

浅谈AI和模型预测控制结合的神经网络模型
人工智能
描述
第一部分
模型预测控制
01
最优控制理论处理的问题通常是找到一个满足容许控制的 u*,把它作用于系统(被控对象)ẋ(t)=f(x(t),u(t),t) 从而可以得到系统的状态轨迹 x(t),使得目标函数最优。对于轨迹跟踪问题,那目标函数就是使得这个轨迹在一定的时间范围[t0tf]内与我们期望的轨迹(目标)x*(t) 越近越好。最优控制问题更一般的表达如下:在被控对象符合动力学原理(状态方程)和状态约束
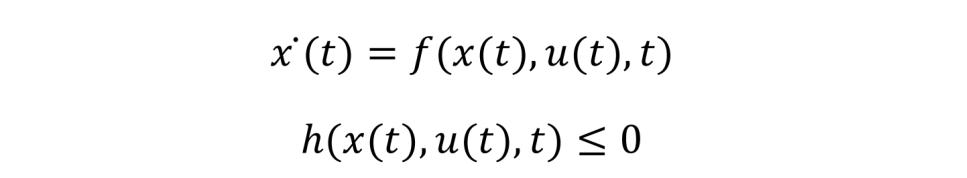
的条件下,求解控制函数 u(t) 以使得连续时间性能指标
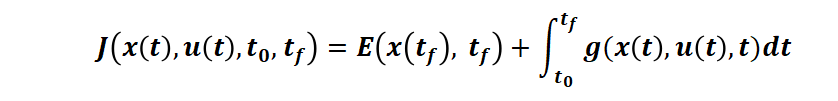
最小。其中 t0 是初始时刻,tf 是终端时刻,E 是终端时刻代价,g 是运行时刻代价。例如,更具体的场景,对于时间最短问题(例如控制电流使得最短时间充电到 SOC100%),性能指标即:
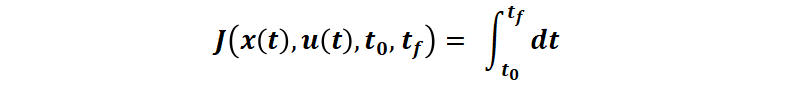
对于最小燃料消耗问题(接下来本文中主要使用的例子,假设燃料消耗与控制量 u 成正比,并且 u∈[0 1]),性能指标变为:
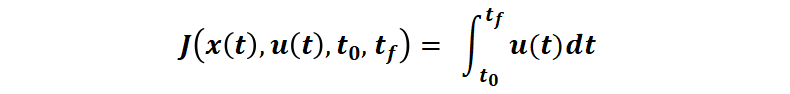
最优控制的性能指标函数和约束函数都是泛函,因为他们的自变量 u(t) 本身也是个函数。于是,求解性能指标函数最优的问题是一个求泛函极值的问题,类比于函数极值通过求导来获得极值条件,泛函极值则通过变分法来获得极值条件。而基于变分的两大方法: 庞特里亚金极小值原理和动态规划(求解 Hamilton-Jacobi-Bellman 方程),则是最优控制问题求解的主要方法。对于简化的最优控制问题,例如被控对象为线性系统
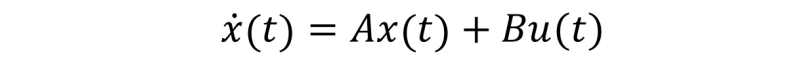
性能指标是二次型的无限时域的连续时间泛函:
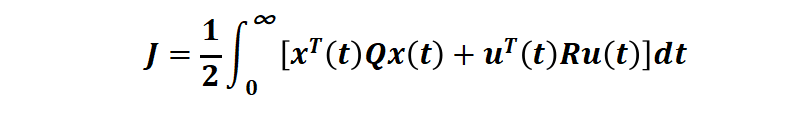
(其中第一项是对状态(例如追踪误差)的要求,第二项是对控制能量的要求,Q 和 R 是权重矩阵),优化区间考虑整个时间域 [t0=0 tf=∞](也就是 Linear-Quadratic Regulator (LQR) ), 可以使用极小值原理或动态规划或 Ricatti 代数方程求得闭环形式的最优控制。例如,对一个车载倒立摆系统[1]:
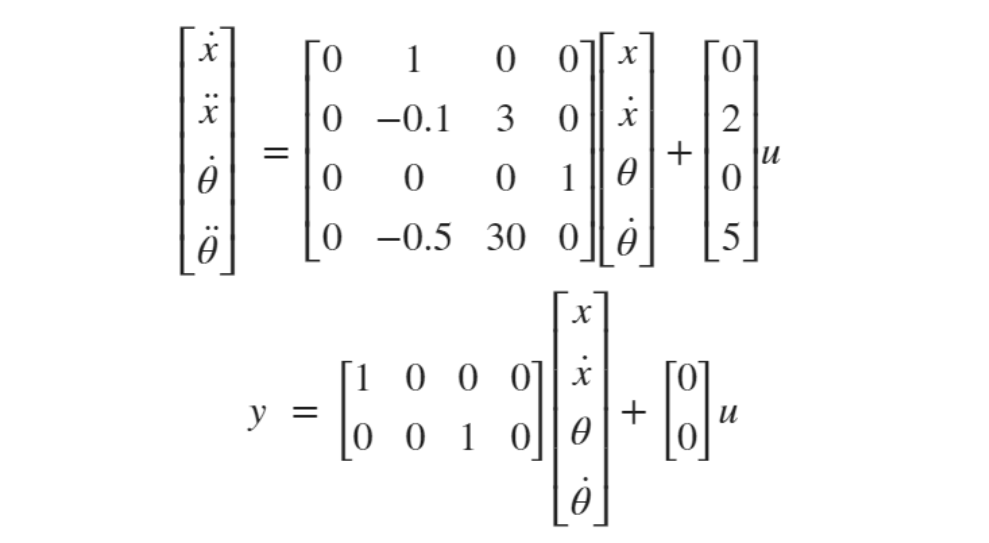
其中系统输出是车辆位移 x 和倒立摆角度 θ,控制输出 u 是作用在车上的水平力。控制是标量,状态是 4 维
Q = [1,0,0,0;...
0,0,0,0;...
0,0,1,0;...
