

一个操作把MySQL主从复制整崩了
电子说
描述
前言
最近公司某项目上反馈mysql主从复制失败,被运维部门记了一次大过,影响到了项目的验收推进,那么究竟是什么原因导致的呢?而主从复制的原理又是什么呢?本文就对排查分析的过程做一个记录。
主从复制原理
我们先来简单了解下MySQL主从复制的原理。
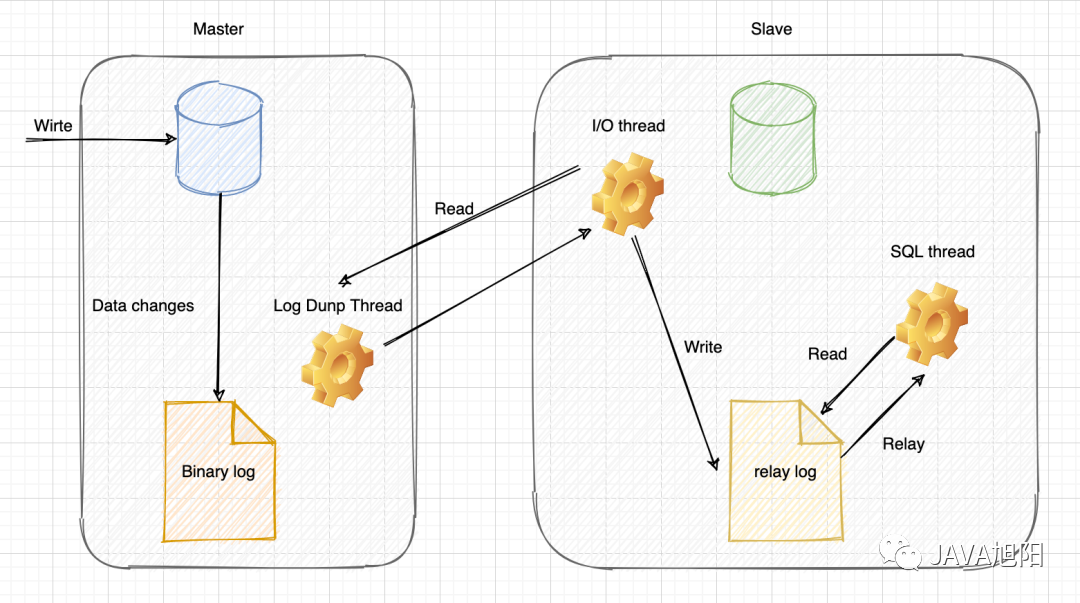
- 主库
master服务器会将 SQL 记录通过dump线程写入到 二进制日志binary log中; - 从库
slave服务器开启一个io thread线程向服务器发送请求,向 主库master请求binary log。主库master服务器在接收到请求之后,根据偏移量将新的binary log发送给slave服务器。 - 从库
slave服务器收到新的binary log之后,写入到自身的relay log中,这就是所谓的中继日志。 - 从库
slave服务器,单独开启一个sql thread读取relay log之后,写入到自身数据中,从而保证主从的数据一致。
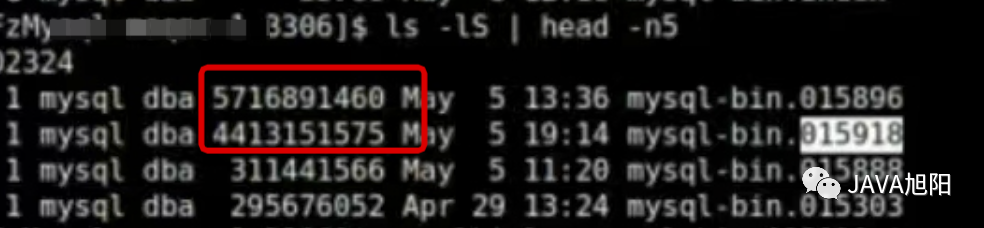
以上是MySQL主从复制的简要原理,更多细节不展开讨论了,根据运维反馈,主从复制失败主要在IO线程获取二进制日志bin log超时,一看主数据库的binlog日志竟达到了4个G,正常情况下根据配置应该是不超过300M。
binlog写入机制
想要了解binlog为什么达到4个G,我们来看下binlog的写入机制。
binlog的写入时机也非常简单,事务执行过程中,先把日志写到 binlog cache ,事务提交的时候,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为binlog cache。
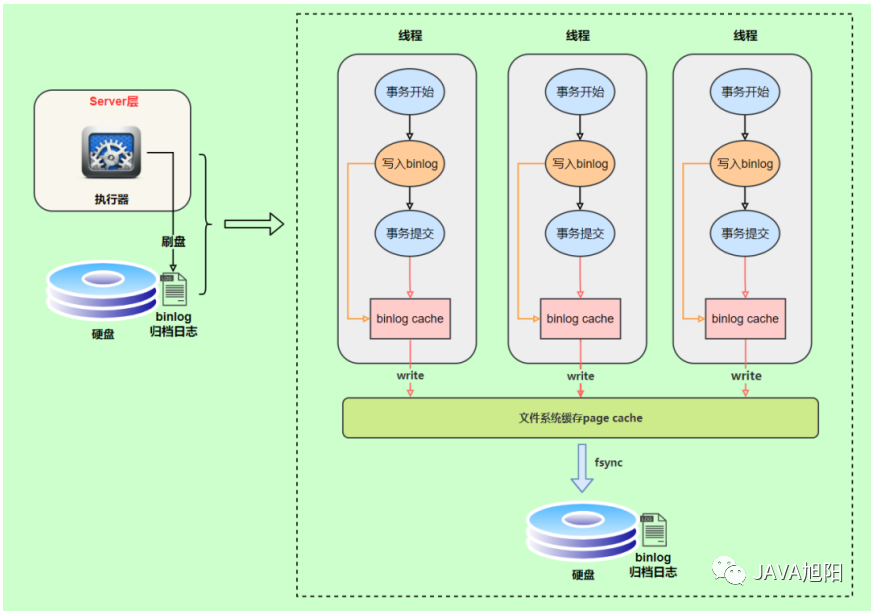
- 上图的
write,是指把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快 - 上图的
fsync,才是将数据持久化到磁盘的操作, 生成binlog日志中
