

 龙芯中科自研 GPGPU!大语言模型浪潮下,国产厂商如何把握机会?
龙芯中科自研 GPGPU!大语言模型浪潮下,国产厂商如何把握机会?
描述
电子发烧友网报道(文/李弯弯)日前,在龙芯中科 2022 年度暨 2023 年第一季度业绩暨现金分红说明会上,龙芯中科董事长胡伟武宣布,集成龙芯自研 GPGPU (通用图形处理器)的第一款 SoC 芯片预计将于 2024 年一季度流片。
胡伟武表示,目前已经基本完成相关 IP 研发,正在开展全面验证,在此基础上,2024 年下半年将完成兼顾显卡和算力加速功能的专用芯片流片。
大语言模型拉动GPGPU需求增长
GPGPU(通用图形处理器),脱胎于 GPU(图形处理器)。GPU最初是为解决 CPU 在图形处理领域性能不足的问题而诞生的,而面对非图像显示领域并涉及大量并行运算的领域,比如 AI、加密解密、科学计算等,则更需要通用计算能力,GPGPU应运而生。
近段时间,随着ChatGPT的出圈,全球掀起大语言模型的研究热潮。而无论是大模型的训练还是推理,这都离不开GPGPU芯片来提供算力支持。业界推测,在未来几年内,大语言模型的训练和部署将推动GPGPU需求增长。
在训练端,英伟达可以说是这场大模型浪潮中的绝对受益者,目前全球大模型的训练基本依赖英伟达的GPU。英伟达有两款强大的GPU产品:A100和H100。
A100 是英伟达2020年推出的数据中心级云端加速芯片,拥有540亿晶体管,采用台积电7nm工艺制程,支持FP16、FP32和FP64浮点运算,为人工智能、数据分析和HPC数据中心等提供算力。A100 提供超快速的显存带宽,可处理超大型模型和数据集。
H100是英伟达2022年3月发布的最新一代数据中心GPU,集成800亿晶体管,采用台积电定制的4nm工艺。英伟达CEO黄仁勋此前表示,这款GPU具有超强的计算能力,20个H100 GPU便可承托相当于全球互联网的流量。相比于A100,H100在FP16、FP32和FP64计算上快三倍,非常适用于当下流行且训练难度高的大模型。
由于全球众多科技企业加入大语言模型研究大军,近段时间,英伟达的GPU供货周期拉长,价格上涨,其A100 GPU市场单价两个月前还在10万元左右,如今已经上涨到15万元。
目前大部分研究都认为,AI大模型预训练是一个非常耗时、耗力、耗电的过程,这部分对GPU的贡献最大。然而实际上,如果真正地去计算成本,对于企业来说,大模型的推理将会耗费巨大的成本,而其中很大部分则是在GPU的购买上。

图:沐曦研究科学家李兆石演讲(电子发烧友拍摄)
在近日某人工智能论坛上,沐曦研究科学家李兆石介绍,以谷歌为例,谷歌目前主要的收入来源是搜索广告,每次搜索平均能够给谷歌带来约1.6美分。
如果把类似ChatGPT插入到谷歌搜索里,在现在主流高性能的英伟达A100 GPU上,需要八张GPU才能做一次GPT3的推理,把电费和GPU的一次性购买成本算进去,每次推理的平均成本大约是0.36美分,如果谷歌直接在谷歌搜索里用类似ChatGPT规模的大模型,相当于很大一部分利润都将耗费在大模型的推理成本上。
相当于在A100上做GPT3规模的预训练,大概需要80万美元。而把刚才0.36美分乘以谷歌每天的搜索次数,可以发现,直接在谷歌搜索里用这个GPT推理,这个推理成本每天是1亿美元,推理成本远远高于预训练成本。
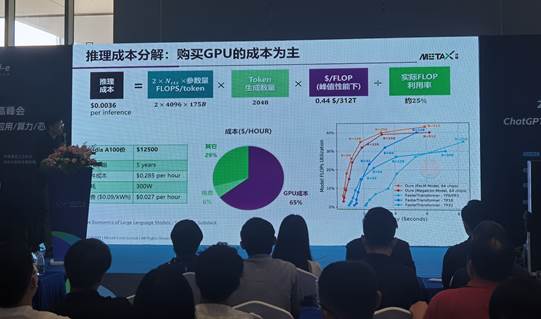
将这个推理成本再进一步拆解,会发现,以英伟达A100 GPU的市场价格12500美元计算(这是之前的价格,现在国内价格基本上已经涨到15到20万人民币),一般GPU的使用年限是五年,把这个购买成本线性平摊到五年时间,这个0.36美分的每次推理成本里面,65%是购买GPU的成本。也就是说GPU的一次性购买成本,占大模型训练和推理的绝大部分。
