

深度剖析SQL中的Grouping Sets语句2
电子说
描述
Expand 算子的实现
Expand 算子在 Spark SQL 源码中的实现为 ExpandExec 类(Spark SQL 中的算子实现类的命名都是 XxxExec 的格式,其中 Xxx 为具体的算子名,比如 Project 算子的实现类为 ProjectExec),核心代码如下:
/**
* Apply all of the GroupExpressions to every input row, hence we will get
* multiple output rows for an input row.
* @param projections The group of expressions, all of the group expressions should
* output the same schema specified bye the parameter `output`
* @param output The output Schema
* @param child Child operator
*/
case class ExpandExec(
projections: Seq[Seq[Expression]],
output: Seq[Attribute],
child: SparkPlan)
extends UnaryExecNode with CodegenSupport {
...
// 关键点1,将child.output,也即上游算子输出数据的schema,
// 绑定到表达式数组exprs,以此来计算输出数据
private[this] val projection =
(exprs: Seq[Expression]) => UnsafeProjection.create(exprs, child.output)
// doExecute()方法为Expand算子执行逻辑所在
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
// 处理上游算子的输出数据,Expand算子的输入数据就从iter迭代器获取
child.execute().mapPartitions { iter =>
// 关键点2,projections对应了Grouping Sets里面每个grouping set的表达式,
// 表达式输出数据的schema为this.output, 比如 (quantity, city, car_model, spark_grouping_id)
// 这里的逻辑是为它们各自生成一个UnsafeProjection对象,通过该对象的apply方法就能得出Expand算子的输出数据
val groups = projections.map(projection).toArray
new Iterator[InternalRow] {
private[this] var result: InternalRow = _
private[this] var idx = -1 // -1 means the initial state
private[this] var input: InternalRow = _
override final def hasNext: Boolean = (-1 < idx && idx < groups.length) || iter.hasNext
override final def next(): InternalRow = {
// 关键点3,对于输入数据的每一条记录,都重复使用N次,其中N的大小对应了projections数组的大小,
// 也即Grouping Sets里指定的grouping set的数量
if (idx <= 0) {
// in the initial (-1) or beginning(0) of a new input row, fetch the next input tuple
input = iter.next()
idx = 0
}
// 关键点4,对输入数据的每一条记录,通过UnsafeProjection计算得出输出数据,
// 每个grouping set对应的UnsafeProjection都会对同一个input计算一遍
result = groups(idx)(input)
idx += 1
if (idx == groups.length && iter.hasNext) {
idx = 0
}
numOutputRows += 1
result
}
}
}
}
...
}
ExpandExec 的实现并不复杂,想要理解它的运作原理,关键是看懂上述源码中提到的 4 个关键点。
关键点 1 和 关键点 2 是基础,关键点 2 中的 groups 是一个 UnsafeProjection[N] 数组类型,其中每个 UnsafeProjection 代表了 Grouping Sets 语句里指定的 grouping set,它的定义是这样的:
// A projection that returns UnsafeRow.
abstract class UnsafeProjection extends Projection {
override def apply(row: InternalRow): UnsafeRow
}
// The factory object for `UnsafeProjection`.
object UnsafeProjection
extends CodeGeneratorWithInterpretedFallback[Seq[Expression], UnsafeProjection] {
// Returns an UnsafeProjection for given sequence of Expressions, which will be bound to
// `inputSchema`.
def create(exprs: Seq[Expression], inputSchema: Seq[Attribute]): UnsafeProjection = {
create(bindReferences(exprs, inputSchema))
}
...
