

最新3D表征自监督学习+对比学习:FAC
描述
论文题目:《FAC: 3D Representation Learning via Foreground Aware Feature Contrast》
作者机构:Nanyang Technological University(南洋理工大学)
项目主页:https://github.com/KangchengLiu/FAC_Foreground_Aware_Contrast (基于 PyTorch )
对比学习,最近在 3D 场景理解任务中展示了无监督预训练的巨大潜力。该作者提出了一个通用的前景感知特征对比 (FAC) 框架, 一种用于大规模 3D 预训练的前景感知特征对比框架。FAC 由两个新颖的对比设计组成,以构建更有效和信息丰富的对比对。构建区域级对比,以增强学习表征中的局部连贯性和更好的前景意识。设计了一个孪生对应框架,可以定位匹配良好的键,以自适应增强视图内和视图间特征相关性,并增强前景-背景区分。
对多个公共基准的广泛实验表明,FAC 在各种下游3D 语义分割和对象检测任务中实现了卓越的知识转移和数据效率。
摘要
对比学习最近在 3D 场景理解任务中展示了无监督预训练的巨大潜力。然而,大多数现有工作在建立对比度时随机选择点特征作为锚点,导致明显偏向通常在 3D 场景中占主导地位的背景点。此外,对象意识和前景到背景的辨别被忽略,使对比学习效果不佳。
为了解决这些问题,我们提出了一个通用的前景感知特征对比 (FAC) 框架,以在预训练中学习更有效的点云表示。FAC 由两个新颖的对比设计组成,以构建更有效和信息丰富的对比对。
第一个是在相同的前景段内构建正对,其中点往往具有相同的语义。
第二个是我们防止 3D 片段/对象之间的过度判别,并通过 Siamese 对应网络中的自适应特征学习鼓励片段级别的前景到背景的区别,该网络有效地自适应地学习点云视图内和点云视图之间的特征相关性。
使用点激活图进行可视化表明,我们的对比对在预训练期间捕获了前景区域之间的清晰对应关系。定量实验还表明,FAC 在各种下游 3D 语义分割和对象检测任务中实现了卓越的知识转移和数据效率。
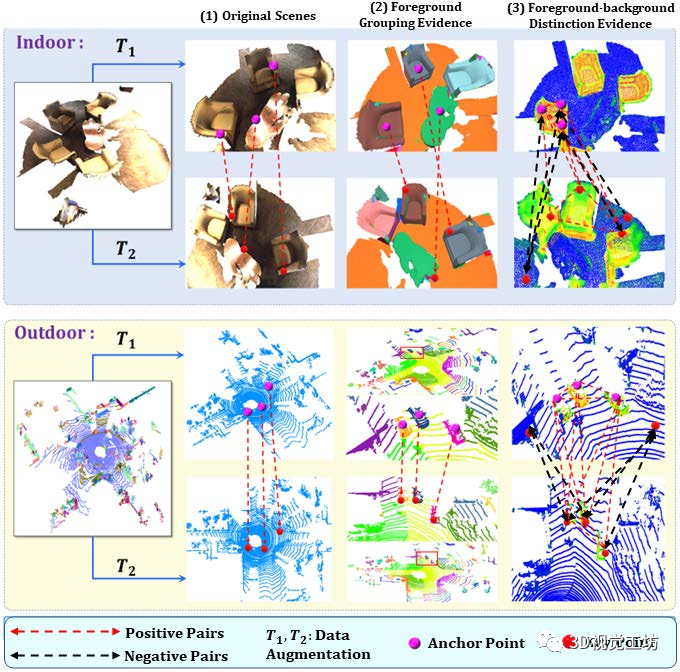
图1
图 1构建信息对比对在对比学习中很重要:传统对比需要严格的点级对应。
所提出的 FAC 方法同时考虑了前景分组 fore-ground 和前景-背景 foreground-background 区分线索,从而形成更好的对比对以学习更多信息和辨别力的 3D 特征表示。
一、前言
3D 场景理解对于许多任务至关重要,例如机器人抓取和自主导航。
然而,大多数现有工作都是全监督的,这在很大程度上依赖于通常很难收集的大规模带注释的 3D 数据。自监督学习 (SSL)允许从大规模未注释的数据中学习丰富且有意义的表示,最近显示出减轻标注约束的巨大潜力。它通过来自未标注数据的辅助监督信号进行学习,这些数据通常更容易收集。特别是,对比学习作为一种流行的 SSL 方法在各种视觉 2D 识别任务中取得了巨大成功。
在语义分割、实例分割和对象检测等各种下游任务中,还探索了用于点云表示学习的对比学习。然而,许多成功的 2D 对比学习方法对 3D 点云效果不佳,这主要是因为点云通常捕获由许多不规则分布的前景对象的复杂点以及大的背景点的数量。一些研究试图设计特定的对比度来迎合点云的几何形状和分布。
