

计算机系统对数值类型的编码、运算、转换原理介绍3
电子说
描述
浮点数
考虑如下一段代码:
// Java
public class Example {
public static void main(String[] args) {
int i = 12345;
float f = 12345.0F;
System.out.printf("binary str of i: %s\\n", int2BinaryStr(i));
System.out.printf("binary str of f: %s\\n", float2BinaryStr(f));
}
// 将int转为32位的二进制表示
private static String int2BinaryStr(int i) {
String str = Integer.toBinaryString(i);
for (int len = str.length(); len < 32; len++) {
str = "0" + str;
}
return str;
}
// 将float转为32位的二进制表示
private static String float2BinaryStr(float f) {
return int2BinaryStr(Float.floatToRawIntBits(f));
}
}
我们将整数 i = 12345 和 浮点数 f = 12345.0 转成二进制表示,结果如下:
binary str of i: 00000000000000000011000000111001
binary str of f: 01000110010000001110010000000000
虽然从十进制上看,值都是 12345,但是两种类型的二进制表示却差别很大,说明, 计算机系统对整数和浮点数的处理是两套不同的机制 。
大部分编程语言支持的整数最大是 64 位,但很多场景下,我们需要更大的取值范围,或者是小数运算,这些都是 64 位整数无法满足的场景。为了解决这些,计算机系统引入了 浮点数 ( Floating Point )类型。
浮点数类型可以分为 32 位单精度 float/float32 类型和 64 位双精度 double/float64 类型,取值范围如下:
| 类型 | 最小值 | 最大值 |
|---|---|---|
| float | -3.40282347E+38 | 3.40282347E+38 |
| double | -1.79769313486231570E+308 | 1.79769313486231570E+308 |
虽然浮点数的取值范围很广,但它只能精确表示其中一小部分,其他都是近似表示 。
下面,我们将深入介绍浮点数的二进制表示和近似规则。
简单浮点数编码
对于十进制数 ,可以表示成 ,其中,以小数点 为界,左边为整数部分,右边为小数部分,那么:
比如, 。
同理,对于二进制数 ,也可以表示成 ,同样以小数点 分割整数和小数部分,那么:
比如,。
计算机系统的这种编码方式,注定只能表示 形式的数,其他的,只能近似表示。
比如,无法精确表示 0.2:
| 二进制表示 | 分数 | 十进制表示 |
|---|---|---|
| 0.0 | 0/2 | 0.0 |
| 0.01 | 1/4 | 0.25 |
| 0.010 | 2/8 | 0.25 |
| 0.0011 | 3/16 | 0.1875 |
| 0.00110 | 6/32 | 0.1875 |
| 0.001101 | 13/64 | 0.203125 |
| 0.0011010 | 26/128 | 0.203125 |
