

什么是DPD?为什么要使用DPD呢?
电子说
描述
DPD是数字预失真的首字母缩写,许多射频(RF)、信号处理和嵌入式软件开发工程师都熟悉这一术语。对于DPD,从纯粹数学角度出发的建模,到微处理器实际实现面临的限制,许多工程师都有自己独特的见解。作为负责评估RF基站产品中DPD性能的工程师,或者是一名算法工程师,可能都会想知道数学建模技术以及在实际系统中的实现方式。如今,DPD在蜂窝通信系统中随处可见,使功率放大器(PA)能够有效地为天线提供最大功率。5G基站中的天线数量增加,频谱变得更加拥挤,DPD开始成为一项关键技术,支持开发经济高效且符合规格要求的蜂窝系统。
什么是DPD?为什么要使用DPD?
当基站射频装置输出RF信号时(参见图1),需要先将其放大,然后通过天线发射出去。放大是通过RF PA来实现的。在理想情况下,PA接收输入信号,然后输出与其输入成正比的更高功率信号。PA效率应尽可能高,将放大器的大部分功耗都转化为信号输出功率。
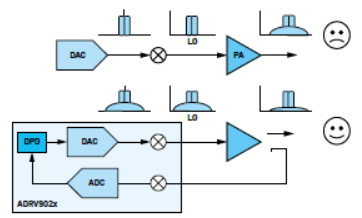
图1:采用和未采用DPD技术的简化射频结构框图。
但理想并非实际。PA由晶体管构成,晶体管是有源器件,本身具有非线性。如图2所示,如果PA工作在“线性”(相对而言)区域,则输出功率与输入功率相对成比例。但缺点是PA效率很低,大部分功耗都会作为热量流失。故希望PA工作在压缩初始区。这意味着, PA输出不会随着输入信号等比例增加,即此时输出信号会严重失真。
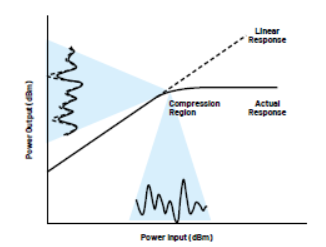
图2:PA输出功率与输入功率之间的关系图(显示了输出/输入信号的投影)。
这种失真发生在频域中的已知位置,具体取决于输入信号。图3显示了这些位置,以及基频与这些失真产物之间的关系。在RF系统中,只需要对基波信号附近的失真进行补偿,这些信号是奇阶交调产物。系统滤波处理带外产物(谐波和偶阶交调产物)。图4显示RF PA的压缩点附近的输出。交调产物(特别是三阶)清晰可见,就像是围绕着目标信号的“裙摆”。
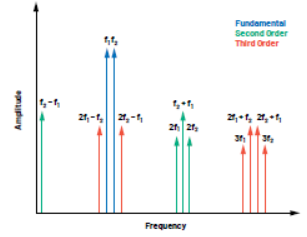
图3:双音输入交调和谐波失真的位置。