0,0,0,0];
R = 1;
[K,S,P] = lqr(sys,Q,R)
利用 lqr 函数就可以求得最优增益矩阵 K。但对于更一般的非线性系统,使用极小值原理或动态规划求解解析解几乎不可能,数值解计算复杂度较高,所以可以考虑一定的问题简化,仅考虑未来的一小段时间最优(而非全时间域“最优”),将最优控制问题转化未来几个时间步的在线数值优化问题,例如 MPC,可以大大降低“最优”控制计算的复杂度。
我们通过和人的行为进行类比来解释 MPC 的思想[2]:设想开车的场景,我们的目标是让车按一定的轨迹行驶,人的控制方式和模型预测控制器的工作方式很像,司机的大脑中可能有一些经验( 类似虚拟的动力学模型),于是他会利用这些经验(虚拟模型)在大脑中去预先“仿真”这个过程,可以预测假如他采取了某些动作(油门,刹车,转向等等)之后的一段时间内汽车会有多快或有多少转向,从而他会从这些可选的一系列动作中选择一个最能使汽车在未来一段时间内接近期望轨迹的控制动作作为当前时刻的行为,例如踩油门,刹车等等,并在每个时刻不断重复类似的思想,从而驱动车辆到期望的轨迹。
算法介绍
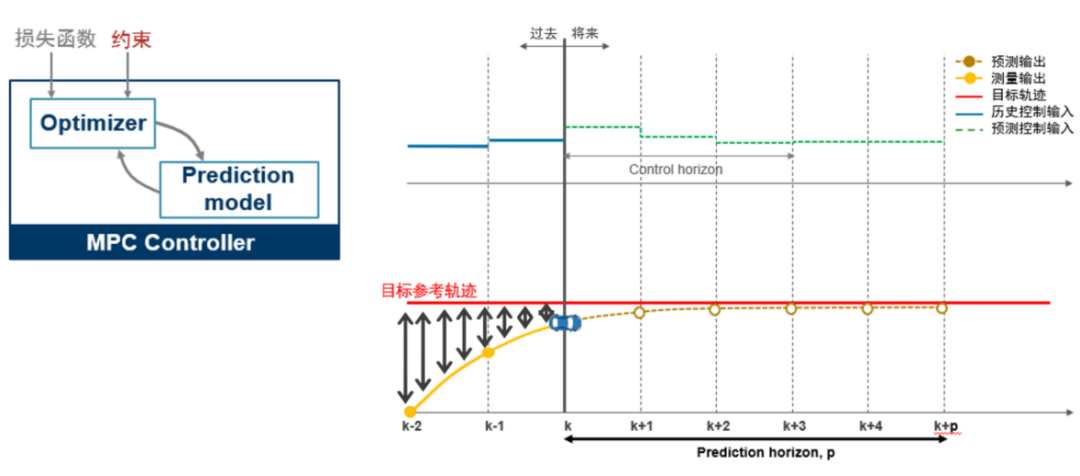
(图表1)
模型预测控制 (MPC) 是一种最优控制技术,在每个控制周期 tk , MPC 控制器获得系统(被控对象)当前的状态。接下来它利用基于系统当前状态和系统动态模型通过在有限时间上预测系统未来 p 步状态轨迹,并与目标轨迹构建代价函数和约束,进行一次开环优化问题(要优化的变量是作用在被控对象上的控制输入序列)求解,得到未来一段时间 [tk,tk+1,···,tk+p] 的控制输入序列 [uk,uk+1,···,uk+p] 。当然对于求解得到的控制输入序列,控制器只将最近时刻 tk 的控制 uk 作用于系统(被控对象)而忽略掉控制序列的其他值[uk+1,···,uk+p], 在下一个时刻tk+1,MPC 控制器会重复上述优化求解过程重新计算控制序输入列并只将第一个控制值作为当前时刻的控制量作用于系统,依次类推,重复上述过程进行下一时刻的求解。所以 MPC 在每个时刻都在线进行一个含约束的优化问题的求解(滚动优化,特殊情况除外)。接下来我们看一下这个优化问题是如何定义以及求解的。MPC 的优化问题 (更具体的二次规划,QP) 包含这几项主要内容[3]:
代价函数: 用于度量控制器性能,目标是求它的最小值。
约束:目标解必须满足的条件,例如控制量(manipulated variables, MV)和被控对象状态输出的物理边界。
控制与决策:得到优化的控制量(MV)
代价函数
一个典型的代价函数由四部分组成,每一部分关注控制器性能的一个方面。
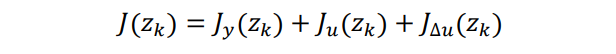
这里面的 zk 就是 QP 问题的决策变量(控制变量)。其中每一项量化一个性能指标。
Jy(zk) 量化系统输出与目标轨迹的跟踪效果
Ju(zk) 用于量化控制输入与目标控制变量跟踪效果(在很多应用中,控制器还需要保证控制变量(MV)保持在某个目标附近,尤其在控制量数目远多于系统输出量数目的情况下)
JΔu(zk) 控制变量波动约束(多数应用场景下一般都希望控制变量有较小的变动或调整,而不希望较大的突变)。
例如对于常用的 Jy(zk) ,即量化图表1中黑色双箭头代表的区域。控制器的目标是将被控对象保持在指定的参考轨迹附近。MPC 控制器通过如下计算得到一个标量作为性能度量来实现目标轨迹跟踪:
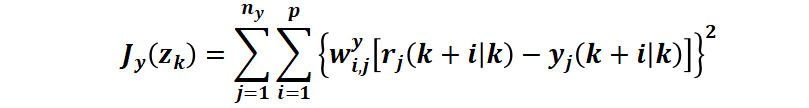
其中,底标 i 是对 p 个预测步的循环,j 是对 ny 个输出的循环。
k:当前控制周期
p:预测区间(Prediction Horizon)
ny:被控对象输出变量的数量
zk:QP 问题决策变量,也就是对应的时间步上的控制器输出序列,其中
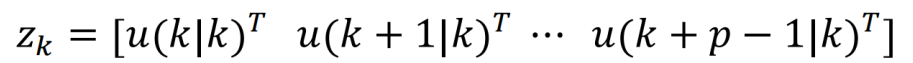
yj(k+i|k):从 k 时刻开始的未来第 i 个(共 p 个)时间步长被控对象第 j 个(共 ny 个)输出的预测值
