

如何设计MLIR的Dialect来在GPU上生成高性能的代码?
电子说
描述
前言
为什么又要开一个新坑?原因是,最近在做的项目都是和MLIR有关,并且发现自己已经在MLIR的研发道路上越走越远了。刚刚好前段时间大家都在跟风各种GPT,就去看了看openai目前放出来的产品,无意间发现了triton这把瑞士军刀。其实早在一些年前就听过triton,那会的triton代码还没有被MLIR进行重构,代码内部的某些逻辑写的也没有看的很明白,结合"Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations"这篇论文其实也没有看出太多新的东西。这次在重新捡起来看的时候,发现其中很多不错的优化,其实还是抱着学习如何设计MLIR的Dialect来在GPU上生成高性能的代码为初衷,来对triton进行一个深入的分析。
什么是Triton?
Triton是openai针对gpu上的算子优化提出的一个programming language & compiler。以NVIDIA GPU为例,使用triton可以越过cuda的闭源生态,直接将自己的后端接入llvm IR,通过走NVPTX来生成在GPU上的代码。这样做相比传统的手写cuda代码的好处是可以不需要借助NVIDIA的nvcc compiler就可以得到在GPU上能跑的machine code。同时,triton的一些设计理念对于 不管是深度学习领域还是其他数据科学领域来做高性能计算来说都可以提供丰富的指导意义。同时,triton不仅仅只支持nv的gpu,它同时对amd的gpu,intel的gpu都会推出后续的支持方案,这其所就彰显出了mlir的优势,可以通过设计Dialect来支持更多的后端。
源码编译Triton
接下来带大家一起从源码来编译下triton的代码,后续我准备分为几章,对triton的设计以及具体的优化细节展开分析,能够给大家一个较为全面的理解。毕竟triton作为mlir中为数不多成功的end-to-end的例子,对于编译技术和系统优化的研究者或者工程师来说,都是不可或缺的好资料了。
0x0 先去官网clone triton的官方repo
$ git clone https://github.com/openai/triton.git $ cd triton $ git checkout 132fe1bb01e0a734d39c60835c76da257dbe7151
0x1 安装第三方依赖
Triton 整个源码编译的过程中,需要使用到两个最为重要的依赖,一个是llvm,一个是pybind11,我在编译和构建triton的过程中,都是通过手动将llvm和pybind11编译安装好后,在编译triton的过程中通过CMakLists.txt来指定对应的路径。
0x10 LLVM的下载与配置
为什么要使用llvm?其实大家都知道,这就是triton最吸引人的地方,通过将高层的python代码一步一步lower到llvm IR,然后通过llvm生态得到最终可以跑在具体设备上的machine code,将llvm作为最重要的后端,并且triton内部的实现也被MLIR进行重构,MLIR刚刚好也是llvm中非常重要的一个子项目。那么,llvm的安装对于想要基于triton来进行二次开发的工程师或者研究人员来说就显得非常重要了。
$ git clone https://github.com/llvm/llvm-project $ cd llvm-project $ git checkout f733b4fb9b8b $ mkdir build $ cd build $ cmake -G Ninja ../llvm -DLLVM_ENABLE_PROJECTS=mlir -DLLVM_BUILD_EXAMPLES=ON -DLLVM_TARGETS_TO_BUILD="X86;NVPTX;RISCV;AMDGPU" -DMLIR_ENABLE_CUDA_RUNNER=ON -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=ON -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLLVM_ENABLE_RTTI=ON -DLLVM_INSTALL_UTILS=ON -DMLIR_INCLUDE_INTEGRATION_TESTS=ON ninja -j8 sudo ninja install
经过一定时间的等待,就可以将llvm装好了
0x11 pybind11的下载与配置