例如,[14, 55] 使用两个增强场景的最大池化特征来形成对比,但它们往往过分强调整体信息而忽略了前景对象的信息特征。
[12,19,51] 直接使用配准的点/体素特征作为正对,并对待所有未配准为否定对,导致语义上有许多错误的对比对。
我们建议利用场景前景 foreground 证据和前景-背景 foreground-background 区别来构建更多的前景分组意识和前景-背景区别意识对比,以学习有区别的 3D 表示。
对于前景分组感知对比,我们首先获得与过度分割的区域对应关系,然后在视图中与同一区域的点建立正对,从而产生语义连贯的表示。此外,我们设计了一种采样策略,在建立对比的同时采样更多的前景点特征,因为背景点特征通常信息量较少,并且具有重复或同质的模式。
对于前景-背景对比,我们首先增强前景-背景点特征区分,然后设计一个 Siamese 对应网络,通过自适应学习前景和背景视图内,及跨视图的特征对之间的亲和力来选择相关特征,以避免部分/对象之间的过度判别。
可视化显示,前景增强对比度引导学习朝向前景区域,而前景-背景对比度以互补的方式有效地增强了前景和背景特征之间的区别,两者合作学习更多的信息和判别表示,如图 1 所示。
这项工作的贡献可以概括为三个方面。
第一,我们提出了 FAC,一种用于大规模 3D 预训练的前景感知特征对比框架。
第二,我们构建区域级对比,以增强学习表征中的局部连贯性和更好的前景意识。
第三,最重要的是,我们设计了一个孪生对应框架,可以定位匹配良好的键,以自适应增强视图内和视图间特征相关性,并增强前景-背景区分。
最后,对多个公共基准的广泛实验表明,与最先进的技术相比,FAC 实现了卓越的自监督学习。
FAC 兼容流行的 3D 分割主干网络 SparseConv 和 3D 检测主干网络,包括 PV-RCNN、PointPillars 和 PointRCNN。
它也适用于室内密集 RGB-D 和室外稀疏 LiDAR 点云。
二、相关工作
2.1 3D 场景理解
3D 场景理解旨在理解 3D 深度或点云数据,它涉及多个下游任务,例如 3D 语义分割 ,3D 对象检测等。在 3D 深度学习策略的进步和不断增加的大规模 3D 数据集的推动下,它最近取得了令人瞩目的进展。已经提出了不同的方法来解决 3D 场景理解中的各种挑战。
例如,基于点的方法可以很好地学习点云,但在面对大规模点云数据集时往往会受到高计算成本的困扰。
基于体素的方法具有计算和内存效率,但通常会因体素量化而丢失信息。
此外,基于体素的 SparseConv 网络在室内场景分割中表现出非常有前途的性能,而结合点和体素通常在基于 LiDAR 的室外检测中具有明显的优势。我们提出的 SSL 框架在室内/室外 3D 感知任务中显示出一致的优势,并且它也是 backbone 不可知论的。
2.2 点云的自监督预训练。
对比预训练
近年来,在学习无监督表示的对比学习方面取得了显着的成功。
例如,对比场景上下文 (CSC)使用场景上下文描述符探索对比预训练。然而,它过于关注优化低级配准点特征,而忽视了区域同质语义模式和高级特征相关性。
一些工作使用最大池化场景级信息进行对比,但它往往会牺牲局部几何细节和对象级语义相关性,从而导致语义分割等密集预测任务的次优表示。
不同的是,我们明确考虑区域前景意识以及前景和背景区域之间的特征相关性和区别,这会导致 3D 下游任务中提供更多信息和判别性表示。
