
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.fc1 = nn.Linear(128, 1024)
self.fc2 = nn.Linear(1024, 2048)
self.fc3 = nn.Linear(2048, 784)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(self.fc1(x))
x = self.activation(self.fc2(x))
x = self.fc3(x)
x = x.view(-1, 1, 28, 28)
return nn.Tanh()(x)
训练
在训练 GAN 时,我们优化了判别器的结果,同时也改进了我们的生成器。这样,在每次迭代过程中会有两个相互矛盾的损失来同时优化它们。我们送入生成器的是随机噪声,而生成器理应根据给定噪声的微小差异来生成图像:
trainGAN.py
"""
Network training procedure
Every step both the loss for disciminator and generator is updated
Discriminator aims to classify reals and fakes
Generator aims to generate images as realistic as possible
"""
for epoch in range(epochs):
for idx, (imgs, _) in enumerate(train_loader):
idx += 1
# Training the discriminator
# Real inputs are actual images of the MNIST dataset
# Fake inputs are from the generator
# Real inputs should be classified as 1 and fake as 0
real_inputs = imgs.to(device)
real_outputs = D(real_inputs)
real_label = torch.ones(real_inputs.shape[0], 1).to(device)
noise = (torch.rand(real_inputs.shape[0], 128) - 0.5) / 0.5
noise = noise.to(device)
fake_inputs = G(noise)
fake_outputs = D(fake_inputs)
fake_label = torch.zeros(fake_inputs.shape[0], 1).to(device)
outputs = torch.cat((real_outputs, fake_outputs), 0)
targets = torch.cat((real_label, fake_label), 0)
D_loss = loss(outputs, targets)
D_optimizer.zero_grad()
D_loss.backward()
D_optimizer.step()
# Training the generator
# For generator, goal is to make the discriminator believe everything is 1
noise = (torch.rand(real_inputs.shape[0], 128)-0.5)/0.5
noise = noise.to(device)
fake_inputs = G(noise)
fake_outputs = D(fake_inputs)
fake_targets = torch.ones([fake_inputs.shape[0], 1]).to(device)
G_loss = loss(fake_outputs, fake_targets)
G_optimizer.zero_grad()
G_loss.backward()
G_optimizer.step()
if idx % 100 == 0 or idx == len(train_loader):
print('Epoch {} Iteration {}: discriminator_loss {:.3f} generator_loss {:.3f}'.format(epoch, idx, D_loss.item(), G_loss.item()))
if (epoch+1) % 10 == 0:
torch.save(G, 'Generator_epoch_{}.pth'.format(epoch))
print('Model saved.')
结 果
当 100 个轮数(epoch)之后,我们可以绘制数据集,并看到从随机噪音中生成的数字的结果:

图 2:GAN 生成的结
如上图所示,生成的结果看起来确实相当像真实的结果。鉴于网络非常简单,所以结果看起来确实很有希望!
超越单纯的内容创作
GAN 的创造与计算机视觉领域的先前工作如此不同。随后的众多应用使学术界对深度网络的能力感到惊讶。下面将介绍一些令人惊讶的工作。
CycleGAN
Zhu 等人的 CycleGAN 引入了一种概念,它无需配对样本就可以将图像从 X 域翻译成 Y 域。马被转化为斑马,夏日的阳光被转化为暴风雪,CycleGAN 的结果令人惊讶且准确。
GauGAN
Nvidia 利用 GAN 的力量,把简单的绘画,根据画笔的语义,转换成优雅而逼真的照片。尽管训练资源的计算成本很高,但它创造了一个全新的研究和应用领域。
AdvGAN
GAN 还扩展到清理对抗性图像,并将其转化为不会欺骗分类器的干净样本。关于对抗性攻击和防御的更多信息可以在 这里 到。
结 语
所以,你已经拥有了它!希望这篇文章对如何构建 GAN 提供了一个概览。
作者简介:
Ta-ying Cheng,中国香港人,牛津大学哲学博士新生,爱好 3D 视觉、深度学习。
编辑:黄飞
-
如何使用MATLAB实现一维时间卷积网络2025-03-07 2400
-
基于PyTorch的卷积核实例应用2024-07-11 1593
-
使用PyTorch构建神经网络2024-07-02 1642
-
使用Pytorch实现频谱归一化生成对抗网络(SN-GAN)2023-10-18 1384
-
pytorch如何构建网络模型2023-07-20 633
-
PyTorch教程8.8之设计卷积网络架构2023-06-05 644
-
图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐2021-08-31 1249
-
如何利用PyTorch API构建CNN?2020-07-16 1230
全部0条评论

快来发表一下你的评论吧 !
