

基于事件相机的vSLAM研究进展
MEMS/传感技术
描述
视觉SLAM (vSLAM)是指移动机器人通过相机感知外部世界并估计机器人的位姿和重建周围环境的三维地图。vSLAM在各种应用中扮演着不可或缺的角色,包括自动驾驶,机器人导航和增强现实。例如,在机器人导航里,vSLAM能够提供环境信息和机器人的位置来帮助它到达指定的地点。vSLAM通常利用传统的RGB相机获取图片信息。然而传统的相机局限于低动态感光范围和运动中产生的动态模糊,而无法在复杂的场景下得到精准的位姿估计和三维重建结果。近年来,基于一种新的仿生相机,即事件相机,相应的vSLAM算法被相继提出。该类方法利用事件相机的高帧率、高动态感光范围、低能耗、低延迟等特性在一些复杂的场景下也能得到了非常优异的结果。
本综述综合性地概述了基于事件相机的vSLAM研究进展,同时也包含了事件相机的工作原理和事件数据的预处理和表征形式。我们将主流的算法分为四大类,即特征法、直接法 、运动补偿法和基于深度学习的方法。在每个类别中,我们对相应的算法框架、突出贡献、优势和局限性都进行了充分的论述。另外,本文还整合了包含事件相机及多模态的诸多vSLAM的数据集,并在典型的数据集上对具有代表性的方法进行了系统的结果评估,也同时讨论了不同方法各自适用的场景。最后,我们讨论了目前基于事件相机的vSLAM存在的挑战以及未来可能的研究方向。
一、事件相机vSLAM介绍
vSLAM能够通过视觉传感器来获取环境信息,以达到估计机器人位姿和周围环境三维重建的目的。但是传统的视觉传感器受限于它的硬件而导致的低动态感光范围和运动中产生的动态模糊,在一些复杂的场景下无法得到良好的结果,例如高速运动中的或者复杂的光照条件下的场景。