rj(k+i|k):从时刻开始的未来第个(共个)时间步长被控对象第个(共个)输出的目标参考值
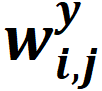
:未来第个时间步,被控对象第个(共个)输出的权重因子(无量纲)
约束
MPC 中最常见的约束就是边界约束,例如针对被控对象、控制变量(MV)、控制变量变化量的边界约束,如下:
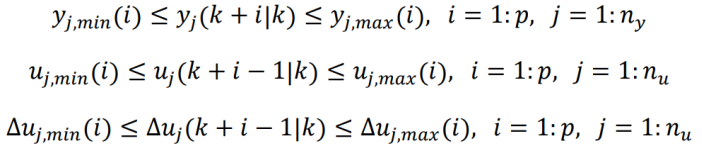
yj,min(i),yj,max(i):从 k 时刻开始的未来第 i 个时间步长被控对象第 j 个(共 ny 个)输出的下界和上界
uj,min(i),uj,max(i):从 k 时刻开始的未来第 i 个时间步长第 j 个(共 nu 个)控制变量的下界和上界
Δuj,min(i),Δuj,max(i):从 k 时刻开始的未来第 i 个时间步长第 j 个(共 nu 个)控制变量的下界和上界
预测与决策
每次滚动优化计算过程中,模型预测控制器可以获得整个预测区间 p 时间步上的参考轨迹 rj(k+i|k)。模型预测控制器中的“模型”包括被控对象模型、扰动模型和噪声模型,如图表2,控制器每次滚动优化计算过程中,使用这些模型加上可调(可优化)的控制变量 zk 来预测被控对象的输出 yj(k+i|k)。
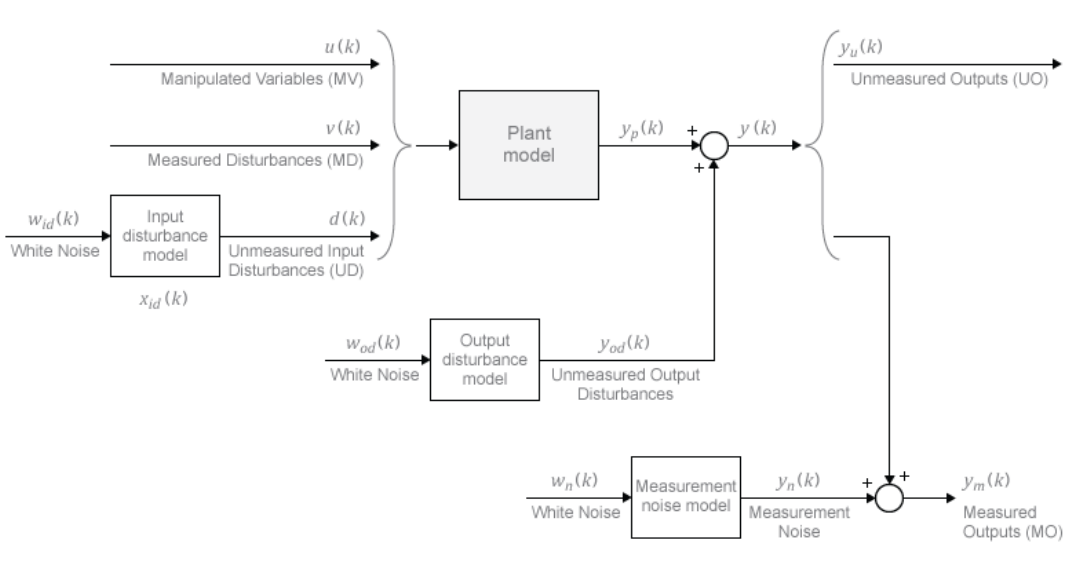
(图表2)
上述预测过程可以通过简化的状态空间离散预测模型表示:
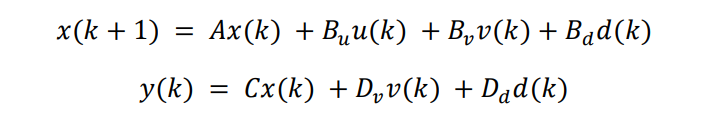
其中 v(k) 是可测干扰输入,d(k) 是不可测干扰输入白噪声。
我们详细描述一下在 k=0 时刻预测模型在预测区间 p 上的轨迹预测过程:对所有预测瞬时 i, 将 d(i) 设为0,可得,问题变成一个递归计算问题(从 k=1到 k=0)即可得到 y(i|0) 序列:
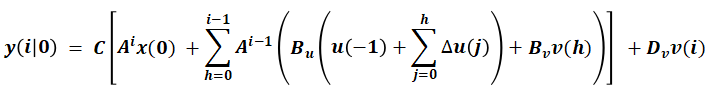
整理成矩阵形式:
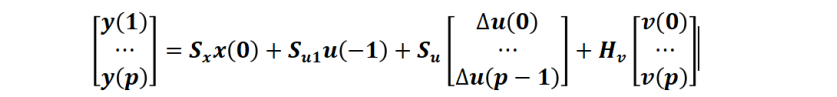
其中(此处不详细列出这些矩阵表达式,可以根据上式递归自行推导)
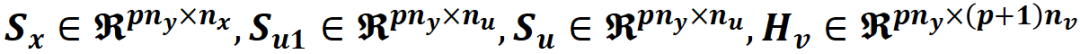
组合各个元素得到优化问题定义
将上述的代价函数,约束,预测模型矩阵结合起来构建 MPC 的开环优化问题如下:
状态变量 x(k)∈Rnx,控制变量 u(k)∈Rnu,满足上述系统动力学方程以及时域约束,通过预测计算,求解如下最小化性能指标对应的优化变量zk
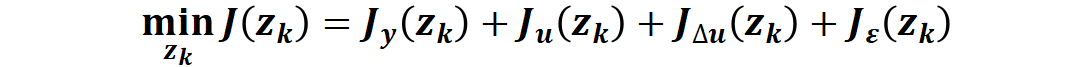
其中
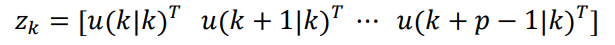
即在预测区间 p 上的待优化的控制输入序列。
示例:
非线性 MPC 的飞行机器人轨迹开环规划和闭环反馈控制
我们通过一个非线性 MPC 的飞行机器人轨迹优化与控制控制器设计示例来主要介绍介绍 MPC 设计方法[4]。MPC 即可以用于轨迹追踪控制(在线实时),也可以用于规划(进行一次开环的优化)。本示例先用 MPC 进行了一次开环优化求解完成了规划,找到了从一个位置到另一个位置的最佳轨迹,然后再结合状态估计器:扩展卡尔曼滤波器,来控制机器人沿规划的最优轨迹进行闭环控制。
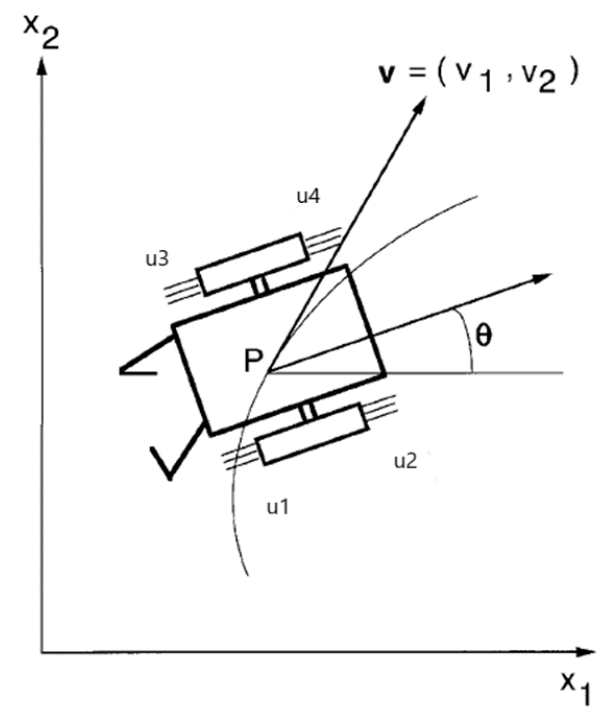
这个简化的例子中的飞行机器人有四个推进器在平面空间中移动。
该模型动力学系统如下:
function dxdt = FlyingRobotStateFcn(x, u)
% 状态方程:x 是六个状态,u是推力控制。
%x(1) – 质心x坐标
%x(2) – 质心y坐标
%x(3) – theta, 机器人(推力)方向
%x(4) – x方向的速度vx
%x(5) – y方向的速度vy
%x(5) – omega, 角速度
…
dxdt = zeros(6,1);
dxdt(1) = x(4);
dxdt(2) = x(5);
