

SEDNet:视差和不确定性联合评估的新方法
描述
本文提出了一种新的深度立体匹配中用于联合视差和不确定性估计的损失函数。在神经网络中加入KL散度项,要求不确定性分布匹配视差误差分布,以实现精确的不确定性估计。使用可微的软直方图技术来近似分布,并在损失函数中使用。该方法在大型数据集上获得了显着的改进。作为cvpr2023最新的文章,非常值得阅读一下。
1 前言
本文提出了SEDNet,一种用于视差和基础不确定性联合估计的深度网络。SEDNet包括一个新颖的、轻量级的不确定性估计子网络,将不确定度的分布与视差误差的分布相匹配。为了生成这个新的损失函数的输入,作者使用可微的软直方图技术以可微分的方式近似分布。在具有真实值的大型数据集上对SEDNet的视差估计和不确定度预测的性能进行了广泛的实验验证。SEDNet优于具有相似架构但没有提出的损失函数的基线。
主要贡献是:
一个新颖的不确定性估计子网络,从视差子网络生成的中间多分辨率视差图中提取信息。
一种可微的软直方图技术,用于近似视差误差和估计不确定性的分布。
一种基于KL散度的损失,应用于使用上述技术获得的直方图。

2 相关背景
立体匹配网络在一种称为成本体积(cost volume)的体积上运行,该体积在每个像素处汇聚每个可能视差处的二维特征,并可以通过相关或串联来构建。DispNetC、iResNet和SegStereo等基于相关的网络生成两个视图中提取的特征的单通道相关地图,在各视差层中,利用有效的计算流程牺牲结构和语义信息在特征表示中。GCNet、PSMNet和GANet等基于串联的网络在成本体积的对应元素所指定的视差处组装两个视图的特征。这有助于学习上下文特征,但需要更多的参数以及一个后续的聚合网络。在置信度估计方面,将置信度和不确定度区分开来,包括置信度CNN、PBCP、EFN、LFN和MMC等方法,以及ConfNet、LGC和LAF等利用图像和视差图作为输入的方法。KL散度用于测量变分推断估计的网络参数分布的近似和精确后验分布之间的距离。(需要注意的是,在分配离散度误差的分布上,作者使用了KL散度来实现完全不同的目的。)
3 方法
本文旨在联合估计视差和不确定性,通过最小化预测不确定性和实际视差误差之间的差异来训练网络。其中,预测模型的损失函数为KL散度损失,用于匹配误差分布和不确定性分布。立体匹配网络通过学习联合公式预测比单独的视差估计器更准确的视差。