国内AI算力芯片厂商的产品和技术进展
可以看到,虽然目前大语言模型的训练基本依赖英伟达的GPU,然而随着大模型逐渐走向落地应用,在推理侧,国内外AI算力芯片厂商将迎来较大的市场机会。
在国内,近些年已经有不少厂商在高性能计算AI算力芯片领域取得进展,包括寒武纪、海光信息、壁仞科技、摩尔线程、天数智芯、燧原科技、沐曦集成、芯动科技、登临科技等。
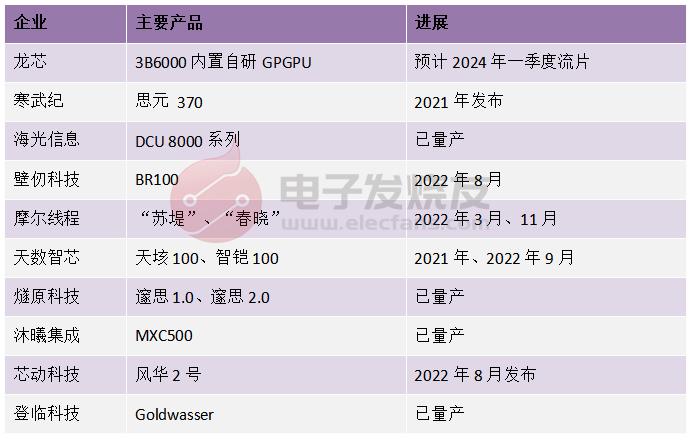
电子发烧友制表
如今CPU厂商龙芯也加入到了GPGPU大军中,不过可以看到龙芯的GPGPU主要还是集成在自家的SOC中。事实上,龙芯早在2017年就开始研究GPU,2021年7月,该公司发布的龙芯3号系列处理器的配套桥片“龙芯7A2000”,内部就首次集成了龙芯自研的GPU。
如今龙芯又透露了其在GPGPU方面的最新进展。据胡伟武介绍,2024 年龙芯将流片首款大小核协同芯片。龙芯 3A6000 的下一代将是 3B6000,四大四小八个核,内置自研 GPGPU。大核争取通过结构优化再提高性能 20% 以上。
寒武纪是一家专注于人工智能芯片研发和技术创新的企业,能够为视觉、语音、自然语言处理、传统机器学习等人工智能技术提供基础计算平台。2021年7月,寒武纪发布了其第三代云端 AI 芯片思元 370,以及基于思元 370 的两款加速卡 MLU370-S4 和 MLU370-X4。
同时,寒武纪全新升级了 Cambricon Neuware 软件栈,新增推理加速引擎 MagicMind,实现训推一体,显著提升了开发部署的效率。而且,有 7nm 先进工艺和全新 MLUarch03 架构加持,思元 370 芯片算力最高可达 256TOPS (INT8),是上一代产品思元 270 算力的 2 倍。
海光信息的产品包括通用处理器(CPU)和协处理器(DCU),海光DCU属于GPGPU的一种。海光DCU 8000系列,支持INT4、INT8、FP16、FP32、FP64运算精度,支持4个HBM2内存通道,最高内存带宽为1TB/s、最大内存容量为32GB。
海光DCU协处理器全面兼容ROCm GPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,CUDA用户可以以较低代价快速迁移至ROCm平台。
壁仞科技去年8月发布了首款通用GPU BR100,集成770亿晶体管,其INT8算力达2048 TOPS,BF16算力达1024 TFLOPS,TF32+算力达512 TFLOPS,FP32算力达256 TFLOPS。同期,壁仞科技还发布了自主原创架构——壁立仞、创造全球性能纪录的OAM服务器——海玄,以及OAM模组——壁砺100,PCIe板卡产品——壁砺104,以及自主研发的BIRENSUPA软件平台。
摩尔线程已经发布两款自主研发的GPU芯片产品,去年3月发布GPU产品“苏堤”,11月又发布了第二款GPU芯片“春晓”。“春晓”内置MUSA架构通用计算核心以及张量计算核心,可支持FP32、FP16和INT8三种计算精度;相较于其首款自研的GPU“苏堤”,“春晓”内置的四大计算引擎都进行了全面升级,性能显著提升,AI计算加速平均提升4倍。
天数智芯于2018年正式启动通用GPU芯片设计,在2021年发布了其通用GPU“天垓100”芯片及天垓100加速卡,2021年10月宣布天垓100正式进入量产环节。2022年9月,天数智芯又发布了首款7nm制程的云端推理通用GPU产品“智铠100”。
智铠 100 芯片支持 FP32、FP16、INT8 等多精度混合计算,实现了指令集增强、算力密度提升、计算存储再平衡,支持多种视频规格解码。
燧原科技已经迭代了两代训练和推理产品,第三代也已经在研发中。燧原科技已经在科研领域和智慧城市的应用中落地了训练和推理的超千卡算力集群。