图4:2× 20 MHz信号通过SKY66391-12 RF PA,中心频率为1850 MHz。
DPD旨在通过观察PA输出来表征这种失真,要了解所需输出信号,随之更改输入信号,使得PA输出接近理想值。只有在相当具体的情况下才能有效地实现这一目标。需要配置放大器和输入信号,使放大器有一定程度的压缩但未完全饱和。
PA失真建模背后的数学计算
在“射频功率放大器数字预失真的广义记忆多项式模型”一文中,开创性地介绍了针对DPD广泛使用的广义记忆多项式(GMP)方法。为了简化,先尝试拆解一下GMP方法,以更直观地理解数学原理。
Volterra级数是DPD的重要数学基础,它用于建立具有记忆的非线性系统模型。记忆仅仅意味着系统的当前输出取决于当前和过去的输入。Volterra级数很常用(所以功能强大),对于PA DPD,该级数可以精简使用,使其在实时数字系统中更易实现,也更稳定。
图5显示如何使用GMP对PA的输入x和输出y之间的关系进行建模。可以看到,该等式的三个单独的求和块彼此都非常相似。先来看看下方用红色圈出来的第一个。|x(…)|k项是指输入信号的包络,其中k是多项式阶。l将记忆集成到系统中。如果La = {0,1,2},那么该模型允许输出yGMP (n)由当前的输入x(n)和过去输入x(n – 1)和x(n – 2)决定。图6分析多项式阶k对样本向量的影响。向量x是单个20 MHz载波,在复基带上表示出来。去除记忆部分,以简化GMP建模等式。x|x|k图显示的失真与图4中的实际失真非常相似。
每个多项式阶(k)和记忆延迟(l)都有相关的复值权重(akl)。在选择模型的复杂程度之后(其中包括k和l的值),需要根据已知输入信号的PA输出实际观测值来求解这些权重。图7将简化的等式转换为矩阵形式。可以使用数学符号简明表示该模型。但是,要在数字数据缓冲区实现DPD,用矩阵表示法会更简单,也更具代表性。
来看看图6中等式的第二行和第三行,为了简化,这两行被忽略了。注意,如果m设置为0,那么这两行会变得与第一行一模一样。这些行允许在包络项和复基带信号之间增加延迟(正延迟和负延迟)。这些称为滞后交叉和超前交叉项,可以显著提高DPD的建模精度。在尝试对放大器的行为建模时,这些项提供了额外的自由度。注意,Mb、Mc、Kb和Kc不包含0;否则,会重复第一行的项。
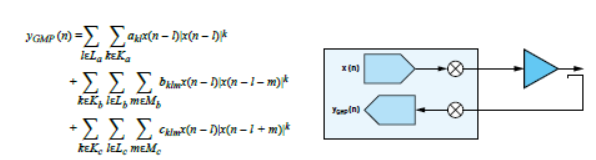
图5:用于PA失真建模的GMP。
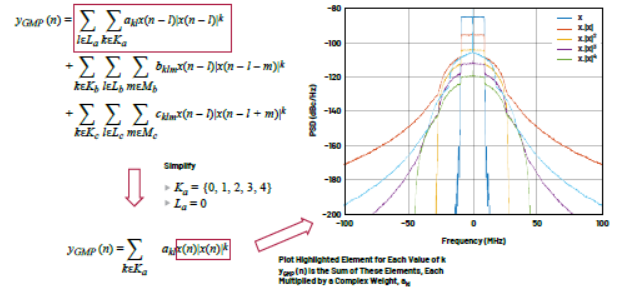
图6:在信号x的频域中,阶(k)对信号的影响曲线图。

图7:将简化的等式转换为数据缓冲区的矩阵运算(更接近于数字实现方式)。
那么,如何确定模型的阶、记忆项的数量,以及应该添加哪些交叉项?此时,就需要一定数量的“黑魔法”了。此时,有关失真的物理学知识能够提供一定帮助。放大器的类型、制造材料,以及通过放大器的信号带宽都会影响建模项,可以帮助熟悉该领域的工程师确定应该使用哪个模型。但是,除此之外,还涉及一定程度的反复试验。
有了模型架构,从数学角度来解决该问题的最后一个方面是如何求解权重系数。在实际场景中,人们倾向于求解上述模型的倒数。事实证明,这些模型系数能够彼此互惠,可以使用相同的权重对捕捉到的PA输出向量进行后失真,以消除非线性,并对通过PA发送的发射信号预失真,使得PA输出尽可能呈现线性。在图8所示的框图中,显示了如何对权重系数进行估算和预失真。

图8:建模和预失真间接实现框图。
在逆模型中,将图7给出的矩阵等式互换,给出X̂ = Yw。其中,矩阵Y的构成方式与其他示例中X的构成方式相同,如图9所示。在本例中,包含了一个记忆项,且减少了包含的多项式的阶数。为了求解w,我们需要得出Y的倒数。Y不是方形的(是一个瘦长矩阵),所以需要使用“伪逆”矩阵进行求解(参见等式1)。这是从最小二乘意义上求解w,最小化了X̂和Yw之间的差的平方!