3.1 Aleatoric Uncertainty Estimation - 随机不确定性估计
为了预测不确定性并降低噪声的影响,Kendall和Gal通过最小化模型输出的负对数似然来实现像素级的预测。模型假设输出服从高斯分布。Ilg等人的后续工作表明,预测的分布可以分别模拟为拉普拉斯分布或高斯分布,具体取决于是对视差估计采用L1损失还是L2损失。由于作者采用的是前者,因此可以将预测模型表示为:
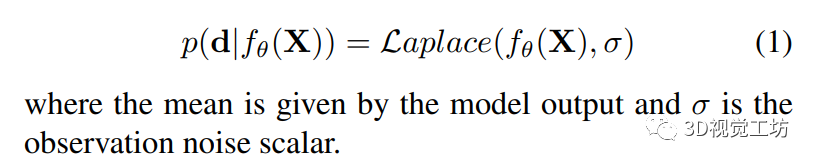
为了模拟算法不确定性,Kendall和Gal引入了像素特定的噪声参数σ(i)。作者采用了Ilg等人在构建拉普拉斯模型时使用的方法,并获得了以下像素级损失函数:
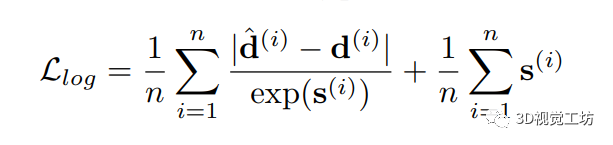
该式可以被视为鲁棒损失函数,其中像素的残差损失受其不确定性的影响而减弱,而第二项则作为正则化项。训练网络来预测观测噪声标量的对数s,以保证数值稳定性。
3.2 Matching the Distribution of Errors - 误差分布的匹配
这部分作者讨论了调整不确定性分布以匹配误差分布的问题。采用KL散度作为衡量二者之间差异的度量,但直接最小化KL散度需要两个分布的归纳公式。为此作者使用直方图来表示分布,同时采用软直方图使其可微分。对于每个批次训练,基于误差值的统计量创建一个直方图。作者对独立的不确定性采用相同的直方图参数,并使用反比例权重的softmax函数来计算每个误差值或不确定性贡献的直方图值。最后,该直方图的KL损失用于网络的训练。
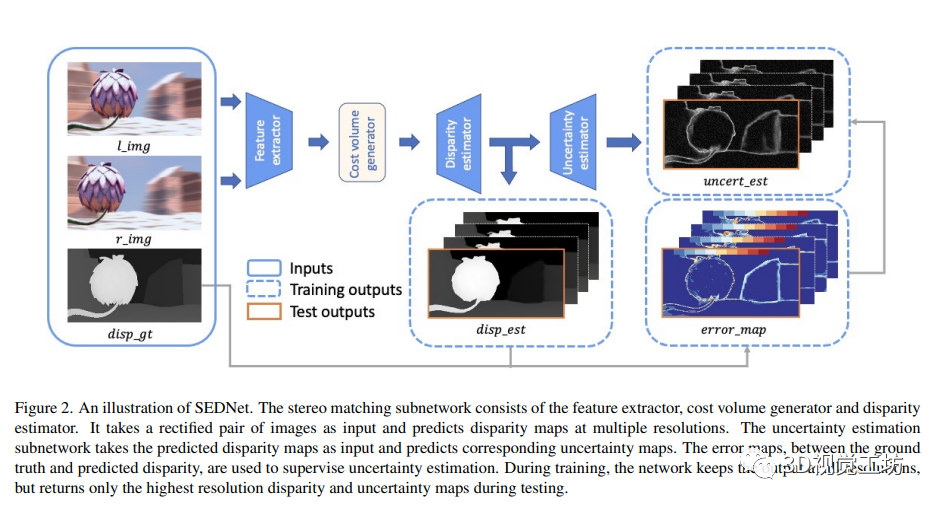
3.3 SEDNet
SEDNet是一个包括视差估计和不确定性估计子网络的网络体系结构。其中视差估计子网络采用GwcNet,GwcNet子网络使用类似ResNet的特征提取器从图像中提取特征,生成代价体积,并使用soft-argmax运算符为像素分配视差。视差预测器的输出模块在不同分辨率下生成K个视差图。不确定性估计子网络学习预测每个像素的观测噪声标量的对数误差。为了计算不确定性图像,作者提出了使用像素对差分向量(PDV)的多分辨率视差预测的新方法。视差估计器输出的视差图首先进行上采样处理,然后进行成对差分以形成PVD。其中,PVD表示像素对之间的视差差异。