}
UnsafeProjection 起来了类似列投影的作用,其中, apply 方法根据创建时的传参 exprs 和 inputSchema,对输入记录进行列投影,得出输出记录。
比如,前面的 GROUPING SETS ((city, car_model), (city), (car_model), ())例子,它对应的 groups 是这样的:
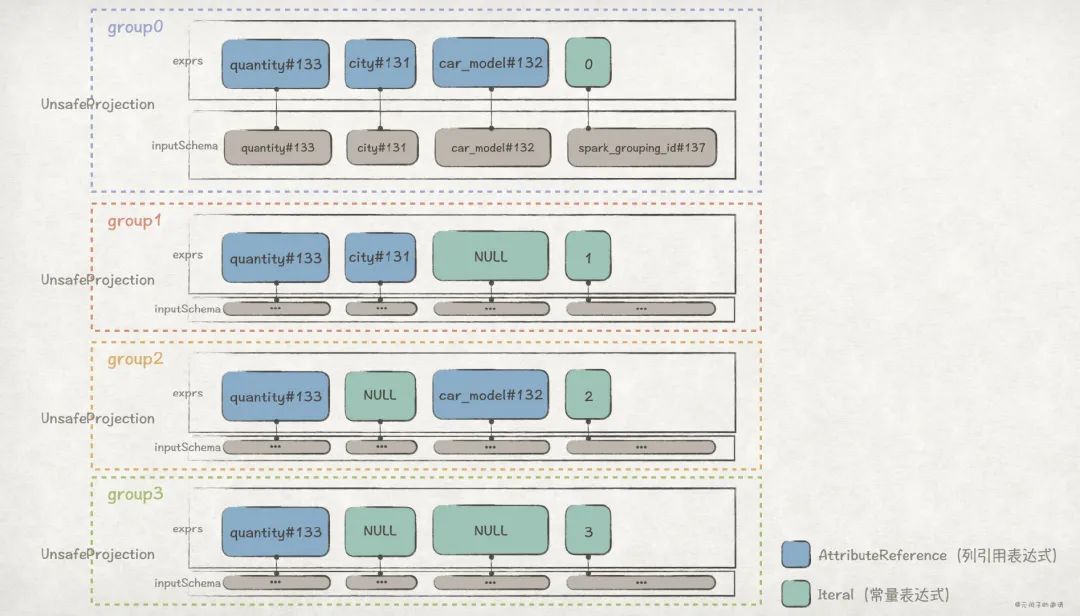
其中,AttributeReference 类型的表达式,在计算时,会直接引用输入数据对应列的值;Iteral 类型的表达式,在计算时,值是固定的。
关键点 3 和 关键点 4 是 Expand 算子的精华所在,ExpandExec 通过这两段逻辑,将每一个输入记录, 扩展(Expand) 成 N 条输出记录。
关键点 4中groups(idx)(input)等同于groups(idx).apply(input)。
还是以前面 GROUPING SETS ((city, car_model), (city), (car_model), ()) 为例子,效果是这样的:
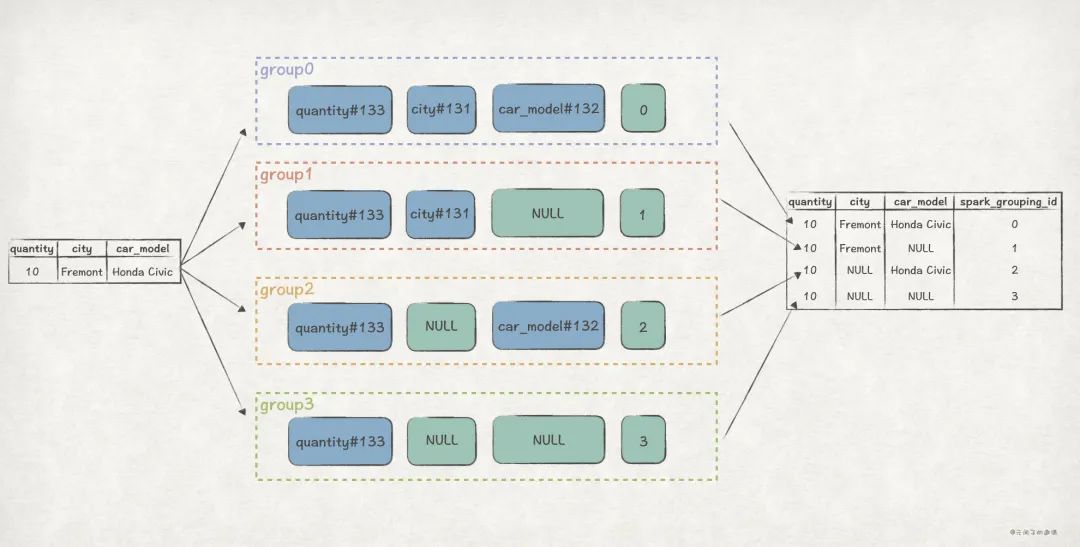
到这里,我们已经弄清楚 Expand 算子的工作原理,再回头看前面提到的 3 个问题,也不难回答了:
- Expand 的实现逻辑是怎样的,为什么能达到
Union All的效果?
