

计算机系统对数值类型的编码、运算、转换原理介绍1
电子说
描述
前言
在日常编程中, 数值类型 ( numeric types )是我们打交道最多的类型,可能没有之一。除了最熟悉的 int,还有 long、float、double 等。正因太熟悉,我们往往不会深究它们的底层原理。因为平时的工作中,知道个大概,也够用了。
但,在某些业务场景下,比如金融业务,数值运算不准确会带来灾难性的后果。这时,你就必须清楚数值类型的二进制表示、截断、转型等原理,否则很难保证运算结果的正确性。
另外,数值类型也是一个容易被黑客攻击的点,考虑如下一段代码:
// C++
/* Declaration of library function memcpy */
void *memcpy(void *dest, void *src, size_t n);
/* Kernel memory region holding user-accessible data */
#define KSIZE 1024
char kbuf[KSIZE];
/* Copy at most maxlen bytes from kernel region to user buffer */
int copy_from_kernel(void *user_dest, int maxlen) {
/* Byte count len is minimum of buffer size and maxlen */
int len = KSIZE < maxlen ? KSIZE : maxlen;
memcpy(user_dest, kbuf, len);
return len;
}
如果你熟悉数值类型的原理,一定会敏锐察觉出第 10 行存在 int 到 size_t 的类型转换。在 64 位系统中,size_t 通常被定义为 unsigned long 类型,如果攻击者在调用 copy_from_kernel 时,特意传入一个负数的 maxlen,转型到 memcpy 中的 n 将会是一个很大的正数,从而导致了内存拷贝的越界!