近年来,事件相机受到了研究者们的关注。由于事件相机的高帧率、低延迟和高动态感光范围,使得基于事件相机的vSLAM 能够胜任一些复杂的场景,尤其是高速运动和复杂光照下的场景。但是,事件相机产生的事件数据和传统相机产生的图像完全不同。如图1(a, b)所示,事件相机通过记录了每个像素点的光度变化而产生时间连续性的、异步的、稀疏的和不规则的数据。因此传统的vSLAM算法不能直接运用在事件数据上。同时,每个事件传递的信息极少,且极易受到硬件噪声的影响。此外,事件相机引入了更加复杂的多视图几何关系。所以,我们需要一个新的框架来处理事件数据来实现vSLAM。

图1. 事件数据在时间空间中的表示、投影到图像平面上的表示以及基于事件相机的vSLAM方法的相机位姿和三维重建图。
为了能让基于事件相机的vSLAM在事件数据上实现位姿估计和三维重建,研究者设计出了多种多样针对事件相机的数据关联、位姿估计和三维重建的解决方案。我们将主流的算法分类为四种类别,分别为特征法、直接法、运动补偿法和基于深度学习的方法。特征法通过在事件数据中提取并跟踪特征点实现vSLAM;而直接法隐式关联事件数据一次实现vSLAM;运动补偿法通过消除投影在图像平面上的事件表征所产生的动态模糊来估计相机的运动;基于深度学习的方法利用神经网络实现端到端的预测位姿和三维图。本文对相关的研究算法做了详尽的介绍,并对一些具有代表性的方法进行了结果评估。
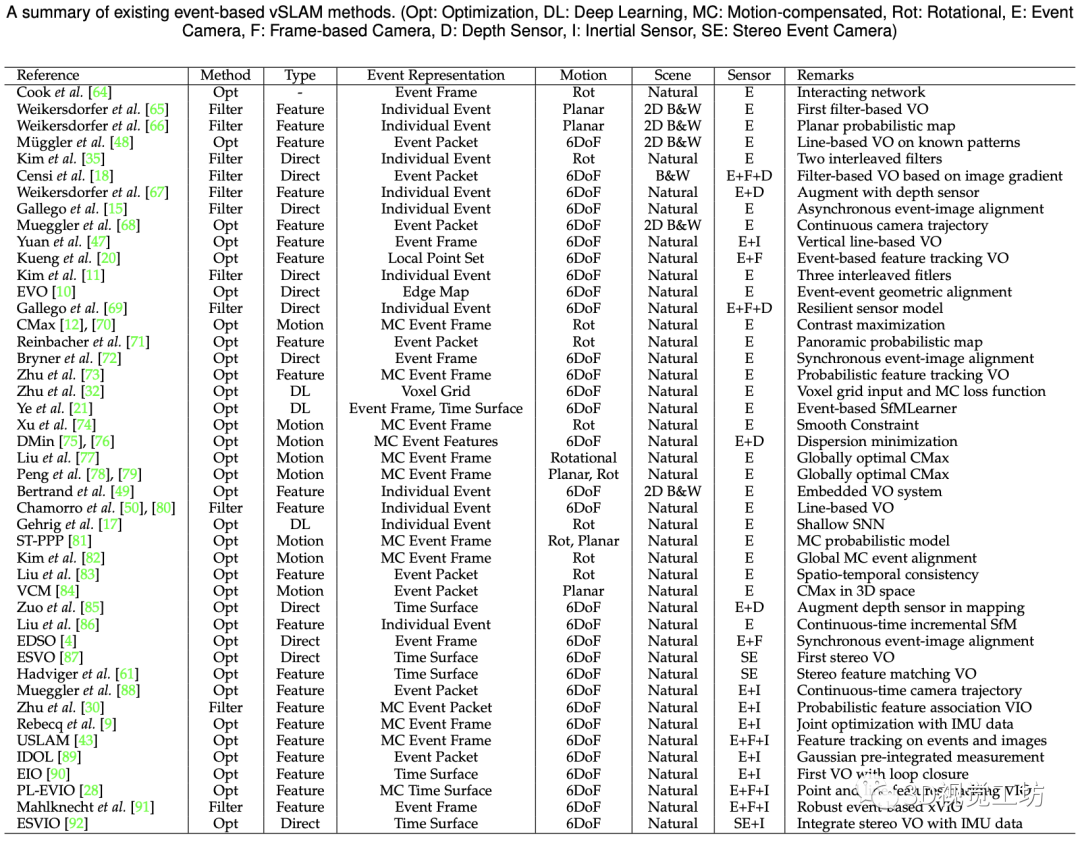
图2. 基于事件相机的vSLAM的方法总结表,包括了他的优化方法、分类、事件表征、相机运动类型、场景类型以及采用的传感器等。
二、具体研究进展及讨论
为了处理事件相机产生的异步的、不规则的事件数据,研究者利用滤波器和脉冲神经网络来单独处理每一个原始的事件数据,但是这些方法通常需要大量的运算。另一方面,研究者提出将一组连续的事件数据转化成同步的事件表征形式,例如二维事件帧、时间平面和voxel grid,来平衡延迟和运算量。更多详情可见文章第三章。
主流的vSLAM算法通常包括三个主要的步骤:数据关联、位姿估计和三维重建。它们对相同三维点在不同二维图像平面上的像素点构建关联,通过多视角的几何学进行位姿估计和三维重建。基于事件相机的vSLAM也遵循了这一范式。
