

Char数组与String是如何从统一走向分离的?
编程语言及工具
描述
# 前言 #
在很多编程语言中,经常用 String 类型来表示字符串,用 Char 来表示字符类型;在以往的观念中,String 与 Char 数组 (字符数组) 是等价的,但随着计算机的发展以及编程语言的演进,这两者之间好像出现了一些细微的不同。这篇文章将向读者展示,Char 数组与 String 是如何从统一走向分离的。
# 从数数开始 #
先从一个简单的 Python 程序讲起,返回一个字符串的长度。
输入数据如下:
hello world 你好,世界 café
在笔者的环境中结果如下:
Python 3.8.0 (default, Dec 9 2021, 17:53:27)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> len("hello world")
11
>>> len("你好,世界")
5
>>> len("café")
5
>>> len("")
5
>>> len("")
7
按理说,len() 函数应该返回字符串包含的 “字符” 的个数,但是这里的 “字符” 与直觉上好像有一些出入。
| 直觉上的长度 | py3 输出的长度 | 相等与否 | |
|---|---|---|---|
| hello world | 11 | 11 | |
| 你好,世界 | 5 | 5 | |
| café | 4 | 5 | |
| 3 | 5 | ||
| 1 | 7 |
发生什么事了
到底是谁错了?人还是机器?
机器永远是对的。——jyy
py3 输出的长度表示的是什么意思呢?
# 字符类型 #
为了回答前面的问题,我们需要了解一下字符类型,虽然在 Python 中没有独立的字符类型,但其他大多数编程语言中都有单独的字符类型,如 C#,Java,Rust,Julia 中的 Char,以及 Go 中的 rune 和 Swift 中的 Character;虽然都叫字符类型,但是由于一些原因,这些字符类型的实现并不一样,有的是 16 位有的是 32 位 (其原因会在后面说明) 。在比较现代的编程语言中,字符类型的实现多数为 32 位,我们就从 32 位字符类型开始讲起吧。
注: 在后文中出现的 Char 或者是 Char 类型,均指代编程语言中的字符类型,由于 “字符” 一词存在歧义,故选择了 Char 这个词来指代。至于“字符”一词的歧义,也会在后文中展开说明。
32 位字符类型基本都是用来表示 Unicode Scalar Value(Unicode 标量值), 或者说 Unicode 中的 Code Point。
首先, Unicode 是什么呢?——Unicode 标准 (The Unicode Standard) [1],简单说就是一个 “字符表”,一种规则,给每个字符一个编号。
可以类比于 ASCII 码,大写字母 “A” 的编号是十进制的 65。
下方的截图来自于 Unicode 官网 [2],可以看到图中列出了几个字符,每个字符的下方会有一个编号 (如 U+0669,十六进制) ,这个编号就称为 Code Point。
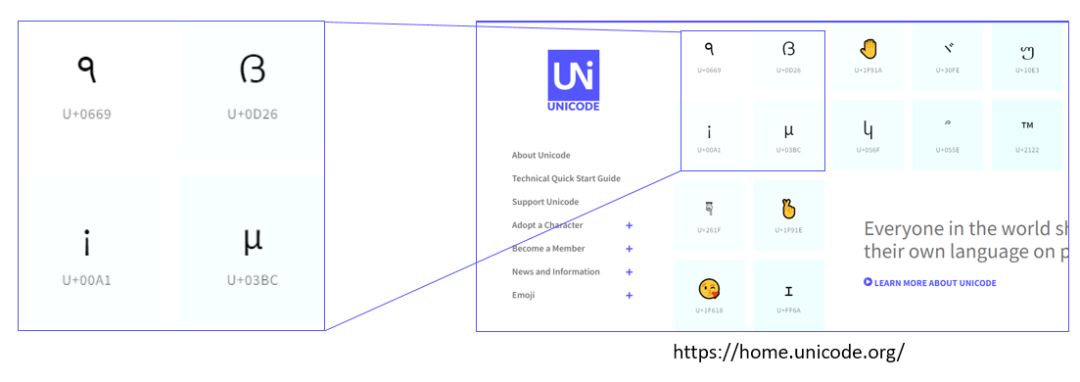
目前 Unicode Code Point 编号达到了 21 位 (二进制) ,所以用 32 位来存储是完全够用的。
32 位字符类型表示的就是这个编号,比如上图中的 U+0669。
# Char == 字符?#
| 直觉上的长度 | py3 输出的长度 | 相等与否 | |
|---|---|---|---|
| hello world | 11 | 11 | |
| 你好,世界 | 5 | 5 | |
| café | 4 | 5 | |
| 3 | 5 | ||
| 1 | 7 |
回到前面字符串长度的表格,现在我们可以回答之前提出的问题了,py3 输出的字符串长度,其含义是字符串中 Unicode Code Point 的个数 (感兴趣的读者可以自己验证,这里就忽略了) 。
再来看左侧的 “直觉上的长度”,为了更准确地讲解,我们引入一个新概念,用户视角的字符 (User-perceived character) ,指符合人类直觉的字符,因为是从直觉的角度出发,没有明确的定义,比如一个“块块”,一个 emoji 表情 。“直觉上的长度” 含义就是 用户视角的字符 的个数。
从这个表格中可以看到,有一些 “字符”,在人类视角是一个 (一个 用户视角的字符) ,但是在计算机的角度是由多个 Unicode Code Point 组成。
