

当我们在谈论cpu指令乱序的时候,究竟在谈论什么?
电子说
描述
很多现代高级语言多提供了多线程并发技术,今天服务器CPU基本上都是多核架构,在Java中,JVM能够根据处理器特性(CPU多级缓存系统、多核处理器等)适当对机器指令进行重排序,最大限度发挥机器性能。Java中的指令重排有两次,第一次发生在将字节码编译成机器码的阶段,第二次发生在CPU执行的时候,也会适当对指令进行重排。
写这篇文章的目的,是想明确下cpu指令乱序这件事。只要是熟悉计算机底层系统的同学就会知道,程序里面的每行代码的执行顺序,有可能会被编译器和cpu根据某种策略,给打乱掉,目的是为了性能的提升,让指令的执行能够尽可能的并行起来。
知道指令的乱序策略很重要,原因是这样我们就能够通过barrier(内存屏障)等指令,在正确的位置告诉cpu或者是编译器,这里我可以接受乱序,那里我不能接受乱序等等。从而,能够在保证代码正确性的前提下,最大限度地发挥机器的性能。
10多年前的程序员对处理器乱序执行和内存屏障应该是很熟悉的,但随着计算机技术突飞猛进的发展,我们离底层原理越来越远,这并不是一件坏事,但在有些情况下了解一些底层原理有助于我们更好的工作,比如现代高级语言多提供了多线程并发技术,如果不深入下来,那么有些由多线程造成问题就很难排查和理解。
前言
这里我不打算讨论编译器的乱序策略,这里讨论的指令乱序,含义稍广些,包括在多核上分别执行的指令间,在时间维度上的乱序。
如果在多核cpu层面考虑乱序执行的话,我们要来梳理清楚以下几个概念:单核和多核,乱序执行和顺序提交,store buffer和invalid queue。最后会对x86和arm/power架构的异同,做一个总结。
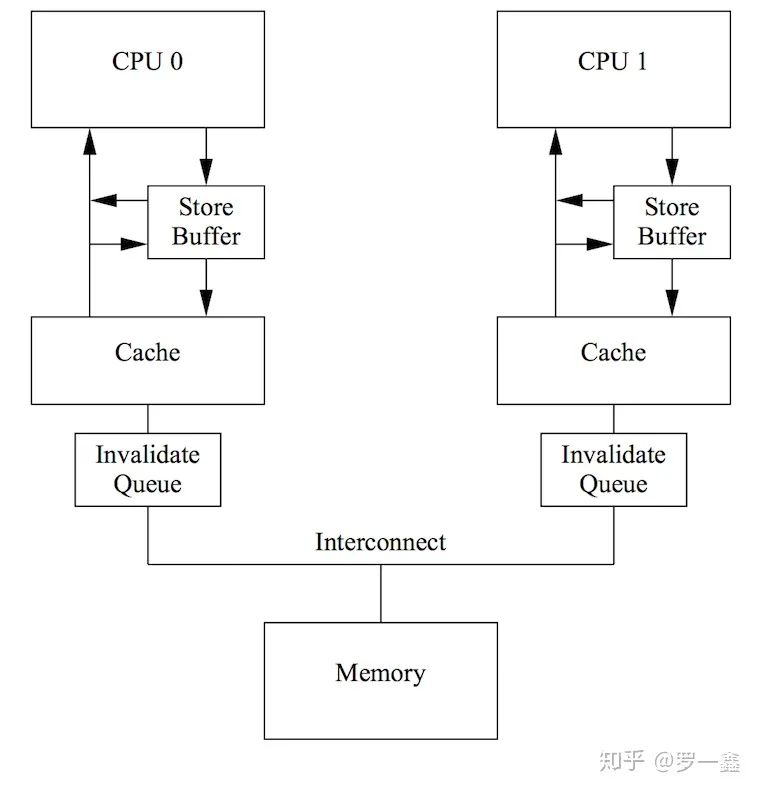
单核 vs 多核
从多核的视角上来说,是存在着乱序的可能的。比如,假设存在变量x = 0,cpu0上执行写入W0(x, 1),对x写入1。接着在cpu1上,执行读取R1(x, 0),得到x = 0,这在x86和arm/power的cpu上都是可能出现的。原因是x86上cpu核和cache以及内存之间,存在着store buffer,当W0(x, 1)执行成功后,修改只存在于store buffer中,并未写到cache以及内存上,因此cpu1读取不到最新的x值。对于arm/power来说,同样也有store buffer,而且还可能会有invalid queue,导致cpu1读不到最新的x值。
对于没有invalid queue的x86系列cpu来说,当修改从store buffer刷入cache时,就能够保证在其他核上能够读到最新的修改。但是,对于存在invalid queue的cpu来说,则不一定。
为了能够保证多核之间的修改的可见性,我们在写程序的时候需要加上内存屏障,例如x86上的mfence指令。
乱序执行 vs 顺序提交
我们知道,在cpu中为了能够让指令的执行尽可能地并行起来,从而发明了流水线技术。但是如果两条指令的前后存在依赖关系,比如数据依赖,控制依赖等,此时后一条语句就必需等到前一条指令完成后,才能开始。
cpu为了提高流水线的运行效率,会做出比如:
1)对无依赖的前后指令做适当的乱序和调度;
2)对控制依赖的指令做分支预测;
3)对读取内存等的耗时操作,做提前预读;
等等。以上总总,都会导致指令乱序的可能。
但是对于x86的cpu来说,在单核视角上,其实它做出了Sequential consistency[1]的一致性保障。Sequential consistency的在wiki上的定义如下:
"... the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program."
