

Linux 性能优化总结!2
电子说
描述
内存
Linux内存是怎么工作的
内存映射
大多数计算机用的主存都是动态随机访问内存(DRAM),只有内核才可以直接访问物理内存。Linux内核给每个进程提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便的访问内存(虚拟内存)。
虚拟地址空间的内部分为内核空间和用户空间两部分,不同字长的处理器地址空间的范围不同。32位系统内核空间占用1G,用户空间占3G。64位系统内核空间和用户空间都是128T,分别占内存空间的最高和最低处,中间部分为未定义。
并不是所有的虚拟内存都会分配物理内存,只有实际使用的才会。分配后的物理内存通过内存映射管理。为了完成内存映射,内核为每个进程都维护了一个页表,记录虚拟地址和物理地址的映射关系。页表实际存储在CPU的内存管理单元MMU中,处理器可以直接通过硬件找出要访问的内存。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存,更新进程页表,再返回用户空间恢复进程的运行。
MMU以页为单位管理内存,页大小4KB。为了解决页表项过多问题Linux提供了多级页表和HugePage的机制。
虚拟内存空间分布
用户空间内存从低到高是五种不同的内存段:
- 只读段 代码和常量等
- 数据段 全局变量等
- 堆 动态分配的内存,从低地址开始向上增长
- 文件映射 动态库、共享内存等,从高地址开始向下增长
- 栈 包括局部变量和函数调用的上下文等,栈的大小是固定的。一般8MB
内存分配与回收
分配
malloc 对应到系统调用上有两种实现方式:
-
brk() 针对小块内存(<128K),通过移动堆顶位置来分配。
内存释放后不立即归还内存,而是被缓存起来。
-
mmap() 针对大块内存(>128K),直接用内存映射来分配,即在文件映射段找一块空闲内存分配。
前者的缓存可以减少缺页异常的发生,提高内存访问效率。但是由于内存没有归还系统,在内存工作繁忙时,频繁的内存分配/释放会造成内存碎片。
后者在释放时直接归还系统,所以每次mmap都会发生缺页异常。
在内存工作繁忙时,频繁内存分配会导致大量缺页异常,使内核管理负担增加。
上述两种调用并没有真正分配内存,这些内存只有在首次访问时,才通过缺页异常进入内核中,由内核来分配
回收
内存紧张时,系统通过以下方式来回收内存:
- 回收缓存:LRU算法回收最近最少使用的内存页面;
- 回收不常访问内存:把不常用的内存通过交换分区写入磁盘
- 杀死进程:OOM内核保护机制(进程消耗内存越大 oom_score 越大,占用 CPU 越多 oom_score 越小,可以通过 /proc 手动调整 oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj如何查看内存使用情况
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
- VIRT 进程的虚拟内存大小
- RES 常驻内存的大小,即进程实际使用的物理内存大小,不包括swap和共享内存
- SHR 共享内存大小,与其他进程共享的内存,加载的动态链接库以及程序代码段
- %MEM 进程使用物理内存占系统总内存的百分比
怎样理解内存中的Buffer和Cache?
buffer是对磁盘数据的缓存,cache是对文件数据的缓存,它们既会用在读请求也会用在写请求中
如何利用系统缓存优化程序的运行效率
缓存命中率
缓存命中率是指直接通过缓存获取数据的请求次数,占所有请求次数的百分比。命中率越高说明缓存带来的收益越高,应用程序的性能也就越好。
安装bcc包后可以通过cachestat和cachetop来监测缓存的读写命中情况。
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例
#首先安装Goexport GOPATH=~/goexport PATH=~/go/bin:$PATHgo get golang.org/x/sys/unixgo ge github.com/tobert/pcstat/pcstatdd缓存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件echo 3 > /proc/sys/vm/drop_caches #清理缓存pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0cachetop 5dd if=file of=/dev/null bs=1M #测试文件读取速度#此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。dd if=file of=/dev/null bs=1M #重复上述读文件测试#此时文件读取性能为4+GB/s,读缓存命中率为100%pcstat file #查看文件file的缓存情况,100%全部缓存O_DIRECT选项绕过系统缓存
cachetop 5sudo docker run --privileged --name=app -itd feisky/app:io-directsudo docker logs app #确认案例启动成功#实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用。
strace -p $(pgrep app)#strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
内存泄漏,如何定位和处理?