很显然,一个用户视角的字符,可能需要多个 Unicode 字符 (Code Point) 来表示。比如这个表示家庭的 emoji,,实际上由七个 Unicode Code Point 组成,但是由前端渲染成了一个 “用户视角的字符”;或者这个 ,由两个 Code Point 组成 (一个 ,外加一个表示肤色的 Code Point) 。
更一般地讲,32 位 Char 类型无法表示全部的用户视角的字符,能表示的有英文、汉字、日语等;不能表示的有法语等小语种、部分组合而成的 emoji 。
不少编程语言中都是用 Char 作为字符类型,久而久之便形成了 “Char == 字符” 这样的假设,潜意识地认为字符类型可以表示任何用户角度的字符,但现在通过上面的几个例子,可以看到 Char 类型与用户视角的字符并不相同。
这里建议读者把 32 位 Char 类型当作表示 Unicode Code Point 的类型,不再使用 “字符” 类型这个词。因为不论 “字符” 还是 “Character”,在计算机中都是含有歧义的词语;比如一个 “字符” 是指 8 位?16 位?还是 32 位?更或是“用户角度的字符”?而这些概念都有对应的指代更为明确的词语。
“Char == 字符” 的时代已经过去了,虽然 Char 依然表示字符类型,但却无法表示很多 “用户视角的字符”,欢迎来到全新的 Unicode 时代~
类比计算机发展早期,比如在 C 语言中,一个 char (8 位) 可以表示 ASCII 字符;但在当今的时代,即使是 32 位的 Char,依然有很多用户视角的字符超出了其表示能力。
小结
很多用户角度的字符已经超出了 Unicode 字符的表示范围,即 32 位 Char 类型的表达能力。
“Char == 字符” 假设,不再成立,或者在一定范围内成立。
字符是一个很容易产生歧义的词,当谈及字符时候一定要小心 (指代不够明确,是用户角度的字符?Char 类型?32 位?16 位?8 位?)。
Char 类型有可能误导使用者,其在部分场景够用,但是更复杂的场景会暴露其不足 (在后面的 Code Point Unaware String 章节会有进一步的讨论) 。
# 走进字符串 #
可以看到,即使是一个用户视角的字符,我们也可能需要一个字符串 (多个 Char 类型) 来表示。
我们对字符串最直观的认识 —— Char 数组,这个直观认识不管从人类直觉还是从计算机发展都是很理所当然的。
从人类直觉来说,字符串,字面意思,“字符” 的 “串”,使用代码来表示,自然而然会想到用 Char 数组。
从笔者个人学习经历来说,笔者学的第一门编程语言是 C 语言,C 语言里面并没有单独的 String 类型,在 C 里面,字符串与 char 数组是等价的。
在一些语言的 String 设计中,这种直觉也是 “行得通” 的,比如 Java、C#、Swift,其字符串的长度都表示 (该语言中) 字符类型的个数,对 String 索引操作得到的也是字符类型。
但如果我们再扩大一下视角,来横向看一下各个编程语言中的 String 类型,我们会发现,“字符串是 Char 数组” 这个概念,好像并不统一。
我们通过各个语言中 String 类型索引和长度的含义,以此来判断其 String 是否为 Char 数组。
索引和长度的含义可能是语言中内置 Char 类型,此时 String 与 Char 数组无异,我们可以像操作数组一样操作 String;
除此之外,索引和长度还可能是指 “字节”,二者的关系 —— 一个 Char 可以由一个多个字节组成 (更具体的关系在后面的编码章节会继续深入),比较的语言和结果如下:
| Swift | Go | Rust | Julia | Java | C# | |
|---|---|---|---|---|---|---|
| String 索引含义 | Character 类型 | byte | byte | byte | Char 类型 | Char 类型 |
| String 是 Char 数组? |
注:这里并不考察 String 与 Char 数组的转换,因为所有语言都支持这种操作。
可以看到,这些语言都做出了不同的选择 (设计) ,设计者到底为什么做出决定,各个语言为何在 string 的概念上不尽相同。
这一切的背后到底是道德的沦丧,还是人性的扭曲。
仔细思考一下这个分类,其实是很粗糙的,同时也存在一些问题的,比如:
不同语言中字符类型相同吗?C 语言中 char 是 8 位,Java 中是 16 位,Rust 中是 32 位,其他语言呢?基于不同的 char 类型比较得出的结论有意义吗?