| 0.00110011 | 51/256 | 0.19921875 |
浮点数除了表示小数之外,还须表示大数,按照这种二进制编码思路,如果要表示 ,需要 102 位,受限于计算机系统的编码长度,这显然不能接受。
其实,对 形式的数,我们只须存储 M 和 E 即可,再来一个符号位 s,即可表示这种形式的数: 。
对 w 位浮点数,可以用 1 位表示 s,用 k 位表示 E,用 n 位表示 M,那么就有 w = 1 + k + n:
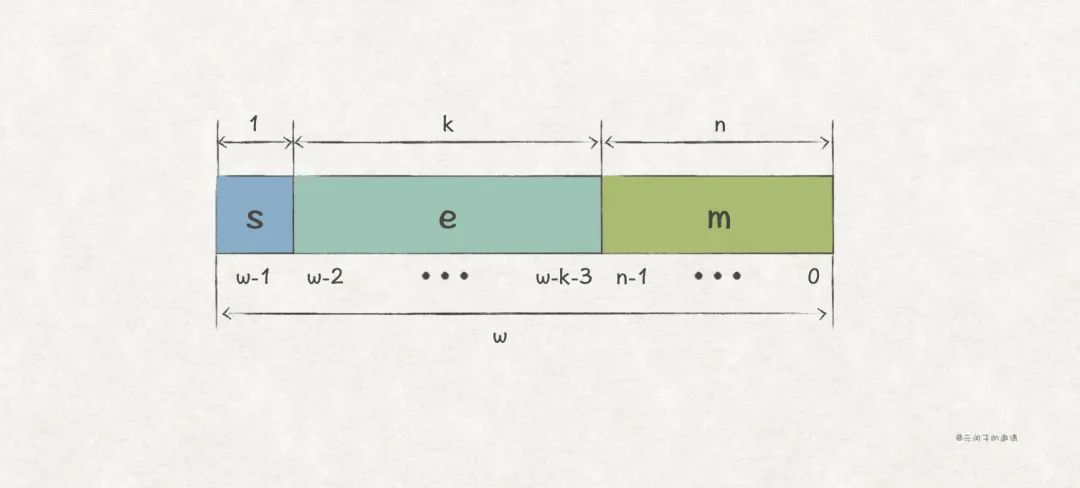
(1)s 的编码
用 0 表示正数,1 表示负数。
(2)E 的编码
二进制表示为 ,因为 E 可以是正,也可以是负,因此,可以直接用 补码 进行编码。
比如,k = 4 时,E 的取值是这样的:
| e | E |
|---|---|
| 0000 | 0 |
| 0001 | 1 |
| ... | |
| 0111 | 7 |
| 1000 | -8 |
| 1001 | -7 |
| ... | |
| 1111 | -1 |
但是,这样从 到 并不是递增的趋势。另一种方法是,对 e 用无符号编码,令 ,其中,。比如,k = 4 时,,那么 E 的取值是这样的:
| e | Bias | E |
|---|---|---|
| 0000 | 7 | -7 |
| 0001 | 7 | -6 |
| ... | ||
| 0111 | 7 | 0 |
| 1000 | 7 | 1 |
| 1001 | 7 | 2 |
| ... | ||
| 1111 | 7 | 8 |
(3)M 的编码
二进制表示为 ,M 不涉及负数,因此可以只用最高位表示整数,其他表示小数,即 。比如,当 n = 3 时,M 的取值如下:
| m | M | 十进制 |
|---|---|---|
| 000 | 0.00 | 0.00 (0/4) |
| 001 | 0.01 | 0.25 (1/4) |
| 010 | 0.10 | 0.5 (2/4) |
| 011 | 0.11 | 0.75 (3/4) |
| 100 | 1.00 | 1.00 (4/4) |
| 101 | 1.01 | 1.25 (5/4) |
| 110 | 1.10 | 1.5 (6/4) |
| 111 | 1.11 | 1.75 (7/4) |
但是, 这种编码方式会导致 0 有很多种表示 。比如 w = 8,k = 4,n = 3 时,因为 ,所以 、、 等的浮点数值都是 0。
可以这么改动,令 ,当 时,;当 时,:
| e | m | M | 十进制 |
|---|---|---|---|
| 0000 | 000 | 0.000 | 0.000 (0/8) |
| 0000 | 001 | 0.001 | 0.125 (1/8) |
| ... | |||
| 0000 | 111 | 0.111 | 0.875 (7/8) |
| 0001 | 000 | 1.000 | 1.000 (8/8) |
| 0001 | 1.001 | 1.125 (9/8) | |
| ... |
这样,既解决了 0 的表示问题,又让 M 的精度更大了 。
IEEE 浮点数编码
上述这些编码方法,就是 IEEE 754 Floating-Point Representation 标准中定义的浮点数编码方式的基本思路,标准会在此基础上做了一些调整,比如新增了 Infinity 和 NaN 的表示。
IEEE 标准将浮点数分成 单精度 和 双精度 两种,分别用 32 位和 64 位表示,它们的 k 值和 n 值都不同:

在此基础上,根据 e 的取值不同,又分为 3 种场景, Denormalized Values 、 Normalized Values 、 Special Values :
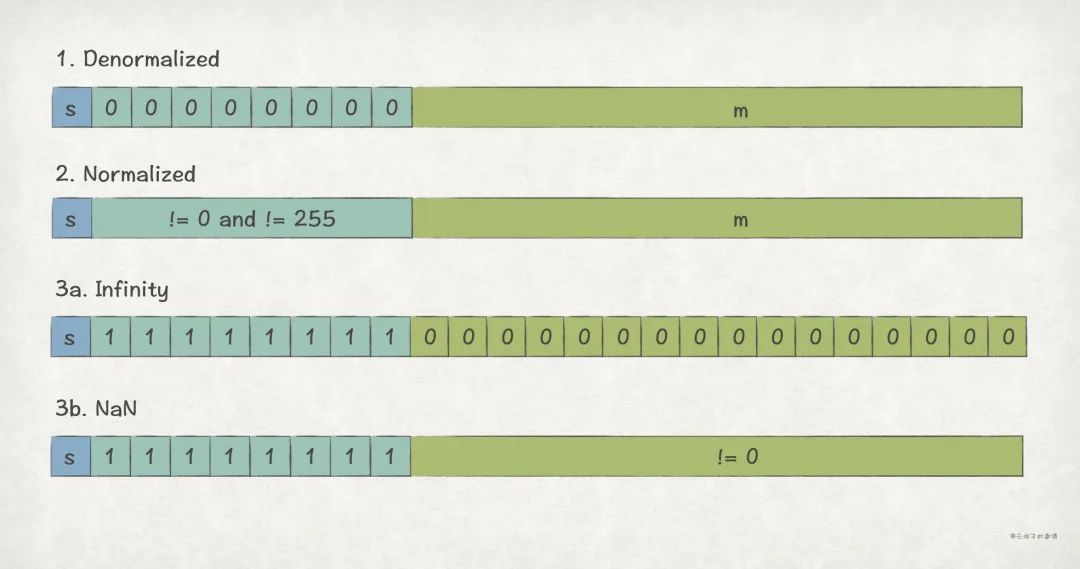
(1)Denormalized Values
此场景下,e 取值为全 0, 用来表示 0 值,以及接近 0 的小数 。
在 的表示下,,。
为什么 ,而不是 E = -Bias ?
根据前文分析,应该有 E = e - Bias,但 Denormalized Values 中,确是 E = 1 - Bias,而不是 E = 0 - Bias。
这主要考虑到,从 Denormalized Values 到 Normalized Values 的平滑过度,让 Largest Denormalized Value 和 Smallest Normalized Value 更接近。后面的举例可以看到。
这里,0 分为了 -0.0 和 +0.0,在一些科学计算场景下,它们会表示不同的含义。比如 ,。
(2) Normalized Values
此场景下,e 取值不是全 0,也不是全 1,是最常见的场景。
在 的表示下,,。
(3)Special Values
此场景下,e 取值为全 1,用来表示 Infinity 和 NaN。
- m 取值全 0,表示 Infinity:1)s = 0 时,为 ;2)s = 1 时,为 。
- m 取值不是全 0,表示 NaN(Not a Number),比如 或者 。
比如,w = 8,k = 4(此时,),n = 3 时,IEEE 标准浮点数的编码例子如下:
| 场景 | 二进制 | e | E | m | M | 十进制 | ||
|---|---|---|---|---|---|---|---|---|
| Denormalized | 0 0000 000 | 0 | -6 | 1/64 | 0/8 | 0/8 | 0/512 | 0.0 |
| 0 0000 001 | 0 | -6 | 1/64 | 1/8 | 1/8 | 1/512 | 0.001953 | |
| ... | ||||||||
| 0 0000 111 | 0 | -6 | 1/64 | 7/8 | 7/8 | 7/512 | 0.013672 | |
| Normalized | 0 0001 000 | 1 | -6 | 1/64 | 0/8 | 8/8 | 8/512 | 0.015625 |
| 0 0001 001 | 1 | -6 | 1/64 | 1/8 | 9/8 | 9/512 | 0.017578 | |
| ... | ||||||||
| 0 1110 111 | 14 | 7 | 128 | 7/8 | 15/8 | 1920/8 | 240.0 | |
| Infinity | 0 1111 000 | - | - | - | - | - | - | |
| NaN | 0 1111 001 | - | - | - | - | - | - | NaN |
| ... | NaN |
从上表可以看出,因为 Denormalized 场景下令 E = 1 - Bias,从 Denormalized 到 Normalized 的过度,也即 7/512 到 8/512,更平滑了。如果令 E = - Bias,则是从 7/1024 到 8/512,跨度太大。
到这里,我们已经深入介绍了 IEEE 浮点数编码格式,回到本节最开始的例子,如何从 int i = 12345 的二进制表示,推断出 float f = 12345.0 的二进制表示?