此外,许多方法结合了辅助时间或空间 3D 信息,用于与增强的未标记数据集和合成 CAD 模型进行自监督对比:
例如通过将 3D 场景视为 RGB-D 视频序列,从动态 3D 场景中引入学习合成 3D。
Randomrooms 通过将合成 CAD 模型随机放入常规合成 3D 场景中,来合成人造 3D 场景。
一些作品利用合成 3D 形状的时空运动先验,来学习更好的 3D 表示。
然而,大多数这些先前的研究都依赖于辅助时空信息的额外监督。不同的是,我们在没有额外合成 3D 模型的情况下对原始 3D 扫描进行自监督学习。
基于 mask 生成的预训练
随着视觉转换器的成功,mask 图像建模已证明其在各种图像理解任务中的有效性 。最近,基于掩码的预训练也被探索用于理解小型 3D 形状。
然而,基于掩码的设计通常涉及一个 transformer 主干,它在处理大型 3D 场景时对计算和内存都有很高的要求。
我们专注于对比学习的预训练,它与基于点和基于体素的 backbone 网络兼容。
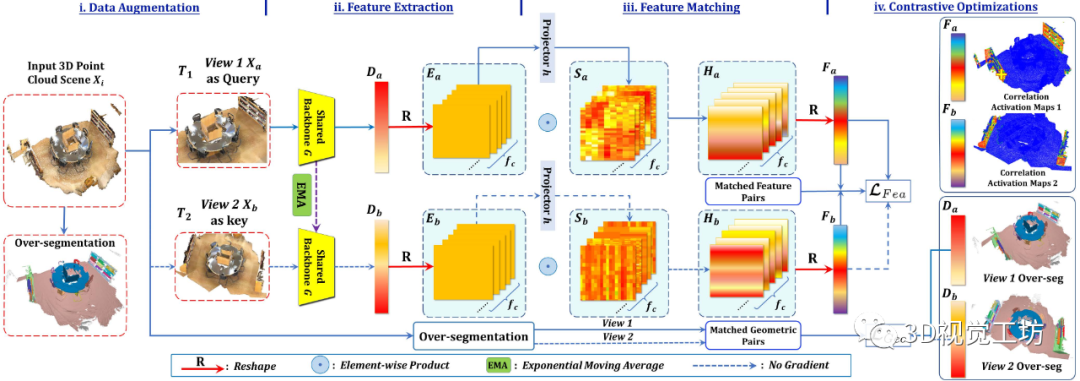
图 2. 我们提议的 FAC 的框架。
FAC 将两个增强的 3D 点云视图作为输入,首先提取主干特征 和 以与 进行前景感知对比。
然后将主干特征重塑为正则化表示 和 ,以找到两个视图之间的对应关系以进行特征匹配。具体来说,我们采用投影头将 和 传输到特征图 和 ,以自适应地学习它们的相关性并产生增强的表示 和 。
最后, 和 被重塑回 和 ,其中匹配的特征对通过特征对比度损失 得到增强。
因此,FAC 在视图内和视图之间利用互补的前景意识,以及前景-背景区别来进行更多信息表示学习。
三、方法
如图 2 所示,我们提出的 FAC 框架由四个部分组成:数据增强、骨干网络特征提取、特征匹配和具有匹配对比对的前景-背景感知特征对比优化。
在下文中,我们首先重新审视 3D 点云的典型对比学习方法,并讨论它们可能导致信息较少的表示的局限性。
然后,我们从三个主要方面阐述了我们提出的 FAC:
区域分组对比,利用过度分割的局部几何同质性,来鼓励局部区域的语义连贯性;
一个由连体网络和特征对比损失组成的对应框架,用于捕获所学特征表示之间的相关性;
利用更好的对比对,进行更具辨别力的自监督学习的优化损失。
3.1 重新思考点级和场景级对比
基于对比学习的 3D SSL 的关键是在两个增强视图之间构建有意义的对比对。正对已在 PointContrast (PCon) 中的点级别或 DepthContrast (DCon) 中的场景级别中构建。
具体来说,给定 3D 局部点/深度扫描的增强视图,应用对比损失来最大化正对的相似性和负对之间的区别。在大多数情况下,可以应用 InfoNCE loss来进行对比:
这里:
和 是两个增强视图的特征向量,用于对比。
是匹配正对的索引集。 是正对,其特征嵌入被强制相似;
而 是负对,其特征嵌入被鼓励相似与众不同。
PCon 直接采用配准点级特征对,而 DCon 使用最大池化场景级特征对进行对比。尽管它们在 3D 下游任务中表现不错,但先前研究中构建的对比对往往是次优的。如图 1 所示:
点级对比度往往过分强调细粒度的低级细节,而忽略了通常提供对象级信息的区域级几何连贯性。
场景级对比聚合了整个场景的特征以进行对比,这可能会丢失对象级空间上下文和独特的特征,从而导致下游任务的信息表示较少。