生产上MySQL中binlog中的配置max_binlog_size为250M, 而max_binlog_size是用来控制单个二进制日志大小,当前日志文件大小超过此变量时,执行切换动作。,该设置并不能严格控制Binlog的大小,尤其是binlog比较靠近最大值而又遇到一个比较大事务时,为了保证事务的完整性,可能不做切换日志的动作,只能将该事务的所有$QL都记录进当前日志,直到事务结束。一般情况下可采取默认值。
所以说怀疑是不是遇到了大事务,因而我们需要看看binlog中的内容具体是哪个事务导致的。
查看binlog日志
我们可以使用mysqlbinlog这个工具来查看下binlog中的内容,具体用法参考官网:https://dev.mysql.com/doc/refman/8.0/en/mysqlbinlog.html。
- 查看
binlog日志
./mysqlbinlog --no-defaults --base64-output=decode-rows -vv /mysqldata/mysql/binlog/mysql-bin.004816|more
- 以事务为单位统计
binlog日志文件中占用的字节大小
./mysqlbinlog --no-defaults --base64-output=decode-rows -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep GTID -B1|grep '^# at' | awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|sort -n -r|more
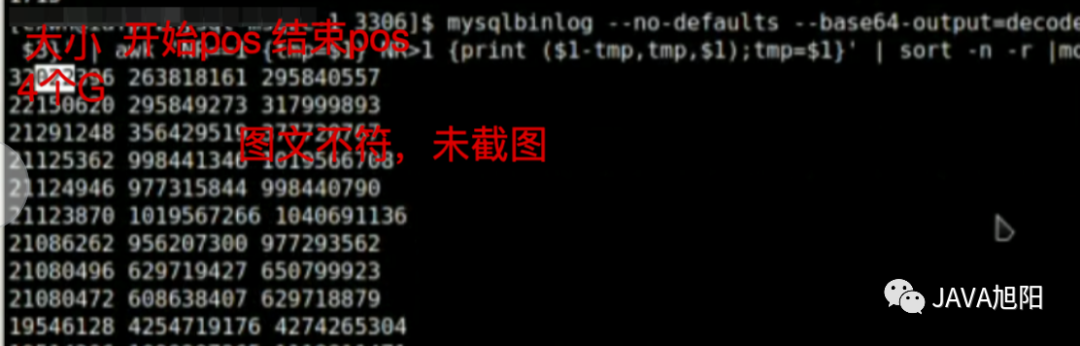
生产中某个事务竟然占用4个G。
- 通过
start-position和stop-position统计这个事务各个SQL占用字节大小
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-position='xxxx' --stop-position='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816 |grep '^# at'| awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|sort -n -r|more
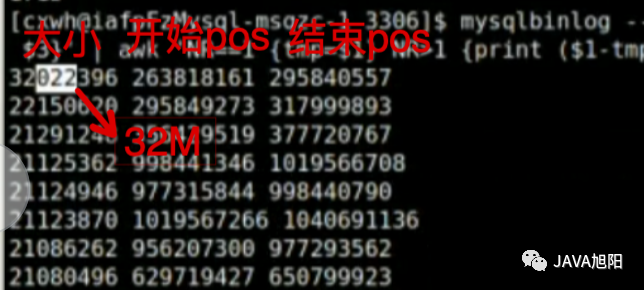
发现最大的一个SQL竟然占用了32M的大小,那超过10M的大概有多少个呢?
