

上海AI lab提出VideoChat:可以与视频对话啦
描述
视频相比语言、图像,是更复杂更高级的一类表征世界的模态,而视频理解也同样是相比自然语言处理与计算机视觉的常见工作更复杂的一类工作。在当下大模型的洪流中,自然而然的想法就是大规模语言模型(LLMs)可以基于语言训练的强大理解推理能力,完成视频理解的工作吗?现在答案到来了,上海 AI Lab 提出了以 Chat 为中心的端到端的视频理解系统 VideoChat,集成了视频基础模型与 LLMs,并且在如空间、时间推理,事件定位、因果推断等多个方面都表现十分出色。

区别于现有多模态大模型针对视频输入的处理方法,即首先文本化视频内容再接入大模型利用大模型自然语言理解的优势,这篇论文从模型角度以可学习的方式集成了视频和语言的基础模型,通过构建视频基础模型与 LLMs 的接口,通过对接口进行训练与学习从而完成视频与语言的对齐。这样一种方式可以有效的避免视觉信息、时空复杂性信息丢失的问题,第一次创立了一个高效、可学习的视频理解系统,可以实现与 VideoChat 对视频内容的有效交流。
论文题目:
VideoChat : Chat-Centric Video Understanding
论文链接:
https://arxiv.org/pdf/2305.06355.pdf
代码地址:
https://github.com/OpenGVLab/Ask-Anything
如果要问大模型有什么样的能力,那我们可能洋洋洒洒从理解推理到计算判断都可以列举许多,但是如果要问在不同场景下如何理解大模型的不同作用,那有可能就是一个颇为玄妙的“艺术”问题。在 VideoChat 中,论文作者将大模型理解为一个视频任务的解码器,即将视频有关的描述或更进一步的嵌入理解为人类可理解的文本。这一过程可以被形式化的理解为:
这里 与 表示一个图片或视频的模型,通过将 I(图像) 与 V(视频)输入到模型中,得到视频或图像的嵌入表示 E,而一个解码的过程,就是:
其中 与 分别表示在第 t 轮中 LLM 的回答和在 t 轮前用户提出的所有问题及答案, 即一个 LLM 模型。传统上针对多模态大模型的解决方法,一般是一种将视频信息文本化的方法,通过将视频序列化为文本,构成 Video Description,再输入到大模型之中,这种文本流可以很好的适应理解类的工作,但是却对如时间、空间感知这类任务表现不佳,因为几乎是必然的,将视频信息文本化后很容易使得这类基础信息出现丢失。而因此论文试图完成一个端到端的一体化的方法,直接提取视频的嵌入信息,如下图对比所示:
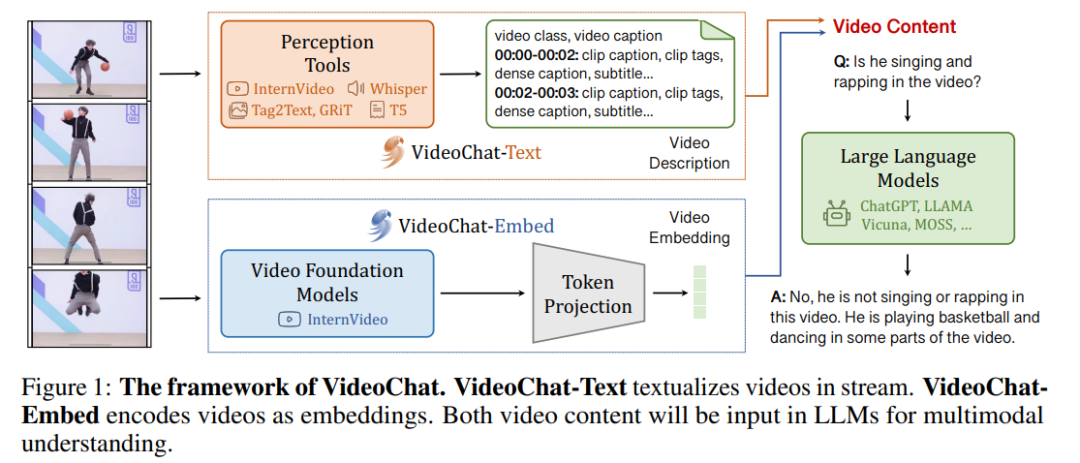
通过整合这样两种视频架构,即整合 VideoChat-Text 与 VideoChat-Embed 得到的 Video Context 输入到大模型之中,以获得更全面的视频信息理解能力,如在上图的任务中,用户提问“他是在唱、跳和 Rap 吗”,VideoChat 回复“不是,他是在打篮球(和跳舞)”
对于 VideoChat-Text 部分,论文作者详细的解构了一个视频包含的内容,比如动作、语音、对象及带有位置注释的对象等等,基于这些分析,VideoChat-Text 模块综合利用各种视频与图像模型获得这些内容的表征,再使用 T5 整合模型输出,得到文本化的视频之中,使用如下图所示的模板完成对 LLMs 的输入:

而对于 VideoChat-Embed 则采用如下架构将视频和大模型与可学习的 Video-Language Token Interface(VLTF)相结合,基于 BLIP-2 和 StableVicuna 来构建 VideoChat-Embed,具体而言,首先通过 GMHRA 输入视频,同时引入图像数据进行联合训练并接入一个经过预训练的 Q-Former,完成视频的 Embedding。
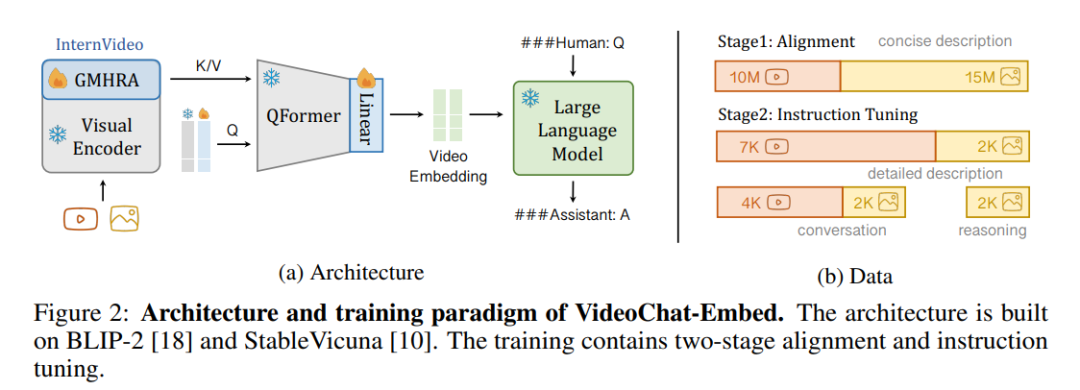
整个训练过程可以分为两个阶段,分别是对齐与微调。在对齐阶段,作者引入了 25M 个视觉-文本对针对接口进行微调,整体的输入提示如下:

而在微调阶段,论文自行构建并开源了包含 7k 个详细的视频描述与图像描述以及 4k 个视频对话,3k 个图像描述,2k 个图像对话,2k 个图像推理的指令数据集对 VideoChat 完成微调。

对比 LLaVa、miniGPT-4 以及 mPLUG-owl,论文对 VideoChat 的多方面能力进行了定性研究。其中,在空间感知与分析中,VideoChat 可以识别日式服装来推断出相应的音乐,并且确定视频中的人数。这即是证明了 VideoChat 识别捕获视觉元素并给予视觉元素进行分析的能力。

