

SAS:length,klength,substr,ksubstr,ksubstrb的区别
电子说
描述
我们经常会看到Klength,Ksubstr,以及Kscan等一系列的函数,由此会产生疑惑,加K和不加K两者之间有什么区别和联系。当我们在做项目的时候发现有时候不加K也能实现我们想要得到的结果,但是有时候则会出现乱码的情况,尝试加上K后就可以完美规避掉乱码这个问题,为什么会出现这样的问题呢?本文告诉你答案。
原来加K是以字符为基础进行处理,也就是你数字符串中有几个字符就是几个字符,而不加K是以字节为基础进行处理。我们知道在SAS中文简体中一个汉字(标点)占两个字节,一个数字占一个字节;在SAS UTF-8中一个汉字(标点)占三个字节,数字占一个字节,但是SAS 英文版字符和数字都占一个字节,所以在此环境下Klength和Length、Substr和Ksubstr的功能是一样的,下面我举三个例子,以UTF-8为例:
一、klength和length
例1:计算test数据集中topic这个字符变量的长度
data test;
input topic $20.;
cards;
话题Topic 1
话题Topic 2
话题Topic 3
话题Topic 4
话题Topic 5
;
run;
data all1;
set test;
topic1=klength(topic);
topic2=length(topic);
run;
结果如下:
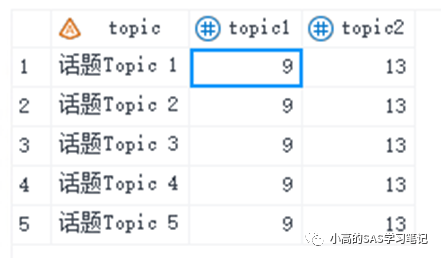
可以看到,由于中文字符在utf-8编码时为3个字节, 而length函数计算的是字节长度,会把一个汉字当成3个长度,数字当做1个长度,所以计算结果为2*3+7=13。而klength函数会忽略全角半角,统一把汉字和数字都当做1个长度,所以计算结果为9。
二、ksubstr和substr
例2:提取test数据集中topic中前六位的值
data all2;
set test;
topic1=substr(topic,1,6);
topic2=ksubstr(topic,1,6);
run;
结果如下:

可以看到,substr提取出的字符串为“话题”, 而ksubstr提取出了前六个字符”话题Topi”,所以还是和上面的例子是一个道理,以K开头的是以字符为基础提取字符串,而不以K开头的以字节为基础提取,但是有时我们会遇到用substr提取出的字符串出现乱码的情况,出现这种情况后要怎样解决呢,看下面一个例子。
三、substr和ksubstrb
例3:提取test数据集中topic中前5位的字符串
data all3;
set test;
topic1=substr(topic,1,5);
topic2=ksubstr(topic,1,5);
topic3=ksubstrb(topic,1,5);
run;
结果如下:

可以看到,用substr提取出的字符串出现了乱码,这是因为substr函数提取字符时是按字节来提取的,中文字符在utf-8编码时为3个字节,所以提取指定长度的字符串时如果截断了汉字,那么返回的结果显示出来便会出现乱码。此时用ksubstrb函数就可以避免出现乱码的情况,它会舍弃最后一个不完整字符,从而保证不会出现显示上的乱码。
-
oracle中substr函数用法2023-12-05 2969
-
Power-Optimized Avago 12Gb/s SAS/SATA SAS35x48 SAS35x40 SAS35x36扩展器2023-08-14 824
-
#硬声创作季 云计算基础入门:12-scsi及sas接口-sas和sata区别Mr_haohao 2022-10-16
-
请问什么是SAS硬盘?具有哪些特点?2021-11-04 2033
-
SAS接口的设计2021-09-09 1752
-
PCIExpress SATA和SAS设计验证的简化2019-11-05 1443
-
Altium中Signal length和Routed length区别2019-10-18 10213
-
SAS硬盘有什么特点?2019-09-24 2875
-
SAS3X24R SAS EXPANDER 使用24端口扩展器实现经济高效的SAS和SATA存储解决方案2019-07-04 835
-
SAS固态硬盘存储技术2019-06-18 3972
-
AD中signal length和routed length中有什么区别2018-05-18 10385
-
SAS分区规范为所有SAS物理结构提供灵活高效的接入控制,其特性包括2011-06-02 2533
-
SAS走进企业级存储应用2009-11-13 5038
全部0条评论

快来发表一下你的评论吧 !
