

FPGA常用运算模块-复数乘法器
描述
写在前面
本文是本系列的第五篇,本文主要介绍FPGA常用运算模块-复数乘法器,xilinx提供了相关的IP以便于用户进行开发使用。
复数乘法器
复数乘法器IP基于用户指定的选项实现了符合 AXI4-Stream 的高性能、优化的复数乘法器。两个被乘数输入和可选的舍入位在独立的 AXI4-Stream 通道上作为从接口输入,结果乘积在 AXI4-Stream 主接口上输出。在每个通道内,操作数和结果以带符号的二进制补码格式表示。操作数宽度和结果宽度是可参数化的。
特点
复数乘法器在许多 DSP 应用中很常见,包括信号混合和快速傅立叶变换。Complex Multiplier IP以笛卡尔形式执行两个操作数的复数乘法。结果也是笛卡尔形式。
8 位至 63 位输入精度和高达 127 位输出精度。
支持截断或无偏舍入。
可配置的最小延迟。
实施选项包括 3 乘法器、4 乘法器和专用原语解决方案。
使用 LUT 或 DSP Slices 的选项。
复数计算方法
给定两个操作数,有两种基本架构来实现复数乘法:
a表示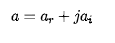
b表示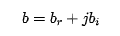
然后得到输出结果为: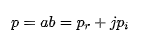
所以直接实现需要四个实数乘法: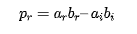
和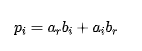
通过整理添加项得到下面的式子:
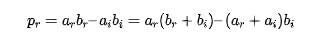
和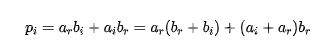
可以设计一种三实乘法器解决方案,将一个乘法器换成三个预组合加法器并增加乘法器字长。
延迟和吞吐量
延迟是可配置的。对于性能表,延迟设置为自动,从而形成完全流水线化的电路。Complex Multiplier 支持所有配置中的全吞吐量,即每个周期一个输出。
IP核图示和端口描述
复数乘法器IP核如下图所示:

| Name | I/O | Optional | Description |
|---|---|---|---|
| aclk | I | Yes | 上升沿时钟。 aclk 信号是可选的。当 FlowControl 为 NonBlocking 且 MinimumLatency = 0 时,它不存在。 |
| aclken | I | Yes | 高电平有效时钟使能(可选) |
| aresetn | I | Yes | Active-Low 同步清零(可选,总是优先于 aclken)aresetn 应该被置位或取消置位不少于两个 aclk 周期。 |
| s_axis_a_tvalid | I | No | 通道 A 的 TVALID。 |
| s_axis_a_tready | O | Yes | 通道 A 的TREADY。 |
| s_axis_a_tuser[A-1:0] | I | Yes | 通道 A 的 TUSER。宽度从 1 到 256 位可选。 |
| s_axis_a_tdata[B-1:0] | I | No | 通道 A 的 TDATA。 |
