

 7.100ASK_V853-PRO开发板支持人形检测和人脸识别
7.100ASK_V853-PRO开发板支持人形检测和人脸识别
描述
1.前言
V853 芯片内置一颗 NPU核,其处理性能为最大 1 TOPS 并有 128KB 内部高速缓存用于高速数据交换,支持 OpenCL、OpenVX、android NN 与 ONNX 的 API 调用,同时也支持导入大量常用的深度学习模型。本章提供一个例程,展示如何使用V853芯片中的NPU部分进行人形检测和人脸识别。
资源包(含有应用程序和yuvplayer软件包):source.zip
100ASK_V853-PRO开发板资料汇总:
链接:100ASK_100ASK-PRO 资料汇总 - Allwinner / V853-Pro - 嵌入式开发问答社区
100ASK_V853-PRO开发板购买链接:100ASK_V853-PRO开发板

2.示例程序目录
将上述资源包下载完成解压后,把示例程序100ASK_viplite-driver放在Ubuntu中的任意目录中。假设我放在/home/book/workspaces目录下,下面为人形识别和人脸识别应用程序的目录结构。
book@100ask:~/workspaces/100ASK_viplite-driver$ tree
.
├── 100ASK_Algo
│ ├── det_demo
│ │ ├── 100ASK_det_demo
│ │ ├── aw_errors.c
│ │ ├── aw_errors.h
│ │ ├── body_384x216.yuv
│ │ ├── body_640x360.yuv
│ │ ├── demo.cc
│ │ ├── face_480x270.nv12
│ │ ├── list.c
│ │ ├── list.h
│ │ ├── Makefile
│ │ ├── Readme.txt
│ │ └── testcase.txt
│ ├── fdet
│ │ └── 100ASK_Facedet_480_288_nv12.nb
│ ├── include
│ │ ├── awnn_det.h
│ │ ├── awnn.h
│ │ ├── awnn_info.h
│ │ ├── awnn_lib.h
│ │ └── cross_utils.h
│ ├── libawnn.a
│ ├── libawnn.so
│ ├── pdet
│ │ ├── 100ASK_humandet_384_224_V0.nb
│ │ ├── 100ASK_humandet_384_224_V1.nb
│ │ ├── 100ASK_humandet_640_384_V0.nb
│ │ └── 100ASK_humandet_640_384_V1.nb
│ └── Readme.txt
└── sdk_release
├── libVIPlite.a
├── libVIPlite.so
├── libVIPuser.a
├── libVIPuser.so
└── sdk
├── vip_lite_common.h
└── vip_lite.h
7 directories, 31 files
其中100ASK_Algo文件包含了:
1.det_demo目录包含应用程序和测试图片
2.fdet目录包含人脸模型
3.include目录包含应用程序头文件和
4.pdet目录包含人形模型
sdk_release中包含了NPU相关的模型处理文件
3.主函数demo.cc
下面仅对应用程序中的demo.cc程序中的main.cc进行讲解,对于其他代码,您可以直接查看应用程序压缩包的其他文件。
int main(int argc, char* argv[]) {
if (argc != 2) {
printf("%s testcase.txtn", argv[0]);
return 0;
}
int count = 0;
/*创建一个结构体获取参数1的中的数据,该结构体是输入nbg路径,返回awnn_info_t结构体。包含库名称,网络输入图像宽高,内存占用大小,阈值信息等,其中count为处理的图像和网络模型个数*/
network_info_t **infos = create_infos_from_testcase(argv[1], count);
printf("count=%dn", count);
if (count && infos) {
awnn_info_t * nbinfo;
unsigned int mem_size = 0;
pthread_t thread[count] = {0};
//获取参数1获取对应模型个数
for (int i = 0; i < count; i++) {
nbinfo = awnn_get_info(infos[i]->nbg);
printf("info %s %s %u %u %u %fn", nbinfo->name, nbinfo->md5,
nbinfo->width, nbinfo->height, nbinfo->mem_size, nbinfo->thresh);
infos[i]->nbinfo = nbinfo;
mem_size += nbinfo->mem_size;
}
//根据内存初始化申请NPU模型所需的内存大小
printf("mem_size: %un", mem_size);
awnn_init(mem_size);
//创建线程处理模型和图片
for (int i = 0; i < count; i++) {
pthread_create(&thread[i], NULL, detect_thread, infos[i]);
}
for (int i = 0; i < count; i++) {
if (thread[i] != 0)
pthread_join(thread[i], NULL);
}
awnn_uninit();
}
//销毁结构体内存
destroy_infos(infos, count);
return 0;
}
可以看到上述过程并没有涉及到模型的处理过程,可以查看100ASK_viplite-driver/100ASK_Algo/include/目录中对应函数的函数说明。
4.编译应用程序
假设我将应用程序文件夹100ASK_viplite-driver放在~/workspaces/100ASK_viplite-driver,进入应用程序目录下
book@100ask:~$ cd ~/workspaces/100ASK_viplite-driver/
book@100ask:~/workspaces/100ASK_viplite-driver$ cd 100ASK_Algo/det_demo/
假设我的Tina SDK放在/home/book/workspaces/tina-v853-open,为应用程序增加环境变量。
book@100ask:~/workspaces/100ASK_viplite-driver/100ASK_Algo/det_demo$ export TINA_TOP=/home/book/workspaces/tina-v853-open
book@100ask:~/workspaces/100ASK_viplite-driver/100ASK_Algo/det_demo$ export STAGING_DIR=~/workspaces/tina-v853-open/openwrt/openwrt/staging_dir/
添加完成后即可编译应用程序
book@100ask:~/workspaces/100ASK_viplite-driver/100ASK_Algo/det_demo$ make
/home/book/workspaces/tina-v853-open/prebuilt/rootfsbuilt/arm/toolchain-sunxi-musl-gcc-830/toolchain/bin/arm-openwrt-linux-muslgnueabi-g++ demo.cc list.c aw_errors.c -I./ -I./../../100ASK_Algo/include -L./../../100ASK_Algo -L./../../sdk_release -l:libawnn.a -l:libVIPlite.a -l:libVIPuser.a -o 100ASK_det_demo
