

YOLOv8版本升级支持小目标检测与高分辨率图像输入
描述
YOLOv8对象检测模型结构
YOLOv8版本最近版本又更新了,除了支持姿态评估以外,通过模型结构的修改还支持了小目标检测与高分辨率图像检测。原始的YOLOv8模型结构如下:
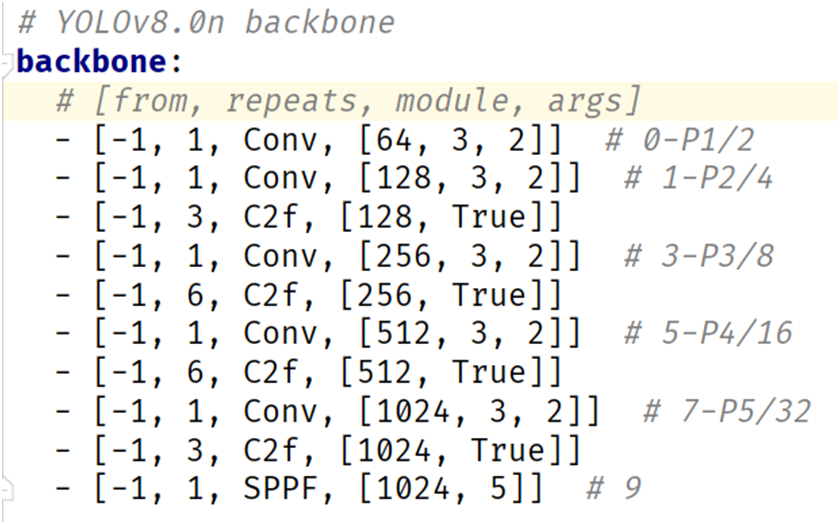

