

目标检测一阶段与二阶段算法简介
描述
目标检测任务
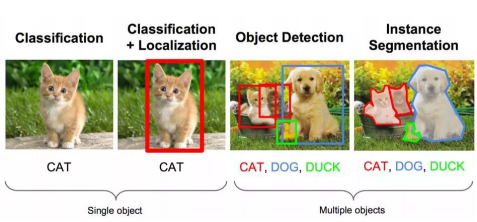
目标检测的任务是找出图像或视频中的感兴趣目标,同时检测出它们的位置和大小,是机器视觉领域的核心问题之一。
目标检测过程中有很多不确定因素,如图像中目标数量不确定,物体有不同的外观、形状、姿态,加之物体成像时会有光照、遮挡等因素的干扰,导致检测算法有一定的难度。
two stage与one stage
进入深度学习时代以来,物体检测发展主要集中在两个方向:two stage 算法如 R-CNN 系列和 one stage 算法如 YOLO、SSD 等。两者的主要区别在于 two stage 算法需要先生成 proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而 one stage 算法会直接在网络中提取特征来预测物体分类和位置。
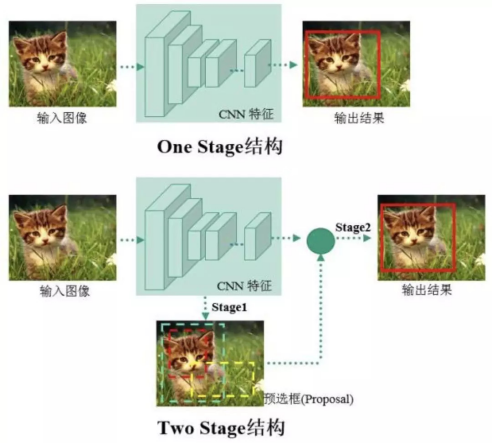
Two-Stage算法(段到段):
使用各种CNN卷积神经网络作为backbone主干网络,进行特征提取,然后进行一步粗分类(区分前景和后景)和粗定位(anchor),也就是说在上图的“产生候选区域CNN特征”之前还应该有一个框“使用RPN网络产生候选区CNN特征”。
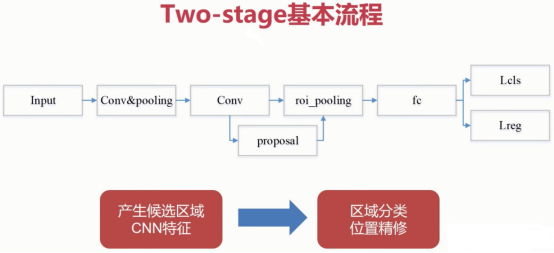
two-stage常见算法:
One-Stage算法(端到端):
one-stage算法使用CNN卷积特征,直接回归物体的类别概率和位置坐标值。
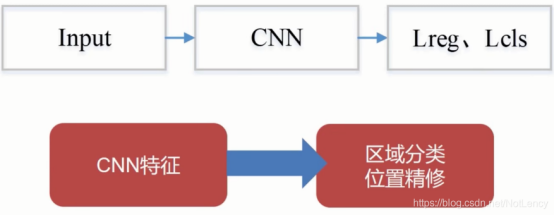
two-stage与one-stage对比:
-
two-stage精度高但速度慢,one-stage速度快但精度稍逊;
-
two-stage目标检测器采用了两段结构采样来处理类别不均衡的问题(意思就是在同一张图片中需要进行检测的目标太少,不需要检测的背景信息太多),一阶段中:rpn使正负样本更加均衡(先粗分类,区分前后景),再粗回归,使用Anchor来拟合bbox,然后再二阶段精调;
-
One stage detector 的一个通病就是既要做定位又要做classification。最后几层1x1 conv layer的loss混在一起,并没有什么专门做detection或者专门做bbox regression的参数,那每个参数的学习难度就大一点;
-
Two stage detector 的第一个stage相当于先拿一个one stage detector来做一次前景后景的classification + detection。这个任务比one stage detector的直接上手N class classification + detection要简单很多。有了前景后景,就可以选择性的挑选样本使得正负样本更加均衡,然后拿着一些参数重点训练classification。训练classification的难度也比直接做混合的classification和regression 简单很多;
-
two-stage其实就是把一个复杂的大问题拆分成更为简单的小问题。各个参数有专攻,Two Stage Detector 在这个方面是有优势的。但one stage detector 里如果用了 focal loss 和 separate detection/classification head 那效果跟 two stage detector 应该是一样的。
优缺点对比:
|
|
one-stage |
two-stage |
|
优势 |