book@100ask:~/workspaces/100ASK_viplite-driver/100ASK_Algo/det_demo$ ls
100ASK_det_demo aw_errors.h body_640x360.yuv face_480x270.nv12 list.h Readme.txt
aw_errors.c body_384x216.yuv demo.cc list.c Makefile testcase.txt
编译完成后,可以在当前目录下生成一个名为100ASK_det_demo的应用程序。
5.修改testcase.txt
testcase.txt文件里面包含有模型路径、待检测的图像、图像尺寸。下面对该文件进行详细的解读,testcase.txt原文件为:
# example:
# [network]
# network type thresh loop
# input1 width height
# input2 width height
# input3 width height
#
# network: nbg path
# type: 1(humanoidv1.0),3(humanoidv3.0),4(face)
# thresh: postprocess thresh
# loop: loop count
# input: multi test case each in oneline
[network]
models/100ASK_humandet_640_384_V1.nb 1 0.25 1
body_640x360.yuv 640 360
[network]
models/100ASK_humandet_384_224_V1.nb 3 0.25 1
body_384x216.yuv 384 216
[network]
models/100ASK_Facedet_480_288_nv12.nb 4 0.6 1
face_480x270.nv12 480 270
可以看到文件已经对该文件如何使用和网络节点的各参数定义有了解释。testcase.txt文件中可以包含有多个处理的模型,每个需要处理的模型需要有特定的格式要求,假设我现在使用的是100ASK_humandet_640_384_V1.nb模型文件处理test1_640x360.yuv的图像文件,则可以修改testcase.txt文件为
[network]
models/100ASK_humandet_640_384_V1.nb 1 0.25 1
test1_640x360.yuv 640 360
models/100ASK_humandet_640_384_V1.nb为模型的存放路径;1为模型的类别;0.25为后处理阈值;1为循环次数;test1_640x360.yuv为测试图像的名称;640 360为测试图像的尺寸。
**注意:**100ASK_humandet_640_384_V1.nb为类别1,100ASK_humandet_384_224_V1.nb为类别3。
如果你还想使用同一个模型,增加一个test2_640x360.yuv测试图像,可以直接在该模型下增加
test2_640x360.yuv测试图像和图像尺寸,例如:
[network]
models/100ASK_humandet_640_384_V1.nb 1 0.25 1
test1_640x360.yuv 640 360
test2_640x360.yuv 640 360
6.运行测试程序
我们在示例程序中已经放入供您进行测试使用的图像,您也可以使用TF卡将虚拟机中的应用程序、模型和测试图像等文件拷贝到TF卡中 ,TF卡中的文件结构应如下所示
book@100ask:/media/book/B89C-7C55$ tree
.
├── 100ASK_det_demo
├── body_384x216.yuv
├── body_640x360.yuv
├── face_480x270.nv12
├── models
│ ├── 100ASK_Facedet_480_288_nv12.nb
│ ├── 100ASK_humandet_384_224_V1.nb
│ └── 100ASK_humandet_640_384_V1.nb
└── testcase.txt
可以看到应用程序、测试图片和testcase.txt文件放在TF卡根目录的文件夹下,单独创建一个models文件夹将模型文件放在该文件夹下。
将开发板板上电,插入12V电源线和2条Type-C数据线后,再将TF卡插入开发板中

启动完成开发板后,挂载TF卡到/mnt目录下,输入mount /dev/mmcblk1p1 /mnt/
root@TinaLinux:/# [ 9866.263682] sunxi-mmc sdc0: sdc set ios:clk 0Hz bm PP pm UP vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.523742] sunxi-mmc sdc0: no vqmmc,Check if there is regulator
[ 9866.553676] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.593686] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.606971] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.619855] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.633161] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.855649] sunxi-mmc sdc0: sdc set ios:clk 0Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.866027] sunxi-mmc sdc0: no vqmmc,Check if there is regulator
[ 9866.893675] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 1 timing LEGACY(SDR12) dt B
[ 9866.914333] mmc1: host does not support reading read-only switch, assuming write-enable
[ 9866.924044] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 4 timing LEGACY(SDR12) dt B
[ 9866.938320] sunxi-mmc sdc0: sdc set ios:clk 400000Hz bm PP pm ON vdd 22 width 4 timing UHS-DDR50 dt B
[ 9866.948838] sunxi-mmc sdc0: sdc set ios:clk 50000000Hz bm PP pm ON vdd 22 width 4 timing UHS-DDR50 dt B
[ 9866.959640] mmc1: new ultra high speed DDR50 SDHC card at address aaaa
[ 9866.967694] mmcblk1: mmc1:aaaa SU08G 7.40 GiB
[ 9866.990824] mmcblk1: p1
root@TinaLinux:/# mount /dev/mmcblk1p1 /mnt/
[ 3573.953864] FAT-fs (mmcblk1p1): Volume was not properly unmounted. Some data may be corrupt. Please run fsck.