3.4 Loss Function - 损失函数
本文所使用的损失函数由两部分组成:对数似然损失和KL散度损失。其中对数似然损失用于优化误差和不确定性,KL散度损失用于匹配不确定性分布和误差。总损失将所有视差和不确定性图像考虑在内,上采样到最高分辨率,并通过每个分辨率级别的系数对不同分辨率级别的对数似然损失和KL散度损失进行加权计算。

4 实验
4.1 数据集和评估指标
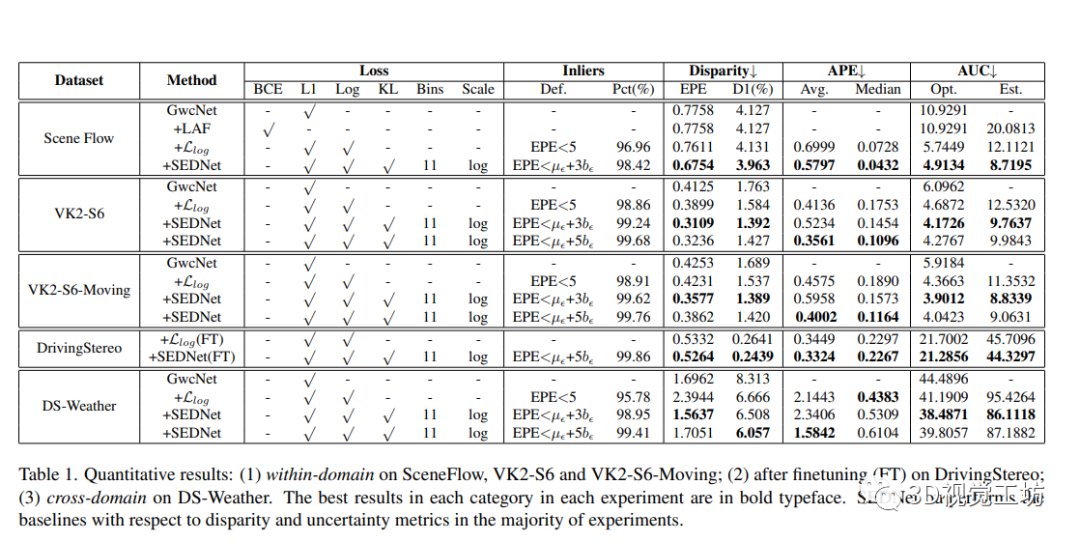
这部分作者介绍了多个用于立体图像深度估计的数据集和评估指标。其中SceneFlow、Virtual KITTI 2和DrivingStereo是当前被广泛使用的三个数据集。作者使用端点误差(EPE)和异常值百分数(D1)来评估视差估计的准确度,并使用密度-EPE ROC曲线和曲线下的面积(AUC)来评估不确定性估计。本文还比较了SEDNet和三个基线:原始GwcNet、LAF-Net和仅使用对数似然损失的SEDNet。
4.2 实施细节
作者在PyTorch中实现了所有网络,并对所有实验使用了Adam优化器,其中β1 = 0.9,β2 = 0.999。在所有模型过拟合之前停止训练。
在VK2数据集上的实验是在两个NVIDIA RTX A6000 GPU上执行的,每个GPU都带有48GB的RAM。对于此数据集,使用初始学习率为0.0001从头训练了所有模型,在每10个epoch后降低了5个。在训练过程中,从图像中随机裁剪了512×256的补丁。在测试期间,在VK2的完整分辨率上评估。
欢迎关注微信公众号「3D视觉工坊」,加群/文章投稿/课程主讲,请加微信:dddvisiona,添加时请备注:加群/投稿/主讲申请
方向主要包括:3D视觉领域各细分方向,比如相机标定|三维点云|三维重建|视觉/激光SLAM|感知|控制规划|模型部署|3D目标检测|TOF|多传感器融合|AR|VR|编程基础等。