鉴于是在具有不同信号的真实环境中使用,可以对其进一步优化。在这里,系数是基于之前的值进行更新,因此受到限制。μ是0和1之间的常数值,用于控制每次迭代时权重的变化量。如果μ = 1,w0 = 0,那么此等式立即恢复到基本最小二乘解。如果将μ设为小于1的值,则需要多次迭代才能使系数收敛。
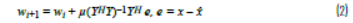
注意,这里描述的建模和估算技术并非是执行DPD的唯一方式。也可以使用其他技术,例如基于动态偏差减少的建模来代替或作为附加方法使用。上述用于求解系数的估算技术具有多种实现方式。鉴于篇幅,此处不再赘述。
如何在微处理器中实现这一技术?
前面介绍了相关数学知识。下一个问题是如何在实际通信系统中实现?在数字基带中,一般在微处理器或FPGA中实现。目前,ADI的RadioVerse收发器产品(例如ADRV902x系列)内置微处理器内核,已经集成了这类算法,其结构有助于轻松实现DPD。不仅提供了高度集成的RF硬件,还为客户提供可配置的软件工具。
在嵌入式软件中实现DPD涉及两个方面。一是DPD执行器,对实时发送的数据执行实时预失真,二是DPD自适应引擎,基于观察到的PA输出来更新DPD系数。
对于如何在微处理器或类似器件中实时执行DPD和许多其他信号处理概念,关键在于使用查找表(LUT)。LUT允许用更简单的矩阵索引操作来代替成本高昂的实时计算。来看看DPD执行器如何对发送的数据样本进行预失真。代表符号如图8所示,其中u(n)表示要传输的新数据样本,x(n)表示预失真版本。图10显示在给定场景下,获取一个预失真样本所需的计算。这是一个相对受限的示例,最高多项式阶为三阶,只有一次记忆选取和一个交叉项。即使在这种情况下,要获取这样一个数据样本,也需要进行大量乘法、幂运算和加法运算。
在这种情况下,使用LUT可以减轻实时计算负担。可以将图10所示的等式改写成图11所示的样式,其中输入LUT的数据会变得更加明显。每个LUT都包含等式中突出显示项的结果值,它们对应|u(n)|的多个可能值。分辨率取决于在可用硬件中实现的LUT大小。当前输入样本的幅度大小基于LUT的分辨率进行量化,可以作为索引,用于访问给定输入的正确LUT元素。
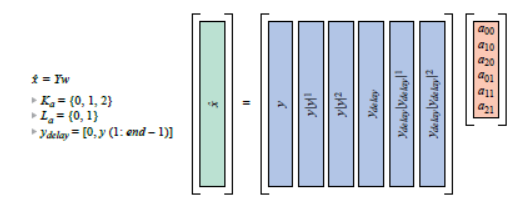
图9:以矩阵形式表示的逆算法等式,有些记忆包含在其中。
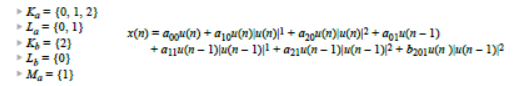
图10:具有一次记忆选择和一个三阶交叉项元素的三阶预失真计算案例。
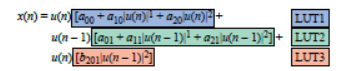
图11:对等式项重新分组,以显示LUT的结构。
图12显示如何将LUT集成到示例案例的完全预失真执行器实现方案。注意,这只是其中一种可能的实现方法。在保持相同输出的情况下,可以做出更改,例如:可以将延迟元素z–1移动到LUT2右侧。
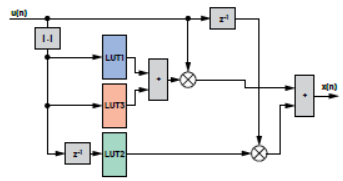
图12:使用LUT可能实现DPD的框图。
自适应引擎负责求解用于计算执行器中的LUT值的系数。这涉及到求解等式1和2中描述的w向量。伪逆矩阵运算(YH Y)-1 YH会耗费大量计算资源。等式1可以改写为

如果CYY = YHY,CYx = YH x,等式3会变成

CYY是矩形矩阵,可以通过柯列斯基分解方法分解为上三角矩阵L和共轭转置矩阵(CYY =L H L)的乘积。这样我们可以通过引入一个虚拟变量z来求解w,求解方法如下:

然后,重新代入这个虚拟变量,求解

因为L和LH分别是上、下三角矩阵,所以花费很少的计算资源,就可以求解等式5和等式6,得出w。自适应引擎每次运行,得出w的新值时,都需要更新执行器LUT来体现这一点。根据观察到的PA输出,或者操作员掌握的待传输信号的变化情况,自适应引擎可以按照设定的定期间隔或不规则的间隔执行操作。
在嵌入式系统中实现DPD需要进行大量检查和平衡,以确保系统的稳定性。最重要的是,发送数据缓冲器和捕捉缓冲器数据的时间要一致,以确保它们之间建立的数学关系是正确的,且在长时间之后仍然保持正确。如果这种一致性丧失,那么自适应引擎返回的系数将不能对系统执行正确的预失真,可能导致系统不稳定。还应检查预失真执行器输出,确保信号不会使DAC饱和。
审核编辑:刘清
-
DPD的原理是什么?DPD到底是怎么实现运行的?2023-08-27 9104
-
RJK4532DPD 数据表2023-07-25 447
-
RJK4502DPD 规格书2023-07-14 509
-
RJJ1011DPD 数据表2023-04-26 383
-
RJK6025DPD 数据表2023-04-12 388
-
RJK4502DPD 数据表2023-04-10 426
-
RJK6032DPD 规格书2023-04-04 438
-
ADRV-DPD1 ADRV-DPD1评估板2021-08-16 781
-
究竟LTE中的CFR和DPD有什么作用?2021-06-21 6279
-
GC5322_DPD数据分析2013-03-14 1391
全部0条评论

快来发表一下你的评论吧 !