进入mnt目录下即可看到TF卡内的文件
root@TinaLinux:/# cd /mnt/
root@TinaLinux:/mnt# ls
100ASK_det_demo face_480x270.nv12
System Volume Information models
body_384x216.yuv testcase.txt
body_640x360.yuv
root@TinaLinux:/mnt# ls models/
100ASK_Facedet_480_288_nv12.nb 100ASK_humandet_640_384_V1.nb
100ASK_humandet_384_224_V1.nb
确保应用程序、模型文件夹中的模型文件、测试图片、testcase.txt都存在后,即可开始运行测试程序,输入
./100ASK_det_demo testcase.txt
root@TinaLinux:/mnt# ./100ASK_det_demo testcase.txt
count=3
info 05dc32ee903c08a3abd53ddd829a8dd5 640 384 10061394 0.000000
info 827b3a725d0fd7173338a56fd06c8db0 384 224 2829624 0.000000
info 3d42fcd47490a62d52ea021760[ 7944.592701] npu[665][665] vipcore, device init..
[ 7944.600170] set_vip_power_clk ON
mem_size: 16530637
Version: AW[ 7944.608597] enter aw vip mem alloc size 16530637
NN_LIB_1.0.3
[0xb6f8f560]vip_in[ 7944.615697] aw_vip_mem_alloc vir 0xe1328000, phy 0x48800000
it[121],
The version of Viplit[ 7944.623477] npu[665][665] gckvip_drv_init kernel logical phy address=0x48800000 virtual =0xe1328000
e is: 1.8.0-0-AW-2023-02-24
VIPLite driver version=0x00010800...
malloc 384x224 nv12 buffer
malloc 480x288 nv12 buffer
malloc 640x384 nv12 buffer
save file: post_body_384x216.yuv
save file: post_face_480x270.nv12
save file: post_body_640x360.yuv
[ 7946.373546] npu[665][665] gckvip_drv_exit, aw_vip_mem_free
[ 7946.379816] aw_vip_mem_free vir 0xe1328000, phy 0x48800000
[ 7946.386027] aw_vip_mem_free dma_unmap_sg_atrs
[ 7946.391003] aw_vip_mem_free ion_unmap_kernel