为什么要使用pybind11?pybind11已经是目前主流的ai开发工具中必不可少的组件了。大部分的框架都以python的DSL暴露给用户,然后用户通过写对应的python语法,调用已经用C++/CUDA或者assemble写好的高性能组件。那么,装配pybind11的目的就是为了能够让我们通过import triton,然后丝滑调用对应的python api来完成高性能算子生成的任务。
$ pip install pytest $ git clone https://github.com/pybind/pybind11.git $ cd pybind11 $ mkdir build $ cd build $ cmake .. $ make check -j 8 $ sudo make install
0x2 编译Triton
$ cd triton $ vim CMakeLists.txt (option(TRITON_BUILD_PYTHON_MODULE "Build Python Triton bindings" ON)) $ mkdir build $ cd build $ cmake .. $ make -j8
 img
img
编辑切换为居中
添加图片注释,不超过 140 字(可选)
可以看到最终生成了一个.so文件,libtriton.so
那么接下来只要将libtriton.so文件移动到triton/python/triton/_C目录下,将triton的python路径下入bashrc
export TRITON_HOME=/home/Documents/compiler/triton
export PYTHONPATH=$TRITON_HOME/python:${PYTHONPATH}
然后通过简单的import triton,没有任何错误则可以通过triton进行开发了
 img
img
编辑切换为居中
添加图片注释,不超过 140 字(可选)
接下来进入triton/python/tutorials,随便找一个例子进行验证,这里我们选择最常见和实用的03-matrix-multiplication.py,直接python 03-matrix-multiplication.py,稍等片刻则可以得到最终结果。
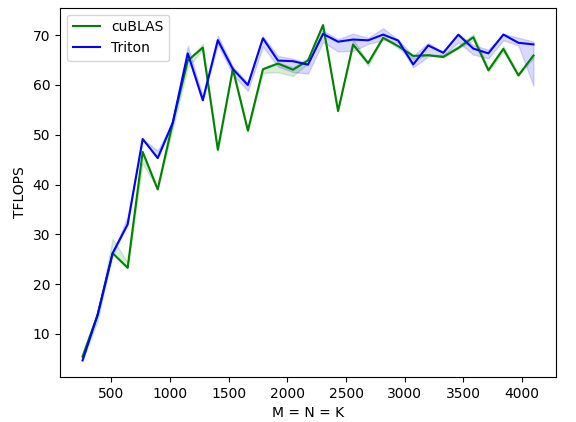 img
img
编辑
添加图片注释,不超过 140 字(可选)
可以看到,triton最终生成的代码,在3090上,对应单batch的gemm在部分size上已经超过了cuBLAS。
同时,可以在build目录下去检查对应的三个bin tool: triton-opt, triton-reduce, triton-translate
然后将本机下的ptxas复制到该build目录下,我的ptxas在(/usr/local/cuda-11.6/bin)下。关于这些工具的使用将会在后续的解读中根据不同层的dialect之间的conversion来进行详细介绍。
0x3 为什么采用这样的编译方式?
其实有的同学说,直接按照triton教程里的pip install -e . 不就行了么?这样做的原因是因为后续我们需要对triton以及对应的llvm进行改进,每次改进后,都需要对triton和llvm分别进行编译。这种分离的方式,可以使得我们在改进完对应的llvm代码或者triton的源码后,分步编译,然后再整合成一个新的shared library (libtriton.so)
在后续的教程中,我将会从triton的frontend, optimizer,backend来作为切入点,分别讲讲triton是如何通过将用户手写的python dsl编译成能跑在gpu上的machine code的。
Triton目前的设计
从triton的源码来看,triton目前在NV的GPU上已经有了一套自己比较成熟的mapping路线,通过先对python语言层,也就是triton DSL进行抽象,得到AST,然后将AST中的每个节点lower到Triton Dialect上,Triton Dialect则是一个比较贴近上层语言表达的IR,他的主要作用则是为了保持用户在书写对应算法时的准确性。接下来会进一步被map到TritonGPU Dialect上,那么TritonGPU Dialect则是一个更加贴近GPU层面的IR,它则是为了具体的性能优化而设计。图中其他的蓝色模块,比如SCF,Arith,Tensor等都是MLIR生态中已经被实现好并且广为使用的Dialect。
这些Dialect会一起和TritonGPU Dialect共存,然后被lower到对应的LLVM Dialect,LLVM Dialect则是最贴近LLVM IR的一层设计,从LLVM Dialect到LLVM IR的转换是非常容易的,最终代码就会被接入到LLVM的NVPTX的后端,从而生成后续能跑在GPU上的高性能machine code.
