

可信人工智能研究方向与算法探索
人工智能
描述
复杂人工智能系统(如深度神经网络)的巨大成功令人工智能领域产生了飞跃式的变革。然而,由于其复杂的结构和庞大的参数体量,这些系统通常被视为黑盒系统。人们既无法理解系统内在的决策逻辑,也无法解释系统在表达能力方面的优势与缺陷,如解释神经网络为何具有优越的性能但却在对抗攻击下极其脆弱等。人工智能系统在决策过程、表达能力、优化能力等方面的不可解释性,极大地损害了系统的可信、可控与安全性,进而阻碍了人工智能在应用领域尤其是智能医疗、自动驾驶等高风险领域的广泛普及。
为了建立可信、可控、安全的人工智能,学术界与工业界致力于增强人工智能系统与算法的可解释性。具体地,可信人工智能旨在增强人工智能系统在知识表征、表达能力、优化与学习能力等方面的可解释性与可量化性以及增强人工智能算法内在机理的可解释性。
可信人工智能,旨在增强复杂人工智能系统和算法(如深度神经网络)的可信度。具体地,可信性概念蕴含了不同层面的含义:① 人工智能系统在知识表征方面的可解释性与可量化性② 人工智能系统在表达能力方面的可解释性与可量化性,包括泛化能力、鲁棒性、公平性与隐私保护性等;③ 人工智能系统在学习与优化能力方面的可解释性;④ 众多人工智能算法内在机理的可解释性。
近年来,可信人工智能的主要研究方向包括:
① 定性或定量地解释人工智能系统所建模的知识表征,如可视化中层表达蕴含的语义信息、量化输入变量对系统决策的重要性等;
② 评估、解释、提升人工智能系统的表达能力,包括理论证明或实证研究神经网络泛化性、鲁棒性等的边界,解释神经网络的泛化性、鲁棒性、表征瓶颈等的内在机理,发展各种方法(如对抗训练)提升系统鲁棒性、公平性或避免隐私泄漏等;
③ 解释人工智能系统优化算法有效性的内在机理,探索当前经验性优化算法的潜在缺陷,如解释随机梯度下降、随机失活等优化手段为何有效,发现批归一化等经典优化操作的潜在数学缺陷等;
④ 设计可解释的人工智能系统,在系统设计阶段将可信性嵌入系统结构中,如通过设计卷积神经网络的目标函数,使高层卷积层的每个滤波器自动地表示某种语义。
近年来,可信人工智能领域受到广泛关注,并取得众多核心研究成果。表 1.2.5 和表 1.2.6 分别列出了可信人工智能领域核心论文的主要产出国家、主要产出机构。表 1.2.7 和表 1.2.8 分别列出了该领域施引核心论文的主要产出国家和主要产出机构。可以看出,代表性的研究机构主要包括麻省理工学院、中国科学院、上海交通大学等,分布在美国、中国等国家。
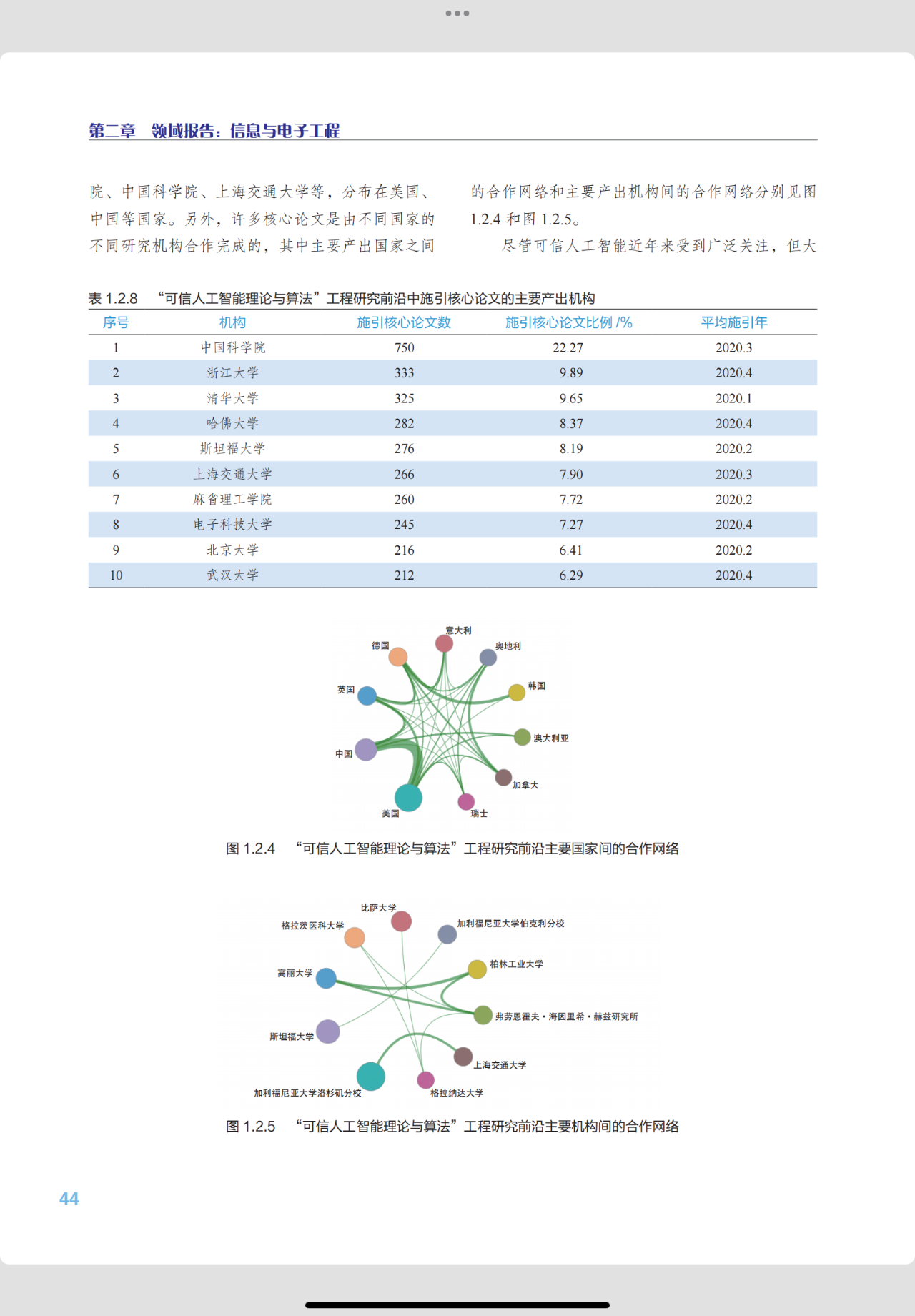
另外,许多核心论文是由不同国家的不同研究机构合作完成的,其中主要产出国家之间的合作网络和主要产出机构间的合作网络分别见图1.2.4 和图 1.2.5。