数值类型是计算机编程的基础,用的很多,也很重要,理解它的底层原理,有助于写出正确的代码,避免一些意料之外的错误 。
每个计算机系统都有固定的 word size ,也即常说的 xx 位,它也是指针的大小,跟 虚拟内存 相关,比如一个 w 位系统上的应用程序,最多能够访问 byte 大小的虚拟内存。
最常用的是 32 位 和 64 位 系统,某些数值类型在它们之上会有些差异,比如 long 类型 在 32 位系统上是 32 bit 大小,在 64 位系统上是 64 bit 大小。 考虑如今 64 位系统逐渐成为主流,本文会以它作为基础,进行数值类型的介绍 。
整数
在计算机系统中,整数可以分成 无符号 ( unsigned )整数 和 有符号 ( signed )整数 两大类,这之下,按照类型表示的 bit 位大小,又可细分成 8 位的 char/byte/int8 、16 位的 short/innt16、32 位的 int/int32 和 64 位的 long/int64,它们的取值范围如下:
| 类型 | 最小值 | 最大值 |
|---|---|---|
[signed] char |
-128 | 127 |
unsigned char |
0 | 255 |
short |
-32,768 | 32,767 |
unsigned short |
0 | 65,535 |
int |
−2,147,483,648 | 2,147,483,647 |
unsigned int |
0 | 4,294,967,295 |
long |
−9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
unsigned long |
0 | 18,446,744,073,709,551,615 |
死记这个表不容易,下面我们将试图从二进制编码层面去理解它。
二进制编码
整数在计算机系统上都是以二进制存储的,对于一个 w 位的整数 ,它的二进制表示写成这样:
其中, 取值 或 。
无符号编码(Unsigned Encodings)
在二进制表示的基础上,无符号编码 是这样:
比如,w = 4 场景下的一些例子:
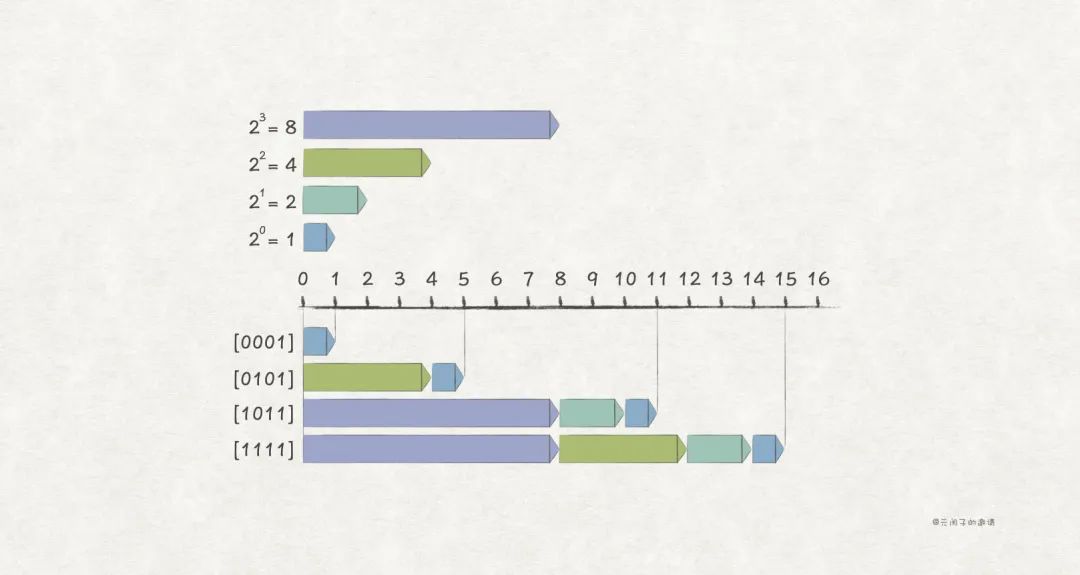
由上述可知, 无符号编码无法表示负数,因此只能表示无符号整数 。为了表示有符号整数,还要探寻另一种编码方式。
原码编码(True Form Encodings)
为了区分正数和负数,很容易想到使用一个 bit 位作为 符号位 , 表示正数, 表示负数。在无符号编码的基础上,使用最高位作为符号位,其他位含义不变,得出 原码编码 形式:
比如,w = 4 场景下的一些例子:
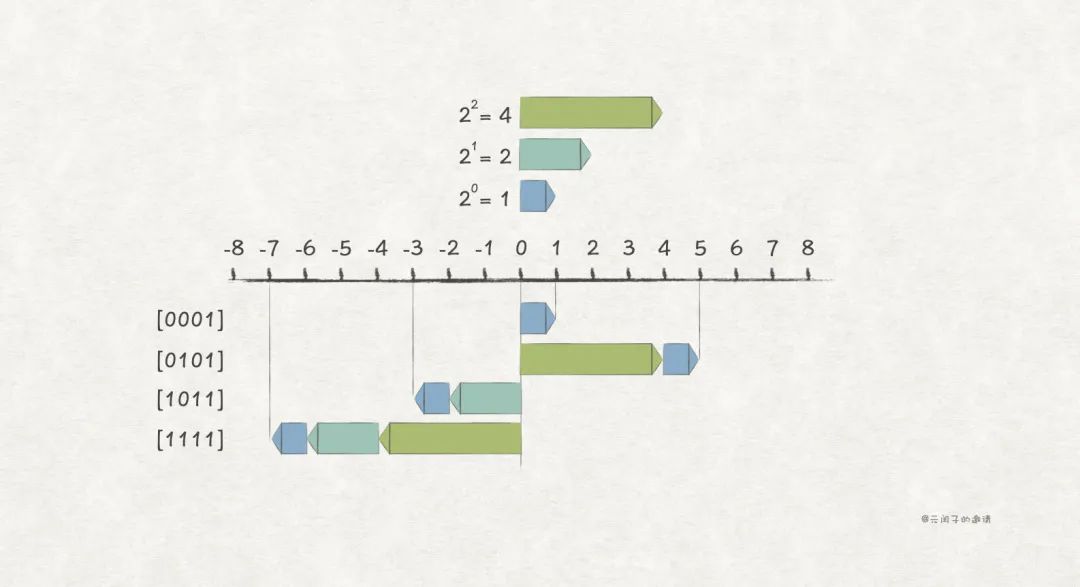
虽然原码编码方式简单直观,但它还存在两个问题:
(1) 存在两种编码形式
原码编码方式下, 存在两种编码形式, 和 。同一个整数值,却有两种编码,这对计算机系统来说没什么意义,反而是一种浪费。
(2)带负数的加法运算不正确
原码编码方式下,两个正数的加法没问题,一旦带上负数,结果就出错了:

所以,原码编码方式,注定不会被使用。
补码编码(Two's-complement Encodings)
于是,补码编码 被发明,它也是建立在无符号编码的基础上,仍然取最高位为符号位,编码方式是这样:
它与无符号编码的唯一区别是,最高位的取值从 变成了 。
比如,w = 4 场景下的一些例子:
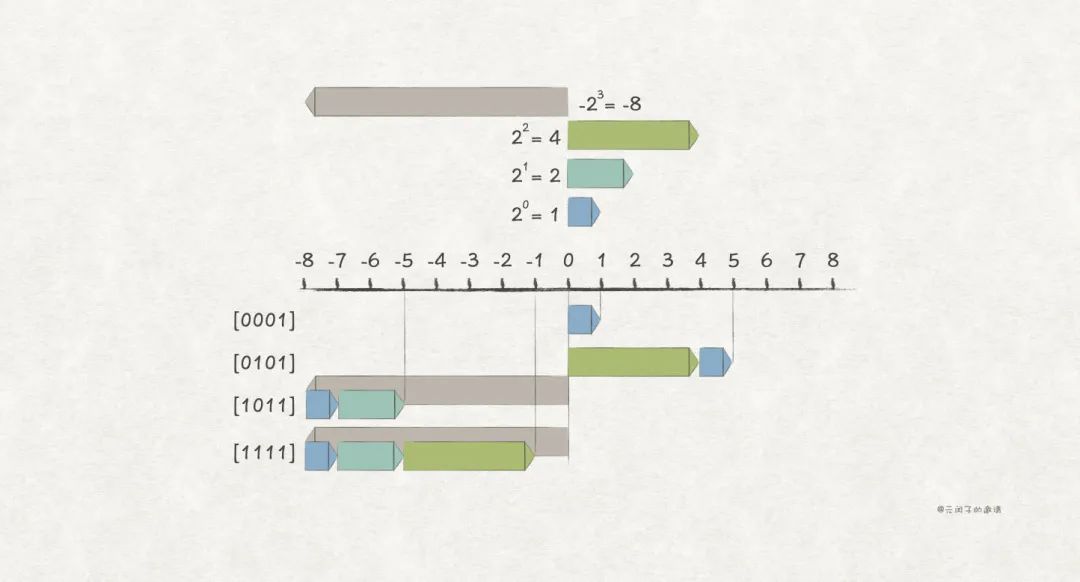
补码编码很巧妙地解决了原码编码的两个问题:
首先,0 在补码编码下只有一种编码形式, 。
此外,带负数的加法运算,也正确了。
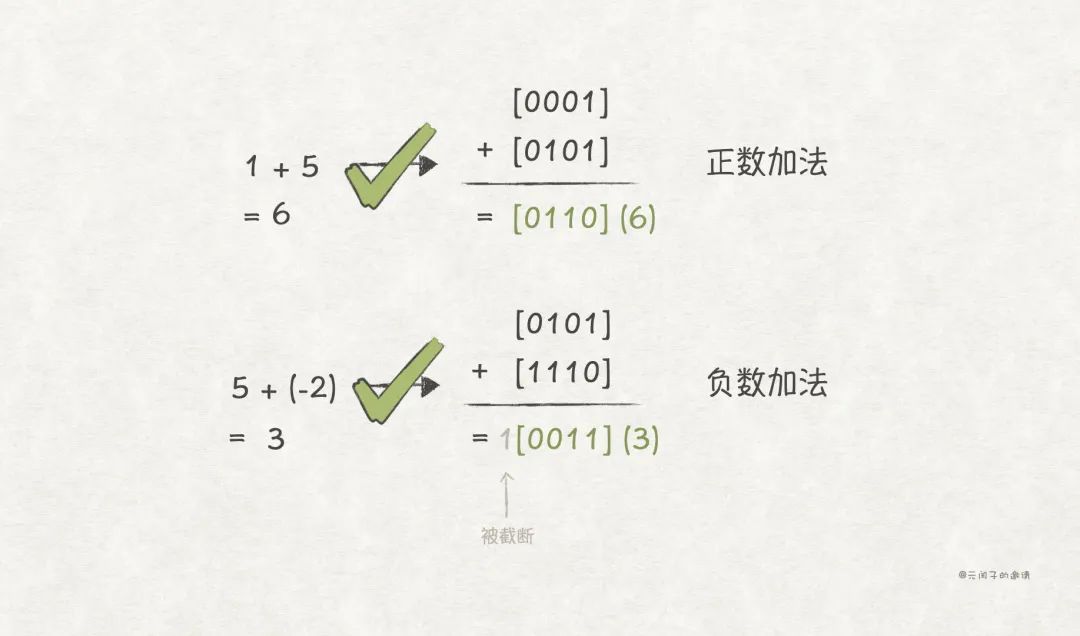
因为补码编码的简单和正确性,目前,几乎所有的计算机系统,都采用补码编码来表示有符号整数 。
位运算
位运算主要包含 取反 、 与 、 或 、 异或 、移位 等几种,我们在业务开发时用得比较少,但如果你有阅读开源代码的习惯,就会经常发现它们的踪迹。如果碰巧对位运算不熟悉,那么阅读这些代码,就同读天书一般。
取反(~)、与(&)、或(|)、异或(^)的规则比较简单:

移位运算,可以分成 左移 和 右移 两种,其中,右移又可分为 逻辑右移 和 算术右移 。