| s_axis_a_tlast | I | Yes | 通道 A 的 TLAST。 |
| s_axis_b_tvalid | I | No | 通道 B 的 TVALID。 |
| s_axis_b_tready | O | Yes | 通道 B 的 TREADY。 |
| s_axis_b_tuser[C-1:0] | I | Yes | 通道 B 的 TUSER。宽度从 1 到 256 位可选。 |
| s_axis_b_tdata[D-1:0] | I | No | 通道 B 的 TDATA。 |
| s_axis_b_tlast | I | Yes | 通道 B 的 TLAST。 |
| s_axis_ctrl_tvalid | I | Yes | 通道 CTRL 的 TVALID。 |
| s_axis_ctrl_tready | O | Yes | 通道 CTRL 的 TREADY。 |
| s_axis_ctrl_tuser[E-1:0] | I | Yes | 通道 CTRL 的 TUSER。宽度从 1 到 256 位可选。 |
| s_axis_ctrl_tdata[7:0] | I | Yes | 通道 CTRL 的 TDATA。 |
| s_axis_ctrl_tlast | I | Yes | 通道 CTRL 的 TLAST。 |
| m_axis_dout_tvalid | O | No | 通道 DOUT 的 TVALID。 |
| m_axis_dout_tready | I | Yes | 通道 DOUT 的 TREADY。 |
| m_axis_dout_tuser[G-1:0] | O | Yes | TUSER表示通道DOUT。Width是输入通道上启用的TUSER字段的总和。 |
| m_axis_dout_tdata[H-1:0] | O | No | 通道DOUT的TDATA。 |
| m_axis_dout_tlast | O | Yes | 通道DOUT的TLAST。 |
宽度常数A到H是任意变量,由GUI或配置参数决定。
硬件实现方式
Three Real Multiplier Solution
三实数乘法器的实现利用了DSP片中的预加器,节省了一般结构资源 。通常,三乘法器解决方案比四乘法器解决方案使用更多的片资源(LUT/触发器),并且具有更低的最大可实现时钟频率 。
Four Real Multiplier Solution
四实数乘法器方案最大限度地利用了DSP片资源,并且比三实数乘法器方案具有更高的时钟频率性能,在许多情况下达到了FPGA的最大时钟频率。
它仍然会消耗用于流水操作平衡的切片资源,但该切片成本始终低于等效三实数乘法器解决方案所需的成本。
Dedicated Primitive Solution
具有专用的DSPCPLX原语设备,能够使用两个DSP片的等效物执行完全的复数乘法。与3倍增或4倍增解决方案相比,此解决方案使用的资源更少,延迟更低。无需特殊选择 ;当配置允许时,系统会自动使用此解决方案。
您可以设置特定的延迟值:将延迟配置设置为手动,然后相应地设置最小延迟值。这允许您针对某些情况指定调整,因为您可能需要比自动延迟分配提供的延迟值更高的延迟值:
LUT-based Solution