dxdt(3) = x(6);
dxdt(4) = (T1 + T2)*cos(theta);
dxdt(5) = (T1 + T2)*sin(theta);
dxdt(6) = alpha*T1 - beta*T2;
end
示例假设机器人有四个物理推力 [u(1)u(2)u(3)u(4)],范围从0到1。
轨迹规划
前面提到了,MPC 用于轨迹规划其实是求解了一次开环的带约束的优化问题,区别于后面的针对规划好的轨迹的路径跟踪(利用反馈状态的滚动优化)。
先定义本示例的轨迹规划问题:机器人最初停留在 [-10, -10] 位置,方向角 theta 为 pi/2。本例中的飞行任务是在 12s 内移动机器人并停在最终位置 [0, 0],方向角 theta 为 0。目标是找到最优路径,使推进器在控制过程中消耗的燃料总量最小。
在此例中,对于规划轨迹,我们开环优化需要使用全部时间长度:12s。设定一个采样时间 Ts=0.4s,所以对应的预测区间为 30 步(12/0.4)。规划的运行周期通常可以比反馈控制周期更大,或更低频,所以有更多计算资源允许计算一个相对较大的优化问题。对于轨迹规划我们可以创建一个多级非线性MPC对象,它允许对每个预测步都定义不同的代价函数和约束。
% 具有 nx=6 个状态和 nu=4 个控制输入(mv)
% 预测区间 p = 30
nlobj=nlmpcMultistage(p,nx,nu);
nlobj.Ts=Ts;
for ct=1:p
%并且每个 stage/ 预测步有自己的代价函数
其中代价函数
包含 stage 这个参数,
见下面 FlyingRobotCostFcn 函数
nlobj.Stages(ct).CostFcn='FlyingRobotCostFcn';
end
% 代价函数示例
function J=FlyingRobotCostFcn(stage, x, u)
%本例中因为推力与燃油正相关,所以这个示例每个预测步(1到p)简化燃油消耗的表达为上四个推力之
%和。本示例没有直接使用 stage 参数。
J = u(1) + u(2) + u(3) + u(4);
end
指定预测模型的状态转移方程和对应的雅可比函数解析形式,可以大幅提升计算效率
nlobj.Model.StateFcn="FlyingRobotStateFcn";
nlobj.Model.StateJacFcn=@
FlyingRobotStateJacobianFcn;
控制目标是在第12秒将机器人停在 [0,0] 处,角度为0弧度。将这个指定为终端状态约束,其中最后一个预测步骤(第p+1步)的每个位置和速度状态都应该为零。
nlobj.Model.TerminalState = zeros(6,1);
如果可以为每个 stage 都提供代价函数和约束函数的雅可比函数解析式会大大提升优化效率。本例没有提供,所以它们的雅可比矩阵由 MPC 控制器使用内置的数值差分方法计算。
每个推力的工作范围在0到1之间,也就是 MV 的下限和上限。
for ct = 1:nu
nlobj.MV(ct).Min = 0;
nlobj.MV(ct).Max = 1;
end
指定飞行器初始条件:
x0=[-10;-10;pi/2;0;0;0];% 机器人停在 [-10, -10], 方向角为 pi/2
u0 = zeros(nu,1); %初始推力为0
通过调用 nlmpcmove 命令,就可以完成一次优化,找到最佳状态和控制(MV)轨迹。
[~,~,info] = nlmpcmove(nlobj,x0,u0);
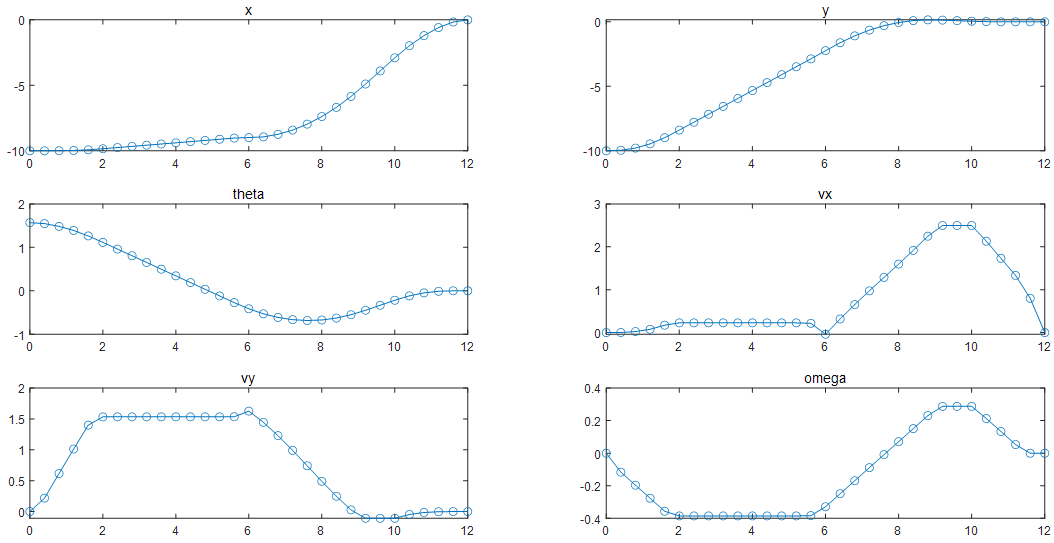
图表 3规划(优化求解)的最优轨迹对应六个状态量的预测值
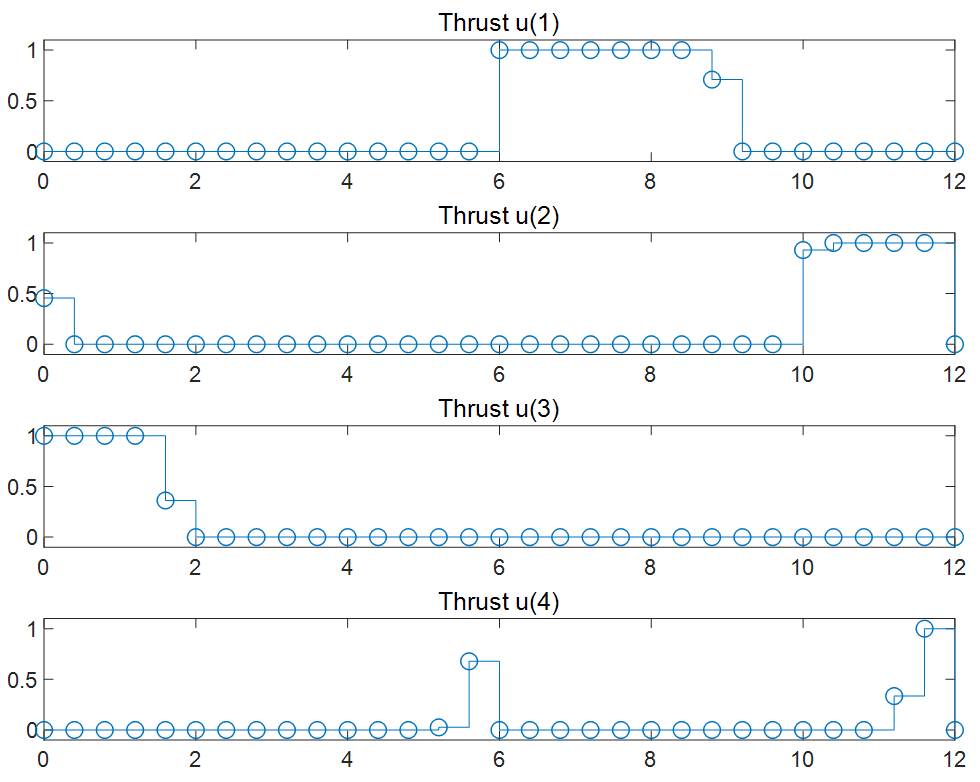
图表4对应的4个推力在最优轨迹规划求解时的最优解序列(MV)
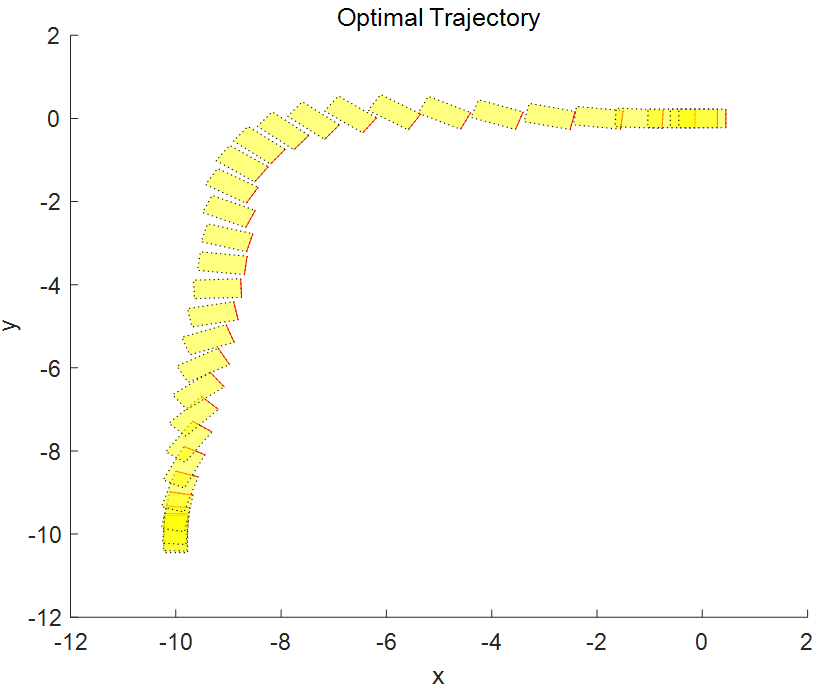
图表5 机器人最优轨迹的坐标和方位信息,从 [-10 -10 pi/2] 到 [0 0 0].