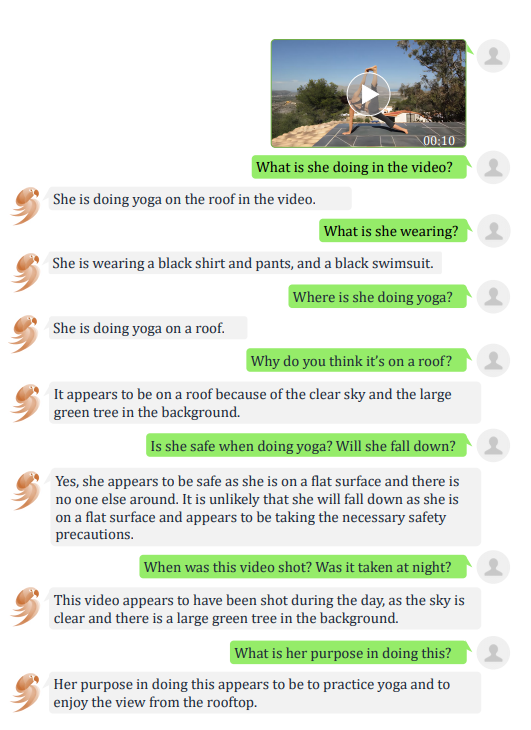
在时间感知与分析中,VideoChat 可以识别出视频中做瑜伽的动作,甚至给出了它摔倒可能性的判断并进行提醒了安全问题。
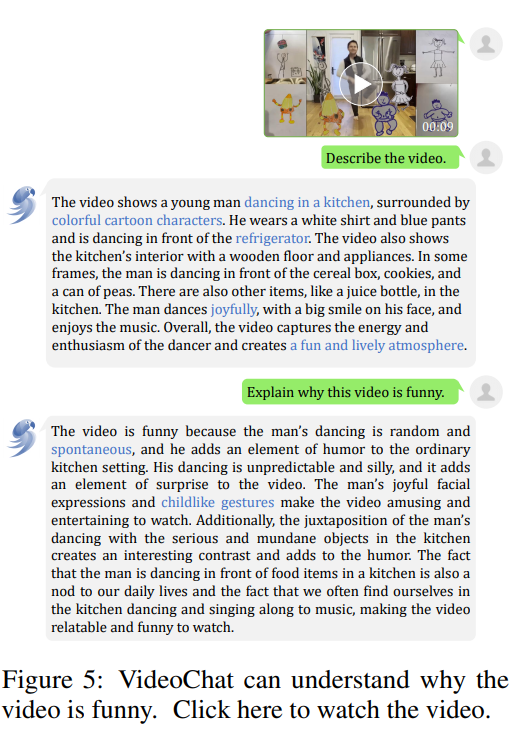
在非正式推断中,VideoChat 也可以解释“为什么这个视频是好笑的”这一问题,并且解释的也符合我们对视频好笑的一些抽象判断,如不协调,突然性等等。
而对比最近的基于图像的多模态对话系统,VideoChat 可以正确的识别场景,而其他系统则错误的将对话环境视为室内,这充分的体现了 Video-Chat 在空间感知方面非常强大的比较优势。
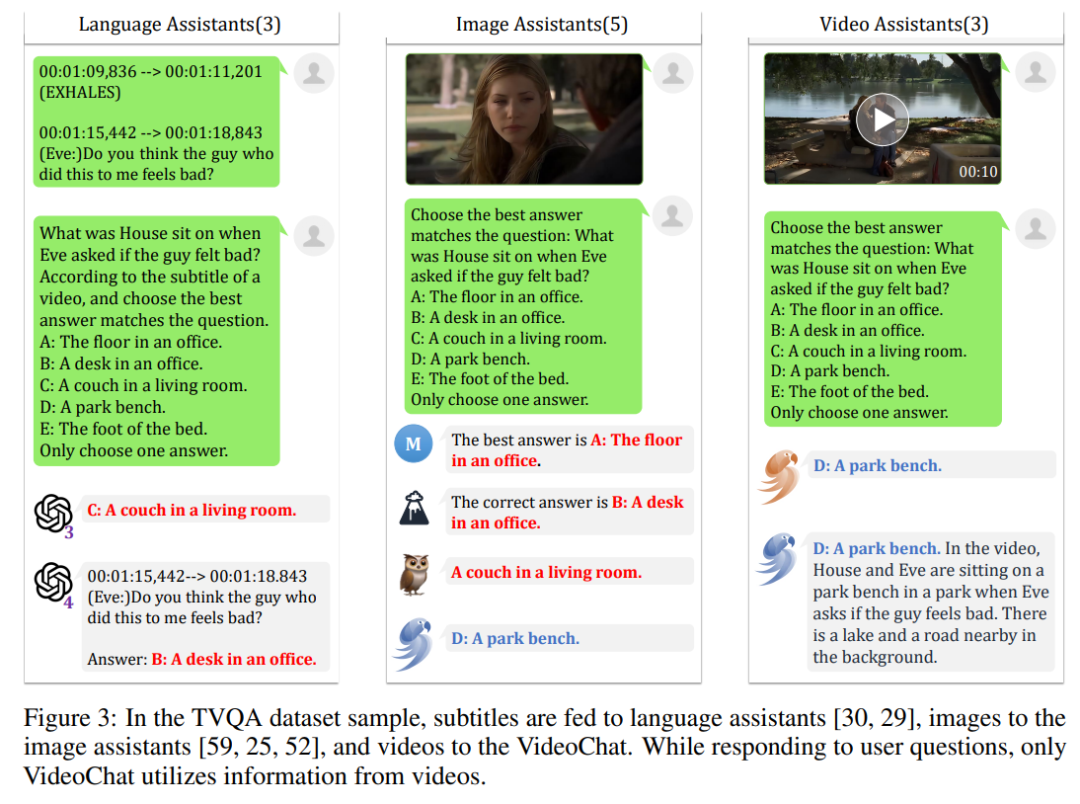
这样一个开源的视频理解框架可以为视频理解这样一个目前还没有什么非常成熟的解决方案的问题铺好道路,显然,将视频信息与文本信息对齐,大规模语音模型的优秀能力是可以允许他们理解视频信息。而如果将大模型看作一个有推理、理解能力的黑盒,视频理解的问题就变成了如何对视频进行解码以及与文本对齐的问题,这可以说是大模型为这一领域带来的“提问方式”的改变。
但是针对我们期望的成熟的视频理解器,这篇工作仍然具有局限性,比如 VideoChat 还是难以处理 1 分钟以上的长视频,当然这主要是来自于大模型上下文长度的限制,但是在有限的上下文长度中如何更好的压缩视频信息也成为一个复杂的问题,当视频时长变长后,系统的响应时间也会对用户体验带来负面影响。另外总的来说,这篇论文使用的数据集仍然不算大,因此使得 VideoChat 的推理能力仍然停留在简单推理的层级上,还无法完成复杂一点的推理工作,总之,尽管 VideoChat 还不是一个尽善尽美的解决方案,但是已然可以为当下视频理解系统增添重要一笔,让我们期待基于它的更加成熟的工作吧!