核心提供了仅使用LUT构建复数乘法器的选项。虽然此选项使用了大量的片,实现了较低的最大时钟频率,并比DSP片实现使用了更多的功率 ,但它可能适用于DSP片供应有限或使用较低时钟速率的应用。当选择LUT实现时,仅使用三实乘法器配置。
舍入原则
在DSP系统中,尤其是当系统包含反馈时,通过乘法器的字长增长应该通过量化结果来抵消。量化或字长减少会导致错误,引入量化噪声,并可能引入偏差。为了获得最佳结果,最好选择一种引入零平均噪声并最小化噪声方差的量化方法。
理想的圆化器不会对信号流引入直流偏置。如果使用静态规则四舍五入0.5,则产生的量化总是引入偏差。为避免偏差,舍入必须随机化。因此,核心增加一个舍入常数,并应以½概率额外增加1,从而抖动精确舍入阈值。下表列出了广泛用作控制信号的典型圆形进位源。
| 0.5 Rounding Rule | Round Carry Source |
|---|---|
| Round towards 0 | -MSB(P) |
| Round towards +/- infinity | MSB(P) |
| Round towards nearest even | LSB(P) |
当过程中涉及多个级联DSP Slices时,四舍五入的结果并不简单,在实际的乘法和加法发生之前,无法从操作数预测输出符号(MSBo),并且会导致额外的延迟或在DSP片之外实现的资源。因此,一个外部信号应该被用来反馈到进位输入通过ROUND_CY引脚 (s_axis_ctrl_tdata的位0)。
一个很好的源可以是一个时钟分频触发器,或任何50%占空比的随机信号,它与结果的小数部分不相关。对于可预测的行为(如位真建模),ROUND_CY信号可能需要连接到 在您的设计中CLK独立源,例如一个复杂乘法器输入的LSB。
尽管如此,即使使用静态规则(例如ROUND_CY=0),与使用截断相比,偏移和量化误差也会减少。在许多情况下,对于DSP切片实现,舍入常数的添加是“自由”的,因为可以使用C端口和进位输入。在没有DSP片的设备中,增加舍入通常需要额外的基于片的加法器和额外的延迟周期。
协议描述
该内核遵循AXI4流规范。
AXI4-Stream注意事项
转换为AXI4流接口,使得接口协议更加标准并增强了IP的互操作性。除aclk、ACLKEN和ARESETn等常规控制信号外,复乘法器的所有输入和输出均通过AXI4流通道传输。通道由tvalid和tdata always以及几个可选端口和字段组成。在除法器中,支持的可选端口为tready、tlast和tuser。tvalid和tready一起执行握手以传输消息,其中有效负载为tdata、tuser和tlast。在复数乘法器中,支持的可选端口为tready、tlast和tuser。tvalid和tready一起执行握手以传输消息,其中有效负载为tdata、tuser和tlast。复数乘法器对tdata中包含的操作数进行操作,并在输出通道的tdata中输出结果。复数乘法器本身不使用tuser和tlast,但提供了以与tdata延迟传输的功能。
这种将tlast和tuser从输入传递到输出的功能旨在简化系统中复数乘法器的使用。例如,复数乘法器可用作混频器或对流式分组数据进行操作的相移。在此示例中,可以将核心配置为通过打包数据通道的tlast,从而减小工作量。
基本握手协议
