

SAS:数据集的横向合并(二)
电子说
描述
前面我们介绍了在data step中用merge的方法可以对数据集横向合并,这节我们来讲讲在procedure过程步中用proc sql的方法对数据集进行横向连接,proc sql的功能十分强大,一般在data step中能实现的同样在proc sql中也可以实现,而且在很多时候, Proc步要更胜一筹。proc sql语句中的横向连接主要有左连接、右连接、内部连接、完全连接这几种情况。下面我将详细介绍:
一、最简单的join——笛卡尔积
不指定where选择子集,则会生成一个最基本的笛卡尔积,即包括两个表所有可能的join。
data one;
input x a$;
cards;
1 a
2 b
4 d
;
run;
data two;
input x b$;
cards;
2 x
3 y
5 v
;
run;
proc sql;
create table three1 as
select *
from one,two;
quit;
/ 结果如下: /
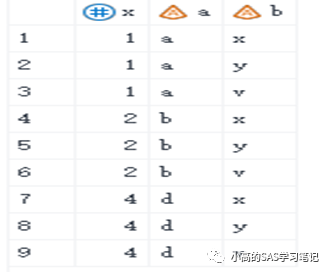
有这个过程后,就能完全了解一对多,多对多,多对一连接后的结果了,反正全部都是先进行一次所有行的笛卡尔积的生成,然后再按条件进行筛选。
二、内连接
(1)内连接只会对两表中基于准则的行进行组合和显示。在内连接中,where从句是限制在笛卡尔输出集中显示的行的数量。
proc sql;
select one.x, a, b
from one, two
where one.x = two.x;
quit;
/ 结果如下: /

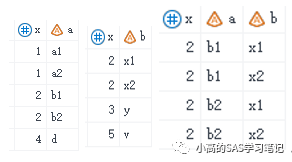
(2)在标准内连接中,出现两个表都含有重复的值的情况,内连接会对所有满足条件的观测行进行一一对应的笛卡尔积
proc sql;
create table three3 as
select *
from three, four
where three.x = four.x;
quit;
/ 结果如下: /
三、外连接
外连接是内连接的一个augmentation,除了交的部分,还含有并的某些或全部
(1) 左连接(左表变量顺序保持不变 )
左连接会将所有满足ON条件的行进行连接,并会额外加上左表中所有不满足条件的行。未满足条件的右表的行被置为缺失值。
proc sql;
create table three4 as
select *
from one left join two
on one.x = two.x;
quit;
/ 结果如下: /

(2)右连接(右表变量顺序保持不变 )
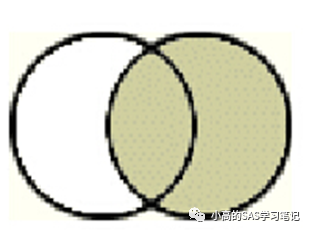
右连接会将所有满足ON条件的行进行连接,并会额外加上左表中所有不满足条件的行。
proc sql;
create table three5 as
select *
from one right join two
on one.x = two.x;
quit;
/ 结果如下: /

(3)全连接
全连接会把所有满足和不满足条件的行全部列出来,如果要得出和merge一样的效果,需要加入coalesce函数
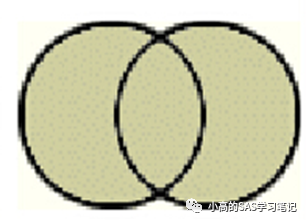
COALESCE(argument-1<..., argument-n>) 这个函数也可以对left和right/join用,但是只能得出left或right的结果
例1:不使用coalesce
proc sql;
create table three6 as
select *
from one full join two
on one.x = two.x;
quit;
/ 结果如下: /
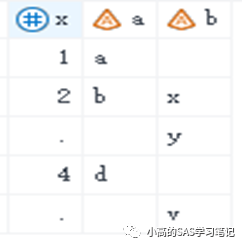
例2:使用coalesce
proc sql;
create table three7 as
select coalesce(one.x,two.x) as x,a,b
from one full join two
on one.x=two.x;
quit;
/ 结果如下: /
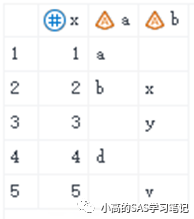
四、Merge/Join的联系与区别
(1)一对一
data one;
input x a$;
cards;
1 a
2 b
4 d
;
run;
data two;
input x b$;
cards;
2 x
3 y
5 v
;
run;
data merged1;
merge one two;
by x;
run;