轨迹跟踪的反馈控制
在通过开环规划得到最优轨迹后,需要一个反馈控制器来使机器人沿着路径移动。理论上,可以将开环规划的到的最优控制输入 MV(图表4)直接应用于推进器实现前馈控制。但在实际应用中,通常会需要一个反馈控制器修正规划时的建模误差和抑制干扰,如下图,所以接下来的任务我们就是设计 MPC Controller 和 State Estimator
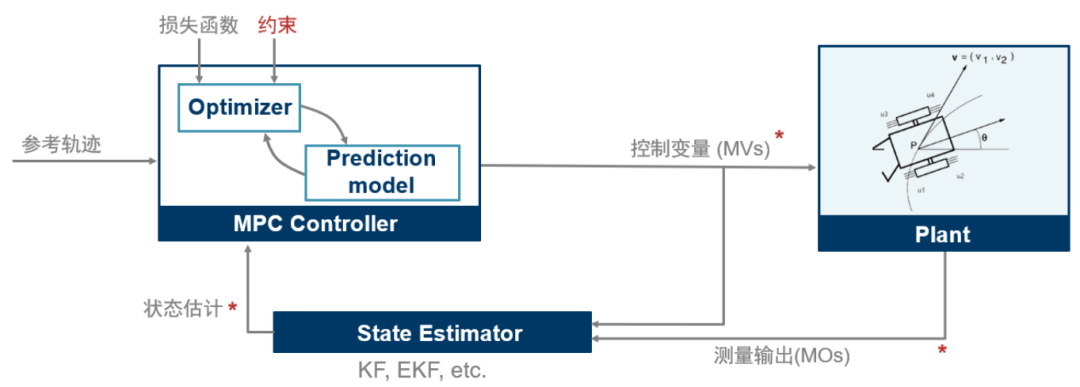
图表 6
设计MPC控制器
本示例使用典型的非线性 MPC 控制器将机器人沿着参考轨迹移动到最终目标位置。在这个轨迹跟踪问题中,参考轨迹包含所有六个状态的轨迹(输出的数量等于状态的数量,ny=nx)。
ny = 6;
nlobj_tracking = nlmpc(nx,ny,nu);
% 对于状态方程和雅可比函数,我们和上面用于轨迹规划的MPC中使用同样的动力学模型
nlobj_tracking.Model.StateFcn=nlobj.、Model.StateFcn;
nlobj_tracking.Jacobian.StateFcn = nlobj.Model.StateJacFcn;
% 指定滚动优化的预测区间 Prediction Horizon (不需要考虑太远的未来时间)和控制区间 Control
% Horizon (例如,仅在前几个预测区间允许变量可优化 来减少计算量)。
nlobj_tracking.PredictionHorizon = 10;
nlobj_tracking.ControlHorizon = 4;
非线性 MPC 的默认代价函数是一个适合轨迹跟踪的标准二次函数。对于轨迹跟踪问题,代价函数中就 J(zk)=Jy(zk)+Ju(zk)+JΔu(zk), 本示例对于跟踪误差 Jy(zk) 更看重,所以代价函数中的惩罚权重设置的大一些,控制抖动项 JΔu(zk)(MV 率)上的惩罚权重设置的小一些,如下:
nlobj_tracking.Weights.ManipulatedVariablesRate = 0.2*ones(1,nu);
nlobj_tracking.Weights.OutputVariables=5*ones(1,nx);
此外,在控制过程中,u1 和 u2 上下限的约束设定在 [0,1] 范围内,因为两个是同侧相反的方向,所以不需要同时工作,因此加一个等式约束,使 u(1)*u(2) 对所有预测区间都为 0,u3 和 u4 也是同样。
nlobj_tracking.Optimization.CustomEqConFcn = ...
@(X,U,data) [U(1:end-1,1).*U(1:end-1,2); U(1:end-1,3).*U(1:end-1,4)];
▼
设计状态估计器
在这个例子中,只测量了三个位置状态 (x、y 和角度)。速度状态是没有测量,需要估计。此处使用扩展卡尔曼滤波器 (EKF) 进行非线性状态估计。因为 EKF 需要离散时间模型,但我们之前的状态空间模型是连续模型,所以使用梯形规则
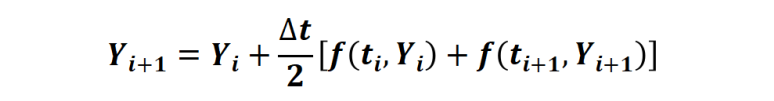
通过解 nx 个非线性代数方程,对连续模型进行转换,得到离散状态方程模型FlyingRobotStateFcnDiscreteTime.m。
其中m中的梯形规则如下实现:
% 利用上述梯形法则计算待定系数xk1
FUN=@(xk1) TrapezoidalRule(xk,xk1,uk,Ts,fk,ffun);
Options=optimoptions('fsolve','Display','none');
xk1 = fsolve(FUN,xk1,Options);
% 梯形法则函数
function f=TrapezoidalRule(xk,xk1,uk,Ts,fk,ffun)
% 计算梯形法则中的 f(ti+1,Yi+1)
fk1=ffun(xk1,uk);
% 通过使 f=0,求得待定系数 xk1.
f=xk1-(xk + (Ts/2)*(fk1+fk));
接下来将上述离散后的模型给到 EKF 估计器用于状态估计。
DStateFcn=@(xk,uk,Ts) FlyingRobotStateFcnDiscreteTime(xk,uk,Ts);
DMeasFcn = @(xk) xk(1:3);
% 创建EKF,并设定测量噪声
EKF=extendedKalmanFilter(DStateFcn,DMeasFcn,x0);
EKF.MeasurementNoise = 0.01;
▼
闭环仿真
现在图表6中 MPC Controller, Plant, State Estimator 都有了,可以进行追踪控制的闭环仿真
设置好初始条件,仿真 32 个时间步,参考轨迹就是在规划阶段计算出来的最优状态轨迹。使用 nlmpcmove 和 nlmpcmoveopt 命令进行闭环仿真。
Tsteps = 32;
for k = 1:Tsteps
%获取被控对象当前时刻测量输出(3维输出数据:x、y和角度,含噪声).
yk = xHistory(k,1:3)' + randn*0.01;
%基于k时刻的测量值估计 k 时刻的状态(得到6维状态).
xk = correct(EKF, yk);
%nlmpcmove 使用参考轨迹 Xref 进行一次 p 个未来步长的优化求解,得到当前时刻的优化控制uk.
[uk,options]=nlmpcmove(nlobj_tracking,xk,
lastMV,Xref(k:min(k+9,Tsteps),:),[],options);
%预测下一时刻的状态和协方差矩阵,用于下步correct.
predict(EKF,uk,Ts);
%保存控制量并更新控制量用于作用在被控对象上
