

一条SQL如何被MySQL架构中的各个组件操作执行的?
描述
1. 单表查询 SQL 在 MySQL 架构中的各个组件的执行过程
简单用一张图说明下,MySQL 架构有哪些组件,接下来给大家用 SQL 语句分析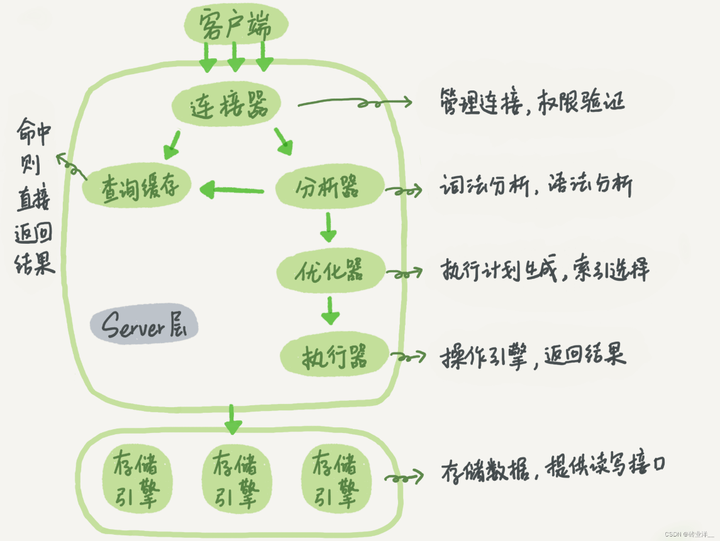
假如 SQL 语句是这样
SELECT class_no FROM student WHERE name = 'lcy' AND age > 18 GROUP BY class_no其中 name 为索引,我们按照时间顺序来分析一下
1. 客户端:客户端(如 MySQL 命令行工具、Navicat、MySQL Workbench 或其他应用程序)发送 SQL 查询到 MySQL 服务器。
2. 连接器:连接器负责与客户端建立连接、管理连接和维护连接。当客户端连接到 MySQL 服务器时,连接器验证客户端的用户名和密码,然后分配一个线程来处理客户端的请求。
3. 查询缓存:查询缓存用于缓存先前执行过的查询及其结果。当收到新的查询请求时,MySQL 首先检查查询缓存中是否已有相同的查询及其结果。如果查询缓存中有匹配的查询结果,MySQL 将直接返回缓存的结果,而无需再次执行查询。但是,如果查询缓存中没有匹配的查询结果,MySQL 将继续执行查询。查询缓存在 MySQL 8.0 中已被移除,不详细解释。
4. 分析器:
解析查询语句,检查语法。
验证表名和列名的正确性。
生成查询树。
5. 优化器:分析查询树,考虑各种执行计划,估算不同执行计划的成本,选择最佳的执行计划。在这个例子中,优化器可能会选择使用 name 索引进行查询,因为 name 是索引列。
6. 执行器:根据优化器选择的执行计划,向存储引擎发送请求,获取满足条件的数据行。
7. 存储引擎(如 InnoDB):
负责实际执行索引扫描,如在 student 表的 name 索引上进行等值查询,因查询全部列,涉及到回表访问磁盘。
在访问磁盘之前,先检查 InnoDB 的缓冲池(Buffer Pool)中是否已有所需的数据页。如果缓冲池中有符合条件的数据页,直接使用缓存的数据。如果缓冲池中没有所需的数据页,从磁盘加载数据页到缓冲池中。
8. 执行器:
对于每个找到的记录,再次判断记录是否满足索引条件 name。这是因为基于索引条件加载到内存中是数据页,数据页中也有可能包含不满足索引条件的记录,所以还要再判断一次 name 条件,满足 name 条件则继续判断 age > 18 过滤条件。
根据 class_no 对满足条件的记录进行分组。
执行器将处理后的结果集返回给客户端。
在整个查询执行过程中,这些组件共同协作以高效地执行查询。客户端负责发送查询,连接器管理客户端连接,查询缓存尝试重用先前查询结果,解析器负责解析查询,优化器选择最佳执行计划,执行器执行优化器选择的计划,存储引擎(如 InnoDB)负责管理数据存储和访问。这些组件的协同作用使得 MySQL 能够高效地执行查询并返回结果集。 根据索引列过滤条件加载索引的数据页到内存这个操作是存储引擎做的。加载到内存中之后,执行器会进行索引列和非索引列的过滤条件判断。