proc sql;
create table merged2 as
select coalesce(one.x, two.x) as X, a, b
from one full join two
on one.x = two.x;
quit;
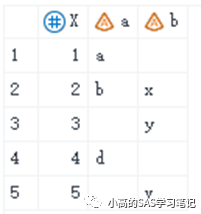
当是处于一对一的情况时,merge a b;by x;相当于SQL的full join:即a full join b on a.x=b.x;
(2)一对多或多对一
data three;
input x a$;
cards;
1 a1
1 a2
2 b1
4 d
;
run;
data four;
input x b$;
cards;
2 x1
2 x2
2 x3
3 y
5 v
;
run;
data merged1;
merge three four;
by x;
run;
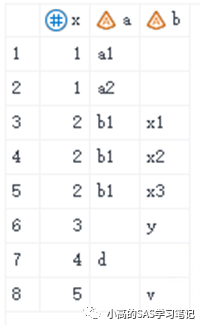
/ 结果如下: /
proc sql;
create table merged2 as
select coalesce(three.x, four.x) as x, a, b
from three full join four
on three.x = four.x;
quit;
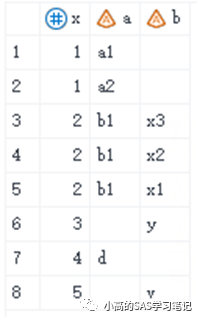
当是处于一对多或多对一的情况时,merge a b;by x;相当于SQL的full join:即a full join b on a.x=b.x on a.x=b.x;
(3)多对多
data five;
input x a$;
cards;
1 a1
1 a2
2 b1
2 b2
4 d
;
run;
data six;
input x b$;
cards;
2 x1
2 x2
2 x3
3 y
5 v
;
run;
data merged1;
merge five four;
by x;
run;
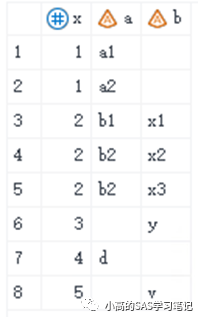
/ 结果如下: /
proc sql;
create table merged2 as
select coalesce(five.x, six.x) as x, a, b
from five full join six
on five.x = six.x;
quit;
/ 结果如下: /
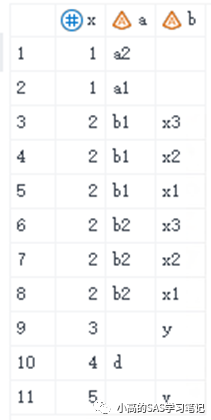
当是多对多的情况时,merge a b;by x;与 SQL的full join会产生不同的结果。
**总结:
**
1.一对一或一对多(多对一)合并
(1)merge a b;by x;相当于SQL的full join:即a full join b on a.x=b.x;
(2)merge a(in=ina) b(in=inb);by x;if ina;相当于sql的左连接 a left join b on a.x=b.x;
(3)merge a(in=ina) b(in=inb);by x;if ina and inb;相当于SQL的内连接:a inner join b on a.x=b.x;
2.多对多合并
两者区别较大,merge只取A.x与B.x的并集,即AUB;而SQL则取两者的笛卡尔乘积数即A.x的数量*B.x的数量。
- 相关推荐
- 热点推荐
- SQL
-
Yonghong Desktop端Excel 数据集的优化2023-09-08 1240
-
SAS-2集成RAID配置实用程序用户指南2023-08-10 703
-
SAS-3集成式磁盘阵列解决方案用户指南2023-08-04 945
-
SAS:数据集的横向合并(一)2023-05-19 6194
-
5个必须知道的Pandas数据合并技巧2022-04-13 3262
-
SAS接口的设计2021-09-09 1752
-
SAS硬盘有什么特点?2019-09-24 2875
-
SAS固态硬盘存储技术2019-06-18 3972
-
一种大数据的密度统计合并算法2018-01-21 554
-
结构粒化的数据合并2018-01-17 537
-
数据表文件读取及数组合并2013-10-14 5061
-
SAS分区规范为所有SAS物理结构提供灵活高效的接入控制,其特性包括2011-06-02 2533
-
SAS走进企业级存储应用2009-11-13 5038
全部0条评论

快来发表一下你的评论吧 !