因此,我们推测区域级对应更适合形成对比度,并且如图 1 所示,这已经通过实验验证,更多细节将在随后的小节中详细说明。
3.2 前景感知对比度
Region-wise 特征表示已被证明在考虑下游任务(如语义分割和检测)的上下文时非常有用。在我们提出的几何区域级前景感知对比中,我们通过利用现成的点云过分割技术来获得区域。采用过度分割(over-segmentation)的动机是其在三个主要方面的优点。
首先,它可以以完全无监督的方式工作,不需要任何带标注的数据。
其次,我们提出的区域采样(稍后描述)允许我们以无监督的方式过滤掉天花板、墙壁和地面等背景区域,其中背景区域通常由具有大量点的几何均匀图案表示。也可以过滤掉点数非常有限的区域,这些区域在几何和语义上都是嘈杂的。
第三,过分割提供了具有高语义相似性的几何连贯区域,而不同的远距离区域在采样后往往在语义上是不同的,这有效地促进了判别特征学习。
具体来说,过分割将原始点云场景划分为 类不可知区域 , 对于任何 来说:。
我们的实证实验表明,我们的框架 FAC 在没有微调的情况下,可以有效地与主流的过分割方法一起工作。
平衡学习的区域抽样
我们设计了一种简单但有效的区域采样技术,以从通过过度分割导出的几何均匀区域获得有意义的前景。具体来说:
我们首先统计每个区域的点数,并根据区域包含的点数对区域进行排序。
然后我们将具有中位数点数的区域识别为 。
接下来,我们选择点数与 最接近的 个区域来形成对比对。
本地区域一致性的对比
与上述 PCon 和 DCon 不同,我们直接利用区域同质性来获得对比度对。
具体来说,以区域内的平均点特征为锚点,我们将同一区域内的选定特征视为正键,将不同区域内的选定特征视为负键。
受益于区域采样策略,我们可以专注于前景以更好地表示学习。将区域内的点数表示为 ,将主干特征表示为 ,我们将它们的点特征聚合以产生区域内的平均区域特征作为锚点,以增强鲁棒性:
将 作为锚点,我们提出了一种前景感知几何对比度损失,将点特征拉到局部几何区域中对应的正特征,并将其与不同分离区域的负点特征推开:
这里, 和 分别表示具有 的正样本和负样本。
我们将每个区域锚点的正负点特征对的数量均等地设置为 。请注意,我们提出的前景对比度是 PCon 的通用版本,前景增强,如果所有区域都缩小到一个点,它会返回到 PCon。受益于区域几何一致性和平衡的前景采样,仅前景感知对比度就在经验实验结果的数据效率方面优于最先进的 CSC 。
3.3 前景-背景(foreground-background)感知对比度
如图 2 所示,我们提出了一个连体对应网络 (SCN) ,来明确识别视图内和视图之间的特征对应关系,并引入特征对比度损失以自适应地增强它们的相关性。 SCN 仅在预训练阶段用于提高表示质量。预训练后,只有骨干网络针对下游任务进行微调。
用于自适应相关挖掘的孪生通信网络。给定具有 个点的输入3D场景
FAC首先将其转换为两个增强视图和
并通过将两个视图输入骨干网络 及其动量来获得骨干特征和 分别更新(通过指数移动平均)( 是特征通道数)。
为了公平比较,我们采用与现有工作相同的增强方案。
此外,我们将主干点级特征重塑为特征图 和 ,以获得正则化点云表示并降低计算成本。
然后,我们将投影仪分别应用于 和 ,以获得与 和 相同维度的特征图 和 。我们采用两个简单的点 MLP,中间有一个 ReLU 层来形成投影仪 。特征图 和 作为可学习的分数,自适应地增强两个视图内和跨两个视图的重要和相关特征。