String 类型的属性依赖于另一个类型?假如改变某一个语言中字符类型的实现,那 String 的属性也跟着变了
为了解释这些疑问,同时为了看到各语言中 String 类型更本质的区别,我们再进一步来看看 String 类型的实现。
# 深入实现之前 —— Unicode 编码 #
在讨论 String 的实现之前,我们先简单讲解一下 Unicode 编码,读者可能之前听到过 UTF-8、UTF-16、UTF-32,这里会尽可能地从 high-level 进行讲解。
首先我们从编码说起,一句话解释,编码就是将 Code Points 转化成二进制字节的过程;
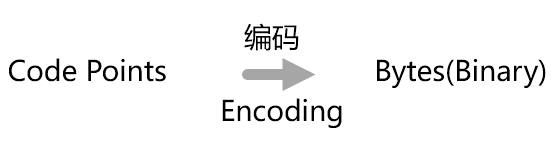
依然从老朋友 ASCII 码讲起,对于 ASCII 码而言,编码只有一种,直接将编号换算 (进制转换) 成二进制 (或者十六进制) 即可;
如:大写字母 “A” 的编号 65,编码后就是 0x41。
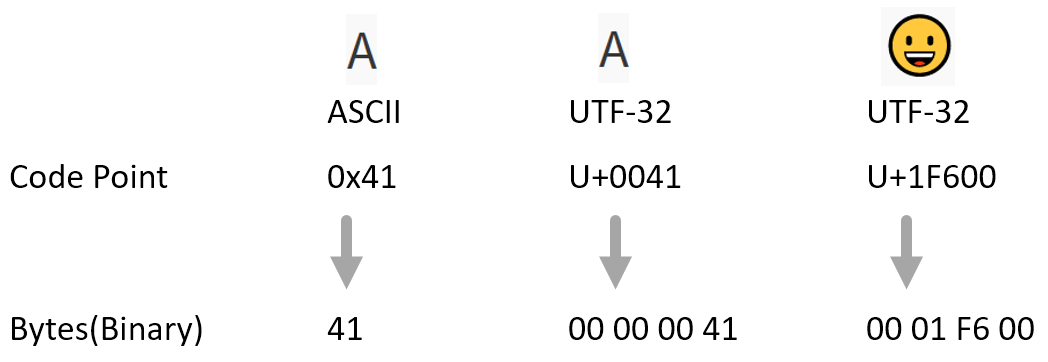
基于这种直接进制转换的思想,我们便得到了名为 UTF-32 的编码方式 —— 直接将 Unicode Code Point 转换成 32 位的二进制字节即可;
如下图中的 A 和 ,分别换算成 00 00 00 41 和 00 01 F6 00,
这种编码方式的缺点很明显 —— 浪费空间,对于常用的小编号 Code Point (字母和数字,在 ASCII 字符集内的字符) ,会存在前导零,这些前导零会浪费空间。
为了解决 UTF-32 浪费空间的前导零,便有了变长编码 —— UTF-8。
读者只需要理解两种编码的由来和特点即可,至于如何具体编码,这篇文章不会包含这部分内容。
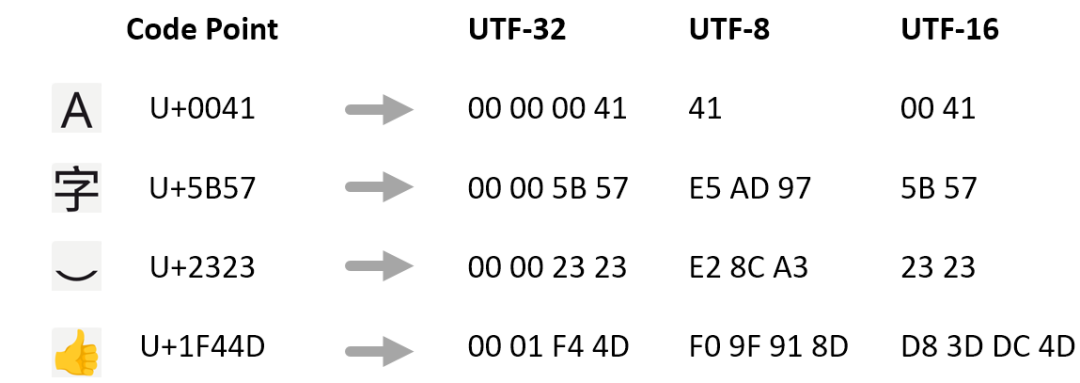
在上图中可以看到,Code Point 经过 UTF-8 编码得到的字节从一个到四个不等。
再引入一个概念——Code Unit (编码单元) ,指的是编码后的基本单元的长度,UTF-32 的编码单元是 32 位,4 个字节,编码名称中的 32 指的就是编码单元的长度;
UTF-8 同理,编码后的基本单元长度是 8 位,一个字节。
关于 UTF-16,从现在的角度来看,既有前导零浪费空间的问题 (下图中的 A 字符) ,又是变长编码 (变长编码的缺点在后面会讨论到) ,