下图显示了AXI4流通道中的数据传输。
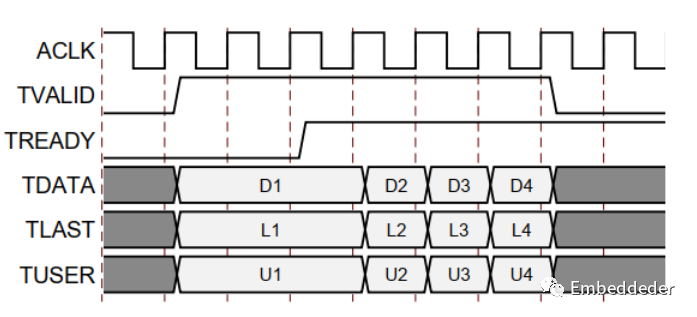
tvalid 由通道的源(主)端驱动,而tready 由接收器(从)驱动。 tvalid 表示有效载荷字段(tdata、tuser 和 tlast)中的值有效。 tready 表示从机已准备好接收数据。当循环中 tvalid 和treaty 都为TRUE 时,就会发生传输。master 和 slave 分别为下一次传输适当地设置了 tvalid 和tready。
非阻塞模式
非阻塞意味着如果在另一个输入通道上接收到数据,则一个输入通道上缺少数据不会阻止操作的执行。并非总是需要 AXI4-Stream 的完整流量控制。使用 FlowControl 参数或 GUI 字段选择阻塞或非阻塞行为。 复乘法器支持 NonBlocking 模式,其中 AXI4-Stream 通道没有 TREADY,即它们不支持背压。Blocking 或 NonBlocking 的选择适用于整个IP,而不是单独的每个通道。通道仍然具有非可选的 tvalid 信号,这类似于采用 AXI4-Stream 之前许多内核上的新数据 (ND) 信号。由于没有阻止数据流的功能,内部实现大大简化,因此这种模式需要的资源更少。对于希望从 AXI 之前的版本迁移到此版本且更改最少的用户,建议使用此模式。
当所有当前输入通道都接收到一个有效的 tvalid时,并且输出 tvalid(适当地被内核的延迟)被断言,从而输出计算的结果。操作发生在每个启用的时钟周期,并且无论 tvalid是状态,数据都显示在输出通道有效载荷字段中。这是为了允许从 v3.1 的最小迁移。下图显示了延迟为一个周期的情况下的 NonBlocking 行为。
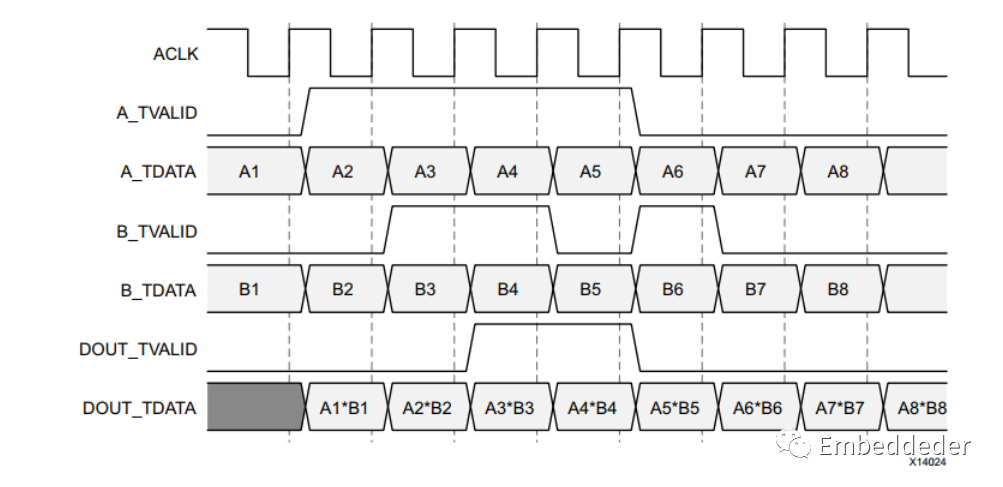
阻塞模式
术语“阻塞”意味着每个通道都在缓冲数据以供使用。 AXI4-Stream 的完整流控制有助于系统设计,因为数据流是自我调节的。使用 FlowControl 参数选择阻塞或非阻塞行为。背压(tready)的存在可以防止数据丢失,因此只有在下游数据路径准备好处理数据时才会传播数据。
复数乘法器有两个或三个输入通道和一个输出通道。当所有输入通道都有可用的有效数据时,会发生一个操作,并且输出结果可用。如果由于tready为低而阻止输出卸载数据,则数据会累积在堆芯内部的输出缓冲区中。当输出缓冲区几乎满时,内核停止进一步的操作。这可以防止输入缓冲区卸载新操作的数据,以便在输入新数据时填充输入缓冲区。当输入缓冲区填满时,其各自的tready将被置为无效,以防止进一步输入。
这三个输入绑定在一起,每个输入都必须在进行运算操作之前接收经过有效的数据。因此,有一个额外的阻塞机制,其中至少一个输入通道不接收有效数据,而其他通道接收有效数据。在这种情况下,有效数据存储在通道的输入缓冲区中。在该情况下的几个周期后,接收数据的通道的缓冲区将填满,该通道的TREADY将被取消断言,直到饥饿通道接收到一些数据。
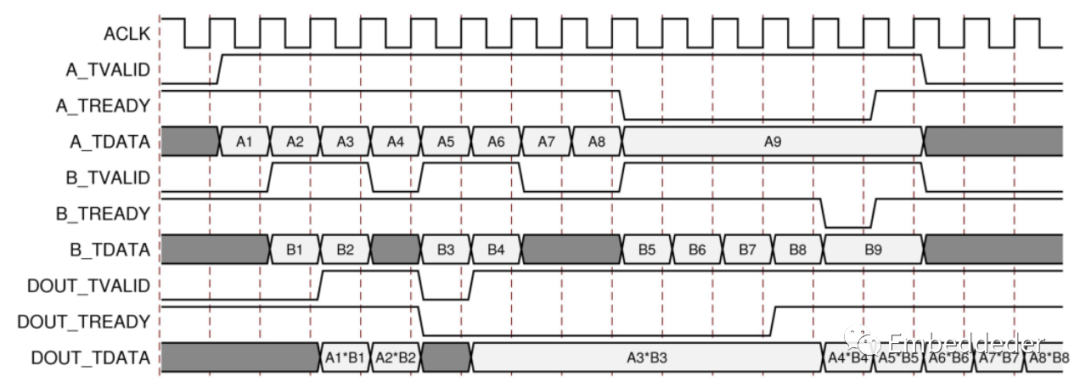
上图显示了阻塞行为和背压。通道 A 上的第一个数据与通道 B 上的第一个数据配对,第二个与第二个数据配对,依此类推。这演示了阻塞概念。该图进一步显示了数据输出如何不仅因延迟而延迟,而且还因握手信号 DOUT_TREADY 而延迟。这是背压输出上的持续背压以及输入上的数据可用性最终导致核心缓冲区饱和,从而导致核心通过取消置位输入通道TREADY 信号来表示它无法再接受进一步的输入。