特征法通常从事件数据中提取并跟踪特征来构建数据关联,例如原始的点和线特征。利用特征和显式的特征关联,特征法能够估计每个特征点对应的相机位姿和三维点。特征法十分依赖于特征提取和算法的表现,而由于事件数据中的噪声和运动变化的特性,现有的基于事件相机的特征提取算法还不够成熟,使得特征法的效果相对比较差。VIO方法通过结合惯性数据提高特征法的鲁棒性并取得了较好的性能。更多详情可见文章第四章。
直接法分为两类:(a) 事件-图像对齐法利用光度变化和绝对光度的关系来建立每个事件和参照光度图像的像素点,(b) 事件表征对齐法利用了事件数据中的空间-时间的关系对齐两帧事件表征。由于事件一般产生于高图像梯度的区域,这一先验可以帮助直接法筛选像素点。同时,事件相机的高帧率特性保证了两帧之间的相对位姿较小,从而保证了直接法能够得到最优解。更多详情可见文章第五章。
长时间跨度的事件帧通常会产生动态模糊,而运动补偿法旨在优化事件数据的对齐锐化事件帧来估计相机的运动。这种方法能够保留长期的边缘模型,提高相机位姿估计的鲁棒性,同时它们能够运动到事件数据中的时间戳。但是,运动补偿法有可能产生事件塌缩的现象,即所有事件对齐到一个点或者一条线上,而得到不准确的相机位姿。更多详情可见文章第六章。
基于深度学习的方法通常将事件数据转换成二维的事件表征或者三维的voxel grid,采用神经网络提取特征来预测位姿和重建三维图。(a) 无监督学习法利用事件的光流作为训练信号来估计位姿和深度。(b) 监督学习法直接利用位姿和深度真 值来训练神经网络,从而直接预测位姿和深度。神经网络能够提取事件相机的非线性特征并处理事件噪声和异常。但是,深度学习方法需要大量的训练数据,并且其泛用性较差。另外,脉冲神经网络能够直接处理异步的、规则的事件数据,但是这项技术还不够成熟,它的脉冲消失问题和训练问题有待解决。更多详情可见文章第七章。
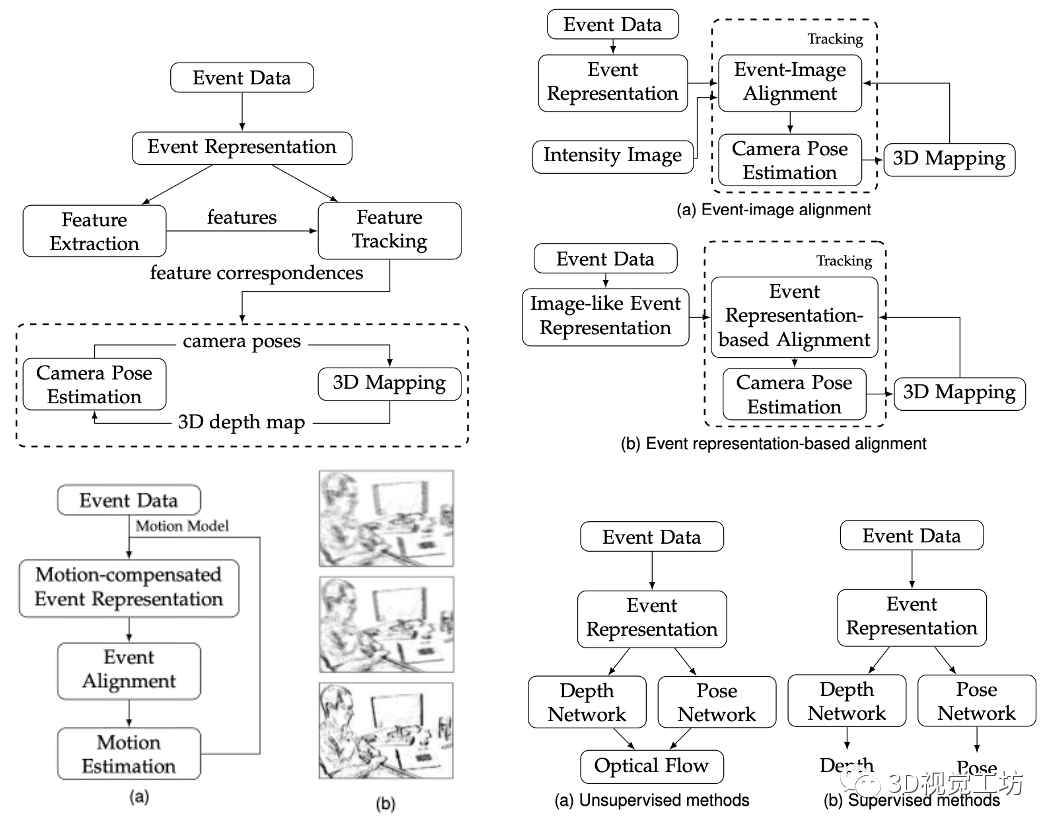