尽管可信人工智能近年来受到广泛关注,但大多数研究仍停留在工程性算法层面,如可视化神经网络的神经元、估计输入变量的重要性、用对抗攻击下的准确率评估神经网络的鲁棒性等,而对于可信人工智能领域中几大关键性、根本性的瓶颈问题却少有涉及与探索。这些问题包括:
1)探索、定位并量化决定人工智能系统表达能力的本质因素。具体地,人工智能系统的众多指标(如网络结构、优化手段等)都会影响系统的表达能力,但这些指标往往蕴含了许多与表达能力无关的冗余因素,并不能揭示决定表达能力的根本因素。只有确切地定位表达能力的决定性因素,才能准确地评估、解释系统的表达能力。
2)对当前众多经验性的人工智能算法内在机理的统一与解释。为解决某一个研究问题,学者们往往会从不同的经验性角度提出不同的人工智能算法。实际上,这些算法背后往往蕴含着相同或相似的内在机理。对这些不同经验性算法内在机理的统一与解释,可以揭示这些算法的公共本质,并从本质层面评估和比较这些算法的可靠性。
3)理论驱动的人工智能系统的设计与优化,尤其是神经网络系统。目前人工智能系统的结构设计、训练优化大都是经验主义的,即人们从大量实验观察中找出行之有效的结构设计和优化方法。然而,我们需要找到统一的理论反馈指导系统的设计与优化,令人工智能系统具备满足特定任务需求的表达能力,方能真正实现系统的可控性。 事实上,国际上已有少数研究团队,发现并重视了上述关键性问题,并在这些方向上做出了前瞻性的探索。例如,上海交通大学的团队统一地解释了众多提升对抗迁移性的算法;加利福尼亚大学伯克利分校的团队提出“自洽性”与“简约性”原则是人工智能系统的基石,并用这些原则指导设计了表征可解释、训练可解释的人工智能系统。

在过去 10 年中,可信人工智能取得诸多研究成果。然而,从整个领域的发展进程看,其仍处于起步阶段,仍存在众多亟待解决的关键性瓶颈问题。具体地,如图 1.2.6 所示,未来 5~10 年的重要发展方向包括如下几个方面。
第一,完善对知识表征的解释。当前对知识表征的解释大多源于启发性直觉,缺乏理论可靠性;这些解释也往往没有标准的答案以供参考,因此无法从实证角度验证解释的可靠性。因此,未来的研究重点可能包括:① 统一现有众多经验性解释,揭示其公共本质;② 发展具有理论保证的新解释;③ 客观评估解释的可靠性。
第二,深入发展对表达能力的解释与量化。未来的研究重点可能包括:① 探索并定位决定人工智能系统表达能力的本质因素;② 如何统一地解释众多提升表达能力的人工智能算法的内在机理;③ 提出精确的量化指标,评估系统的真实表达能力;④ 解释并证明系统在表达能力方面的特点和缺陷。