这个例子中的最小延迟是两个周期,但在Blocking 操作中的延迟并不是一个有用的概念。每个通道都充当一个队列,确保每个通道上的第一个、第二个、第三个数据样本与每个操作的其他通道上的相应样本配对。
TDATA包
AXI4-Stream 接口中的遵循特定的命名法。通常情况下,与应用相关的信息(在本例中为复数乘法)在TDATA字段中携带。
在IP核中,复数操作数分量(实操作数分量和虚操作数分量)都通过通道TDATA端口传入或传出IP,其中实操作数分量位于最低有效位置。为了简化与面向字节的协议的互操作性,如果需要时,首先扩展TDATA中可独立使用的每个子字段,以适合8位的倍数的位字段。例如,如果将复数乘法器配置为具有11位的操作数宽度。A的每个实部和虚部都是11位宽。实分量将占用位10到0。位15到11将被忽略。位26到16将保持虚部,位31到27同样将被忽略。对于输出DOUT通道,结果字段符号扩展到字节边界。按字节方向添加的位被内核忽略,不会导致额外的资源使用。
A、B和DOUT通道的TDATA结构
输入端口A、B和输出端口D在其TDATA字段中携带复杂数据。对于每一个,实际组件占用最低有效位。虚部占据一个位域,该位域从实部上方的下一个字节边界开始。
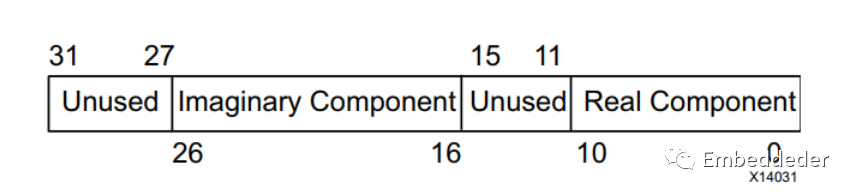
CTRL通道的TDATA结构
CTRL通道仅在选择舍入时存在,且仅用于传递舍入位。此位占用此通道TDATA的位0。但是,由于TDATA面向字节的特性,这意味着TDATA的宽度为8位。将舍入系数添加到舍入常数0.01111…,使舍入常数为0.01111..或0.100...因此,将该位设置为0会导致舍入为负无穷大;将其设置为1将使其四舍五入为正无穷大,并为每个样本设置一个新的随机值,从而实现无偏随机四舍五入。
TLAST and TUSER握手
AXI4-Stream 中的 tlast 用于表示数据块的最后一次传输。 tuser 用于限定或扩充 tdata 中的主要数据的辅助信息。复数乘法器基于每个采样进行操作,其中每个操作独立于任何之前或之后的操作。因此,在复数乘法器上不需要tlast,也不需要tlast。
在每个信道上支持tlast和tlast信号,通过复数乘法器的数据流确实具有一些分组化或辅助字段,但不是与复数乘法器相关。传递 tlast 或 tuser 的功能消除了通过复数乘法器将延迟匹配到 tdata 路径的负担,该路径可以是可变的。
TLAST Options
每个输入通道的 tlast 是可选的。每个存在时,都可以通过复数乘法器,或者,当多个通道启用了 tlast 时,可以通过 tlast 输入的逻辑 AND 或逻辑 OR。当任何输入通道上不存在 tlasts时,输出通道也没有 tlast。
TUSER Options
t每个输入通道的接收器是可选的。每个都有用户可选择的宽度。这些字段连接在一起,没有任何字节方向或填充,以形成输出通道TUSER字段。通道A中的TUSER字段形成连接的最低有效部分,然后是通道B中的TUSER,然后是通道CTRL中的TUSER。