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
- 没正确回收分配的内存,导致了泄漏
- 访问的是已分配内存边界外的地址,导致程序异常退出
内存的分配与回收
虚拟内存分布从低到高分别是只读段,数据段,堆,内存映射段,栈五部分。其中会导致内存泄漏的是:
- 堆:由应用程序自己来分配和管理,除非程序退出这些堆内存不会被系统自动释放。
- 内存映射段:包括动态链接库和共享内存,其中共享内存由程序自动分配和管理
内存泄漏的危害比较大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。内存泄漏不断累积甚至会耗尽系统内存。
如何检测内存泄漏
预先安装systat,docker,bcc
sudo docker run --name=app -itd feisky/app:mem-leaksudo docker logs appvmstat 3可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求
/usr/share/bcc/tools/memleak -a -p $(pidof app)从 memleak 输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是 fibonacci 函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可。
为什么系统的 Swap 变高
系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括:
- 缓存/缓冲区,属于可回收资源,在文件管理中通常叫做文件页
- 在应用程序中通过fsync将脏页同步到磁盘
- 交给系统,内核线程pdflush负责这些脏页的刷新
- 被应用程序修改过暂时没写入磁盘的数据(脏页),要先写入磁盘然后才能内存释放
- 内存映射获取的文件映射页,也可以被释放掉,下次访问时从文件重新读取
对于程序自动分配的堆内存,也就是我们在内存管理中的匿名页,虽然这些内存不能直接释放,但是 Linux 提供了 Swap 机制将不常访问的内存写入到磁盘来释放内存,再次访问时从磁盘读取到内存即可。
Swap原理
Swap本质就是把一块磁盘空间或者一个本地文件当作内存来使用,包括换入和换出两个过程:
- 换出:将进程暂时不用的内存数据存储到磁盘中,并释放这些内存
- 换入:进程再次访问内存时,将它们从磁盘读到内存中
Linux如何衡量内存资源是否紧张?
-