对于DrivingStereo数据集(DS),坐这儿也在两个NVIDIA RTX A6000 GPU上进行了实验。对于此数据集,使用在VK2上预训练的模型进行了两个实验:(1)在DS训练集上进行微调,学习率从0.0001开始,在第10个epoch后每3个epoch降低2次学习率,然后在DS测试集上进行领域内评估;(2)跳过微调步骤,并在DS-Weather子集上进行跨域评估。在训练期间,作者随机裁剪了与VK2实验相同大小的输入。在测试期间,作者对测试样本进行了填充,使其分辨率与VK2相同。
在SceneFlow数据集上的实验是在一台具有24 GB内存的Nvidia TITAN RTX GPU上进行的。作者从半分辨率图像中裁剪了256×128的补丁来限制内存消耗,并将初始学习率设置为0.001,在第10个epoch后每2个epoch降低2次学习率。
4.3 定性和定量结果
作者进行了视差估计和不确定性估计的定量和定性分析,并展示了针对不同实验设置的SEDNet的性能优于基线结果。使用自适应阈值的内点过滤器使模型在视差和不确定性估计方面表现更好。SEDNet还具有在极端天气下预测视差的能力,不受糟糕照明和模糊影响。此外,作者还发现使用自适应阈值进行内点过滤可以提高网络的性能。
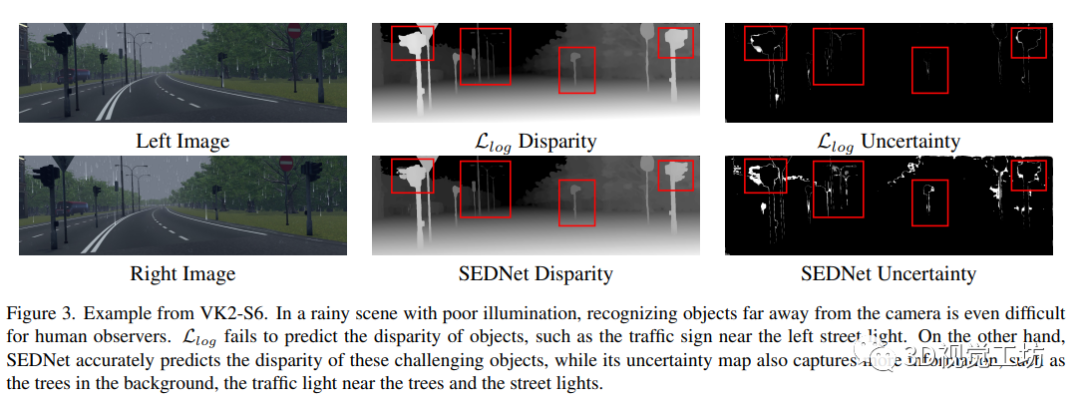

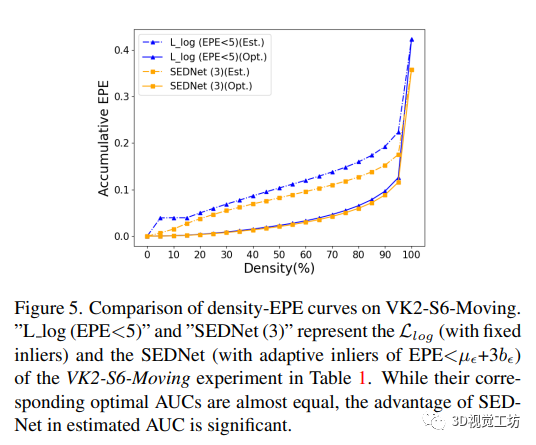
4.4 匹配误差分布
作者提出的能够更好匹配真实分布的视差估计和不确定性估计方法SEDNet,表明其在精度和鲁棒性方面具有优势。在误差分布匹配方面,通过比较APE的结果,验证了SEDNet的匹配能力。
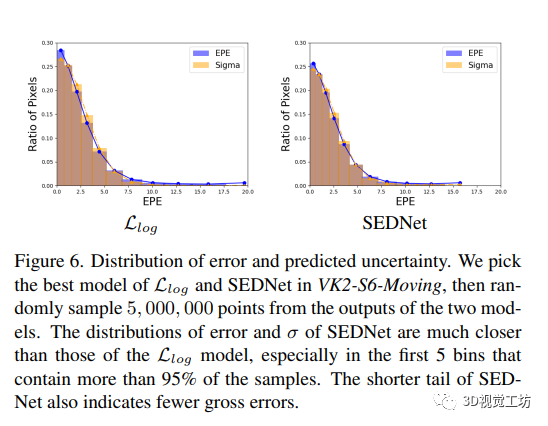
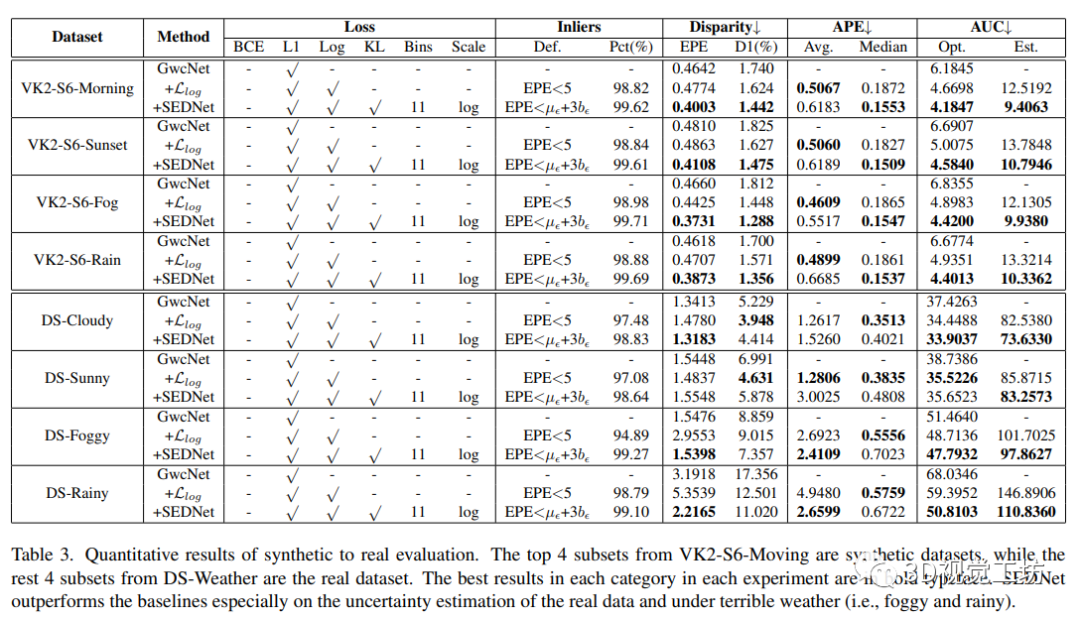
4.5 从合成数据到真实数据的泛化
视差匹配网络通常在合成数据上进行训练,并在目标域的少量真实数据上进行微调,因为获取带有真实深度信息的真实数据成本高且难度大。在本节中,作者将VK2-S6和DS-Weather的实验扩展到所有仅在合成数据上进行训练的方法在看不见的真实域上的泛化性能进行比较。
5 总结
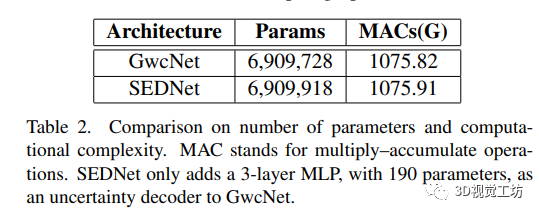