如果通道 A 和 CTRL 都有宽度分别为 5 位和 8 位的 TUSER,则输出 TUSER 是 A 和 CTRL TUSER 字段的适当延迟串联,13 位宽,带有 A 在最低有效的 5 位位置(4 到 0)。
如果 B 和 CTRL 的 TUSER 宽度分别为 4 和 10,但 A 没有 TUSER,则 DOUT TUSER (m_axis_dout_tuser) 将适当延迟位置 3 到 0 与 CTRL_TUSER (s_axis_ctrl_tuser) 位将适当延迟位置13 下到4。
复数乘法器IP配置
复数乘法器IP配置界面如下:
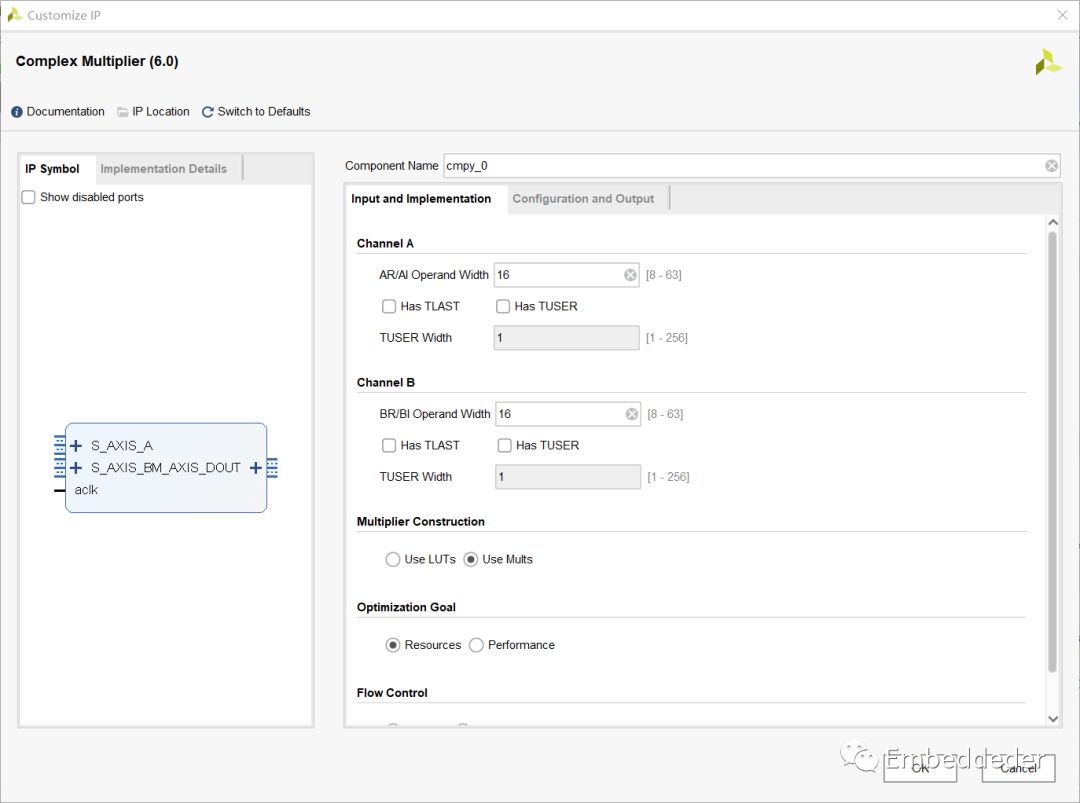
输入和实现选项卡
Channel A Options:
AR/AI Operand Width: AR/AI操作数宽度。选择第一个操作数宽度。宽度应用于复数操作数的实部和虚部。
Has TLAST: Has TLAST:选择通道是否具有TLAST。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
Has TUSER: 选择通道是否有TUSER。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
TUSER Width: 选择此通道的TUSER字段的宽度(以位为单位)。
Channel B Options:
BR/BI Operand Width: BR/BI操作数宽度。选择第一个操作数宽度。宽度应用于复数操作数的实部和虚部。
Has TLAST: Has TLAST:选择通道是否具有TLAST。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
Has TUSER: 选择通道是否有TUSER。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
TUSER Width: 选择此通道的TUSER字段的宽度(以位为单位)。
Multiplier Construction Options: 乘法器构造选项。允许选择使用LUT(切片逻辑)构造复数乘法器,或使用DSP切片。
Optimization Goal: 优化目标。在资源优化和性能优化之间进行选择。
此选择会影响AXI4流接口中的内部体系结构决策和性能/资源权衡。
对于基于乘法器的实现,资源优化通常使用三个实数乘法器结构。当三实数乘法器结构使用更多的乘法器资源时,核心使用四实数乘法器结构。性能优化始终使用四实乘法器结构,以实现最佳时钟频率性能。
Flow Control Options: 流量控制选项。选择AXI4流接口的阻塞和非阻塞行为。
配置和输出选项卡
Output Product Range: 输出宽度。选择输出运算结果的实部和虚部的宽度。设置A和B操作数宽度时,会自动初始化这些值以提供全精度乘积。复数乘法的自然宽度是输入宽度加上一的总和。如果输出宽度设置为小于此自然宽度,则根据下一个GUI字段的选择,将截断或舍入最低有效位。
Output Rounding: 如果选择了全精度运算结果(输出宽度等于自然宽度),则没有舍入选项可用。否则,可以选择截断或随机舍入。选择“随机舍入”后,将启用CTRL通道。此通道的TDATA字段的第0位决定了相关操作的特定舍入类型。