2. SELECT 的各个关键字在哪里执行?
根据执行顺序,如下:
(1)FROM:FROM 子句用于指定查询所涉及的数据表。在查询执行过程中,执行器需要根据优化器选择的执行计划从存储引擎中获取指定表的数据。
(2)ON:ON 子句用于指定连接条件,它通常与 JOIN 子句一起使用。在查询执行过程中,执行器会根据 ON 子句中的条件从存储引擎获取满足条件的记录。如果连接条件涉及到索引列,存储引擎可能会使用索引进行优化。
(3)JOIN:JOIN 子句用于指定表之间的连接方式(如 INNER JOIN, LEFT JOIN 等)。在查询执行过程中,执行器会根据优化器选择的执行计划,从存储引擎中获取需要连接的表的数据。然后,执行器根据 JOIN 子句的类型和 ON 子句中的连接条件,对数据进行连接操作。
(4)WHERE:执行器对从存储引擎返回的数据进行过滤,只保留满足 WHERE 子句条件的记录。部分过滤条件如果涉及到索引,在存储引擎层就已经进行了过滤。
(5)GROUP BY:执行器对满足 WHERE 子句条件的记录按照 GROUP BY 子句中指定的列进行分组。
(6)HAVING:执行器在进行分组后,根据 HAVING 子句条件对分组后的记录进行进一步过滤。
(7)SELECT:执行器根据优化器选择的执行计划来获取查询结果。
(8)DISTINCT:执行器对查询结果进行去重,只返回不重复的记录。
(9)ORDER BY:执行器对查询结果按照 ORDER BY 子句中指定的列进行排序。
(10)LIMIT:执行器根据 LIMIT 子句中指定的限制条件对查询结果进行截断,只返回部分记录
3. 表关联查询 SQL 在 MySQL 架构中的各个组件的执行过程
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM student s JOIN score sc ON s.id = sc.student_id WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;这个例子中,student_id 和 subject 是联合索引,age 是索引。 我们按照时间顺序来分析一下
1. 连接器:当客户端连接到 MySQL 服务器时,连接器负责建立和管理连接。它验证客户端提供的用户名和密码,确定客户端具有相应的权限,然后建立连接。
2. 查询缓存:MySQL 服务器在处理查询之前,会先检查查询缓存。如果查询缓存中已经存在相同的查询及其结果集,服务器将直接返回缓存中的结果,而不再执行后续的查询处理。由于查询缓存在 MySQL 8.0 中已被移除,我们在这个示例中不再详细讨论。
3. 解析器:解析器的主要任务是解析 SQL 查询语句,确保查询语法正确。解析器会将查询语句分解成多个组成部分,例如表、列、条件等。在这个示例中,解析器会识别出涉及的表(student 和 score)以及需要的列(id、name、age、subject、score)。
4. 优化器:优化器的职责是根据解析器提供的信息生成执行计划。它会分析多种可能的执行策略,并选择成本最低的策略。在这个示例中,优化器可能会分析各种表扫描和索引扫描的组合,最终选择一种成本最低的执行计划。
5. 执行器:根据优化器生成的执行计划处理查询,向存储引擎发送请求,获取满足条件的数据行。
6. 存储引擎(如 InnoDB):存储引擎负责管理数据的存储和检索。
存储引擎首先接收来自执行器的请求。请求可能包括获取满足查询条件的数据行,以及使用哪种扫描方法(如全表扫描或索引扫描)。
假设执行器已经决定使用索引扫描。在这个示例中,存储引擎可能会先对 student 表进行索引扫描(使用 age 索引),然后对 score 表进行索引扫描(使用 student_id 和 subject 的联合索引)。
存储引擎会根据请求查询相应的索引结构。在 student 表中,存储引擎会找到满足 age > 18 条件的记录。在 score 表中,存储引擎会找到满足 subject = 'math' AND score > 80 条件的记录。
一旦找到了满足条件的记录,存储引擎需要将这些记录所在的数据页从磁盘加载到内存中。存储引擎首先检查缓冲池(InnoDB Buffer Pool),看这些数据页是否已经存在于内存中。如果已经存在,则无需再次从磁盘加载。如果不存在,存储引擎会将这些数据页从磁盘加载到缓冲池中。
加载到缓冲池中的记录可以被多个查询共享,这有助于提高查询效率。
7. 执行器:处理连接、排序、聚合、过滤等操作。
在内存中执行连接操作,将 student 表和 score 表的数据行连接起来。
对连接后的结果集进行过滤,只保留满足查询条件(age > 18、subject = 'math'、score > 80)的数据行。
将过滤后的数据行作为查询结果返回给客户端。
前面说过,根据存储引擎根据索引条件加载到内存的数据页有多数据,可能有不满足索引条件的数据,如果执行器不再次进行索引条件判断, 则无法判断哪些记录满足索引条件的,虽然在存储引擎判断过了,但是在执行器还是会有索引条件 age > 18、subject = 'math'、score > 80 的判断。