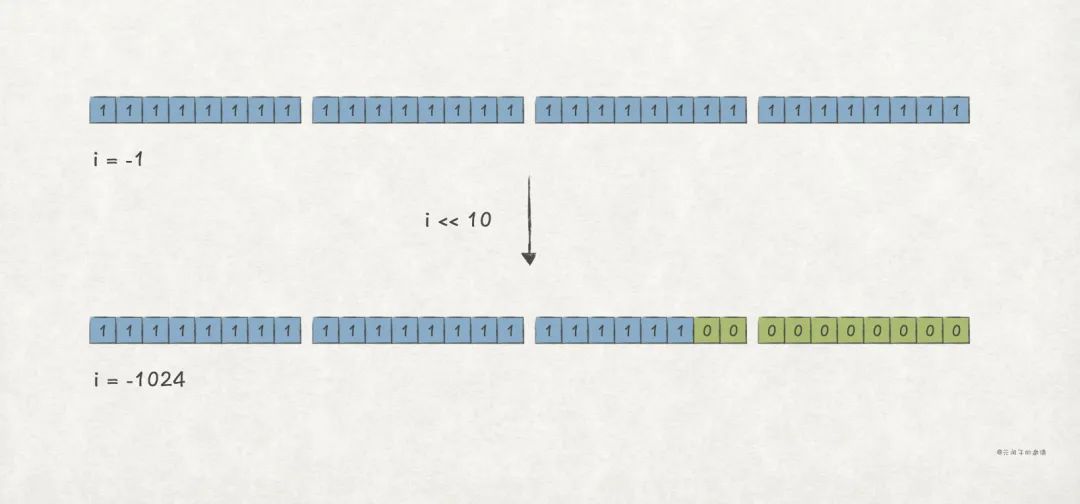
左移(<<)运算,是对二进制整数,向左移若干位,高位丢弃,低位补零 。也即,对 左移 位,得到 。
比如,对 int i = -1 左移 10 位,会得到 i = -1024 的结果:
// Java语言
public static void main(String[] args) {
int i = -1;
System.out.println("Before << , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
i <<= 10;
System.out.println("After << , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
}
// 输出结果:
Before << , i's value is -1
i's binary string is 11111111111111111111111111111111
After << , i's value is -1024
i's binary string is 11111111111111111111110000000000
在 C/C++ 中,两种右移操作符都是 >>,对无符号整数用的是逻辑右移,对有符号整数用的是算术右移;在 Java 中,逻辑右移的操作符是 >>>,算术右移的操作符是 >>。为了方便区分,下文统一用 Java 的表示方法。
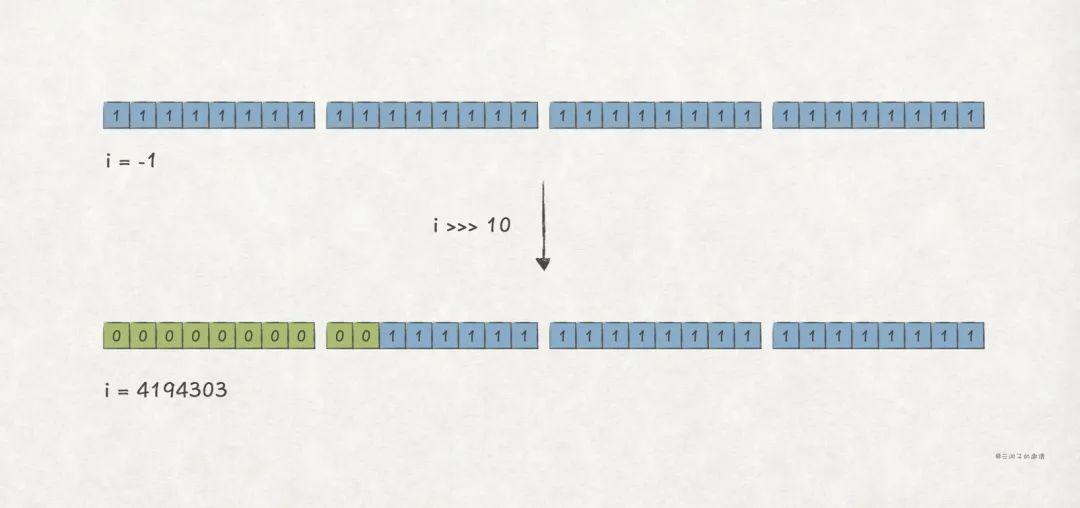
逻辑右移(>>>)运算,是对二进制整数,向右移若干位,高位补零,低位丢弃 。也即,对 逻辑左移 k 位,得到 。
比如,对 int i = -1 逻辑右移 10 位,会得到 i = 4194303 的结果:
// Java语言
public static void main(String[] args) {
int i = -1;
System.out.println("Before >>> , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
