

用VCS跑simulation hang住了该怎么办?
电子说
描述
最近遇到一个棘手的问题,用VCS跑simulation hang住了。
遇到此类问题,我第一个想到的是去打印一些log看看,比如设置定时打印,调高UVM打印级别等。我在仿真环境里面设置定时打印log的信息,发现hang住之后不会打印了。由此猜测是环境里面存在0延时的死循环,导致仿真无法继续推前。
VCS提供了ucli可以进行单步调试,如果遇到0延时的死循环,理论上进行单步调试的时候,会循环的执行某一段代码。但是考虑到可能涉及到的循环逻辑比较多,单纯用手工单步调试会非常困难。如果用脚本自动运行几千行,然后将单步调试的结果保存在log文件中,将非常有助于分析出死循环的代码。对于这种想法网友已经用tcl脚本实现。让我们看看网友怎么用loop detect的方式寻找0延时的死循环。
第一步用vcs -debug_all 编译文件。
第二步用simv -ucli 执行文件
第三步在ucli界面里面source loop_detect.tcl 这个 tcl文件
Loop_detect.tcl 的文件内容如下
#!/usr/bin/tclsh
proc loop_detect(args) {
set help"-help"
if{[stringequal $args $help] != 1} {
configfollowactivescope on
set i 0;
while {$i< $args} {
run_step
incr i
}
}
else {
puts"Usage: loop_detect
}
}
proc run_step{} {
redirect -floop.txt -a {set x [step]};
redirect -floop.txt -a {set y [scope]};
puts $x;
puts $y;
}
第四步在ucli 里面用run {time} 执行到hang住的地方,比如simulation 是在1000ns的地方hang住了,可以用run1000ns 执行到此处。
第五步在ucli里面用loop_detect {number of steps} 检查hang住的原因,比如我用loop_detect 1000 则表示单步执行了1000次,并将每步的结果存在loop.txt 中。然后从loop.txt 中查看是否有0延时的死循环。
我的问题用这种方法寻找到了0延时的死循环逻辑。如果通过上面五步,在loop detect中没有看到死循环怎么办,还有其他办法吗?这可能需要借助 Verdi和VCS进行联合仿真了。怎么用Verdi和VCS进行单步调试呢?
第一步用 vcs -debug_access+all -kdb -lca进行编译
第二步用 simv -gui=verdi启动联合单步调试
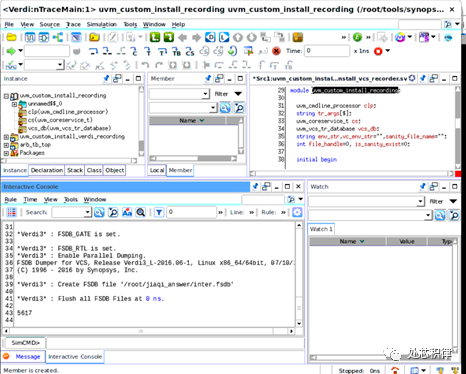
通过verdi进行单步调试,让debug变比较容易。
如果通过Verdi和VCS联合单步调试还没发现问题呢?各位同行们还有什么手段,欢迎各位留言讨论。
审核编辑:刘清
-
vcs和vivado联合仿真2025-10-24 442
-
请问protuse8出现“fatal simulation error encounlered”应该怎么办2016-04-20 75793
-
诺基亚n70白屏怎么办2008-09-01 3784
-
显示桌面没了怎么办2010-01-18 4188
-
本本发热导致“发烧” 那该怎么办呢?2010-01-26 1827
-
NTDETECT失败怎么办2010-02-25 2245
-
若忘记了Linux系统的root密码,该怎么办?2018-10-15 13637
-
电池换新无法可依怎么办2019-03-19 1967
-
日常运营中网站受到安全威胁时该怎么办2019-11-16 866
-
linux无法识别U盘怎么办2020-05-19 17903
-
锡浆(锡膏)干了怎么办?用什么稀释?2022-05-31 9048
-
电机过热怎么办?2023-11-01 1851
-
pcb钻孔偏孔了怎么办?2023-11-22 6736
-
风机轴磨损怎么办2024-01-07 558
-
工控主板发生故障该怎么办?2024-04-11 1800
全部0条评论

快来发表一下你的评论吧 !