YOLOv8小目标检测模型
正常的YOLOv8对象检测模型输出层是P3、P4、P5三个输出层,为了提升对小目标的检测能力,新版本的YOLOv8 已经包含了P2层,有四个输出层。Backbone部分的结果没有改变,但是Neck跟Header部分模型结构调整如下:
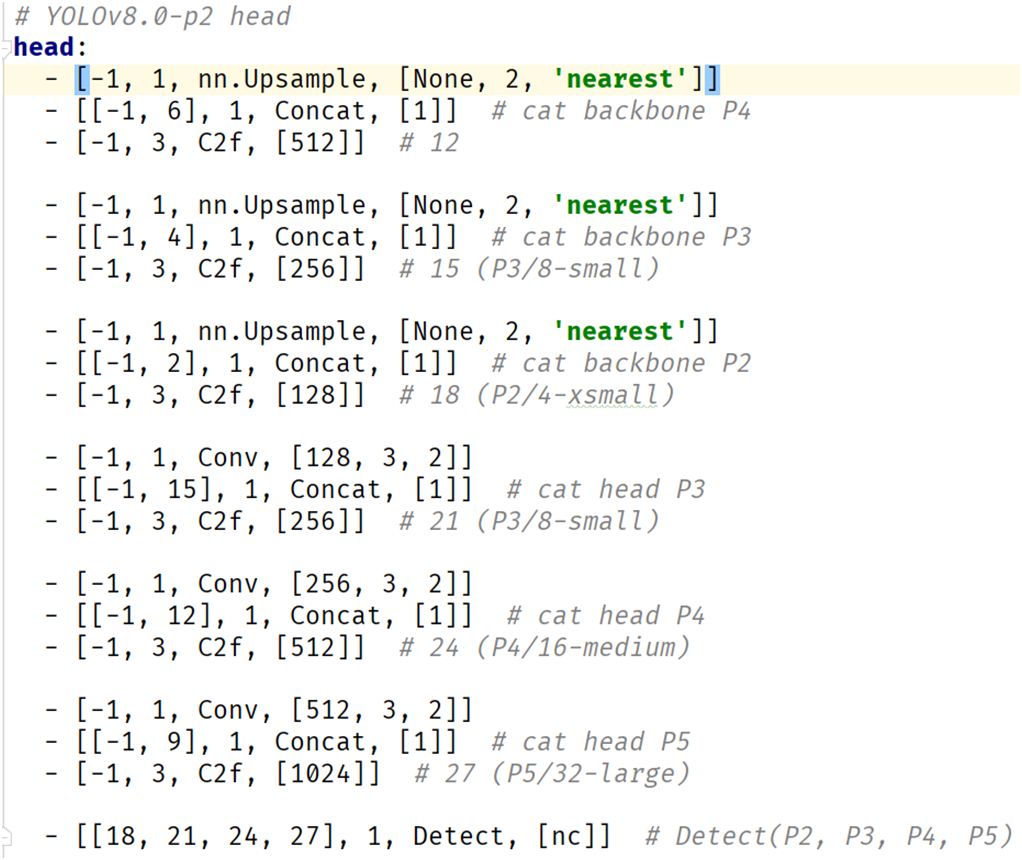
通过这样的模型结构调整,加强YOLOv8对小目标的检测能力。
YOLOv8实例分割C++推理演示
为了提升对高分辨率图像的支持,YOLOv8同时改进了输入分辨率、Backbone、Neck与Header部分,这些部分的改动对比正常的YOLOv8对象检测主要有:
输入分辨率:640x640 => 1280x1280 BackBone: 加入了两层,从9层变为11层、降采用至64倍! Neck部分:多层上采用,从2层变为3层 Head部分:输出层从P3、P4、P5变为P3、P4、P5、P6图示如下:
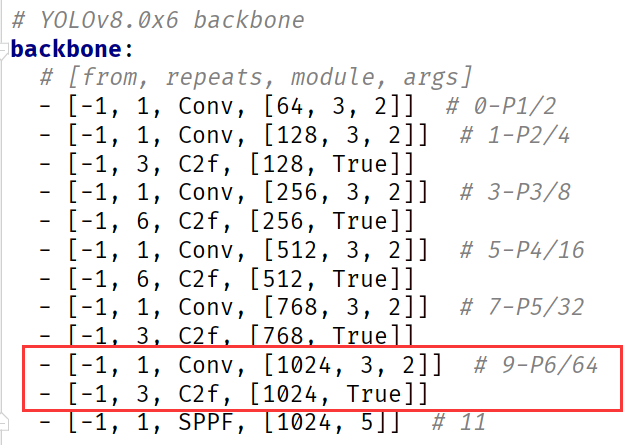
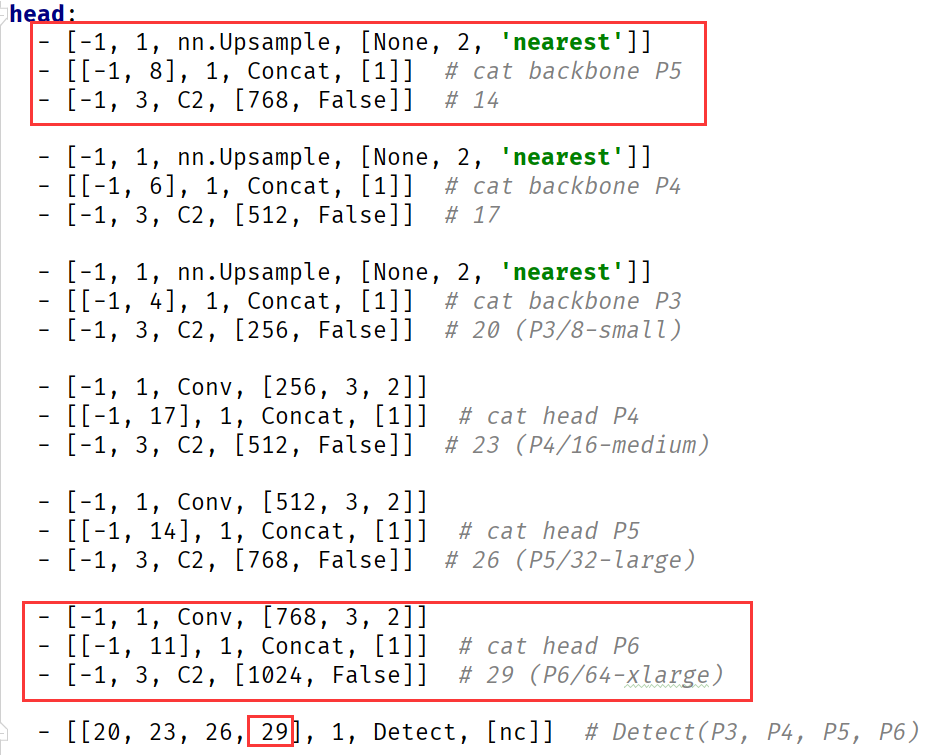
如何训练使用它们
model=yolov8n.ymal 使用正常版本 model=yolov8n-p2.ymal 小目标检测版本 model=yolov8n-p6.ymal 高分辨率版本
YOLOv8是YOLO系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了YOLOv5、YOLOv6、YOLOX等模型的设计优点,全面提升改进YOLOv5的模型结构基础上实现同时保持了YOLOv5工程化简洁易用的优势。
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
高分辨率合成孔径雷达图像的直线特征多尺度提取方法2010-05-06 1862
-
用高分辨率示波器测量微小信号2018-03-21 3636
-
增强高分辨率图像捕获的选择2018-10-25 1795
-
KAI-43140 CCD图像传感器提供高分辨率及图像均匀性2018-10-29 2470
-
请问哪几个版本的Microsoft Visual Studio集成开发环境支持高分辨率?2019-10-30 2355
-
如何实现DCP的高分辨率控制?2021-04-27 2099
-
超高分辨率图像实时显示系统设计2009-07-09 819
-
基于FPGA+PowerPC的高分辨率图像实时压缩系统的设计2010-09-15 880
-
基于FPGA的高分辨率全景图像处理平台2015-11-04 791
-
基于FPGA的高分辨率图像DCT域增强2016-08-30 968
-
基于多模型表示的高分辨率遥感图像配准方法_项盛文2017-03-19 1066
-
一种基于参考高分辨率图像的视频序列超分辨率复原算法2017-10-26 1388
-
高分辨率遥感图像飞机目标检测2018-03-06 1497
-
目标检测算法再升级!YOLOv8保姆级教程一键体验2023-02-28 4632
-
Moritex 5X 高分辨率远心镜头 助力晶圆检测2024-07-27 1370
全部0条评论

快来发表一下你的评论吧 !