如果说Union All是先聚合再联合,那么 Expand 就是先联合再聚合。Expand 利用groups里的 N 个表达式对每条输入记录进行计算,扩展成 N 条输出记录。后面再聚合时,就能达到与Union All一样的效果了。 - Expand 节点的输出数据是怎样的 ?
在 schema 上,Expand 输出数据会比输入数据多出 spark_grouping_id 列;在记录数上,是输入数据记录数的 N 倍。
spark_grouping_id列的作用是什么 ?
spark_grouping_id 给每个 grouping set 进行编号,这样,即使在 Expand 阶段把数据先联合起来,在 Aggregate 阶段(把 spark_grouping_id 加入到分组规则)也能保证数据能够按照每个 grouping set 分别聚合,确保了结果的正确性。
查询性能对比
从前文可知,Grouping Sets 和 Union All 两个版本的 SQL 语句有着一样的效果,但是它们的执行计划却有着巨大的差别。下面,我们将比对两个版本之间的执行性能差异。
spark-sql 执行完 SQL 语句之后会打印耗时信息,我们对两个版本的 SQL 分别执行 10 次,得到如下信息:
// Grouping Sets 版本执行10次的耗时信息
// SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
Time taken: 0.289 seconds, Fetched 15 row(s)
Time taken: 0.251 seconds, Fetched 15 row(s)
Time taken: 0.259 seconds, Fetched 15 row(s)
Time taken: 0.258 seconds, Fetched 15 row(s)
Time taken: 0.296 seconds, Fetched 15 row(s)
Time taken: 0.247 seconds, Fetched 15 row(s)
Time taken: 0.298 seconds, Fetched 15 row(s)
Time taken: 0.286 seconds, Fetched 15 row(s)
Time taken: 0.292 seconds, Fetched 15 row(s)
Time taken: 0.282 seconds, Fetched 15 row(s)
// Union All 版本执行10次的耗时信息
// (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
Time taken: 0.628 seconds, Fetched 15 row(s)
Time taken: 0.594 seconds, Fetched 15 row(s)
Time taken: 0.591 seconds, Fetched 15 row(s)
Time taken: 0.607 seconds, Fetched 15 row(s)
Time taken: 0.616 seconds, Fetched 15 row(s)
Time taken: 0.64 seconds, Fetched 15 row(s)
Time taken: 0.623 seconds, Fetched 15 row(s)
Time taken: 0.625 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
可以算出,Grouping Sets 版本的 SQL 平均耗时为 0.276s ;Union All 版本的 SQL 平均耗时为 0.616s ,是前者的 2.2 倍 !
所以, Grouping Sets 版本的 SQL 不仅在表达上更加简洁,在性能上也更加高效 。
RollUp 和 Cube
Group By 的高级用法中,还有 RollUp 和 Cube 两个比较常用。
首先,我们看下 RollUp 语句 。
Spark SQL 官方文档中 SQL Syntax 一节对 RollUp 语句的描述如下:
Specifies multiple levels of aggregations in a single statement. This clause is used to compute aggregations based on multiple grouping sets.
ROLLUPis a shorthand forGROUPING SETS. (... 一些例子)
官方文档中,把 RollUp 描述为 Grouping Sets 的简写,等价规则为:RollUp(A, B, C) == Grouping Sets((A, B, C), (A, B), (A), ())。
比如,Group By RollUp(city, car_model) 就等同于 Group By Grouping Sets((city, car_model), (city), ())。
下面,我们通过 expand extended 看下 RollUp 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY ROLLUP(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2164 ASC NULLS FIRST, car_model#2165 ASC NULLS FIRST], true
+- Aggregate [city#2164, car_model#2165, spark_grouping_id#2163L], [city#2164, car_model#2165, sum(quantity#2159) AS sum#2150L]
+- Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]], [quantity#2159, city#2164, car_model#2165, spark_grouping_id#2163L]
+- Project [quantity#2159, city#2157, car_model#2158]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2156, city#2157, car_model#2158, quantity#2159], Partition Cols: []]
== Physical Plan ==
...