速度快 |
精度高 定位、检出率 |
|
避免背景错误,产生false positives |
Anchor机制 |
|
|
学到物体的 泛化特征 |
共享计算量 |
|
|
劣势 |
精度低 定位、检出率 |
速度慢 |
|
小物体的 检测效果不好 |
训练时间长 |
|
|
|
误报率高 |
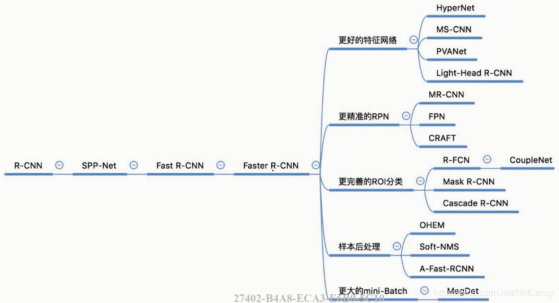
Coovally部分内置目标检测算法介绍
Two-Stage算法示例
Faster R-CNN
Faster R-CNN 取代selective search,直接通过一个Region Proposal Network (RPN)生成待检测区域,这么做,在生成RoI区域的时候,时间也就从2s缩减到了10ms。下图是Faster R-CNN整体结构。
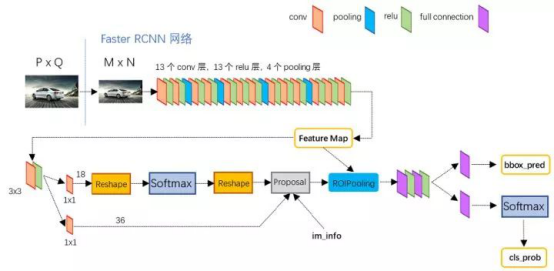
由上图可知,Faster R-CNN由共享卷积层、RPN、RoI pooling以及分类和回归四部分组成:
-
首先使用共享卷积层为全图提取特征feature maps;
-
将得到的feature maps送入RPN,RPN生成待检测框(指定RoI的位置),并对RoI的包围框进行第一次修正;
-
RoI Pooling Layer根据RPN的输出在feature map上面选取每个RoI对应的特征,并将维度置为定值;
-
使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。Faster R-CNN最大特色是使用了RPN取代了SS算法来获取RoI,以下对RPN进行分析。
RPN
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。
而Faster R-CNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。下图为RPN的工作原理:
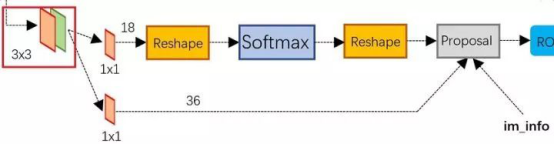
上图展示了RPN网络的具体结构。
可以看到RPN网络实际分为2条支线,上面一条支线通过softmax来分类anchors获得前景foreground和背景background(检测目标是foreground),下面一条支线用于计算anchors的边框偏移量,以获得精确的proposals。
而最后的proposal层则负责综合foreground anchors和偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
anchor:简单地说,RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框(即anchor)。
分类和定位
Faster R-CNN中的RoI Pooling Layer与 Fast R-CNN中原理一样。
在RoI Pooling Layer之后,就是Faster R-CNN的分类器和RoI边框修正训练。分类器主要是分这个提取的RoI具体是什么类别(人,车,马等),一共C+1类(包含一类背景)。
RoI边框修正和RPN中的anchor边框修正原理一样,同样也是SmoothL1 Loss,值得注意的是,RoI边框修正也是对于非背景的RoI进行修正,对于类别标签为背景的RoI,则不进行RoI边框修正的参数训练。
One-Stage算法示例
1. Yolo
针对于two-stage目标检测算法普遍存在的运算速度慢的缺点,Yolo创造性的提出了one-stage,也就是将物体分类和物体定位在一个步骤中完成。
