

人工智能中的训练与推理
描述
在想要训练一个能区分苹果和香蕉的模型,你需要搜索一些苹果和香蕉的图片,将这些图片放在一起构成训练数据集(Training Dataset),训练数据集是有标签的,苹果图片的标签是苹果,香蕉图片的标签是香蕉。
通过对初始的神经网络参数不断地优化来让模型变得更准确。可能开始对于20张苹果的照片,只有10张被判断为苹果,对另外10张没有做出正确判断,这时可以通过优化参数让神经网络对20张图片都做出正确判断,这个过程就是训练过程。训练后的模型能对训练数据集中所有苹果图片准确地加以识别,但是我们的期望是它可以对以前没看过的图片进行正确识别。
重新拍一张苹果的图片让神经网络判断时,这种图片叫作现场数据(Live Data),如果神经网络对现场数据识别的准确率非常高,就证明你的网络训练是非常成功的。我们把用训练好的模型识别新图片的过程称为推理。图中给出了深度学习中训练和推理的关系。
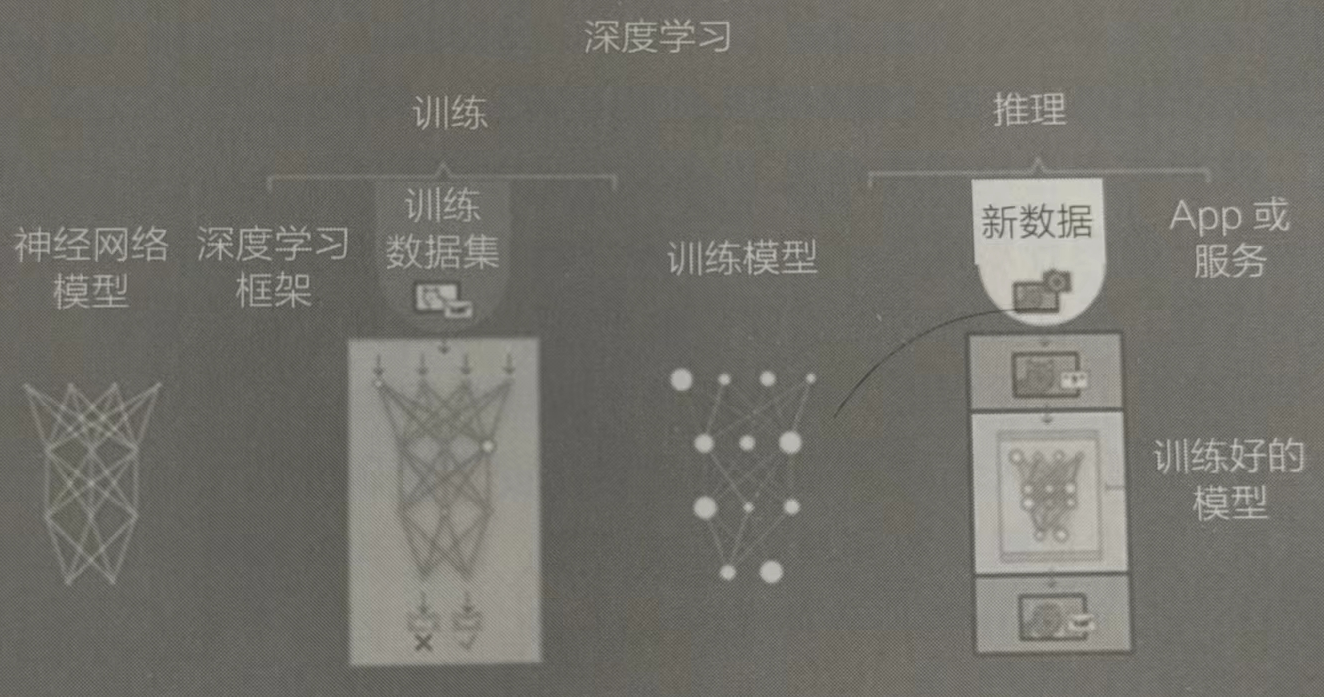 推理是模型的应用过程
推理是模型的应用过程训练是利用已有数据进行学习的过程,对计算的精度要求较高,会直接影响推理的准确度。而推理是在新的输入数据下,应用训练形成的模型完成特定的任务,如图像识别、自然语言处理等,通常数据量会比训练小很多,可以放到移动终端设备上进行。
这又涉及一个概念-—部署(Deployment)。把一个训练好的模型应用起来,使它能够在移动终端上运行推理,这个过程就称为部署。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA在人工智能中的应用有哪些?2024-07-29 8316
-
人工智能是什么?2015-09-16 6490
-
人工智能就业前景2018-03-29 8466
-
解读人工智能的未来2018-11-14 4993
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5944
-
人工智能上路需要知道什么常识2019-05-13 4180
-
人工智能:超越炒作2019-05-29 5079
-
人工智能芯片是人工智能发展的2021-07-27 6759
-
人工智能基本概念机器学习算法2021-09-06 2814
-
物联网人工智能是什么?2021-09-09 5371
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2251
-
《移动终端人工智能技术与应用开发》+理论学习2023-02-27 24498
-
《通用人工智能:初心与未来》-试读报告2023-09-18 1305
-
人工智能中训练和推理的区别是什么,需要关注哪些要点2022-12-16 32835
-
人工智能训练师是什么2023-08-13 3820
全部0条评论

快来发表一下你的评论吧 !