最后,我们在 and 之间进行逐元素乘积,以获得增强的特征 和 进一步转化回逐点特征 和 进行对应挖掘。所提出的 SCN 增强了全局特征级判别表示学习,从而能够与匹配的特征进行后续对比。
与 Matched Feature 和 ForegroundBackground Distinction 对比。
将获得的采样前景-背景对标记为负,我们进行特征匹配以选择最相关的正对比对。如图 2 所示,我们评估 和 之间的相似性并选择最相关的对进行对比。区域锚点的选择方式与 3.2 小节相同。
具体地,我们首先引入一个区域内点特征的平均特征 作为形成对比时的锚点,给出,基于点的观察在同一局部区域中往往具有相同的语义。
对于 中的第 个点级特征 ,我们计算其与区域特征 的相似度:
这里 表示向量 和 之间的余弦相似度。我们从 中采样前 个元素作为正键,同时从前景和背景点特征中提取区域特征 。通过将 操作重新表述为最优传输问题,很容易使其变得可微分。
此外,我们同样选择其他 个前景-背景对作为负对:
这里, 表示在另一个视图中从 中识别出的与 最相似的 个元素的正键。 分别表示一批中采样的其他 个负点特征。因此,通过学习 3D 场景的点级特征图 和 ,可以自适应地增强相关的交叉视点特征。
我们的特征对比通过明确地找到前景锚点的区域到点最相关的键作为查询来增强视图内和视图之间特征级别的相关性。通过学习特征图,自适应地强调相关前景/背景点的特征,同时抑制前景-背景特征。FAC 在点激活图中定性有效,在下游迁移学习和数据效率方面定性有效。
3.4 FAC联合优化
同时考虑局部区域级前景几何对应和视图内与视图间的全局前景-背景区分,FAC框架 的总体目标函数如下:
这里 是平衡两个损失项的权重。我们根据经验设置 而不进行调整。

图3
图 3. 室内 ScanNet(第 1-4 行)和室外 KITTI (第 5-8 行)投影点相关图关于黄色十字突出显示的查询点的可视化。
每个示例中的视图 1 和视图 2 ,分别显示视图内和交叉视图相关性。
我们将 FAC 与最先进的 CSC 在分割(第 1-4 行)和 ProCo 在检测(第 5-8 行)方面进行比较。
FAC 清楚地捕获了视图内和视图之间更好的特征相关性(第 3-4 列)。
四、实验
数据高效学习和知识转移能力已被广泛用于评估自监督预训练和学习的无监督表示[12]。在下面的实验中,我们首先在大规模未标记数据上预训练模型,然后对其进行微调使用下游任务的少量标记数据来测试其数据效率。
我们还将预训练模型转移到其他数据集,以评估它们的知识转移能力。这两个方面通过多个下游任务进行评估,包括3D 语义分割、实例分割和对象检测。附录中提供了所涉及数据集的详细信息。
4.1.实验设置
3D 对象检测。
对象检测实验涉及两个主干,包括 VoxelNet 和 PointPillars。按照 ProCo,我们在 Waymo 上预训练模型并在 KITTI 和 Waymo 上对其进行微调。继 ProCo 和 CSC 之后,我们通过随机旋转、缩放和翻转以及随机点丢失来增强数据以进行公平比较。
我们在 ProCo 之后将 和 中的超参数 设置为 ,,并且在所有实验中正/负对的总数为 ,包括检测和分割而不调整。
在 Waymo 和 KITTI [8] 的室外目标检测中,我们使用 Adam 优化器对网络进行预训练,并遵循 ProCo 的 epoch和批量大小设置,以便与现有作品进行公平比较。