本文提出了一种新的视差和不确定性联合评估的方法,其中关键思想是使用基于KLD散度的独特损失函数来比较视差误差和不确定性估计的分布情况,通过一种可微的直方图方案实现,同时引入了仅有190个参数的不确定性估计子网络。实验表明,该方法在视差和不确定性预测方面都取得了比较有效的结果。和GwcNet相比,即使基本上具有相同的容量和几乎相同的架构,SEDNet在视差估计方面表现更好,这归因于微小的不确定性估计子网络。未来研究计划将该方法同样应用于其他逐像素回归任务。
该篇论文介绍了一种视差和不确定性联合评估的方法SEDNet,提出了一种可微的直方图方案来实现KL散度损失函数,通过匹配视差误差和不确定性分布来实现精确的不确定性估计。实验表明,该方法在视差和不确定性预测方面都取得了有效的结果,并且在视差估计方面表现更好,相比于GwcNet,这归因于微小的不确定性估计子网络。该文章的主要贡献是引入了一种新颖的不确定性估计子网络和使用KL散度的损失函数来对比视差误差和不确定性估计的分布情况。SEDNet的实现对于视觉和深度学习领域的研究也有一定的参考意义。

审核编辑 :李倩
-
科技云报到:数字化转型,从不确定性到确定性的关键路径2024-11-16 1403
-
将不确定性感知和姿态回归结合用于自动驾驶车辆定位2023-01-30 2336
-
深部目标姿态估计的不确定性量化研究2022-04-26 1986
-
运算放大器的开环电压增益有哪些不确定性?2021-07-19 2617
-
基于RFID技术的供应链管理项目存在哪些不确定性?2021-05-28 1963
-
针对自闭症辅助的不确定性联合组稀疏建模方法2021-04-07 1070
-
傅里叶变换与不确定性看了就知道2020-12-30 2555
-
测试系统不确定性分析2019-09-18 1430
-
435B-K05输出不确定性2019-08-02 1441
-
N5531S TRFL不确定性2019-02-19 1881
-
是否可以使用全双端口校准中的S11不确定性来覆盖单端口校准的不确定性?2018-12-29 2957
-
去嵌入和不确定性是否使用了正确的设置2018-09-27 3066
-
如何用不确定性解决模型问题2018-09-07 6126
-
考虑模型参数不确定性的航天器姿态机动控制2017-01-07 966
全部0条评论

快来发表一下你的评论吧 !