uHistory(k,:) = uk'; %#ok<*SAGROW>
lastMV = uk;
%基于当前的状态 xk, 将求解的最优的uk作用在被控对象上(连续时间 ODE)并求解 ODE 得到下一时刻的状态.
ODEFUN=@(t,xk) FlyingRobotStateFcn(xk,uk);
[TOUT,YOUT] = ode45(ODEFUN,[0 Ts], xHistory(k,:)');
%将状态结果保留下来用于下个循环进行测量.
xHistory(k+1,:) = YOUT(end,:);
end
将规划的参考轨迹和实际的闭环控制轨迹进行比较。
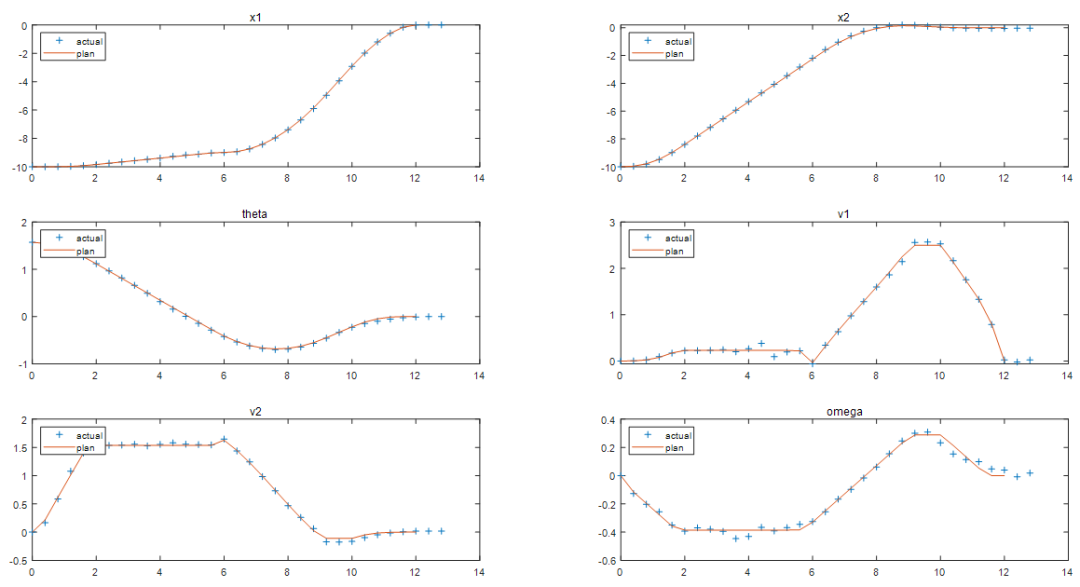
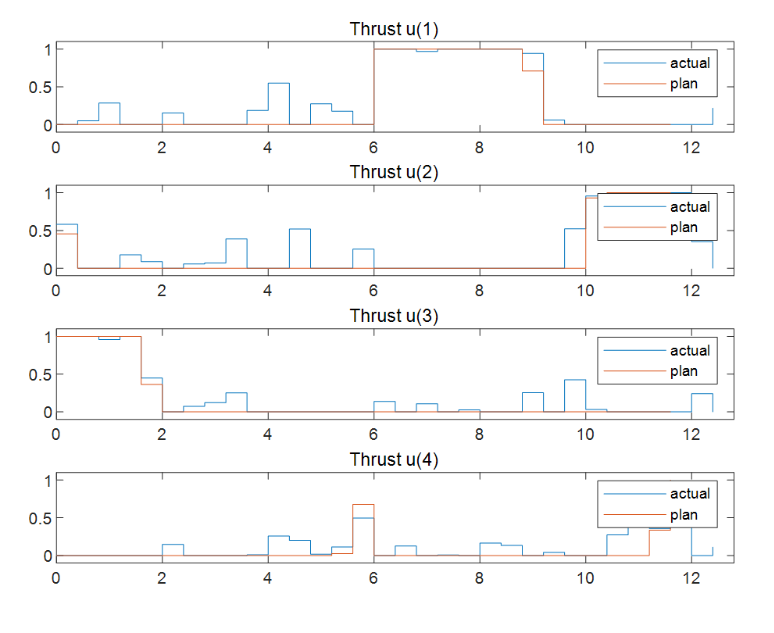
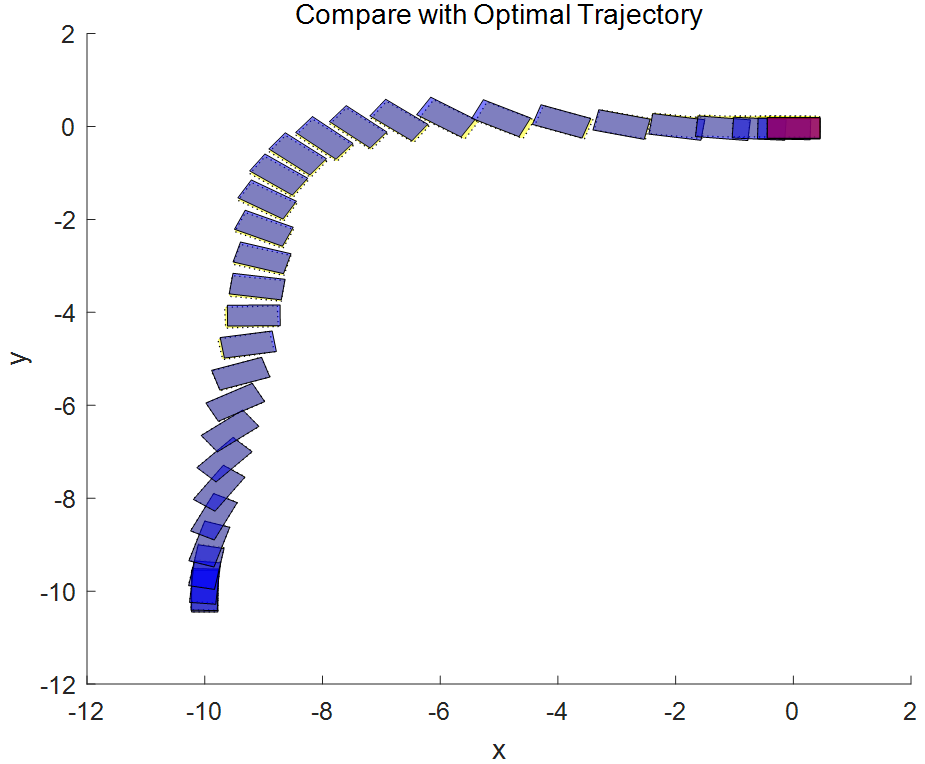
非线性 MPC 反馈控制器成功地移动机器人(蓝色块),沿着最优轨迹(黄色块),并将其停在最后一个图中的最终位置(红色块)。当然计算出的实际燃油损失高于规划的油量。产生此结果的主要原因是,由于我们在反馈控制器中使用了更小时间域的预测和控制范围最优求解,因此与规划阶段使用全时间域优化问题相比,每个区间的控制决策都是次优的。
第二部分
为被控对象辨识神经网络状态
空间模型并用于 MPC
02
区别于第一性原理建模的另一种方法是基于实验数据的黑盒建模。对于动态系统(被控对象)进行数据建模的方式有很多,包括系统辨识(线性系统,Grey-Box, Nonlinear 等等,具体见前面文章[5] 数据驱动的动态系统建模-系统辨识),以及深度学习(LSTM, Neural ODE 等等,具体见前面的文章[6] 数据驱动的动态系统建模-深度学习)。
我们前面看到 MPC 控制器中进行预测时需要被控对象的状态空间方程(Plant Model),也就是飞行器的状态空间方程脚本。在工业应用中,有时很难利用第一性原理手动推导得到形如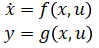 的非线性状态空间动态模型。在这种情况下我们可以训练一个神经网络状态空间模型,
的非线性状态空间动态模型。在这种情况下我们可以训练一个神经网络状态空间模型,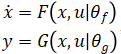 ,其中 F 和 G 是两个神经网络模型,然后作为对象模型放到 MPC 中用于预测过程。示意如下
,其中 F 和 G 是两个神经网络模型,然后作为对象模型放到 MPC 中用于预测过程。示意如下
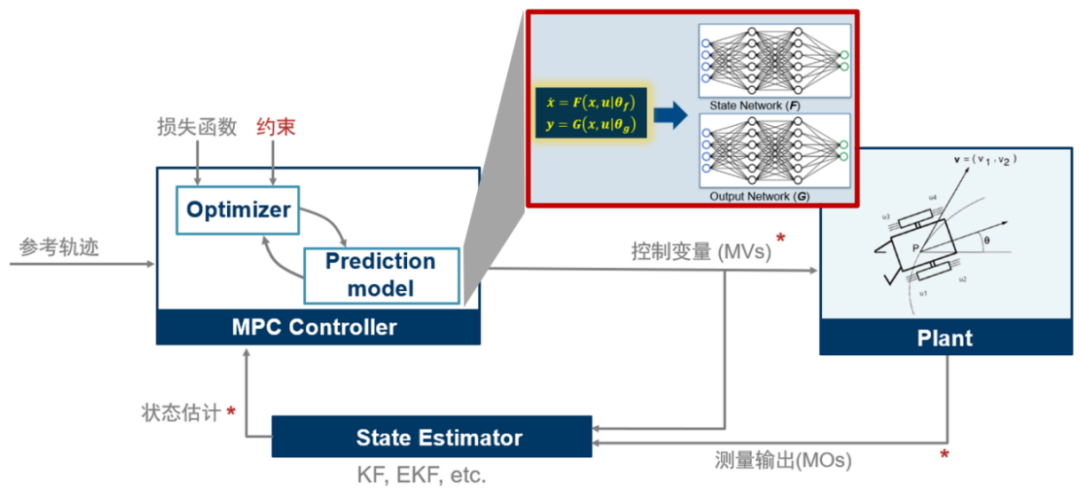
神经网络 ODE 算法与训练
Neural ODE 思想介绍
神经网络状态空间模型是基于神经网络 ODE 实现的,这里可以简单介绍一下实现思路(在前面的文章 数据驱动的动态系统建模-深度学习中简单介绍了训练的思想。在视频[7]
https://www.bilibili.com/video/BV1sU4y1z7Qb/中介绍了实现过程)。
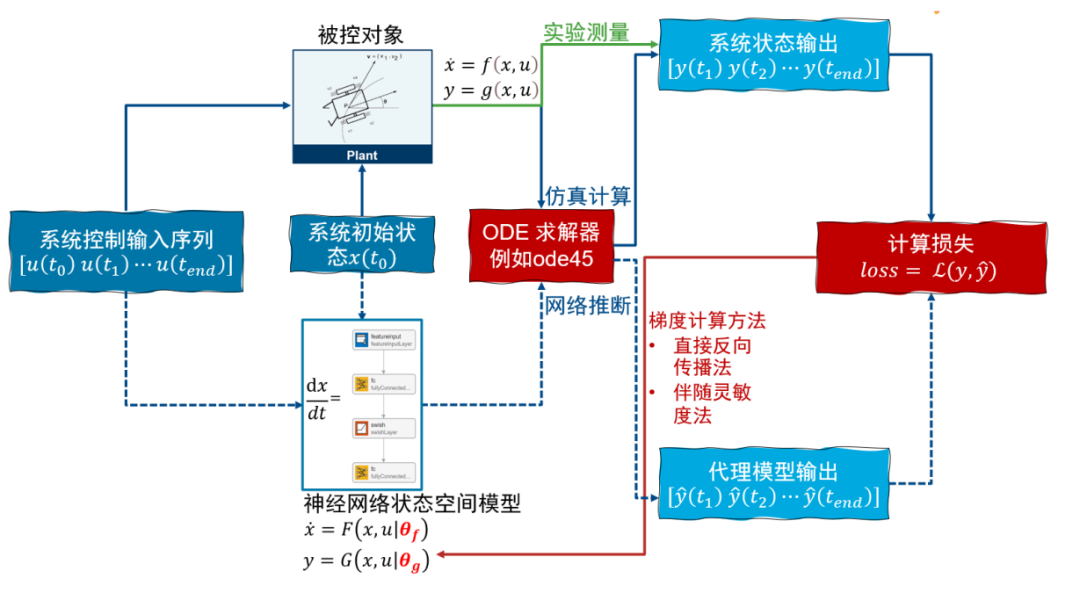
对于一个被控对象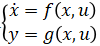 初始状态 x(t0),作用一个控制输入序列 [u(t0)u(t1)···u(tend)],通过实验测量或者仿真计算(使用 ode 求解器,例如 ode45),可以得到系统的输出 [y(t1)y(t2)···y(tend)],作为真值。我们的目的是训练神经网络状态空间模型的参数 [θf,θg] 使得在相同的初始状态和作用相同的控制输入序列的情况下,通过对神经网络状态空间模型
初始状态 x(t0),作用一个控制输入序列 [u(t0)u(t1)···u(tend)],通过实验测量或者仿真计算(使用 ode 求解器,例如 ode45),可以得到系统的输出 [y(t1)y(t2)···y(tend)],作为真值。我们的目的是训练神经网络状态空间模型的参数 [θf,θg] 使得在相同的初始状态和作用相同的控制输入序列的情况下,通过对神经网络状态空间模型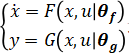
进行计算得到的输出序列 [ŷ(t1)ŷ(t2)···ŷ(tend)] 与系统的真值 [y(t1)y(t2)···y(tend)] 尽量接近,也就是loss=L{ŷ(t),y(t)} 越小越好,其中 L 可以是任何自定义的损失函数。计算神经网络状态空间模型系统输出的过程可以使用 ode 求解器,例如 ode45, 先计算状态转移方程
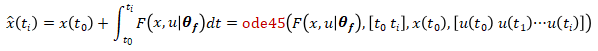
然后计算测量输出方程
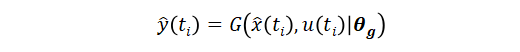
这样就可以计算损失函数,接下来可以按神经网络的训练步骤对参数 [θf,θg] 进行训练。
Neural ODE 训练过程实现
我们通过示意脚本来介绍训练的过程,主要包含六步。
将整个数据集 (一轮 /epoch) 分成小的 chrunk(minibatches).
在每次迭代 (each minibatch), 进行预处理.
将输入数据传给网络进行前馈计算 (inference).
和真值进行比较 (i.e. compute loss function).
自动微分 (compute gradients of each layer or operation
in the network w.r.t. loss)
更新模型权重和偏置 (parameters)
%遍历轮数
for epoch= 1:numEpochs