在 ScanNet 上的室内物体检测中,我们遵循 CSC 采用 SparseConv 作为骨干网络和 VoteNet 作为 3D 检测器,并遵循其训练设置,场景重建数量有限。
3D 语义分割。
对于 3D 分割,我们在有限的重建设置中严格遵循 CSC。具体来说,我们在 ScanNet 上进行预训练,并对室内 S3DIS、ScanNet 和室外 SemanticKITTI (SK)上的预训练模型进行微调。
我们在预训练中使用 SGD,学习率为 ,批量大小为 ,步长为 ,以确保与其他 3D 预训练方法(包括 CSC 和 PCon)进行公平比较。此外,我们在 SK 上测试了 ScanNet 预训练模型,以评估其对室外稀疏 LiDAR 点云的学习能力。
唯一的区别是我们对 SK 的模型进行了 次微调,而对室内数据集进行了 次微调。使用 SK 进行更长时间的微调是因为将在室内数据上训练的模型转移到室外数据需要更多时间来优化和收敛。
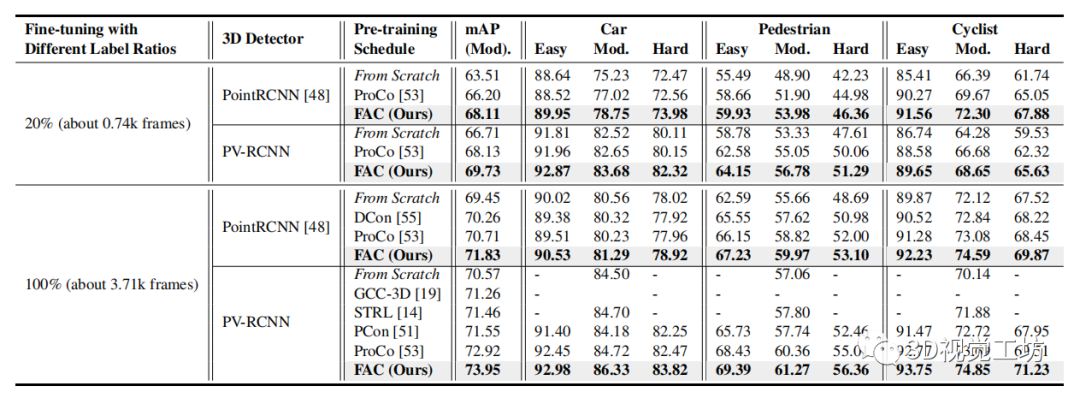
表1
表 1. KITTI 上的数据高效3D 对象检测。
我们在 Waymo 上预训练了 PointRCNN 和 PV-RCNN 的骨干网络,并在微调中以 和 的注释比例转移到 KITTI。对于两种设置,FAC 始终优于最先进的 ProCo。“From Scratch”表示从头开始训练的模型。所有实验结果均取三个运行的平均值。
4.2.数据高效的迁移学习
3D 对象检测。
自监督预训练的一个主要目标是使用更少的标记数据进行更高效的数据迁移学习以进行微调。我们评估了从 Waymo 到 KITTI 的数据高效传输,如表 1 和图 4 所示。
我们可以看到 FAC 始终优于最新技术。通过使用 的标记数据进行微调,FAC 通过使用 的训练数据实现了与从头开始训练相当的性能,展示了它在减轻 3D 对象检测中对大量标记工作的依赖方面的潜力。如图 3 所示,FAC 对车辆和行人等视图间和视图内对象具有明显更大的激活,表明其学习到的信息和判别表示。
我们还研究了数据高效学习,同时在具有 1% 标签的标签极其稀缺的情况下执行域内传输到 Waymo 验证集。如表 2 所示,FAC 明显且一致地优于 ProCo,证明了其在减少数据注释方面的潜力。此外,我们在 ScanNet 上进行了室内检测实验。
如表 3 所示,与 From Scratch 相比,FAC 实现了出色的转移,并将 AP 显着提高了 ,标签为 10%。此外,当应用较少的注释数据时,改进会更大。卓越的对象检测性能主要归功于我们利用信息前景区域形成对比度的前景感知对比度,以及增强整体对象级表示的自适应特征对比度。
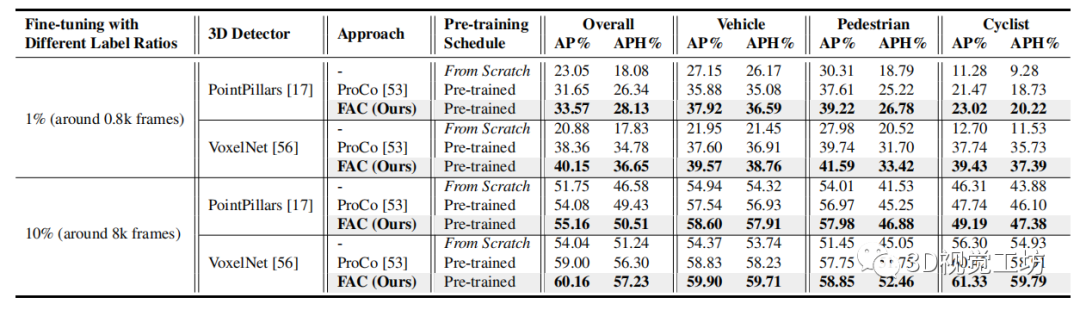
表2
表 2. Waymo 上具有 1% 和 10% 标记训练数据的数据高效3D 对象检测实验结果。与最先进的 ProCo 相比,表 1 中针对 FAC 的 KITTI 获得了类似的实验结果。
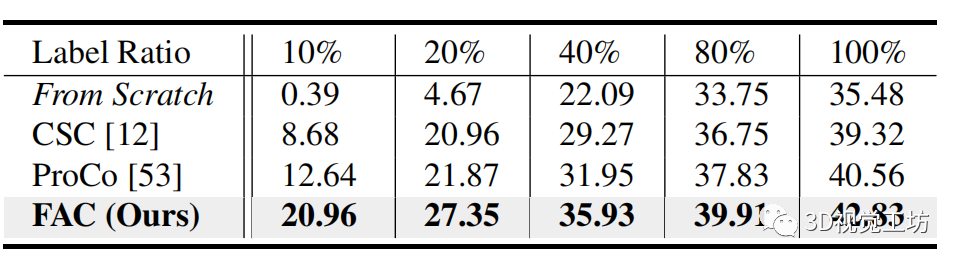
表3
表 3. 以 VoteNet 作为主干网络的 ScanNet 上,有限数量的场景重建的数据高效3D 对象检测平均精度 (AP%) 结果。
3D 语义分割。