- 通过超过10M大小的数量
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-position='xxxx' --stop-position='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep '^# at' | awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|awk '$1>10000000 {print $0}'|wc -l

统计结果显示竟然有200多个,毛估一下,也有近4个G了
- 根据pos, 我们看下究竟是什么SQL导致的
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-position='xxxx' --stop-position='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep '^# atxxxx' -C5| grep -v '###' | more

根据sql,分析了下,这个表正好有个blob字段,统计了下blob字段总合大概有3个G大小,然后我们业务上有个导入操作,这是一个非常 大的事务 ,会频繁更新这表中记录的更新时间,导致生成binlog非常大。
问题: 明明只是简单的修改更新时间的语句,压根没有动blob字段,为什么生产的binlog这么大?因为生产的binlog采用的是row模式。
binlog的模式
binlog日志记录存在3种模式,而生产使用的是row模式,它最大的特点,是很精确,你更新表中某行的任何一个字段,会记录下整行的内容,这也就是为什么blob字段都被记录到binlog中,导致binlog非常大。此外,binlog还有statement和mixed两种模式。
- STATEMENT模式 ,基于SQL语句的复制
- 优点: 不需要记录每一行数据的变化,减少
binlog日志量,节约IO,提高性能。 - 缺点: 由于只记录语句,所以,在
statement level下 已经发现了有不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些定的函数或者功能的时候会出现。
- ROW模式,基于行的复制
5.1.5版本的MySQL才开始支持,不记录每条sql语句的上下文信息,仅记录哪条数据被修改了,修改成什么样了。
- 优点:
binlog中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条被修改。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定的情况下的存储过程或function,以及trigger的调用和触发无法被正确复制的问题 - 缺点: 所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,会产生大量的日志内容。
- MIXED模式
从5.1.8版本开始,MySQL提供了Mixed格式,实际上就是Statement与Row的结合。
在Mixed模式下,一般的语句修改使用statment格式保存binlog。如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog。
总结
最终分析下来,我们定位到原来是由于大事务+blob字段大致binlog非常大,最终我们采用了修改业务代码,将blob字段单独拆到一张表中解决。所以,在设计开发过程中,要尽量避免大事务,同时在数据库建模的时候特别考虑将blob字段独立成表。
-
配置MySQL主从复制和读写分离2024-10-23 1451
-
mysql主从复制三种模式2023-11-16 2634
-
什么是Redis主从复制2023-10-09 1339
-
聊聊RocketMQ的主从复制2023-07-04 1882
-
MySQL主从复制原理详解2023-02-06 1804
-
利用MySQL进行一主一从的主从复制2022-07-28 1874
-
mysql的主从复制2020-04-28 1523
-
基于二进制安装MySQL的主从复制2020-03-10 1510
-
Mysql如何实现双向互为主从复制?2018-06-22 2751
-
基于mycat的Mysql主从复制读写分离全攻略2017-09-08 953
全部0条评论

快来发表一下你的评论吧 !