[ 7946.396101] aw_vip_mem_free ion_free
[ 7946.400118] aw_vip_mem_free ion_client_destroy
[ 7946.410983] npu[665][665] vipcore, device un-init..
执行测试程序完成后可以查看当前目录下的文件,输入ls
root@TinaLinux:/mnt# ls
100ASK_det_demo post_body_640x360.yuv.input_0.txt
System Volume Information post_body_640x360.yuv.input_1.txt
body_384x216.yuv post_body_640x360.yuv.output_0.txt
body_640x360.yuv post_data
face_480x270.nv12 post_face_480x270.nv12
models post_face_480x270.nv12.input_0.txt
post_body_384x216.yuv post_face_480x270.nv12.input_1.txt
post_body_384x216.yuv.input_0.txt post_face_480x270.nv12.output_0.txt
post_body_384x216.yuv.input_1.txt post_face_480x270.nv12.output_1.txt
post_body_384x216.yuv.output_0.txt post_face_480x270.nv12.output_2.txt
post_body_384x216.yuv.output_1.txt testcase.txt
post_body_640x360.yuv
上述文件中,带有post前缀的文件为执行应用程序后生成的文件。其中post_data文件夹含有模型的执行结果和执行性能
post_data/result_TID.txt :输出每个模型检测结果,其中 TID 为检测线程ID号。
post_data/performance_TID.txt :输出每个模型检测性能结果,其中 TID 为检测线程ID号;性能评测时建议运行单个模型且将 stdout 重定向为 /dev/null 。
post_inputN :每个输入的画框结果,其中 inputN 为输入图像路径,直接在路径前添加 post_前缀进行保存,因此输入图像路径请勿添加 ./ 或使用绝对路径。
post_body_384x216.yuv 、post_body_640x360.yuv、post_face_480x270.nv12为输出画框结果的图像。
卸载TF卡所用的文件系统,输入
root@TinaLinux:/mnt# cd ../
root@TinaLinux:/# umount /mnt/
7.使用yuvplayer软件查看图像
将TF卡放入读卡器后,插入电脑端,使用yuvplayer软件打开图像,该文件放在source目录下的yuvplayer-2.5.zip,解压后即可使用。设置图像尺寸和颜色空间即可查看图像。
在电脑端,打开U盘文件夹。注意:您之前没使用过yuvplayer.exe,可能不会出现我的.nv12文件一样的图标,但不影响后续的操作。
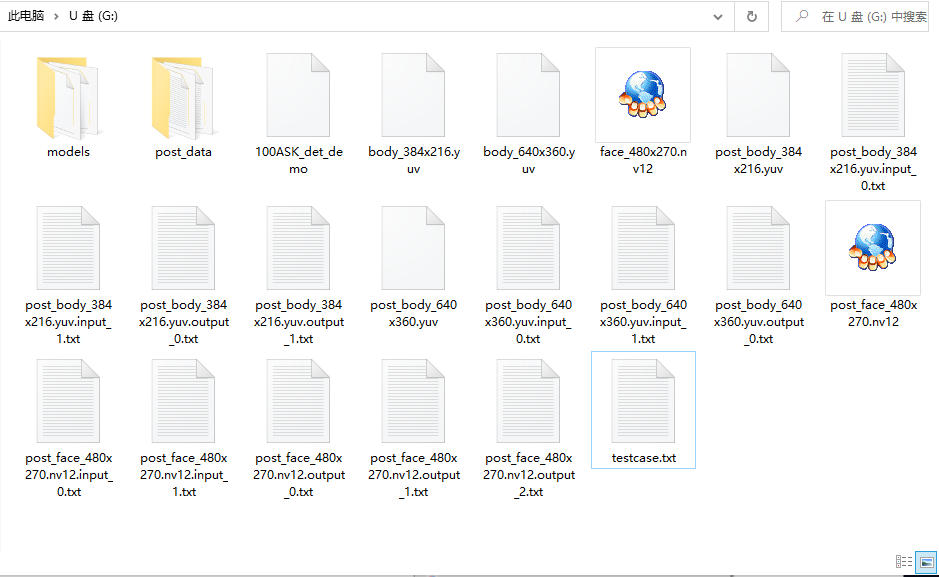