- 首先,12345 整数的二进制表示为 ,也可以表示成 ,对应到 的形式,可以确认 s = 0,E = 13,M = 1.1000000111001。
- 另外,12345 属于 Normalized 场景,而 float 类型中 k = 8,有,,得出 e = 140,按 k 位无符号编码表示为 。
- 同理,由 ,float 类型中,n = 23,所以,得出 m 的二进制表示为 ,注意, 低位补零 。
- 最后将 s、e、m 按照 float 单精度的编码格式组合起来,就是 ,也即 12345.0 的二进制编码。
近似规则(Rounding)
前面说过,浮点数只能表示 形式的数,其他的,只能近似表示。
近似规则,我们最熟悉的是 “ 四舍五入 ”,比如,要保留 2 位小数,那么 1.234、1.235、1.236 近似之后分别是 1.23、1.24、1.24。
IEEE 浮点数标准中,并没采用 “四舍五入” 法,定义了如下 4 种近似规则:
- Round-to-even ,往更近的方向靠,如果向上和向下的距离一样,则往偶数的方向靠。
- Round-toward-zero ,往 0 的方向靠。
- Round-down ,往更小的方向靠。
- Round-up ,往更大的方向靠。
比如,下面的例子,需要近似为整数:
| 规则 | 1.40 | 1.60 | 1.50 | 2.50 | -1.50 |
|---|---|---|---|---|---|
| Round-to-even | 1 | 2 | 2 | 2 | -2 |
| Round-toward-zero | 1 | 1 | 1 | 2 | -1 |
| Round-down | 1 | 1 | -2 | ||
| Round-up | 2 | 2 | 3 | -1 |
这些规则对二进制也生效,比如,Round-to-even 规则,在二进制中,0 代表偶数,1 表示奇数。下面例子中,需要按照 Round-to-even 近似保留 2 位小数:
| 二进制(十进制) | 向下 | 中点 | 向上 | Round-to-even |
|---|---|---|---|---|
| 10.00011 (67/32) | 10.00 (64/32) | 68/32 | 10.01 (72/32) | 10.00 (64/32) |
| 10.00110 (70/32) | 10.00 (64/32) | 68/32 | 10.01 (72/32) | 10.01 (72/32) |
| 10.11100 (23/8) | 10.11 (22/8) | 23/8 | 11.00 (24/8) | 11.00 (24/8) |
| 10.10100 (21/8) | 10.10 (20/8) | 21/8 | 10.11 (22/8) | 10.10 (20/8) |
上述例子中,前 2 个按照就近原则近似;后 2 个处于中点位置,往偶数方向靠。
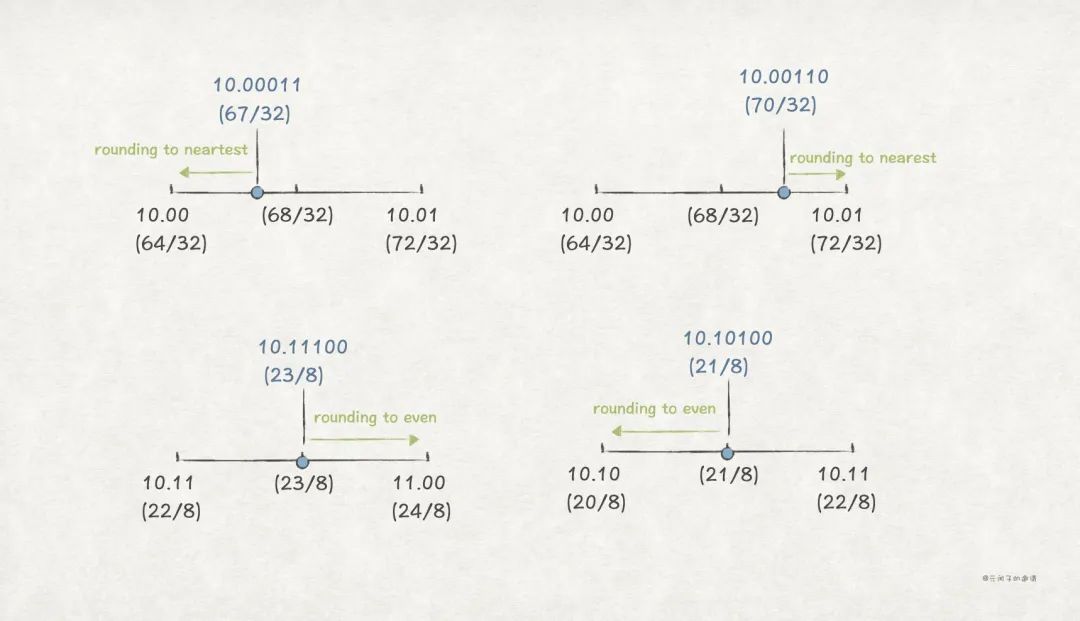
注意, IEEE 标准规定 Round-to-even 为默认的近似规则 。