%每一轮的迭代数,一次迭代一个minibatch用于更新一次模型参数
for i= 1:numIterperEpoch
iter=iter + 1;
%创建每次迭代用于训练模型参数的 minibatch
数据集,包含控制序列和输出序列(真值)
[dlU,dlY,timeIds]=
createMiniBatch(neuralOdeTimesteps,
UtrainCell,YtrainCell);
…
%@modelGradients 函数为了计算损失对模型
参数的梯度,总共完成了三个任务:
· 将输入数据传给网络进行前馈计算(inference).
· 和真值进行比较计算loss
(i.e. compute loss function).
· 计算梯度
[grads,loss]=dlfeval(@modelGradients,
dlX0,dlYTarge,dlU(或者插值体),
parameters,tspan);
%利用计算得到的梯度使用优化求解器 adam
更新模型权重和偏置
[parameters,averageGrad2,averageSqGrad2]=
adamupdate(parameters,grads,averageGrad,
averageSqGrad,iter,learnRate,gradDecay,
sqGradDecay);
end
end
%modelGradient 函数完成三个任务
function[grad,loss]=modelGradients(dlTarget,
dlX0, dlU, params, tspan)
%neuralStateMode l 函数(接下来列出来的函数)
就是利用初始状态和控制序列进行网络推断计算。
dlY= neuralStateModel(dlX0, dlU, params, tspan);
%利用模型推断结果和真值进行损失计算
loss= huber(dlY, dlTarget);
%利用损失进行梯度计算
grad= dlgradient(loss, params);
end
function Y= neuralStateModel(stateX0, controlX, Params, tspan)
%odeModel 函数对应着状态方程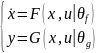 中的F(x,u|θf),基于初始状态,和当前神经网络参数下的状态方程,利用 dlode45 进行积分求解,得到对应的模型推断的状态序列 stateX
中的F(x,u|θf),基于初始状态,和当前神经网络参数下的状态方程,利用 dlode45 进行积分求解,得到对应的模型推断的状态序列 stateX
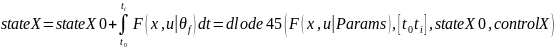
%odeModel 对应 F
stateX= dlode45(@(t,y,p)odeModel
(t,y,p,controlX),[0tspan],
stateX0,Params.neuralode);
% 下面的代码利用计算的状态序列和输入的控制序列,通过构造G(x,u|θg)来计算得到测量输出Y
stateControl = cat(1,stateX,controlX);
…(此处省去多层连接)
Y = fullyconnect(stateControl,Param.fc1.Weights,);
end
function dxdt = odeModel(t,y,thetaODE,controlu)
% 这个函数就是构造状态方程 Ẋ=F(x,u|θf) 中的右半部分 F(x,u|θf)
dxdt = cat(1,u,y);
dxdt = thetaODE.fc1.Weights*dxdt + thetaODE.fc1.Bias;
… (可以自定义层逻辑)
end
其中利用损失进行梯度计算时,可以直接用反向传播方法进行自动微分,根据 BP 算法原理,要保留在前向计算过程中模型中的激活值,尤其进行 ode 积分求解时,积分时长 tspan 较长,或者积分步长较小导致积分步数过多,都会使网络前向计算保留较多的激活值(用于反向传播进行自动微分),这就对内存有了较高的要求。为了解决这个问题,计算梯度的时候,原文[8]使用了伴随梯度算法(adjoint method), 把梯度的计算变成了求解带初值的另外一个常微分方程问题,只需要当前激活作为初值,直接可以使用 ODE 求解器计算这个新的常微分方程得到各个时刻损失对网络参数的梯度,而不需要保留前向过程中的激活。具体的细节可以看原论文[8]证明。具体使用哪种微分计算可以通过设置 dlode45 这个针对神经网络微分方程的 ODE 求解器的属性来实现[9]。
工程师更友好的神经网络状态空间模型辨识
通过上述脚本实现模型的训练,可以得到一个训练好的神经网络状态空间模型。对于领域工程师,MATLAB 提供了一种更集成的方式实现上述过程,将上述的六个步骤集成在一个 nlssest 函数中,我们通过这种简单易用的方式对飞行机器人被控对象模型进行神经网络状态空间模型的辨识。
%创建一个 idNeuralStateSpace 对象,包含6个状态量和4个控制输入.
obj=idNeuralStateSpace(6,NumInputs=4);
%系统因为状态量就是测量输出,所以只需要创建一个状态方程 Ẋ=F(x,u|θf),测量方程是个恒等式 (G(x,u|θg)=I,即 Y=I*X),自定义状态方程的网络节点数和层数.
obj.StateNetwork = createMLPNetwork(obj,'state',...
LayerSizes=[32 32 32],...
Activations='tanh',...
WeightsInitializer="glorot",...