选择我们需要查看的图像,例如我想查看body_640x360.yuv文件,单击body_640x360.yuv文件后,右键后选择打开方式。
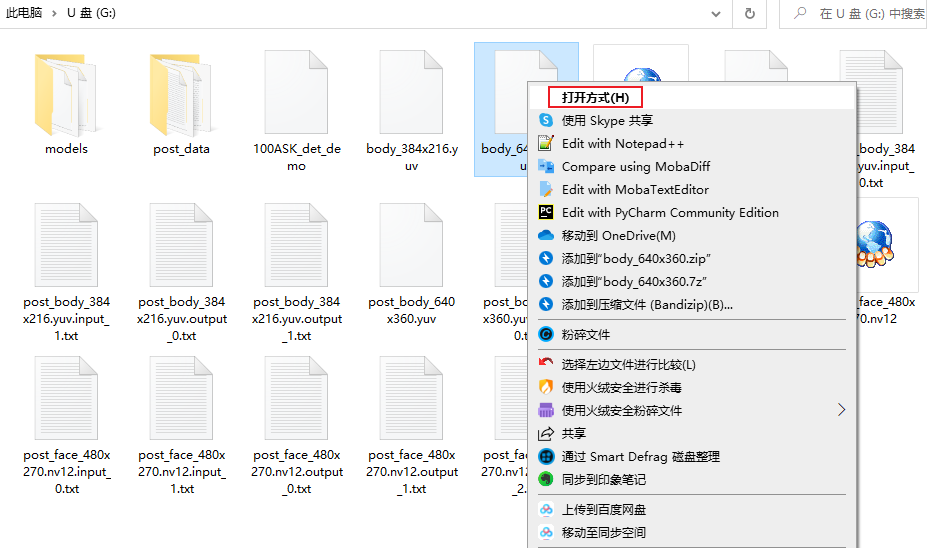
点击更多应用
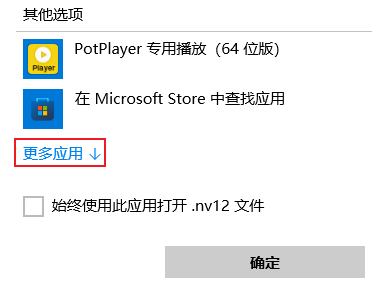
使用滚轮往下滑,点击在这台电脑上查找其他应用

找到yuvplayer-2.5.zip解压出来的yuvplayer-2.5文件夹中的yuvplayer.exe文件,选中该文件后点击打开
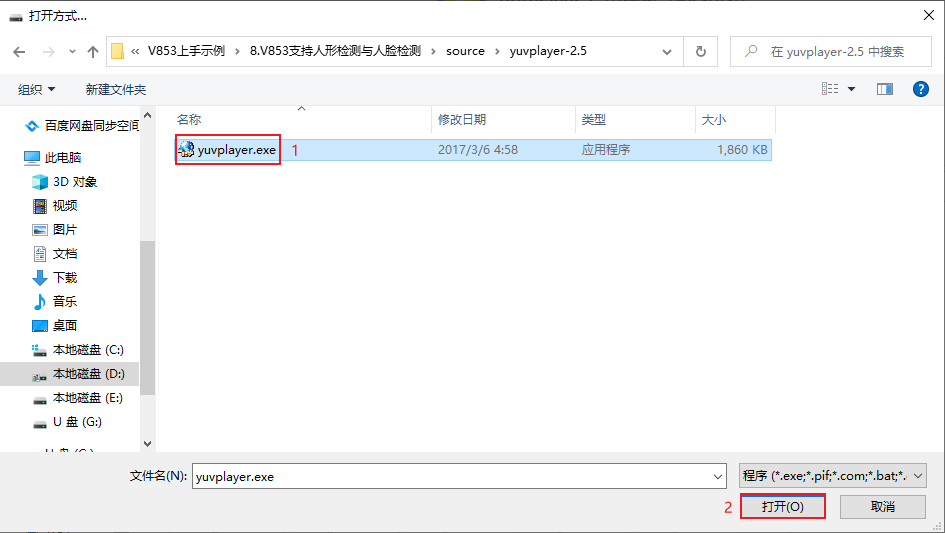
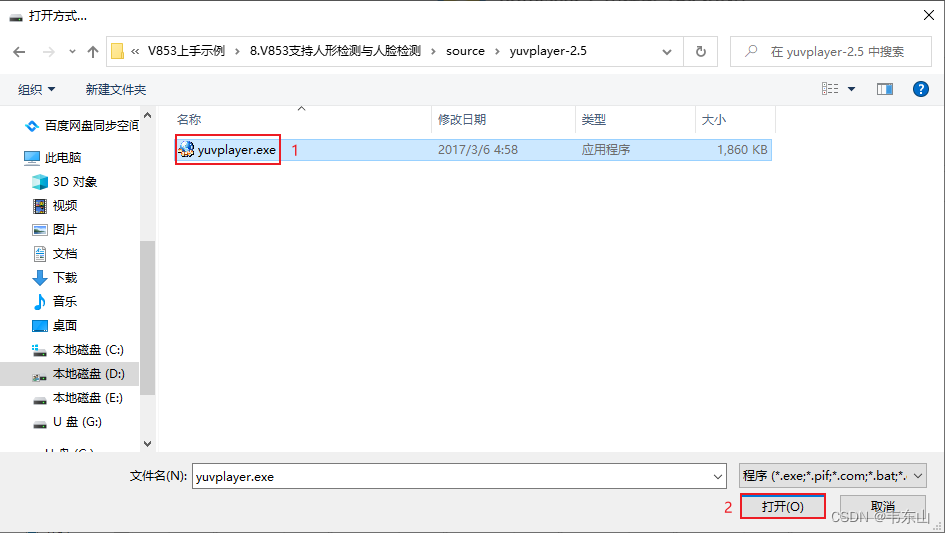
打开后,会出现如下画面,该画面是由于没有设置尺寸和颜色空间导致的
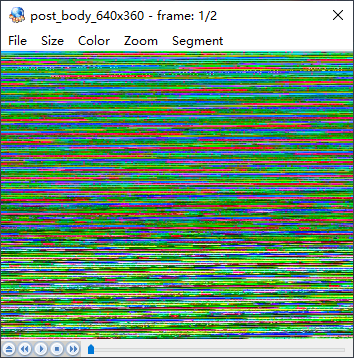
在选项栏中点击Size后,选择Custom。这样的选择意思是选择自定义尺寸
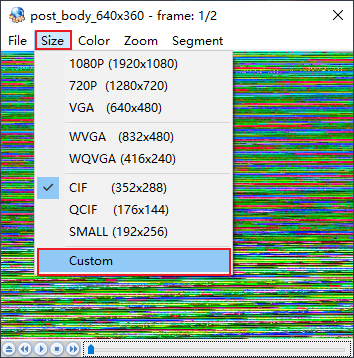
在自定义尺寸界面输入图像尺寸,该图像尺寸宽为640,高为360,设置完成后点击确定
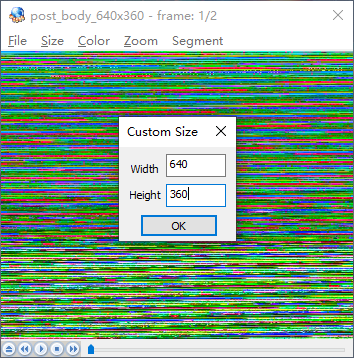
确定完成之后可以,看到大致的图像,但此时还需要修改显示的图像空间。

在选项栏中点击选择Color后,点击选择NV12颜色空间
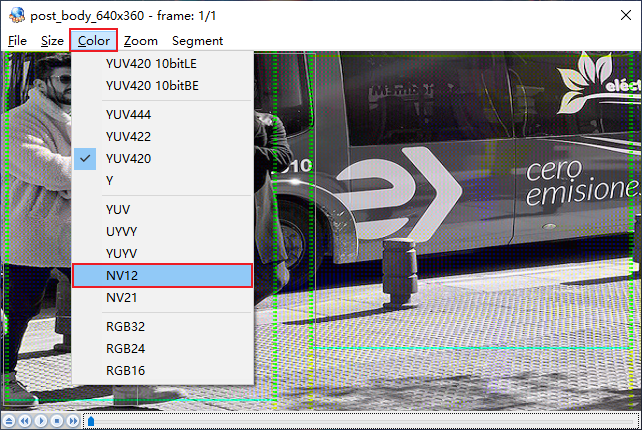
选择完成后,即可看到正常的图像
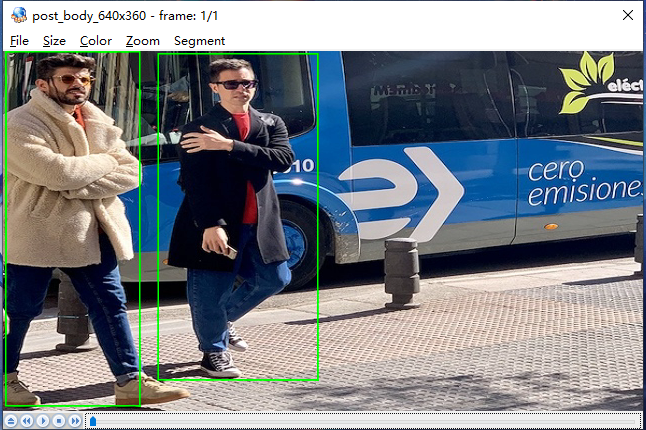
其他图像的查看方式也同理,值得注意的是每张图像的尺寸可能不一样,需要根据源图像的尺寸设置。
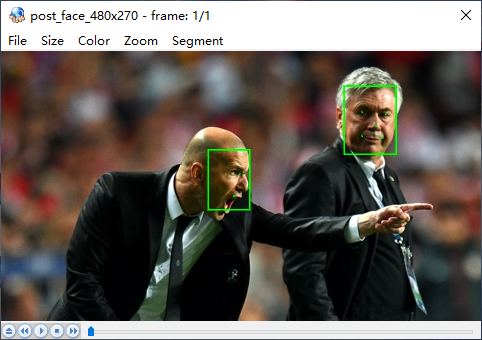
使用yuvplayer查看post_face_480x270.nv12 图像文件为:
7.使用自定义图片测试
由于我们平常使用的图片格式多为JPG或者PNG格式,其图像数据格式都为RGB等常见颜色空间,但在视频编解码和视频传输应用中通常使用NV12的视频存储格式,它将图片中 Y 轴色度信息和 UV 轴亚像素信息存储在同一个平面中。这就导致在 NV12 格式中,图像的每一行都存储一个 Y 值(代表色度信息),然后每隔两行存储一个 U 和 V 值(代表亚像素信息)。所以NV12 格式中的图像数据通常会比其他格式(如 RGB)少一半。
如果您获取的应用的图像为NV12就不需要进行格式转换,如果您想测试的图像为并不是NV12格式,而是我们常见的RGB格式的JPG或PNG图像,则需要使用工具进行转换。
下面我们使用的工具是ffmpeg,下面演示如何使用ffmpeg进行图像存储格式的转换。
安装ffmpeg,在虚拟机终端界面输入sudo apt-get install ffmpeg
book@100ask:~$ sudo apt-get install ffmpeg
[sudo] password for book:
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
libdumbnet1
Use 'sudo apt autoremove' to remove it.
The following additional packages will be installed:
i965-va-driver libaacs0 libass9 libavcodec57 libavdevice57 libavfilter6
libavformat57 libavresample3 libavutil55 libbdplus0 libbluray2 libbs2b0
libchromaprint1 libcrystalhd3 libdc1394-22 libflite1 libgme0 libgsm1
libllvm10 libmysofa0 libnorm1 libopenal-data libopenal1 libopenjp2-7
libopenmpt0 libpgm-5.2-0 libpostproc54 librubberband2 libsdl2-2.0-0
libshine3 libsnappy1v5 libsndio6.1 libsoxr0 libssh-gcrypt-4 libswresample2
libswscale4 libva-drm2 libva-x11-2 libva2 libvdpau1 libx264-152 libx265-146
libxvidcore4 libzmq5 libzvbi-common libzvbi0 mesa-va-drivers
mesa-vdpau-drivers va-driver-all vdpau-driver-all
Suggested packages:
ffmpeg-doc i965-va-driver-shaders libbluray-bdj firmware-crystalhd
libportaudio2 sndiod libvdpau-va-gl1 nvidia-vdpau-driver
nvidia-legacy-340xx-vdpau-driver
The following NEW packages will be installed:
ffmpeg i965-va-driver libaacs0 libass9 libavcodec57 libavdevice57
libavfilter6 libavformat57 libavresample3 libavutil55 libbdplus0 libbluray2
libbs2b0 libchromaprint1 libcrystalhd3 libdc1394-22 libflite1 libgme0
libgsm1 libllvm10 libmysofa0 libnorm1 libopenal-data libopenal1 libopenjp2-7
libopenmpt0 libpgm-5.2-0 libpostproc54 librubberband2 libsdl2-2.0-0
libshine3 libsnappy1v5 libsndio6.1 libsoxr0 libssh-gcrypt-4 libswresample2
libswscale4 libva-drm2 libva-x11-2 libva2 libvdpau1 libx264-152 libx265-146
libxvidcore4 libzmq5 libzvbi-common libzvbi0 mesa-va-drivers
mesa-vdpau-drivers va-driver-all vdpau-driver-all
0 upgraded, 51 newly installed, 0 to remove and 242 not upgraded.