这东西可以说完全是 “时代的眼泪”,UTF-16 的设计初衷是 “定长编码”,因为早期的 Unicode 标准犯了一个历史错误——过早承诺了 Code Point 可以用 16 位存下。
但随着 Unicode 标准的演进,最初的设计优点 (定长编码) 不复存在,成了只留下了缺点 (浪费空间和变长) 的编码方案。
虽然不在本文的关注范围内,但是如果遇到文本乱码,那基本上是编码问题了。
你无法在不知道编码的情况下解决乱码的问题。
没有编码的字符串,毫无意义!——马主任
在了解了 Unicode 和相关编码之后,再来回头看一下各种语言的 Char 和 String 类型的实现:
| Swift | Go | Rust | Julia | Java | C# | |
|---|---|---|---|---|---|---|
| String 实现编码 | UTF-16 -> UTF-8 | UTF-8 | UTF-8 | UTF-8 | UTF-16 | UTF-16 |
| String 索引含义 | Character 类型 | byte | byte | byte | Char 类型 | Char 类型 |
| 字符类型 | User-perceived character | 32 位 | 32 位 | 32 位 | 16 位 | 16 位 |
| 字符类型是用户角度的字符? | ||||||
| String 是编码单元数组? |
可以很明显的看到,首先是 String 类型实现上的不同——有的语言采用了 UTF-8 编码,有的采用了 UTF-16。
其次,连 Char 类型的实现也不一样,Swift 中的 Character 类型,其抽象程度是最高的,可以直接用来表示用户角度的字符;比如需要 7 个 Code Point 才能表示的一家子 ,在 Swift 中完全可以用一个 Character 类型的变量存下。
其它语言中的 Char 类型有 32 位的也有 16 位的,这两种实现中只有 32 位的 Char 可以表示 Unicode Code Point,而 16 位 Char 甚至连一个 Code Point 都无法表示,要知道,Code Point 可是 Unicode 标准中最小的带有语义的单元。
编程语言中各不相同的 String 和 Char 类型的设计,是否存在统一的视角进行解读?