Yolo直接在输出层回归bounding box的位置和bounding box所属类别,从而实现one-stage。
通过这种方式,Yolo可实现45帧每秒的运算速度,完全能满足实时性要求(达到24帧每秒,人眼就认为是连续的)。
整个系统如下图所示:

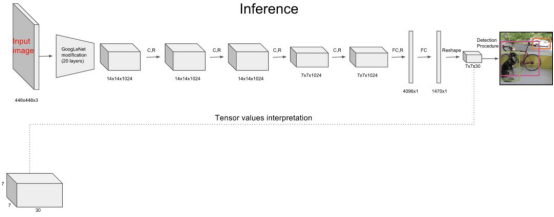
主要分为三个部分:卷积层,目标检测层,NMS筛选层。
卷积层
采用Google inceptionV1网络,对应到上图中的第一个阶段,共20层。
这一层主要是进行特征提取,从而提高模型泛化能力。但作者对inceptionV1进行了改造,他没有使用inception module结构,而是用一个1x1的卷积,并联一个3x3的卷积来替代(可以认为只使用了inception module中的一个分支,应该是为了简化网络结构)。
目标检测层
先经过4个卷积层和2个全连接层,最后生成7x7x30的输出。
先经过4个卷积层的目的是为了提高模型泛化能力。
Yolo将一副448x448的原图分割成了7x7个网格,然后每个单元格负责去检测那些中心点落在该格子内的目标。

NMS筛选层
筛选层是为了在多个结果中(多个bounding box)筛选出最合适的几个,这个方法和faster R-CNN 中基本相同。都是先过滤掉score低于阈值的box,对剩下的box进行NMS非极大值抑制,去除掉重叠度比较高的box(NMS具体算法可以回顾上面faster R-CNN小节)。
这样就得到了最终的最合适的几个box和他们的类别。
Yolo损失函数
yolo的损失函数包含三部分,位置误差,confidence误差,分类误差。具体公式如下:
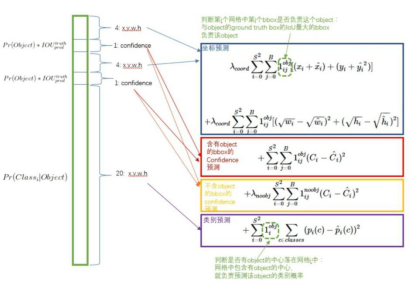
误差均采用了均方差算法,Yolo算法开创了one-stage检测的先河,它将物体分类和物体检测网络合二为一,都在全连接层完成。故它大大降低了目标检测的耗时,提高了实时性。
但它的缺点也十分明显:
-
每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果很差;
-
原始图片只划分为7x7的网格,当两个物体靠的很近时,效果很差;
-
最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到);
-
对于图片中比较小的物体,效果很差。
2. SSD
Faster R-CNN准确率mAP较高,漏检率recall较低,但速度较慢。而Yolo则相反,速度快,但准确率和漏检率不尽人意。
SSD综合了他们的优缺点,对输入300x300的图像,在voc2007数据集上test,能够达到58 帧每秒( Titan X 的 GPU ),72.1%的mAP。
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,SSD网络结构如下图:
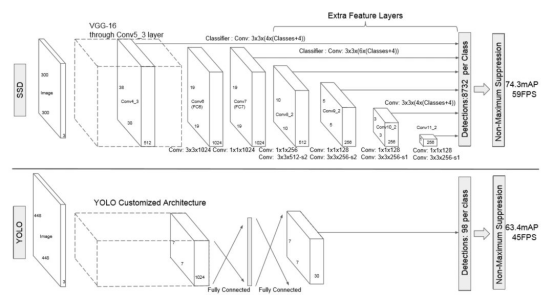
和Yolo一样,也分为三部分:卷积层,目标检测层和NMS筛选层。
卷积层
SSD论文采用了VGG16的基础网络,其实这也是几乎所有目标检测神经网络的惯用方法。先用一个CNN网络来提取特征,然后再进行后续的目标定位和目标分类识别。
目标检测层
这一层由5个卷积层和一个平均池化层组成。去掉了最后的全连接层。SSD认为目标检测中的物体,只与周围信息相关,它的感受野不是全局的,故没必要也不应该做全连接。SSD的特点如下:
-