4. LEFT JOIN 将过滤条件放在子查询中再关联和放在 WHERE 子句上有什么区别?
先看例子 查询 1
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM student s LEFT JOIN score sc ON s.id = sc.student_id WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
查询 2
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM (SELECT id, name, age FROM student WHERE age > 18) s LEFT JOIN (SELECT student_id, subject, score FROM score WHERE subject = 'math' AND score > 80) sc ON s.id = sc.student_id
查询 3
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM student s LEFT JOIN score sc ON s.id = sc.student_id AND s.age > 18 AND sc.subject = 'math' AND sc.score > 80;先给出结论:查询 2 和 3 是一样的,也就是过滤条件放在子查询中和放在 on 上面是一样的,后面就只讨论查询 1、2,查询 1 和查询 2 是不一样的,过滤条件放在 where 子句中和放在子查询再关联查询出的结果也是有区别的。 分析一下 从运行结果来看,对于查询 1
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM student s LEFT JOIN score sc ON s.id = sc.student_id WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;在这个查询中,首先执行 LEFT JOIN,将 student 表和 score 表连接起来。连接操作是基于 s.id = sc.student_id 条件进行的。LEFT JOIN 操作会保留左表(student 表)中的所有行,即使它们在右表(score 表)中没有匹配的行。如果右表中没有匹配的行,那么右表的列将显示为 NULL。 然后,WHERE 子句会过滤连接后的结果集,只保留那些满足 s.age > 18 and sc.subject = 'math' and sc.score > 80 条件的行。这意味着,右表为 NULL 的记录将被排除,因为右表的过滤条件 sc.subject = 'math' and sc.score > 80 条件不满足。 对于查询 2:
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM (select id, name, age from student where age > 18) s LEFT JOIN (select subject, score from score where subject = 'math' AND score > 80) sc ON s.id = sc.student_id在这个查询中,我们首先执行两个子查询。第一个子查询从 student 表中选择所有 age > 18 的行,而第二个子查询从 score 表中选择所有 subject = 'math' and score > 80 的行。这意味着,在进行连接操作之前,我们已经对两个表分别进行了过滤。 接下来,执行 LEFT JOIN 操作,将过滤后的 s 和 sc 子查询的结果集连接起来,基于 s.id = sc.student_id 条件。因为 LEFT JOIN 操作会保留左表(s 子查询的结果集)中的所有行,右表为 NULL 的记录包含了。 结果差异: 查询 1 和查询 2 的主要区别在于 WHERE 子句和子查询的使用。
查询 1 在连接操作后应用过滤条件,这可能导致右表为 NULL 的关联记录因为右表的过滤条件而被排除在外。而查询 2 在连接操作之前就已经过滤了表中的数据,这意味着查询结果会包含所有左表过滤条件的记录,以及右表过滤条件的记录和 NULL 的记录。 如果查询 1 想保留右表为 NULL 的记录,只需要改为 WHERE s.age > 18 AND (sc.student_id is null OR (sc.subject = 'math' AND sc.score> 80)); 这样查询 1 和 2 会有相同的结果集。 我们分析一下这两个查询在 MySQL 架构中各个组件中执行的区别 对于查询 1:
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM student s LEFT JOIN score sc ON s.id = sc.student_id WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
连接器:客户端与服务器建立连接。
查询缓存:检查缓存是否存在此查询的结果。如果有,直接返回结果。否则,继续执行。
解析器:解析查询语句,检查语法是否正确。
优化器:对查询进行优化,生成执行计划,决定连接和过滤条件的顺序等。
执行器:开始请求执行查询。
存储引擎(InnoDB):从磁盘或者缓冲池读取满足条件的数据行(s.id = sc.student_id),因为是 left join,所以即便 sc.student_id 为 null 也会被关联。