图3. 四种方法的流程图,左上为特征法,右上为两种直接法,包括事件-图像对齐和事件表征对齐,左下为运动补偿法,右下为两种基于深度学习的方法,包括无监督学习和监督学习。
三、实验对比
我们首先详细介绍了常用的基于事件相机的vSLAM数据集以及近几年最新的相关数据集。它们提供了事件相机在不同场景、不同光照条件下的事件数据以及相机的位姿和深度图。另外,我们详细介绍了位姿和深度估计的评价标准。我们分别在相机位姿和深度估计两个子任务上对具有代表性的算法进行了详尽的比较。我们在相同的设定下以公正的评测目前的基于事件相机的vSLAM方法与传统相机的方法。相关指标结果如图4,5所示。最后,我们讨论了四种主流方法的适用场景。
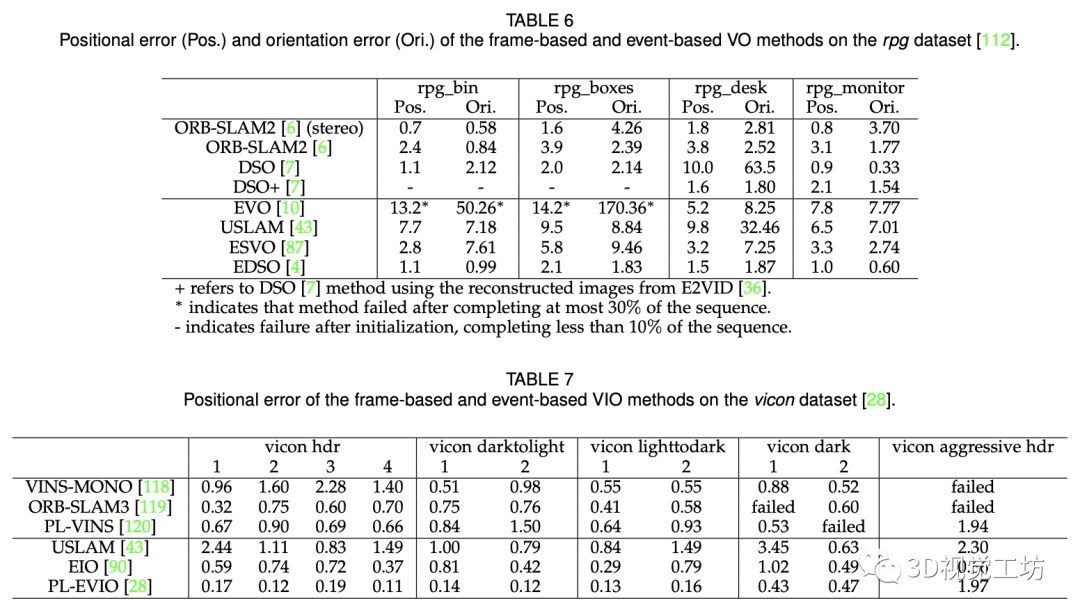
图4. 深度估计算法的评估结果。
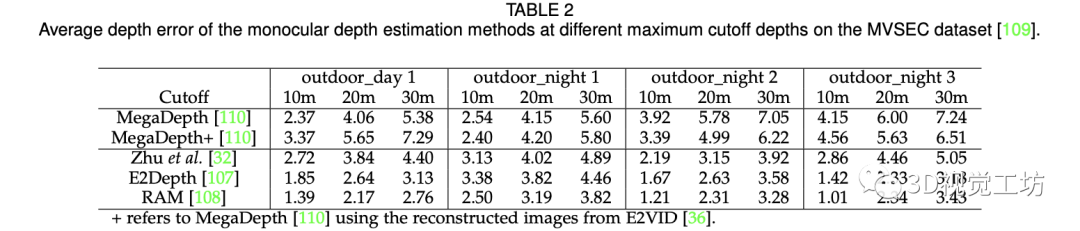
图5. vSLAM位姿估计的评估结果。
四、挑战与展望
在这一节,我们讨论了基于事件相机的vSLAM面临的主要挑战和未来的研究方向。我们在这里做一个简要的讨论。更多详情可见文章第九章。
理论研究
理论分析能够提供基于事件相机的vSLAM方法泛用性和验证性提供理论保证。近几年,传统的vSLAM发展了许多理论研究,然而基于事件相机的vSLAM缺乏相应的理论研究。如何将传统的vSLAM的理论研究扩展到事件相机上或者建立新的理论体系是一个值得研究的未来方向。
提高恶劣环境下的鲁棒性
即将事件相机在高动态感光范围的环境下有巨大的优势,但是一些恶劣环境下的场景依旧会提高事件数据的噪声,降低基于事件相机的vSLAM方法的准确率,例如,夜晚场景和极端天气状况。如何提高vSLAM方法在恶劣环境下的鲁棒性保有精确的位姿估计和三维重建是一个充满潜力的研究方向。
全局优化
由于不准确的数据关联和传感器的噪声,基于事件相机的vSLAM算法会累积偏移误差,导致在长时间的相机运动下产生更大的误差,而偏离实际的位置。额外的全局优化有望消除累积的便宜误差,例如,全局地图优化和位姿图优化。
多模态的基于事件相机的vSLAM