我们首先对数据集 ScanNet 上的点激活图进行定性分析。如图 3 所示,与最先进的 CSC 相比,FAC 可以在 3D 场景内和之间找到更多的语义关系。这表明 FAC 可以学习捕捉相似特征同时抑制不同特征的极好的表征。
我们还进行了如表 4 所示的定量实验,我们在训练中采用有限的标签(例如,{1%、5%、10%、20%})。我们可以看到,对于不同标记百分比下的两个语义分割任务,FAC 的性能始终大大优于基线 From Scratch。
此外,当仅使用 1% 的标签时,FAC 的性能显着优于最先进的 CSC,证明其在使用有限标签学习信息表示方面的强大能力。注意 FAC 在使用较少标记数据的同时实现了更多改进。对于数据集 SK 上的语义分割,FAC 在标记数据减少的情况下实现了一致的改进和类似的趋势。
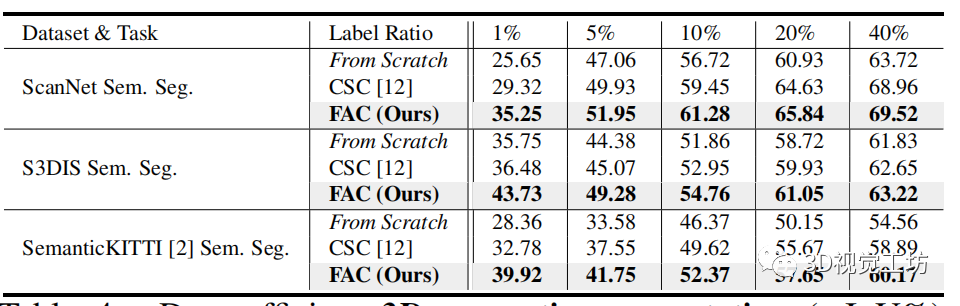
表4
表 4. 具有不同标签比率的 ScanNet、S3DIS 和 SemanticKITTI (SK) 上有限场景重建 的数据高效3D 语义分割(mIoU%) 结果。
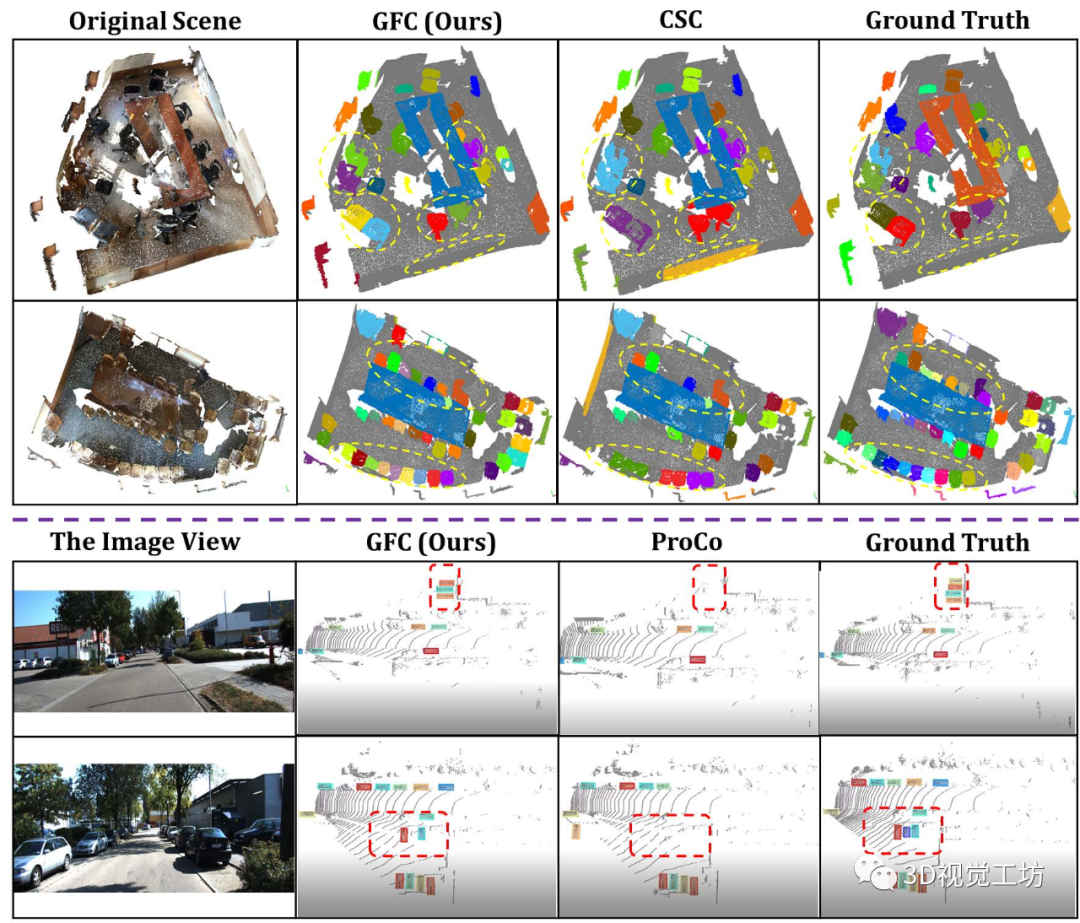
图 4. 与 CSC 相比,ScanNet 的室内 3D 分割可视化与 ProCo 相比,使用 10% 标记训练数据和 KITTI 进行微调,带有 20% 标记训练数据。
不同的分割实例和检测到的对象,用不同的颜色突出显示。
预测的差异,用黄色椭圆和红色框突出显示。
欢迎关注微信公众号「3D视觉工坊」,加群/文章投稿/课程主讲,请加微信:dddvisiona,添加时请备注:加群/投稿/主讲申请
方向主要包括:3D视觉领域各细分方向,比如相机标定|三维点云|三维重建|视觉/激光SLAM|感知|控制规划|模型部署|3D目标检测|TOF|多传感器融合|AR|VR|编程基础等。
4.3.消融研究和分析
我们对 FAC 中的关键设计进行广泛的消融研究。具体来说,我们检查了所提出的区域采样、特征匹配网络和两个损失的有效性。最后,我们提供t-SNE 可视化以将 FAC 学习的特征空间与最先进的进行比较。
在消融研究中,我们在语义分割实验中采用 5% 的标签,在 ScanNet 上的室内检测实验中采用 10% 的标签,在 KITTI 上采用 PointRCNN 作为 3D 检测器的室外物体检测实验中采用 20% 的标签。
区域抽样和特征匹配。
区域采样将前景区域中的点采样为锚点。表 5 显示了由抽样表示的相关消融研究。
我们可以看到,在没有采样的情况下,分割和检测都会恶化,这表明过度分割中的前景区域在形成对比度的同时可能提供重要的对象信息。它验证了所提出的区域采样不仅可以抑制噪声,还可以减轻对背景的学习偏差,从而在下游任务中提供更多信息。
此外,我们用匈牙利二分匹配(即H-FAC)替换建议的 Siamese 对应网络,如表 5 所示。我们可以观察到一致的性能下降,表明我们的 Siamese 对应框架可以实现更好的特征匹配并提供用于下游任务的相关性良好的特征对比对。附录中报告了更多匹配策略的比较。
FAC 损失。
FAC 采用前景感知几何损失 和特征损失 ,这对其在各种下游任务中的学习表示至关重要。几何损失指导前景感知对比度以捕获局部一致性,而特征损失指导前景背景区分。它们是互补的,并且协作学习下游任务的判别表示。
如表 5 中的案例 4 和案例 6 所示,包括损失明显优于基线以及最先进的 CSC 在分割方面和 ProCo 在检测方面的表现。