审核编辑 :李倩
-
HarmonyOS NEXT 应用开发练习:AI智能对话框2025-01-03 290
-
《AI Agent 应用与项目实战》----- 学习如何开发视频应用2025-03-05 2120
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战2025-09-12 3966
-
基于Lab空间的图像检索算法2009-04-18 1076
-
可以给黑白视频上色的谷歌AI技术2018-07-03 4762
-
自然语言对话领域的现状与未来展望2018-07-28 4618
-
MIT提出一种可以保护基于云的AI系统2018-08-24 1130
-
OPEN AI LAB联合Arm中国、瑞芯微发布EAIDK2018-09-14 6259
-
微信推出专属对话AI机器人2019-09-10 6182
-
Adobe认为AI可以解决照片和视频的模糊问题2020-10-29 3679
-
NVIDIA推出的Maxine平台集成了先进的视频和对话式AI等功能2021-08-13 2460
-
NVIDIA GPU助力加速先进对话式AI技术2022-05-06 2651
-
上海新前端奕天科技的视频AI交通事件检测算法获得华为技术认证2022-07-21 3241
-
NVIDIA技术助力Pantheon Lab数字人实时交互解决方案2025-01-14 1370
-
单次、多次对话与RTC对话AI交互模式,如何各显神通?2025-04-02 2731
全部0条评论

快来发表一下你的评论吧 !