BiasInitializer="zeros");
% 设置训练选项
options = nssTrainingOptions('adam');
% 使用nlssest利用实验数据/仿真数据对构建的进行参数的训练
% 完成了上述六个步骤
nss=nlssest(U,X,obj,options,'UseLastExperimentForValidation',true);
训练完成得到状态空间模型 nss 后,可以使用 generateMATLABFunction 自动为这个神经网络状态空间模型生成状态方程和雅可比函数解析式。
generateMATLABFunction(nss,'nssStateFcn');
function [A, B] = nssStateFcnJacobian(x,u)
% 这是自动生成的神经网络状态模型的雅可比函数
%# codegen
persistent StateNetwork
MATname = 'nssStateFcnData';
if isempty(StateNetwork)
StateNetwork = coder.load(MATname);
end
out = [x;u];
J = eye(length(out));
% 第一层隐含层
Jfc=StateNetwork.fc1.Weights;
out=StateNetwork.fc1.Weights*out+StateNetwork.fc1.Bias;
Jac = deep.internal.coder.jacobian.tanh(out);
…
% output layer
J = StateNetwork.output.Weights*J;
end
将训练的神经网络状态空间模型作为MPC中的预测模型
我们把自动生成生成的状态方程和雅可比函数赋给 MPC 的模型。
nlobj_tracking.Model.StateFcn =
'nssStateFcn';
nlobj_tracking.Jacobian.StateFcn=
'nssStateFcnJacobian';
使用含有神经网络状态空间模型的 MPC 再次进行闭环仿真,代码跟上述使用第一原理的 MPC 一样,查看追踪效果。
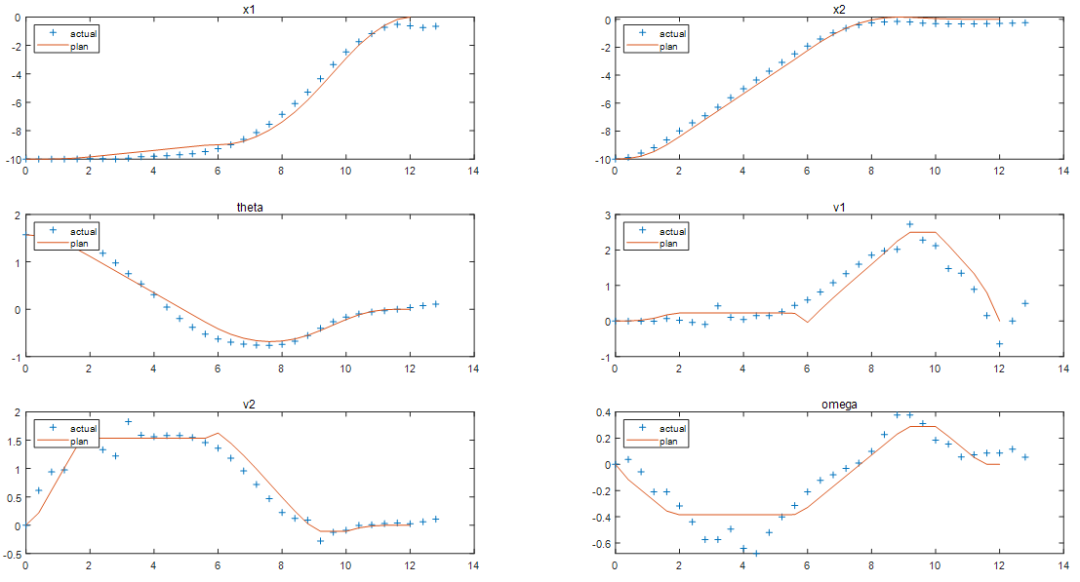
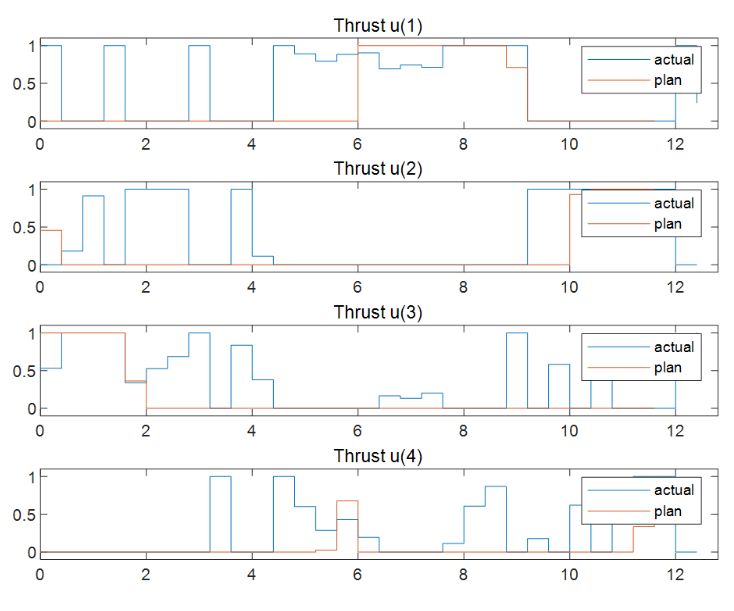
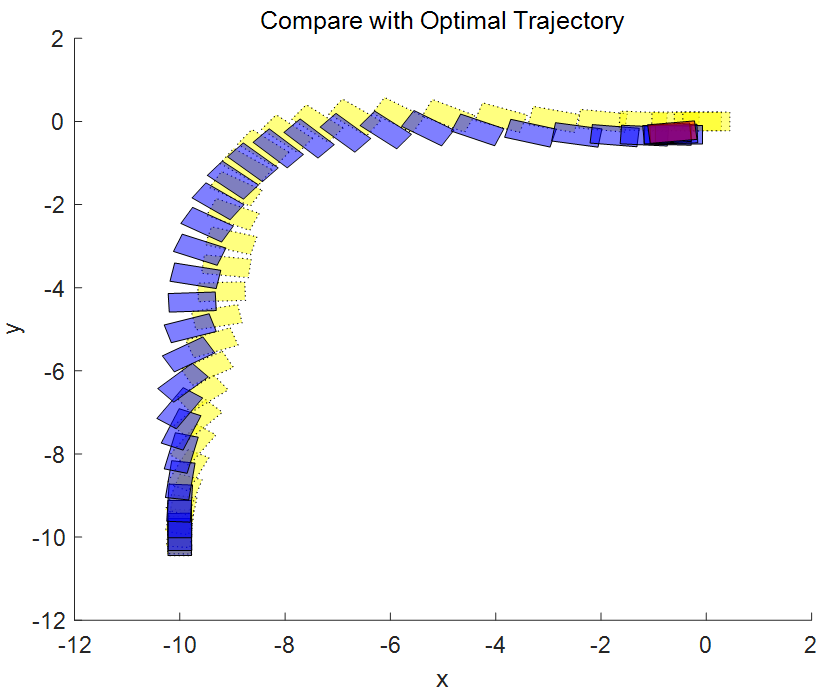
将计划的闭环轨迹与实际的闭环轨迹进行比较。响应与基于第一性原理的预测模型结果相对接近。
总结
本文旨在提供一种将 AI 和模型预测控制结合的方法,可以将训练的神经网络状态空间方程的模型给到模型预测控制器中使用,从而在第一原理模型不存在的情况下也可以实现预测控制。对于模型预测控制本身比较复杂,包括类型选择和加速等等。
编辑:黄飞
-
bp神经网络预测模型建模步骤2024-07-11 2482
-
神经网络预测模型的构建方法2024-07-05 3170
-
构建神经网络模型的常用方法 神经网络模型的常用算法介绍2023-08-28 1779
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 2586
-
卷积神经网络模型发展及应用2022-08-02 13417
-
模型预测控制介绍2021-08-18 2796
-
模型预测控制+逻辑控制2021-08-17 1924
-
如何构建神经网络?2021-07-12 2043
-
基于BP神经网络优化的光伏发电预测模型2021-06-27 1335
-
【AI学习】第3篇--人工神经网络2020-11-05 4331
-
Keras之ML~P:基于Keras中建立的回归预测的神经网络模型2018-12-20 4480
-
基于RBF神经网络的通信用户规模预测模型2017-11-22 1331
-
用matlab编程进行BP神经网络预测时如何确定最合适的,BP模型2014-02-08 3642
-
基于BP神经网络预报的动态矩阵预测控制2009-04-10 587
全部0条评论

快来发表一下你的评论吧 !