执行器:将从存储引擎获取的数据行进行左连接,应用过滤条件 s.age > 18 and sc.subject = 'math' and sc.score > 80 进行过滤,将结果集返回给客户端。
当查询包含索引列的条件时,MySQL 的存储引擎会首先利用索引在磁盘上定位到满足索引条件的记录。接着,将这些索引数据对应的数据页加载到内存中的缓冲池。然后,执行器在内存中对这些记录进行进一步的过滤,根据索引条件和非索引列的条件来过滤数据。
当查询涉及到非聚集索引时,需要回表的操作会导致聚集索引和非聚集索引都被加载到内存中。但是,如果查询只涉及到聚集索引(如主键查询),那么只需要加载聚集索引的数据页即可。 对于查询 2
SELECT s.id, s.name, s.age, sc.subject, sc.score FROM (SELECT id, name, age FROM student WHERE age > 18) s LEFT JOIN (SELECT student_id, subject, score FROM score WHERE subject = 'math' AND score > 80) sc ON s.id = sc.student_id
连接器:客户端与服务器建立连接。
查询缓存:检查缓存是否存在此查询的结果。如果有,直接返回结果。否则,继续执行。
解析器:解析查询语句,检查语法是否正确。
优化器:决定使用哪些索引进行查询优化,以及确定连接顺序。
执行器:开始请求执行子查询。
存储引擎(InnoDB):首先,对 student 表进行扫描,将满足条件 s.age > 18 的记录对应的数据页加载到缓冲池 (如果缓冲池没有这个页的数据)。然后,使用 subject = 'math' AND score > 80 对 score 表进行扫描,将满足条件的记录对应的数据页加载到缓冲池 (如果缓冲池没有这个页的数据)。
执行器:对从存储引擎获取的数据应用所有的过滤条件,过滤后的结果存入临时表,执行主查询,从临时表中获取数据,将 s 和 sc 进行左连接,根据 s.id = sc.student_id 组合结果。将连接后的结果返回给客户端。
从这里我们可以看出,查询 2 是先过滤后连接,每张表的索引都很重要,如果没设置好索引,单表过滤会全表扫描。 写 SQL 的时候,查询 1 和查询 2 到底采用哪种方式呢? 根据不同情况各有应用场景,需要注意的是,对于查询 2,子查询的结果集被存储在一个临时表中,临时表不会继承原始索引,包括聚集索引和非聚集索引,所以刚刚的例子中,临时表中 s.id 和 sc.student_id 已经不是任何索引列了。对于查询 1,最终满足关联条件 s.id = sc.student_id 的所有记录都会被加载到内存后再进行过滤。
当单表过滤后的数据量较小时,查询 2 可能是一个更好的选择,因为它可以减少关联操作的数据量,从而提高查询效率。子查询阶段,MySQL 依然会利用原始表上的索引进行过滤。子查询执行完成后,将过滤后的数据存储在临时表中。所以查询 2 的方式可以优化的点就是在单表查询时尽可能的利用索引。
当单表过滤后的数据量较大时,查询 1 可能更合适,因为它可以更好地利用索引进行关联操作。这样可以减少关联操作的时间开销,查询 2 因为临时表不继承索引,表关联的时间开销比较大。
5. 聚集索引和全表扫描有什么区别呢?
走 PRIMARY 索引(聚集索引)和全表扫描有什么区别 呢?准确来说,使用 InnoDB 存储引擎的情况下,全表扫描的数据和聚集索引的数据在 InnoDB 表空间中的存储位置是相同的,也就是说它们的内存地址也是相同的。所以你也可以理解为,他们其实都是在聚集索引上操作的(聚集索引 B + 树的叶子结点是根据主键排好序的完整的用户记录,包含表里的所有字段),区别就在于 全表扫描将聚集索引 B + 树的叶子结点从左到右依次顺序扫描并判断条件。 聚集索引是利用二分思想将聚集索引 B + 树到指定范围区间进行扫描,比如 select * from demo_info where id in (1, 2) 这种条件字段是主键 id,可以很好的利用 PRIMARY 索引进行二分的快速查询。
在 MyISAM 中,全表扫描的数据和索引数据的存储位置是分开的。然而 MyISAM 已经被 InnoDB 取代,不再是 MySQL 的推荐存储引擎,从 MySQL5.5 开始,InnoDB 就成了 MySQL 的默认存储引擎。 默认情况下,InnoDB 使用一个名为 ibdata1 的共享表空间文件存储所有的数据和索引,包括聚集索引和二级索引(又称非聚集索引或辅助索引)。
审核编辑:刘清
-
查询SQL在mysql内部是如何执行?2024-01-22 1477
-
MySQL执行过程:如何进行sql 优化2023-12-12 1281
-
sql where条件的执行顺序2023-11-23 3574
-
mysql和sql server区别2023-11-21 3051
-
一条SQL查询语句是怎么去执行的?(上)2023-03-03 954
-
简述SQL更新语句的执行流程12023-02-14 1299
-
一条SQL语句是怎么被执行的2021-09-12 2273
-
select语句和update语句分别是怎么执行的2020-11-03 4722
-
在Linux系统下执行MySQL的SQL文件程序免费下载2019-11-01 974
-
DRDS分布式SQL引擎—执行计划介绍2018-07-12 3004
全部0条评论

快来发表一下你的评论吧 !