i >>>= 10;
System.out.println("After >>> , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
}
// 输出结果:
Before >>> , i's value is -1
i's binary string is 11111111111111111111111111111111
After >>> , i's value is 4194303
i's binary string is 1111111111111111111111
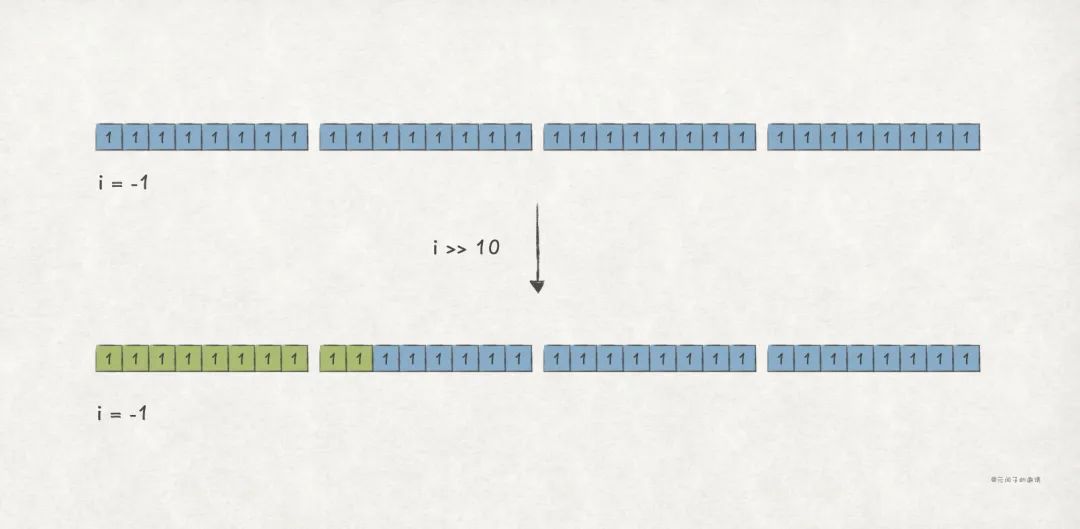
算术右移(>>)运算,是对二进制整数,向右移若干位,高位补符号位,低位丢弃 。也即,对 逻辑左移 k 位,得到 。
比如,对 int i = -1 算术右移 10 位,仍会得到 i = -1 的结果:
// Java语言
public static void main(String[] args) {
int i = -1;
System.out.println("Before >> , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
i >>= 10;
System.out.println("After >> , i's value is " + i);
System.out.println("i's binary string is " + Integer.toBinaryString(i));
}
// 输出结果:
Before >> , i's value is -1
i's binary string is 11111111111111111111111111111111
After >> , i's value is -1
i's binary string is 11111111111111111111111111111111
目前为止,介绍移位运算的原理时,我们都默认 k < w,如果 k >= w 会怎样 ?