从上述 Plan 可以看出,RollUp 底层实现用的也是 Expand 算子,说明 RollUp 确实是基于 Grouping Sets 实现的。 而且 Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]] 也表明 RollUp 符合等价规则。
下面,我们按照同样的思路,看下 Cube 语句 。
Spark SQL 官方文档中 SQL Syntax 一节对 Cube 语句的描述如下:
CUBEclause is used to perform aggregations based on combination of grouping columns specified in theGROUP BYclause.CUBEis a shorthand forGROUPING SETS. (... 一些例子)
同样,官方文档把 Cube 描述为 Grouping Sets 的简写,等价规则为:Cube(A, B, C) == Grouping Sets((A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ())。
比如,Group By Cube(city, car_model) 就等同于 Group By Grouping Sets((city, car_model), (city), (car_model), ())。
下面,我们通过 expand extended 看下 Cube 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY CUBE(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2202 ASC NULLS FIRST, car_model#2203 ASC NULLS FIRST], true
+- Aggregate [city#2202, car_model#2203, spark_grouping_id#2201L], [city#2202, car_model#2203, sum(quantity#2197) AS sum#2188L]
+- Expand [[quantity#2197, city#2195, car_model#2196, 0], [quantity#2197, city#2195, null, 1], [quantity#2197, null, car_model#2196, 2], [quantity#2197, null, null, 3]], [quantity#2197, city#2202, car_model#2203, spark_grouping_id#2201L]
+- Project [quantity#2197, city#2195, car_model#2196]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2194, city#2195, car_model#2196, quantity#2197], Partition Cols: []]
== Physical Plan ==
...
从上述 Plan 可以看出,Cube 底层用的也是 Expand 算子,说明 Cube 确实基于 Grouping Sets 实现,而且也符合等价规则。
所以,RollUp 和 Cube 可以看成是 Grouping Sets 的语法糖,在底层实现和性能上是一样的。
最后
本文重点讨论了 Group By 高级用法 Groupings Sets 语句的功能和底层实现。
虽然 Groupings Sets 的功能,通过 Union All 也能实现,但前者并非后者的语法糖,它们的底层实现完全不一样。Grouping Sets 采用的是先联合再聚合的思路,通过 spark_grouping_id 列来保证数据的正确性;Union All 则采用先聚合再联合的思路。Grouping Sets 在 SQL 语句表达和性能上都有更大的优势 。
Group By 的另外两个高级用法 RollUp 和 Cube 则可以看成是 Grouping Sets 的语法糖,它们的底层都是基于 Expand 算子实现, 在性能上与直接使用 Grouping Sets 是一样的,但在 SQL 表达上更加简洁 。
-
在Delphi中动态地使用SQL查询语句2009-05-10 6734
-
SQL语句的两种嵌套方式2019-05-23 2815
-
区分SQL语句与主语言语句2021-10-28 1782
-
为什么要动态sql语句?2021-12-20 1183
-
数据库SQL语句电子教程2011-07-14 1274
-
sql语句实例讲解2017-11-17 13915
-
如何使用navicat或PHPMySQLAdmin导入SQL语句2018-04-10 905
-
VS中SQL命令语句的详细资料免费下载2019-10-09 1231
-
如何使用SQL修复语句程序说明2019-10-31 944
-
嵌入式SQL语句2021-10-21 925
-
Group By高级用法Groupings Sets语句的功能和底层实现2022-07-04 4575
-
Java中如何解析、格式化、生成SQL语句?2023-04-10 2774
-
深度剖析SQL中的Grouping Sets语句12023-05-10 1556
-
sql查询语句大全及实例2023-11-17 3354
-
oracle执行sql查询语句的步骤是什么2023-12-06 2091
全部0条评论

快来发表一下你的评论吧 !