浮点数运算
浮点数的运算规则比较简单,令 指代后一类的运算符,x 和 y 为浮点数类型,那么 的运算结果为 ,也即对真实计算结果进行近似。
注意,算术运算的 结合律 、分配率在浮点数运算下是不生效的,比如:
// Java
public static void main(String[] args) {
// 结合律不满足示例
float f1 = 3.14F;
float f2 = 1e10F;
float f3 = (f1 + f2) - f2;
float f4 = f1 + (f2 - f2);
System.out.printf("(3.14 + 1e10) - 1e10 = %f\\n", f3);
System.out.printf("3.14 + (1e10 - 1e10) = %f\\n", f4);
// 分配律不满足示例
float f5 = 1e20F;
float f6 = f5 * (f5 - f5);
float f7 = f5 * f5 - f5 * f5;
System.out.printf("1e20 * (1e20 - 1e20) = %f\\n", f6);
System.out.printf("1e20 * 1e20 - 1e20 * 1e20 = %f\\n", f7);
}
// 输出结果
(3.14 + 1e10) - 1e10 = 0.000000
3.14 + (1e10 - 1e10) = 3.140000
1e20 * (1e20 - 1e20) = 0.000000
1e20 * 1e20 - 1e20 * 1e20 = NaN
结合律例子中,(3.14+1e10)-1e10 结果是 0,因为 3.14 在近似时,精度丢失了,也即 3.14+1e10=1e10;类似,分配律例子中,1e20*1e20 的结果超出了 float 类型的表示范围,得到 Infinity,而 Infinity - Infinity 的结果是 NaN。
注意, 浮点数运算结果,如果超出了浮点数表示范围,会得到 Infinity/-Infinity 。这与整数运算的溢出机制有所区别。
-
微处理器如何控制计算机系统2024-08-22 1958
-
计算机系统中的关键组件有哪些2024-07-15 4478
-
计算机系统对数值类型的编码、运算、转换原理介绍12023-05-09 1818
-
深入理解计算机系统的数值类型2022-08-19 2228
-
简单介绍微型计算机的组成2022-01-10 1660
-
嵌入式计算机系统概述2021-12-22 1844
-
计算机系统中的软件系统2021-09-13 2145
-
什么是计算机系统?硬件和软件哪个更重要?2021-07-26 2016
-
什么是计算机系统、计算机硬件和计算机软件?2021-07-22 2488
-
计算机系统结构2014-05-09 3213
-
微型计算机系统2010-03-03 892
-
什么是计算机系统的容错性2010-01-08 1889
-
计算机系统概论2009-04-11 1180
全部0条评论

快来发表一下你的评论吧 !