将基于事件相机的vSLAM方法与多模态领域进行融合可以进一步提高算法的鲁棒性。例如,惯性传感器能够提供惯性数据防止相机跟踪丢失。事件-图像对齐直接法利用光度变化和绝对广度的关系对齐事件和图像上的像素点。未来可以进一步探究不同传感器和事件相机之间互补的特性来得到更精确、鲁棒的vSLAM方法。
五、总结
我们提供了一份基于事件相机的vSLAM领域的综述,涵盖了事件相机的工具原理、事件预处理的表征形式、四种主要的vSLAM方法,公开的评估结果以及未来的研究方向。事件相机能够提高vSLAM算法在高速运动和高动态感光范围场景下的鲁棒性。为了能够利用事件相机的优势并运用到vSLAM上,未来还需要我们更好地处理异步的、稀疏的事件数据。
编辑:黄飞
-
新型铜互连方法—电化学机械抛光技术研究进展2009-10-06 7415
-
室内颗粒物的来源、健康效应及分布运动研究进展2010-03-18 3619
-
薄膜锂电池的研究进展2011-03-11 3123
-
传感器EMC的重要性与研究进展2018-11-05 2292
-
太赫兹量子级联激光器等THz源的工作原理及其研究进展2019-05-28 2594
-
声频定向扬声器的研究进展2010-01-08 913
-
锂离子电池合金负极材料的研究进展2009-10-28 4961
-
CMOS_Gilbert混频器的设计及研究进展2015-12-21 925
-
移动互联网QoS机制的研究进展述评2016-01-04 788
-
脑电信号伪迹去除的研究进展_杜晓燕2016-01-15 1191
-
物联网隐私保护研究进展2016-03-24 720
-
软件测试技术的研究进展刘继华2017-03-14 1188
-
农业机械自动导航技术研究进展2021-03-16 1322
-
基于事件相机的vSLAM研究进展2023-05-12 1021
-
超结IGBT的结构特点及研究进展2023-08-08 1463
全部0条评论

快来发表一下你的评论吧 !