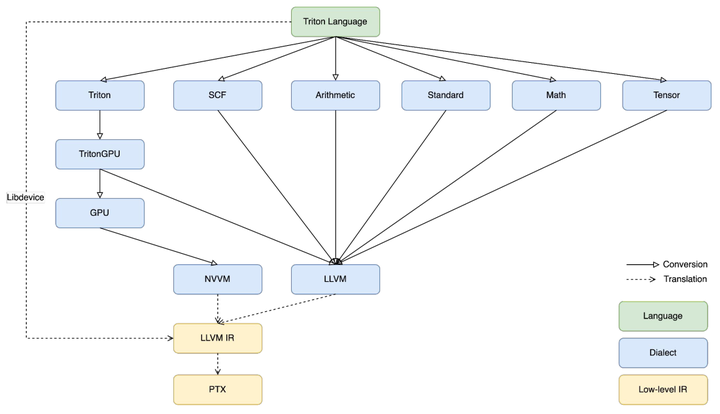 img
img
编辑切换为居中
添加图片注释,不超过 140 字(可选)
Triton 未来的支持
通过下图可以看到,triton的未来计划和大多数的compiler有着一样的发展蓝图,向上去支持各种各样具有不同表达能力的前端。向下对接各种不同厂商的hardware,最终将一个application高效的map到一个硬件上。
从哦的
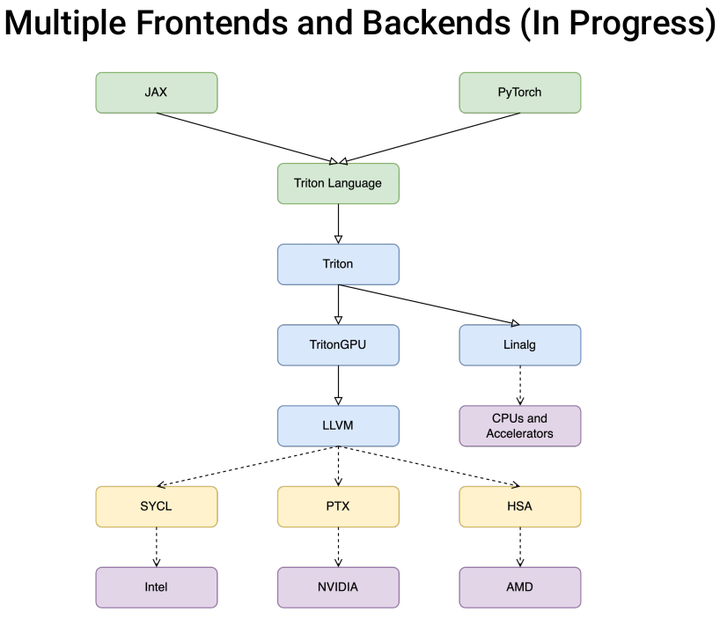 img
img
编辑切换为居中
审核编辑:刘清
-
 jf_06890261
2023-08-01
0 回复 举报good 收起回复
jf_06890261
2023-08-01
0 回复 举报good 收起回复
-
TPU-MLIR开发环境配置时出现的各种问题求解2024-01-10 1190
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理2025-06-18 1796
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 5179
-
探求NVIDIA GPU极限性能的利器2022-10-11 2741
-
智能网卡简介及其在高性能计算中的作用2023-07-28 1628
-
【开源硬件】从PyTorch到RTL - 基于MLIR的高层次综合技术2022-11-24 3051
-
Claude在MLIR代码分析上完全超越了ChatGPT2023-04-19 2110
-
Claude在MLIR代码分析上完全超越了ChatGPT并表现十分惊艳2023-04-24 4073
-
TPU-MLIR之量化感知训练2023-08-21 1771
-
如何适配新架构?TPU-MLIR代码生成CodeGen全解析!2023-11-02 3304
-
GPU高性能服务器配置2024-10-21 1684
-
MAX17409:高性能GPU的电源控制利器2026-03-17 284
-
沐曦股份联合上海人工智能实验室发布高性能GPU算子生成系统Kernel-Smith2026-04-08 483
-
华为鸿蒙正式开源SimpleGPULayer高性能GPU加速框架2026-06-01 1005
-
摩尔线程MusaCoder开源:首个基于国产全功能GPU全栈训练的代码大模型,性能比肩国际SOTA2026-06-10 152
全部0条评论

快来发表一下你的评论吧 !