多尺寸feature map上进行目标检测。每一个卷积层,都会输出不同大小感受野的feature map。在这些不同尺度的feature map上,进行目标位置和类别的训练和预测,从而达到多尺度检测的目的,可以克服yolo对于宽高比不常见的物体,识别准确率较低的问题。而yolo中,只在最后一个卷积层上做目标位置和类别的训练和预测。这是SSD相对于yolo能提高准确率的一个关键所在。
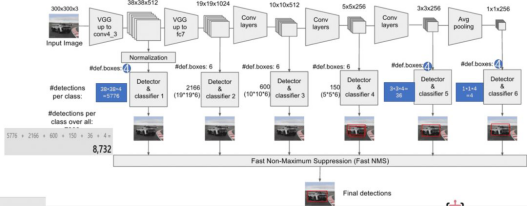
如上所示,在每个卷积层上都会进行目标检测和分类,最后由NMS进行筛选,输出最终的结果。多尺度feature map上做目标检测,就相当于多了很多宽高比例的bounding box,可以大大提高泛化能力。
-
设置先验框。在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD和Faster R-CNN相似,也提出了anchor的概念。卷积输出的feature map,每个点对应为原图的一个区域的中心点。以这个点为中心,构造出6个宽高比例不同,大小不同的anchor(SSD中称为default box)。每个anchor对应4个位置参数(x,y,w,h)和21个类别概率(voc训练集为20分类问题,在加上anchor是否为背景,共21分类)。
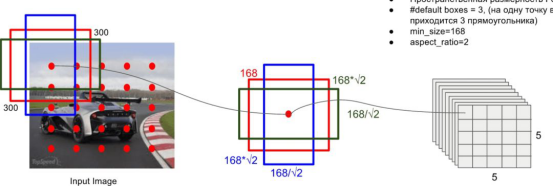
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 个类别,SSD其实需要预测 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值 ,分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset,但是觉得transformation更合适,参见R-CNN。
另外,SSD采用了数据增强。生成与目标物体真实box间IOU为0.1 0.3 0.5 0.7 0.9的patch,随机选取这些patch参与训练,并对他们进行随机水平翻转等操作。SSD认为这个策略提高了8.8%的准确率。
筛选层
和yolo的筛选层基本一致,同样先过滤掉类别概率低于阈值的default box,再采用NMS非极大值抑制,筛掉重叠度较高的。只不过SSD综合了各个不同feature map上的目标检测输出的default box。
审核编辑 :李倩
-
一款二阶段恒流限压式铅酸电池充电器原理2023-11-13 640
-
丰厚奖金 | 首届OpenHarmony开源开发者成长计划(第二阶段申请截止)2021-11-15 9885
-
LT3742:二元,二阶段Stephn交换控制器数据Sheet2021-05-11 818
-
苹果公司的AR眼镜将进入研发第二阶段2021-01-06 2593
-
机器学习的第二阶段:推理2020-06-28 6720
-
特斯拉柏林超级工厂第一阶段目标公布2020-02-20 2569
-
为什么uboot在第一阶段就已经进行时钟初始化了2019-09-23 1370
-
含风电场的机组组合二阶段随机规划模型2018-03-28 913
-
基于RobustICA的二阶段盲源分离算法2018-01-04 1025
-
英特尔携手爱立信完成第二阶段的5G技术研发试验2017-09-29 1503
-
FF否认CES发布会耗资巨大 称工厂将进入第二阶段2017-01-19 1047
-
4G标准:TD-LTE规模试验进入第二阶段2012-02-03 748
-
TD-SCDMA规模测试第一阶段被曝结果良好2009-06-24 693
-
典型二阶段低通滤波器电路图2009-05-08 2140
全部0条评论

快来发表一下你的评论吧 !