Need to get 32.5 MB/47.9 MB of archives.
After this operation, 222 MB of additional disk space will be used.
Do you want to continue? [Y/n] y
此时会提示您将有222M空间需要被使用,此时输入y,即可进行下载安装
等待安装完成后,输入ffmpeg -h
book@100ask:~$ ffmpeg -h
ffmpeg version 3.4.11-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 7 (Ubuntu 7.5.0-3ubuntu1~18.04)
...
可以看到ffmpeg的版本号和适用的Ubuntu,后续的使用指南可自行观看,这里就不展示全部输出信息。
下面我们使用《RISC-V嵌入式开发线下交流会》中的照片,尺寸为480×270,图像格式为JPG

book@100ask:~/workspaces/testImg$ ls
test_480-270.jpg
使用ffmpeg进行格式转换,在终端输入ffmpeg -i test_480-270.jpg -s 480x288 -pix_fmt nv12 100ask_face-480-270.yuv
book@100ask:~/workspaces/testImg$ ffmpeg -i test_480-270.jpg -s 480x270 -pix_fmt nv12 100ask_face-480-270.yuv
ffmpeg version 3.4.11-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 7 (Ubuntu 7.5.0-3ubuntu1~18.04)
configuration: --prefix=/usr --extra-version=0ubuntu0.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --enable-gpl --disable-stripping --enable-avresample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librubberband --enable-librsvg --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzmq --enable-libzvbi --enable-omx --enable-openal --enable-opengl --enable-sdl2 --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libopencv --enable-libx264 --enable-shared
libavutil 55. 78.100 / 55. 78.100
libavcodec 57.107.100 / 57.107.100
libavformat 57. 83.100 / 57. 83.100
libavdevice 57. 10.100 / 57. 10.100
libavfilter 6.107.100 / 6.107.100
libavresample 3. 7. 0 / 3. 7. 0
libswscale 4. 8.100 / 4. 8.100
libswresample 2. 9.100 / 2. 9.100
libpostproc 54. 7.100 / 54. 7.100
Input #0, image2, from 'test_480-270.jpg':
Duration: 00:00:00.04, start: 0.000000, bitrate: 5699 kb/s
Stream #0:0: Video: mjpeg, yuvj420p(pc, bt470bg/unknown/unknown), 480x270 [SAR 96:96 DAR 16:9], 25 tbr, 25 tbn, 25 tbc
Stream mapping:
Stream #0:0 -> #0:0 (mjpeg (native) -> rawvideo (native))
Press [q] to stop, [?] for help
[swscaler @ 0x55787ff64b20] deprecated pixel format used, make sure you did set range correctly
Output #0, rawvideo, to '100ask_face-480-270.yuv':
Metadata:
encoder : Lavf57.83.100
Stream #0:0: Video: rawvideo (NV12 / 0x3231564E), nv12, 480x270 [SAR 1:1 DAR 16:9], q=2-31, 38880 kb/s, 25 fps, 25 tbn, 25 tbc
Metadata:
encoder : Lavc57.107.100 rawvideo
frame= 1 fps=0.0 q=-0.0 Lsize= 190kB time=00:00:00.04 bitrate=38880.0kbits/s speed=0.664x
video:190kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000000%
执行完成没有出现报错,并可以输入ls查看转换后的图像文件
book@100ask:~/workspaces/testImg$ ls
test_480-270.jpg 100ask_face-480-270.yuv
可以发现生成了一个名为100ask_face-480-270.yuv文件,该文件的图像尺寸为480×270,图像存储格式为NV12。
将其拷贝到开发板上,与应用程序100ASK_det_demo放在同一目录中,例如:
root@TinaLinux:/mnt# ls
100ASK_det_demo
100ask_face-480-270.yuv
System Volume Information
body_384x216.yuv
body_640x360.yuv
face_480x270.nv12
models
post_100ask_face-480_288.yuv.input_0.txt
post_100ask_face-480_288.yuv.input_1.txt
post_100ask_face-480_288.yuv.output_0.txt
post_100ask_face-480_288.yuv.output_1.txt
post_100ask_face-480_288.yuv.output_2.txt
post_body_384x216.yuv
post_body_384x216.yuv.input_0.txt