也就是说,要满足Sequential consistency,必需保障每个处理器的指令执行顺序必需和程序给出的顺序一致。奇怪吧?这不就和我刚才说的指令乱序优化矛盾了嘛?其实并不矛盾,指令在cpu核内部确实是乱序执行和调度的,但是它们对外表现却是顺序提交的。
如果把ISA寄存器(如EAX,EBX等)和store buffer,作为cpu对外的接口的话,cpu只需要把内部真实的物理寄存器按照指令的执行顺序,顺序映射到ISA寄存器上,也就是cpu只要将结果顺序地提交到ISA寄存器,就可以保证Sequential consistency。
当然,以上是对x86架构的cpu来说的,ARM/Power架构的cpu在单核上的一致性保证要弱一些,无需保证Sequential consistency,因此也不需要顺序提交,只需保证控制依赖,数据依赖,地址依赖等指令的顺序即可。要想在这些弱一致性模型cpu下保证无关指令间的提交顺序,需要使用barrier指令。
Store Buffer & Invalid Queue
store buffer存在于cpu核与cache之间,对于x86架构来说,store buffer是FIFO,因此不会存在乱序,写入顺序就是刷入cache的顺序。但是对于ARM/Power架构来说,store buffer并未保证FIFO,因此先写入store buffer的数据,是有可能比后写入store buffer的数据晚刷入cache的。从这点上来说,store buffer的存在会让ARM/Power架构出现乱序的可能。store barrier存在的意义就是将store buffer中的数据,刷入cache。
在某些cpu中,存在invalid queue。invalid queue用于缓存cache line的失效消息,也就是说,当cpu0写入W0(x, 1),并从store buffer将修改刷入cache,此时cpu1读取R1(x, 0)仍是允许的。因为使cache line失效的消息被缓冲在了invalid queue中,还未被应用到cache line上。这也是一种会使得指令乱序的可能。load barrier存在的意义就是将invalid queue缓冲刷新。
X86 vs ARM/Power
对于x86架构的cpu来说,在单核上来看,其保证了Sequential consistency,因此对于开发者,我们可以完全不用担心单核上的乱序优化会给我们的程序带来正确性问题。在多核上来看,其保证了x86-tso模型,使用mfence就可以将store buffer中的数据,写入到cache中。而且,由于x86架构下,store buffer是FIFO的和不存在invalid queue,mfence能够保证多核间的数据可见性,以及顺序性。[2]
对于arm和power架构的cpu来说,编程就变得危险多了。除了存在数据依赖,控制依赖以及地址依赖等的前后指令不能被乱序之外,其余指令间都有可能存在乱序。而且,它们的store buffer并不是FIFO的,而且还可能存在invalid queue,这些也同样让并发编程变得困难重重。因此需要引入不同类型的barrier来完成不同的需求。[3]
总结
从上面的介绍可以知道,开发者想要做好并发编程是多么困难的事情,但是我们至少跨出了第一步,也就是定义困难本身。
审核编辑 :李倩
-
当我们谈论“工业网关”时,到底在谈论什么?2026-06-08 739
-
谈论MCU上运行什么样的应用2021-12-22 2833
-
我们在谈论音质的时候在谈论什么资料下载2021-04-25 1375
-
每个人都在谈论的物联网究竟在哪里2019-02-14 3400
-
科技巨头扎堆AIoT,华为、小米究竟看到了什么?2019-01-27 1430
-
我们是不是要信任智慧城市?2018-06-25 3950
-
我们的生活与大数据关联在一起,确保信息安全极为重要2018-06-20 1883
-
关于智慧银行,我们都在谈论着什么?2016-07-01 5238
全部0条评论

快来发表一下你的评论吧 !