直接内存回收新的大块内存分配请求,但剩余内存不足。
此时系统会回收一部分内存;
-
kswapd0 内核线程定期回收内存。
为了衡量内存使用情况,定义了pages_min,pages_low,pages_high 三个阈值,并根据其来进行内存的回收操作。
-
剩余内存 < pages_min,进程可用内存耗尽了,只有内核才可以分配内存
-
pages_min < 剩余内存 < pages_low,内存压力较大,kswapd0执行内存回收,直到剩余内存 > pages_high
-
pages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求
-
剩余内存 > pages_high,说明剩余内存较多,无内存压力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
-
NUMA 与 SWAP
很多情况下系统剩余内存较多,但 SWAP 依旧升高,这是由于处理器的 NUMA 架构。
在NUMA架构下多个处理器划分到不同的 Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况内存三个阈值可以通过 /proc/zoneinfo 来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。
当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。
- 0表示既可以从其他Node寻找空闲资源,也可以从本地回收内存
- 1,2,4 表示只回收本地内存,2表示可以会回脏数据回收内存,4表示可以用Swap方式回收内存。
swappiness
在实际回收过程中Linux根据 /proc/sys/vm/swapiness 选项来调整使用Swap的积极程度,从 0-100,数值越大越积极使用 Swap,即更倾向于回收匿名页;数值越小越消极使用 Swap,即更倾向于回收文件页。
注意:这只是调整 Swap 积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生 Swap。
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap#先创建并开启swapfallocate -l 8G /mnt/swapfilechmod 600 /mnt/swapfilemkswap /mnt/swapfileswapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令cachetop5 #观察缓存#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候 Swap 用的多,有时候缓冲区波动更多。