post_body_384x216.yuv.input_1.txt
post_body_384x216.yuv.output_0.txt
post_body_384x216.yuv.output_1.txt
post_body_640x360.yuv
post_body_640x360.yuv.input_0.txt
post_body_640x360.yuv.input_1.txt
post_body_640x360.yuv.output_0.txt
post_data
post_face_480x270.nv12
post_face_480x270.nv12.input_0.txt
post_face_480x270.nv12.input_1.txt
post_face_480x270.nv12.output_0.txt
post_face_480x270.nv12.output_1.txt
post_face_480x270.nv12.output_2.txt
testcase.txt
修改testcase.txt,增加人脸模型的输入图像,在串口终端输入
root@TinaLinux:/mnt# vi testcase.txt
修改文件内容为:
# example:
# [network]
# network type thresh loop
# input1 width height
# input2 width height
# input3 width height
#
# network: nbg path
# type: 1(humanoidv1.0),3(humanoidv3.0),4(face)
# thresh: postprocess thresh
# loop: loop count
# input: multi test case each in oneline
[network]
models/100ASK_humandet_640_384_V1.nb 1 0.25 1
body_640x360.yuv 640 360
[network]
models/100ASK_humandet_384_224_V1.nb 3 0.25 1
body_384x216.yuv 384 216
[network]
models/100ASK_Facedet_480_288_nv12.nb 4 0.6 1
face_480x270.nv12 480 270
100ask_face-480-270.yuv 480 270
运行100ASK_det_demo应用程序
root@TinaLinux:/mnt# ./100ASK_det_demo testcase.txt
count=3
info 05dc32ee903c08a3abd53ddd829a8dd5 640 384 10061394 0.000000
info 827b3a725d0fd7173338a56fd06c8db0 384 224 2829624 0.000000
info 3d42fcd47490a62d52ea021760[ 212.538113] npu[465][465] vipcore, device init..
[ 212.545449] set_vip_power_clk ON
mem_size: 16530637
Version: AW[ 212.553935] enter aw vip mem alloc size 16530637
NN_LIB_1.0.3
[0xb6fe0560]vip_init[121],
The version of Viplite is: 1.8.0-0-AW-2023-02-24
[ 212.569158] aw_vip_mem_alloc vir 0xe1353000, phy 0x48800000
[ 212.575548] npu[465][465] gckvip_drv_init kernel logical phy address=0x48800000 virtual =0xe1353000
VIPLite driver version=0x00010800...
malloc 480x288 nv12 buffer
malloc 384x224 nv12 buffer
malloc 640x384 nv12 buffer
save file: post_body_384x216.yuv
save file: post_face_480x270.nv12
save file: post_body_640x360.yuv
save file: post_100ask_face-480-270.yuv
[ 215.019076] npu[465][465] gckvip_drv_exit, aw_vip_mem_free
[ 215.025231] aw_vip_mem_free vir 0xe1353000, phy 0x48800000
[ 215.031525] aw_vip_mem_free dma_unmap_sg_atrs
[ 215.036451] aw_vip_mem_free ion_unmap_kernel
[ 215.041627] aw_vip_mem_free ion_free
[ 215.045646] aw_vip_mem_free ion_client_destroy
[ 215.051785] npu[465][465] vipcore, device un-init..
使用yuvplayer软件查看图像,配置图像的尺寸:宽480、高270;配置图像颜色空间为NV12

可以看到该模型已经检测到大部分人脸模型,可能由于图像过于模糊导致有个别未能识别到,但该模型的精度还是比较高的。这里仅演示人脸识别,对于人形识别大家也可以参考这个示例自行去修改增加。参考这个示例大家可以去自己尝试获取自定义的图像进行人脸识别或人形检测。
-
【Milk-V Duo S 开发板免费体验】人脸检测2025-07-27 1583
-
11. 100ASK-V853-PRO开发板 RGB屏测试指南2023-06-16 2032
-
9.100ASK_V853-PRO开发板支持E907小核开发2023-05-12 3754
-
5.100ASK_V853-PRO开发板支持按键输入2023-05-11 2554
-
100ASK_全志V853-PRO开发板支持人形检测和人脸识别2023-05-10 1201
-
100ASK_全志V853-PRO开发板 环境配置及编译烧写2023-05-04 1382
-
100ASK_V853-PRO开发板支持人形检测与人脸检测2023-04-27 1313
-
【开源硬件大赛】基于全志V853设计的全功能BTB学习开发板2022-12-07 5394
-
V853 PER1开发板PCB文件2022-10-21 583
-
全志V853开发板双目摄像头模组原理图202206242022-10-19 1386
-
【全志V853开发板试用】国产之光——全志V853开发硬件介绍2022-08-29 5607
全部0条评论

快来发表一下你的评论吧 !