# String 类型的历史变迁 #
下面,从计算机发展的角度来理解一下各语言的设计初衷。
# ASCII 码, C 语言
计算机早期处理的自然语言字符很有限,使用 ASCII 编码就能装下,对于字符串和字符的概念也没有明确的区分。
比如在 C 语言中,使用 8 位的 Char 类型表示 ASCII 字符,而字符串也自然而然地使用了 char 数组。
从这里开始慢慢诞生了一个假设或者说是潜意识的习惯 —— “一个 Char 表示一个字符”,很显然,这里需要限定是 8 位 Char 和 ASCII 码字符。
# Unicode, UTF-16,Java 和 C#
随着计算机的发展,出现了 Unicode 来统一人类的语言的编码,但是早期的 Unicode 犯了一个 历史性错误——承诺 Unicode 字符可以用 16 位存下。
与此同时第一批支持 Unicode 的 Java 和 windows 都成了受害者——选择了 UTF-16 编码,但这个编码延续了以前的“习惯” —— “一个 Char 依然能表示一个字符”,只不过这里的 Char 变成了 16 位,字符变成了早期 Unicode 字符集里的字符。
这个时期的编程语言里也出现了独立的数据类型 String 来表示字符串,幸运的是,在 UTF-16 编码下,String 依然可以视作 Char 数组,因为 UTF-16 编码中每个编码单元都是 16 位,这些语言中的 Char 也从以前语言中的 8 位变成了 16 位。
# Unicode,UTF-8 和最近的编程语言
随着 Unicode 的进一步发展,标准内的字符集已经无法用 16 位装下了,需要 32 位才能表示一个 Unicode 编码的字符。
甚至还出现了一些组合字符或者修饰字符,甚至有些自然语言里无法清晰地定义 “字符” 这个概念。
这时候即使是能够表示 Unicode 编码字符的 32 位 Char,也不能表示用户角度的字符了。
此时上述“习惯” —— “Char == 字符”已经不成立了,与此同时出现了 UTF-8 的编码方式,该编码方式被大量的网站和协议,工具等采用,采用 UTF-16 实现 String 的编程语言开始产生新的问题:
虽然 String 依然是 Char 数组,但这里的 16 位 Char 表示能力已经远低于后面语言中的 32 位 Char 了,甚至一些汉字和 emoji 需要两个 16 位 Char 才可以表示。
丢弃假设“Char == 字符”,String 不再视作 Char 数组,如 Go、Rust、Julia。这些语言中,不存在 String 到 Char 的抽象开销,由此带来了高效的字符串处理效率,但是需要用户先打破自己对字符串的传统认知
# String 类型的设计与性能 #
说完了比较 high-level,比较抽象的设计层面,我们再来关注一下更具体的东西——性能,看看 String 的设计与性能会存在什么样的联系。
首先补充两个背景知识:
UTF-8 已成为事实上的标准。
变长编码带来的 Code Point 抽象层开销。
这两条背景知识刚好对应着 String 性能的两个维度——外部和内部:
String 外部的性能 (与其他库或者接口操作) ,String 实现采用非 UTF-8 编码时,会在 String 编解码时产生开销 (如 Java 和 C#) 。
String 内部的性能 (自身操作) ,比如查找,切片等操作,String 抽象成非 “编码单元” 数组时,由于多了一层抽象层 (编码索引和字符索引之间的转换) ,在 String 自身操作时会产生性能问题 (如 Swift) 。
举例说明 UTF-8 变长编码索引 Code Point 时的性能开销:

比如,如果我们想得到汉字“阳”的字符类型索引,由于前面的字符 (字母标点和汉字) 对应的编码字节都是不确定的,所以需要从头开始计算,这样一个 O(N) 的操作对于字符串这种准基本类型代价是很高的。
再来定性分析一下各语言 String 类型的性能:
| Swift | Go | Rust | Julia | Java | C# | |
|---|---|---|---|---|---|---|
| String 是编码单元数组? | ||||||
| 字符串操作开销 | 有 | 无 | 无 | 无 | 无 | 无 |
| String 实现编码 | UTF-8 | UTF-8 | UTF-8 | UTF-8 | UTF-16 | UTF-16 |
| API 间编解码开销 | 无 | 无 | 无 | 无 | 有 | 有 |
继续具体地看一下各个语言的 String 类型:
Swift
该语言中的 Character 抽象能力最强,可以表示用户角度的字符,其 String 类型的长度也是符合人类直觉的 “字符串” 的长度;但是由于 Character 这层抽象层,不仅在使用上带来不便,为什么 Swift 的 String 这么难用 [3],性能也会受影响,Swift String 性能问题) [4]。
Java
在 Java 18 中,各种 API 已经默认使用了 UTF-8 编码,但是使用 UTF-16 实现的 String 不可避免的会产生编解码的开销;与此同时,由于 16 位 Char 表达能力的缺陷,在 String 类型的 API 中除了 Char 相关的,也有 Code Point 相关的,如 CharAt (int index) [5] 和 codePointAt (int index) [6]。
C#
不光有 16 位的 Char 类型,还有 32 位的 Rune 类型。
(一点吐槽,Java 设计 UTF-16 String 是由于 Unicode 标准的历史错误,但是 C# 的时期是可以避免这点的,为什么也栽了跟头呢?)