第三,理论驱动的人工智能系统的设计与优化。目前,人们往往是从大量实验观察中找出行之有效的结构设计和优化方法,而可信人工智能需要我们找到统一的理论,有的放矢地反馈指导系统的设计与优化。为了实现这一目标,未来的研究重点可能包括:① 探索神经网络的网络结构与知识表征的关系;② 探索神经网络的模型性能与知识表征的关系;③ 探索神经网络的众多表达能力(如泛化性、鲁棒性、公平性等)与知识表征的关系。
(内容取自《全球工程前沿2022》)
张拳石,上海交通大学电院计算机科学与工程系长聘教轨副教授,博士生导师,入选国家级海外高层次人才引进计划,获ACM China新星奖。2014年获日本东京大学博士学位,2014—2018年在加州大学洛杉矶分校(UCLA)从事博士后研究,主要研究方向包括机器学习和计算机视觉。研究工作主要发表在计算机视觉、人工智能、机器学习等领域顶级期刊和会议(包括IEEE T-PAMI、ICML、ICLR、CVPR、ICCV、AAAI、KDD、ICRA等)。近年来,在神经网络可解释性方向取得多项具有国际影响力的创新性成果。担任ICPR 2020领域主席,CCF-A类会议IJCAI 2020和IJCAI 2021可解释性方向tutorial,并先后担任AAAI 2019、CVPR 2019、ICML 2021大会可解释性方向分论坛主席。
编辑:黄飞
-
嵌入式人工智能的就业方向有哪些?2024-02-26 12404
-
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得2024-10-14 1699
-
人工智能是什么?2015-09-16 6402
-
有没有搞机器学习,人工智能算法研究的啊?2016-02-26 5748
-
人工智能的前世今生 引爆人工智能大时代2016-03-03 5963
-
【下载】人工智能 : 一种现代方法(第3版)(中文版)2017-05-24 97976
-
分享:人工智能算法将带领机器人走向何方?2017-08-16 6019
-
人工智能就业前景2018-03-29 8390
-
人工智能的就业方向详解2018-04-24 14432
-
天津大学与中科视拓共建“人工智能联合实验室”2018-05-25 7328
-
百度深度学习研究院科学家深度讲解人工智能2018-07-19 16700
-
人工智能技术及算法设计指南2019-02-12 5148
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5820
-
人工智能基本概念机器学习算法2021-09-06 2756
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2325
全部0条评论

快来发表一下你的评论吧 !