比如, 左移 w 位,结果会是 吗:
// Java语言
public static void main(String[] args) {
int i1 = -1;
System.out.println("Before << 31, i1's value is " + i1);
System.out.println("i1's binary string is " + Integer.toBinaryString(i1));
i1 <<= 31;
System.out.println("After << 31, i1's value is " + i1);
System.out.println("i1's binary string is " + Integer.toBinaryString(i1));
int i2 = -1;
System.out.println("Before << 32, i2's value is " + i2);
System.out.println("i2's binary string is " + Integer.toBinaryString(i2));
i2 <<= 32;
System.out.println("After << 32, i2's value is " + i2);
System.out.println("i2's binary string is " + Integer.toBinaryString(i2));
}
// 输出结果:
Before << 31, i1's value is -1
i1's binary string is 11111111111111111111111111111111
After << 31, i1's value is -2147483648
i1's binary string is 10000000000000000000000000000000
Before << 32, i2's value is -1
i2's binary string is 11111111111111111111111111111111
After << 32, i2's value is -1
i2's binary string is 11111111111111111111111111111111
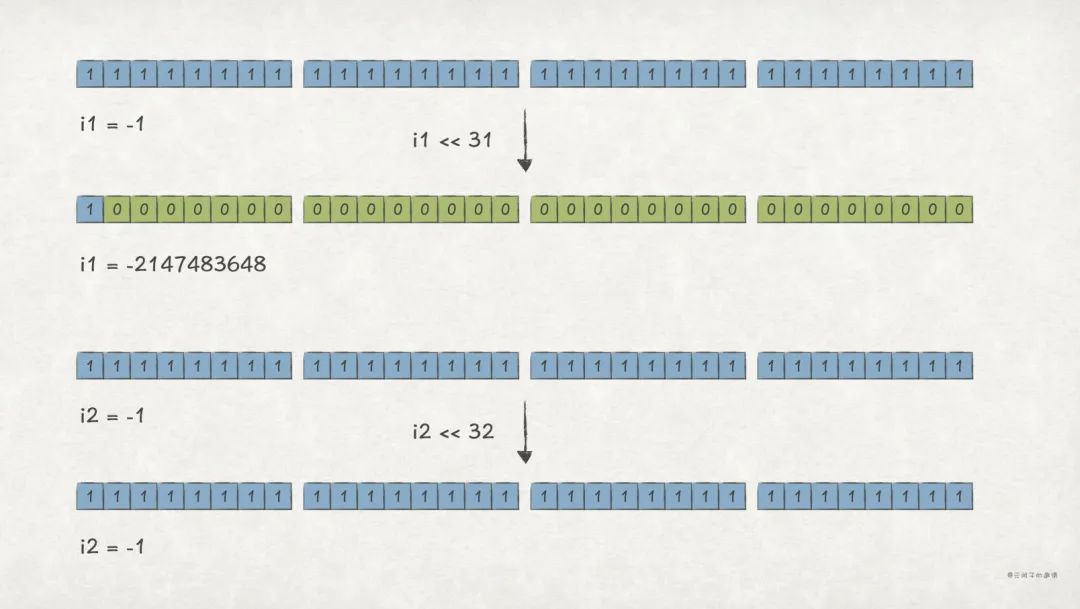
上述例子中, w = 32,我们发现 k = 31 时,结果还符合预期;当 k = 32 时,结果不是 0,而是 -1,也即相当于 k = 0 时的结果。
原因是这样,对 w 位整数 x,当执行 x << k 时,实际执行的是 x << (k % w)。所以,当 i2 << 32 时,实际是 i2 << 32 % 32 = i2 << 0。
右移操作也遵循同样的规则,也即 x >> k = x >> (k % w), x >>> k = x >>> (k % w)。
-
微处理器如何控制计算机系统2024-08-22 1958
-
计算机系统中的关键组件有哪些2024-07-15 4478
-
计算机系统对数值类型的编码、运算、转换原理介绍22023-05-09 1615
-
深入理解计算机系统的数值类型2022-08-19 2228
-
简单介绍微型计算机的组成2022-01-10 1660
-
嵌入式计算机系统概述2021-12-22 1844
-
计算机系统中的软件系统2021-09-13 2145
-
什么是计算机系统?硬件和软件哪个更重要?2021-07-26 2016
-
什么是计算机系统、计算机硬件和计算机软件?2021-07-22 2488
-
计算机系统结构2014-05-09 3213
-
微型计算机系统2010-03-03 892
-
什么是计算机系统的容错性2010-01-08 1887
-
计算机系统概论2009-04-11 1180
全部0条评论

快来发表一下你的评论吧 !