该公司创始人兼COO张亚林此前在接受电子发烧友采访的时候表示,类似ChatGPT这样的AIGC生成式模型,对于燧原科技而言是个机遇,公司可以把已经积累的系统集群的经验推广到更多的客户赛道上,帮助客户使能更多大模型的生成。
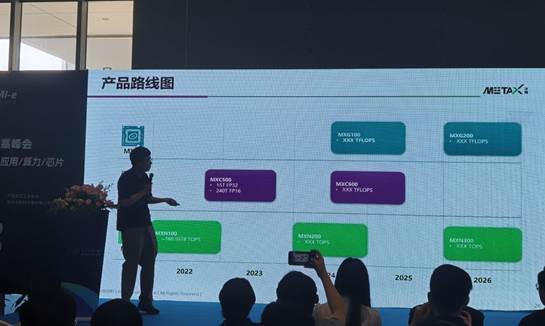
沐曦集成产品路线图
沐曦集成目前有三条产品线规划,G系列、C系列和N系列,G系列主要是用于图形处理领域,C系列主要用于高性能云端的训练和推理,N系列主要是云端的推理芯片。现在N系列的云端推理芯片已经量产出货,C系列正在做调试,如果没有问题的话,也很快就会量产。
芯动科技已经发布两款GPU芯片——风华1号和风华2号。风华1号于2021年发布,于去年9月正式量产。风华2号于2022年8月发布,是一款集超低功耗、强渲染、4K高清三屏显示、及智能AI计算于一体的桌面和笔记本GPU。
风华2号在AI计算能力方面,支持科学/边缘计算,AI性能超过12.5TOPS,支持人脸识别、目标识别、语义分割、图像超分辨率等多种场景实时应用。
登临科技是一家专注于高性能通用计算平台的芯片研发与技术创新的公司,其自主研发的GPU+架构正式采用了软件定义的片内异构体系,目前首款基于GPU+的系列产品—Goldwasser已在云至边缘的各个应用场景实现规模化落地。
登临科技联合创始人王平此前在接受电子发烧友采访的时候表示,登临科技希望通过异构,从由点及面在一些足够大的市场领域,把产品做到比英伟达同系列产品更具性价比优势,甚至超过英伟达。
带着这样的出发点,在大型语言模型方面,登临科技会更关心如何更好的提升产品的能效比。简单来说,在同样功耗下,登临科技可以提供英伟达1.5到2倍的算力,在算力一致的情况下,做到单位功耗更低。这样从计算的整体性能上,实现英伟达同类产品的能效比3倍的优势。如此一来,可以极大地节省电费及运维成本。
小结
很显然,随着ChatGPT的出圈,国内外众多科技企业掀起大语言模型的研究热潮,而无论是大模型的训练还是部署,都离不开GPGPU芯片提供算力支持。目前而言,大模型的训练基本依赖英伟达的GPU,然而相比较而言,随着大模型逐步落地应用,在推理部分将同样需要用到大量GPGPU,而这也是除英伟达之外,国内外众多GPGPU厂商的机会。
-
国产GPGPU集体爆发!沐曦登陆科创板,龙芯也宣布了2025-12-17 11625
-
龙芯中科首款GPGPU芯片9A1000计划明年流片2024-09-24 1980
-
龙芯中科胡伟武:3B6600 八核桌面 CPU 性能将达到英特尔中高端酷睿 12~13 代水平2024-08-13 2054
-
大模型发展下,国产GPU的机会和挑战2024-07-18 951
-
广东龙芯发布2K0300蜂鸟板,今日正式发售2024-06-20 694
-
国产CPU龙头龙芯中科侵权MIPS案胜诉!力证自研指令集实力2023-06-26 1922
-
龙芯3D5000完成初样芯片验证,国产服务器芯片即将诞生2023-02-15 1275
-
润和软件与龙芯中科战略签约,携手发布国内首个“龙芯+OpenHarmony”教育解决方案2022-11-17 2230
-
苹果自研射频芯片?OPPO自研NPU芯片!芯片的国产替代需要跨越三个误区!2022-01-02 7207
-
简述国产GPGPU的进阶之路2021-10-09 3238
-
中国自研CPU第一股龙芯中科已提交了 IPO 申请2021-07-02 6240
-
龙芯中科将成为首家在创科版上市的国产CPU企业2021-01-08 9060
-
国产CPU厂商龙芯中科欲冲刺科创板2020-12-31 3512
-
国产最强性能CPU!龙芯自研笔记本微边框惊艳亮相2017-04-25 1568
全部0条评论

快来发表一下你的评论吧 !