此时查看 swappiness 值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型。
如何“快准狠”找到系统内存存在的问题
内存性能指标
- 系统内存指标
- 已用内存/剩余内存
- 共享内存 (tmpfs实现)
- 可用内存:包括剩余内存和可回收内存
- 缓存:磁盘读取文件的页缓存,slab分配器中的可回收部分
- 缓冲区:原始磁盘块的临时存储,缓存将要写入磁盘的数据
进程内存指标
- 虚拟内存:5大部分
- 常驻内存:进程实际使用的物理内存,不包括Swap和共享内存
- 共享内存:与其他进程共享的内存,以及动态链接库和程序的代码段
- Swap 内存:通过Swap换出到磁盘的内存
缺页异常
- 可以直接从物理内存中分配,次缺页异常
- 需要磁盘 IO 介入(如 Swap),主缺页异常。此时内存访问会慢很多
内存性能工具
根据不同的性能指标来找合适的工具:
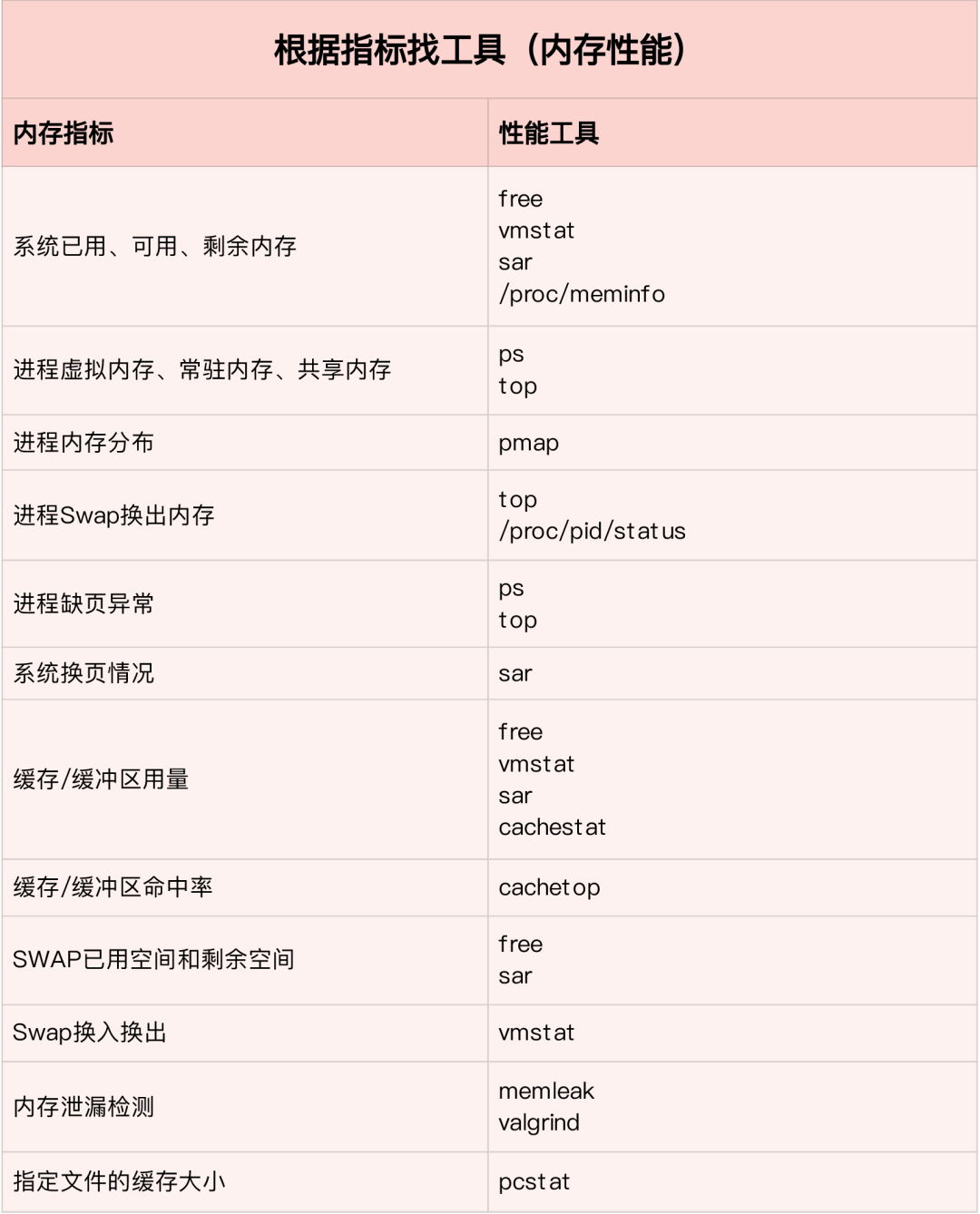
内存分析工具包含的性能指标:
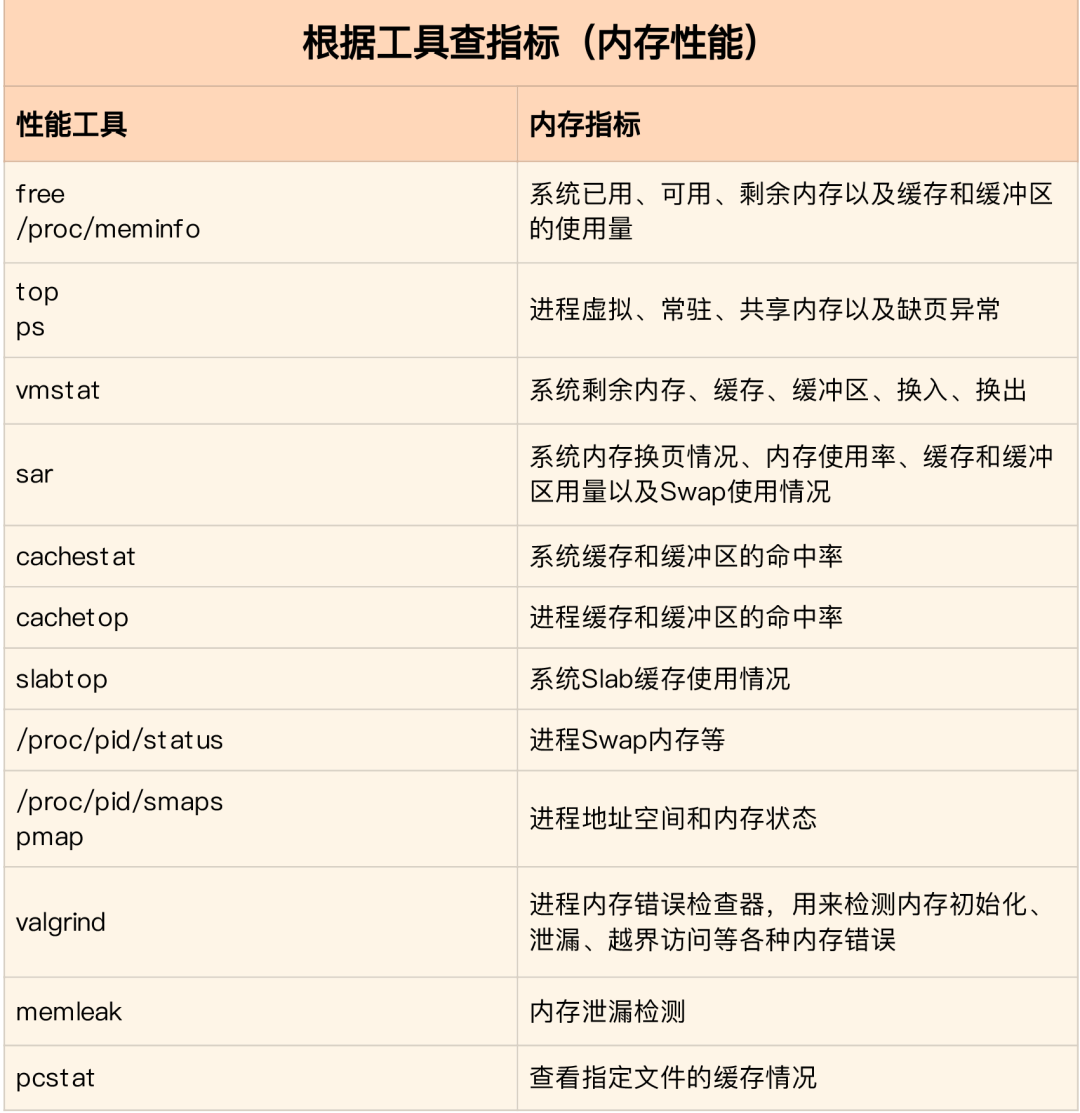
-
Linux应急响应命令总结2022-11-17 1543
-
HBase性能优化方法总结2018-04-20 2028
-
Linux系统的性能优化策略2019-07-16 2106
-
基于Linux的Socket网络编程的性能优化2009-10-22 1311
-
DSP程序优化总结2017-10-23 638
-
linux Android基础知识总结2017-10-24 825
-
linux redis基础命令总结2017-11-25 7046
-
Linux CPU的性能应该如何优化2020-01-18 4344
-
Linux的基础学习笔记资料总结2020-11-13 874
-
Linux下Apache性能分析总结2021-09-24 870
-
Linux 性能优化总结!12023-05-12 1270
-
Linux内核slab性能优化的核心思想2023-11-13 1739
-
性能优化之路总结2024-06-17 926
-
如何优化Linux服务器的性能2024-09-29 1554
-
Linux系统性能优化技巧2025-08-27 1179
全部0条评论

快来发表一下你的评论吧 !