Channel CTRL Options:
控制通道用于提供决定舍入类型的位。
Output TLAST Behavior: TLAST行为。确定哪个输入通道的TLAST或哪个输入通道TLAST组合被传送到输出通道TLAST。可用选项包括传递任何一个输入通道的TLAST或传递所有可用输入TLAST的逻辑or或传递所有可用输入TLAST的逻辑AND。
Core Latency: Core Latency为Core选择所需的延迟。
Latency Configuration: 延迟配置。在自动和手动之间进行选择。自动时,延迟设置为使核心完全流水线化以获得最大性能。手动允许用户选择最小延迟。当值集小于完全流水线延迟时,性能会下降。当值集大于完全流水线时,内核使用SRL延迟输出。选择阻塞流控制后,核心延迟不是固定的,因此只能指定最小延迟。
Minimum Latency: 最小延迟。手动延迟配置的值。
Control Signals
控制信号。当内核的最小延迟为零时,这些选项将被禁用。
ACLKEN: 启用内核上的时钟启用(ACLKEN)引脚。核心中的所有寄存器都由该信号启用。
ARESETn: 启用内核上的活动低同步清除(ARESETn)引脚。内核中的所有寄存器都通过该信号复位。这会增加资源使用并降低性能,因为可以使用的基于SRL的移位寄存器数量会减少。aresetn始终优先于aclken。
Implementation Details(实现详细信息)选项卡
单击Implementation Details(实现详细信息)选项卡,查看用于特定复杂乘法器配置的DSP片资源的估计值。该值随GUI中的更改而即时更新,从而允许立即评估实现中的权衡。
reference
TUSER Width: 选择此通道的TUSER字段的宽度(以位为单位)。
Has TUSER: 选择通道是否有TUSER。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
Has TLAST: Has TLAST:选择通道是否具有TLAST。为了简化系统设计,内核将任何TLAST和TUSER传递到输出,延迟等于TDATA字段。
非常高的性能(使用更高的延迟值可在输入级之前和输出级之后添加更快的可编程逻辑寄存器。)
-
FPGA常用运算模块-加减法器和乘法器2023-05-22 7223
-
硬件乘法器的相关资料分享2021-12-09 2235
-
乘法器原理_乘法器的作用2021-02-18 28136
-
应用于CNN中卷积运算的LUT乘法器设计2020-11-30 3624
-
怎么设计基于FPGA的WALLACETREE乘法器?2019-09-03 2038
-
使用verilogHDL实现乘法器2018-12-19 11532
-
进位保留Barrett模乘法器设计2017-11-08 2105
-
求fpga乘法器,要求快的2012-08-16 3100
-
基于FPGA的WALLACE TREE乘法器设计2011-11-17 5849
-
基于IP核的乘法器设计2011-05-20 1032
-
模拟乘法器及其在运算电路中的应用2010-09-25 925
-
乘法器的基本概念2010-05-18 15382
-
乘法器对数运算电路应用2010-04-24 2924
全部0条评论

快来发表一下你的评论吧 !