例如,仅包括 (案例 6)在 KITTI 和 ScanNet 上的目标检测平均精度达到 67.22% 和 18.79%,分别优于 ProCo(66.20% 和 12.64%)1.02% 和 6.15%,如表 1 和表3。
最后,表 5 中的完整 FAC(包括两种损失)在各种下游任务中学习到具有最佳性能的更好表示。
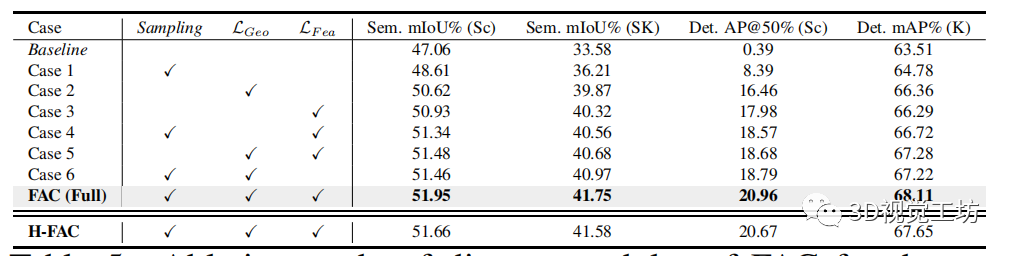
表5
表 5. FAC 不同模块在 ScanNet (Sc) 和 SemanticKITTI (SK) , 及 KITTI (K) 下游任务的消融研究
使用 t-SNE 进行特征可视化。
我们使用 tSNE 来可视化为 SemanticKITTI 语义分割任务学习的特征表示,如图 5 所示。
与 PCon 和 CSC 等其他对比学习方法相比,FAC 学习了更紧凑和判别特征空间,可以清楚地区分不同语义类的特征。
如图 5 所示,FAC 学习的特征具有最小的类内方差和最大的类间方差,表明 FAC 学习的表示有助于在下游任务中学习更多的判别特征。

图 5. t-SNE SemanticKITTI 语义分割的特征嵌入可视化,使用 5% 的标签进行微调(ScanNet 预训练)。
显示了具有最少点数的十个类,其中 表示类内和类间方差。
与最先进的方法 PCon、CSC 相比,FAC 学习了更紧凑的特征空间,具有最小的类内方差和最大的类间方差。
五、结论
我们提出了一种用于 3D 无监督预训练的前景感知对比框架 (FAC)。FAC 构建更好的对比对以产生更多几何信息和语义意义的 3D 表示。
具体来说,我们设计了一种区域采样技术,来促进过度分割的前景区域的平衡学习并消除噪声区域,这有助于基于区域对应构建前景感知对比对。
此外,我们增强了前景-背景的区别,并提出了一个即插即用的 Siamese 对应网络,以在前景和背景部分的视图内和视图之间找到相关性良好的特征对比对。
大量实验证明了 FAC 在知识转移和数据效率方面的优越性。
审核编辑 :李倩
-
使用MATLAB进行无监督学习2025-05-16 1747
-
深度学习中的无监督学习方法综述2024-07-09 3265
-
设计时空自监督学习框架来学习3D点云表示2022-12-06 1771
-
自监督学习的一些思考2022-01-26 613
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5646
-
基于人工智能的自监督学习详解2021-03-30 7142
-
半监督学习:比监督学习做的更好2020-12-08 2302
-
为什么半监督学习是机器学习的未来?2020-11-27 4790
-
最基础的半监督学习2020-11-02 3517
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6821
-
如何用Python进行无监督学习2019-01-21 5435
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 1013
-
基于半监督学习框架的识别算法2018-01-21 1081
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 1047
全部0条评论

快来发表一下你的评论吧 !
