

机器学习应该学习哪些 人工智能技术学习路线分享
人工智能
描述
每一波浪潮的到来,都意味一片无人占领的蓝海,也意味着众多新成长起来的巨头,还意味着什么?大量的技术人员需求,供不应求的开发市场,以及从业者的高薪与众多的机会。
我们最常做的事情是目送着上一次浪潮的余波远去,感叹自己生不逢时,却没有意识到,下一波浪潮已经到了我们脚下。
没错,我们说的就是AI。
身在IT圈中的人,应该都有着直观的认识。目前国内知名的互联网企业无一不在建立自己的人工智能技术团队,以期用AI技术,提升产品的体验和智能化程度。
但与此同时,各种不明觉厉的名词也吓退了很多非科班出身的开发者。什么叫卷积神经网络?什么叫凸优化?是不是还要回去重读高数,线代,概率?那么一大堆公式,感觉完全看不懂啊?听说没个名校博士出身都搞不了这个?
在很久以前的一篇知乎回答中提过,作为开发人员,AI领域界在我看来会分成这么几个层次
1. 学术研究者
他们的工作是从理论上诠释机器学习的各个方面,试图找出“这样设计模型/参数为什么效果更好”,并且为其他从业者提供更优秀的模型,甚至将理论研究向前推进一步。能够做到这一步的人,可以说凤毛麟角,天赋是绕不过去的大山,机遇和努力也缺一不可。
2. 算法改进者
他们也许无法回答出“我的方法为什么work”,也许没有Hinton,LeCun那样足以载入史册的重大成果,但是却能根据经验和一些奇思妙想,将现有的模型玩出更好的效果,或者提出一些改进的模型。这些人通常都是各个机器学习巨头公司的中坚力量或者成长中的独角兽,使用什么模型对他们来讲也不是问题,根据所处的环境,通常都有固定的几个选择。在这个层面,insight和idea才是重要的东西,各种工具的区别,影响真的没那么大。可能会让一个结果早得到或者晚得到几天或者几周,却不可能影响“有没有成果”。
3. 工业实现者
这些人基本上不会在算法领域涉入太深,也就是了解一下各个算法的实现,各个模型的结构。他们更多地是根据论文去复现优秀的成果,或者使用其他人复现出来的成果,并且试图去在工业上应用它。
对于大部分IT人来说,做到第三类,也就是工业实现这个层面,已经足够好了,至少,我们已经有了亲身参与这个大时代的机会,仅就这一点来说,便已经击败了全国99%的人(斜眼笑的表情)。
不光是普通程序猿这么说,文艺的程序猿和……额,高大上的程序猿也都这么说。
我说,呵呵。
答案只有一个:Just Do IT(去搞IT吧,少年)
成为人工智能工程师,在我看来,要把机器学习、深度学习掌握好,就可以入行拼搏了!另外,理论必须要结合项目实战:因为作为程序员,读十遍书不如跑一遍程序,与其花费大量的时间去啃书本,不如亲手完成自己的程序并运行它。我们在写出代码的同时,就会了解到自己还有哪些地方不够清楚,从而针对性地学习。
02
我们先来说说,机器学习应该学习哪些。
学习任何东西,勿在浮沙筑高台(对这句话眼熟的请举手),有一些基础的知识还是需要掌握的。例如在计算机视觉领域,根据我们团队内部培训的经验,为了能够独立进行机器学习的开发工作,最好首先完成这么几项课程:
1. 入门机器学习:
熟悉机器学习领域的经典算法、模型及实现的任务等,同时学习搭建和配置机器学习环境,并学会用 线性回归 解决一个实际问题。
2. Logistic回归分析、神经网络、SVM:
掌握数据集探索;理解分类任务算法(Logistic回归、神经网络、SVM)原理;学会在scikit-learn框架下采用各分类算法分类具体任务。
3. 决策树模型与集成学习算法:
损失函数:信息增益、Gini系数;划分:穷举搜索、近似搜索;正则:L2/L1;预防过拟合:预剪枝及后剪枝;Bagging原理;Boosting原理;流行的GBDT工具:XGBoost和LightGBM
4. 聚类、降维、矩阵分解:
主成分分析(PCA);独立成分分析(ICA);非负矩阵分解(NFM);隐因子模型(LFM);KMeans聚类和混合高斯模型GMM(EM算法);吸引子传播聚类算法(Affinity Propagation聚类算法)
5. 特征工程、模型融合& 推荐系统实现:
学会常用数据预处理方法及特征编码方法;学习特征工程的一般处理原则;组合各种特征工程技术和机器学习算法实现推荐系统。
上面的课程大概会消耗你1个月多的所有业余时间。但是相信我,这是值得的。
如果实在连一两个月的业余时间都拿不出来,好吧,我来偷偷告诉你最最最基本的一个要求,满足了这个要求,你就能够算是机器学习入门了: 会算矩阵乘法
别笑,说正经的,在这个框架高度封装的年代,梯度不需要自己算,损失不需要自己求,反向传导更是被处理得妥妥的,在不求甚解的情况下,你甚至只需要知道这么几个概念就可以开始着手写第一个程序了:
它就是通过一系列矩阵运算(或者类似的一些其他运算)将输入空间映射到输出空间而已。参与运算的矩阵的值称为权重,是需要通过不断迭代来寻找到最优值。
当前的权重值离最优值还差多远,用一个数值来表示,这个值就叫损失,计算这个值的函数叫损失函数。
当前的权重值应该调大还是调小,这个值通过对损失函数求导来判断,这个求导得到的函数叫做梯度。
通过损失和梯度来更新权重的方法叫做反向传导。
迭代的方法称为梯度下降。
虽然这么写出来的程序一定是不知其所以然,但是其实20年前我第一次用C++写Hello world的时候也是一脸懵逼的,我相信,每个能够投身机器学习开发工作的程序猿,都是有大毅力大勇气的,自然不会欠缺继续学习的动力和决心。
03
我们再来说说,深度学习应该学习哪些。
深度学习着重掌握卷积神经网络和循环神经网络,使用大量真实的数据集,结合实际场景和案例介绍深度学习技术的应用范围与效果。
1. 神经网络入门及深度学习环境配置:
熟悉神经网络领域的常用术语、安装并配置深度学习框架Tensorflow,学会用Tensorflow解决一个实际问题。
2. 神经网络基础及卷积神经网络原理:
使用不同结构的神经网络结构验证网络结构对效果的影响;了解卷积神经网络的相关概念和基础知识,并通过实战案例理解CNN局部相关性与权值共享等特性。
3. 卷积神经网络实战:
图像分类及检测任务:学习图像分类任务及检测任务目前主要模型算法,并通过两个实战案例学习在Tensorflow框架下训练CNN模型。
4. 卷积神经网络之图像分割实例:
掌握分割任务简介、反卷积(deconv/transpose-conv)、FCN
5. 循环神经网络原理:
RNN基本原理
门限循环单元(GRU)
长短期记忆单元(LSTM)
词向量提取:Word2Vec
编码器—解码器结构
注意力机制模型:Attention Model
图片标注(Image Captioning)
图片问答(Visual Question Answering)
04
恭喜你,成为人工智能工程师群中的一员了
接下来就可以收集一些自己的数据,并且训练一些自己的识别引擎;或者尝试着优化这个模型,感受一下所谓调参党的痛苦;又或者直接尝试实现ResNet、Inception这些更为先进的网络来刷刷Cifar;再不然可以尝试着向NLP或者强化学习方向去学习一下。总之,这些事情远没有看起来那么难。
当然,不论那条路,学习,进步和自我鞭策都是逃避不掉的必修课。一个新生的领域,勃勃的生机必然也意味着新成果的层出不穷。完成我上面提到的三门课程只能让一个人从门外汉变成圈里人,有了进入这个领域,赶上这波浪潮的基本资格,至于到底是成为弄潮儿还是直接被大浪吞没,还是那句话,不劳苦必然无所得。努力学习不一定能修成正果,而不去努力学习,则注定是一无所获。
最后,祝福,祝福各位能在AI领域里大放异彩。
附技术学习路线图:
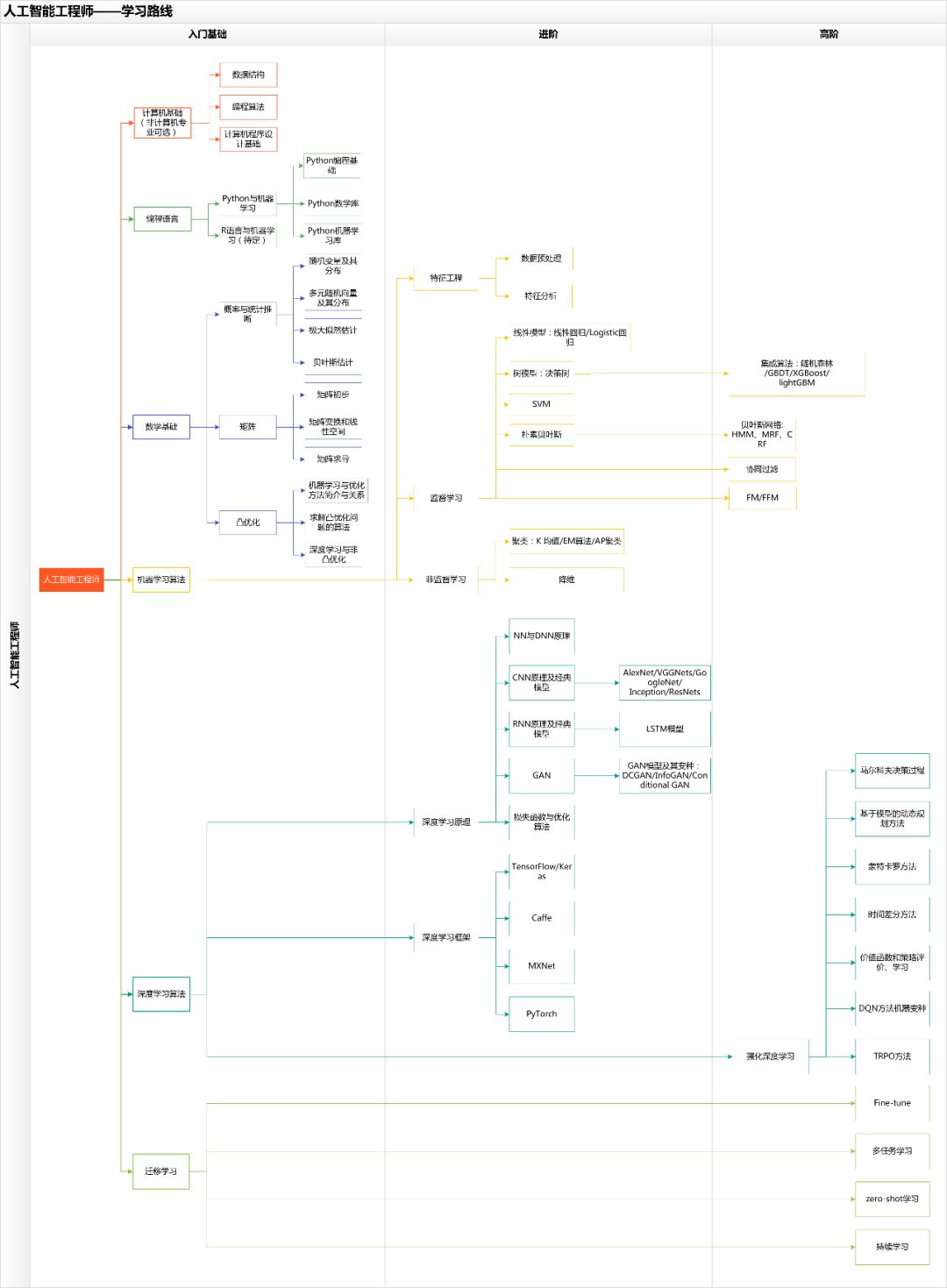
编辑:黄飞
-
【第一届中国AI与机器学习研讨会】微软领衔人工智能大咖共同探讨AI与机器学习2018-03-15 13680
-
人工智能技术—AI2015-10-21 9796
-
人工智能和机器学习的前世今生2018-08-27 3601
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2860
-
python人工智能/机器学习基础是什么2020-04-28 3242
-
人工智能和机器学习技术在2021年的五个发展趋势2021-01-27 4875
-
人工智能基本概念机器学习算法2021-09-06 2786
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4712
-
嵌入式人工智能学习路线2022-09-16 4542
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2384
-
《移动终端人工智能技术与应用开发》+理论学习2023-02-27 24472
-
机器学习和人工智能有什么区别?2023-04-12 1254
-
浅谈人工智能,机器学习,深度学习三者关系2018-07-01 2454
-
机器学习是如何工作的? 人工智能与机器学习实例2020-02-08 2537
-
人工智能与机器学习、深度学习的区别2023-03-29 2653
全部0条评论

快来发表一下你的评论吧 !