虽然 C# String 实现和微软自家生态都是基于 UTF-16,但微软官方也在提倡采用 UTF-8 编码,Use the Windows UTF-8 code page [7]。
Go,Rust,Julia
基于 UTF-8 编码,无额外抽象层的 String 类型,在性能上看不到明显短板,唯一可能让人感到违背直觉的——无法按照 char 来操作,接下来我们就来讲解一下。
# Code Point Unaware String #
比较现代的语言都选择了 UTF-8 实现的 string,性能上可以看到两方面都没有劣势,唯一可能让人感到违背直觉的——无法按照 char 来操作,更准确的说法是,Code Point Unaware String,在网上也可以经常看到一些讨论,如 what if strings were Code Point aware? [8] on Rust,Indexing strings by Unicode code point instead of code unit? [9] on Julia。
那么这个设计的初衷是什么呢,即使不去设计编程语言,作为语言 (库) 的使用者又该如何理解呢?
首先,从实现的角度来说,变长的 UTF-8 编码不适合 “直接” 抽象成 Code Point 数组 (可以参考 Swift 的抽象层导致的性能问题) ;
其次,在当今的软件中,索引 Code Point 并不像大家直觉中那么重要,绝大部分场景 Code Point 都不能满足需求。
从实际的应用软件角度来考虑:
鼠标移动和选定——从上面的例子可以发现,用户角度的字符并不是由 Char 一一对应的,在这种情况下,使用到的基本单位是字素 (grapheme)
文本查找和替换的场景——类似下方背景中性能问题提到的例子,需要先通过遍历或者搜索得到字符串的位置,再通过这个位置来操作,而这个位置是字节还是 Code Point 的并不会影响功能,但是会影响性能 (后者需要额外的计算)
限制长度的场景——如输入字符串,协议传输,数据库等;更关心字符串编码后的长度,即字节数,使用到的基本单位是 (code unit)
在屏幕上渲染 “字符”——同样地,与 Char 无关,一个 Char 占据多少列是不确定的,需要由渲染引擎决
最后一点,不是那么明显但是影响深远,Code Point 这层抽象不是一个 “正确” 的抽象。 Code Point 在简单的场景中使用看起来不会有问题,但一旦问题变复杂,程序员可能意识不到是编程语言的数据类型的问题;Code Point 作为一个不准确的抽象,如果仅指望通过它来进行简化,无异于掩盖 Unicode 的复杂性,而这种行为反倒会埋下潜在的隐患。
由此可见,该抽象层可能会误导程序员,掩盖了所处理问题的复杂性。 # 总结 # 从编程语言的历史演进中可以看到,String 可以说是始于 Char 数组,但随着处理问题越来越复杂 (源于人类语言的复杂性) ,在一些现代语言中,String 已经不再作为 Char 数组,而是独立成单独的类型;出于不同的目的或者是原因,各个编程语言中的字符类型和 String 类型也存在着这样或那样的差异。
审核编辑:刘清
-
深入探索KUKA KRL中的数组应用2024-04-18 2690
-
C++字符串string2023-07-10 3923
-
如何使用String从flash复制char数组?2023-05-08 345
-
ESP-NOW如何传输String或 'char *' 变量?2023-02-21 361
-
C语言中的char数组和char指针有什么区别?2023-01-29 3898
-
char和string在西门子PLC中的格式2022-07-07 18656
-
S71200:char和string的定义2022-04-01 9975
-
字符串与字符数组的转换字符数组介绍2022-01-12 1734
-
MCU_C语言中 数组型指针 的应用 -- char (*stringp)[]2021-11-29 680
-
string类字符串和char*/char[]型型字符串的区别 相关资料分享2021-07-05 1982
-
为什么C语言函数不能返回数组?2021-03-29 2849
-
char *和char数组的区别及内核访问用户区2019-04-02 3478
-
应该用0终止char数组吗?2018-12-04 1275
-
在Labivew里字符串(String)转为为字符(Char)数组。2016-09-29 5118
全部0条评论

快来发表一下你的评论吧 !
