

英特尔如何构建下一代超级计算芯片
处理器/DSP
描述
在雄心勃勃的将 CPU 和 GPU 集成到芯片中的计划突然逆转后,英特尔终于提供了有关其超级计算芯片路线图的大规模更改的具体细节。
该芯片制造商分享了即将推出的名为 Falcon Shores 的芯片的更多细节,该芯片最初被定为 XPU(统一的 CPU 和 GPU)。Falcon Shores 现在是一款纯 GPU 产品,并针对科学和 AI 计算进行了重新配置。
“我之前推动并强调将 CPU 和 GPU 集成到 XPU 中还为时过早。原因是,我们觉得我们所处的市场比我们一年前想象的要活跃得多,”英特尔公司副总裁兼超级计算事业部总经理 Jeff McVeigh 在新闻发布会上说。
新的 Falcon Shores 芯片是面向高性能计算和 AI 的下一代独立 GPU。它包括来自 Gaudi 系列的 AI 处理器(在 Falcon Shores 发布时将是第 3 版),还包括标准以太网交换、HBM3 内存和大规模 IO。
“这提供了跨供应商的灵活性,可以将 Falcon Shores GPU 与其他 CPU 以及 CPU 与 GPU 的结合起来,同时仍然提供非常通用的基于 GPU 的编程接口,并在 CPU 和 GPU 之间共享 CXL,以提高生产力和性能对于这些代码,”McVeigh 说。
Falcon Shores GPU 是代号为 Ponte Vecchio 的 Max 系列 GPU 的继任者,现在将于 2025 年推出。英特尔在 3 月份废弃了代号为 Rialto Bridge 的超级计算机 GPU,该 GPU 是 Ponte Vecchio 的指定后续产品。
McVeigh 说,计算环境还不成熟,无法实施 XPU 战略,并补充说,围绕生成式人工智能和大型语言模型的创新——其中大部分来自商业领域——引发了英特尔关于如何构建下一代超级计算芯片的思维转变。
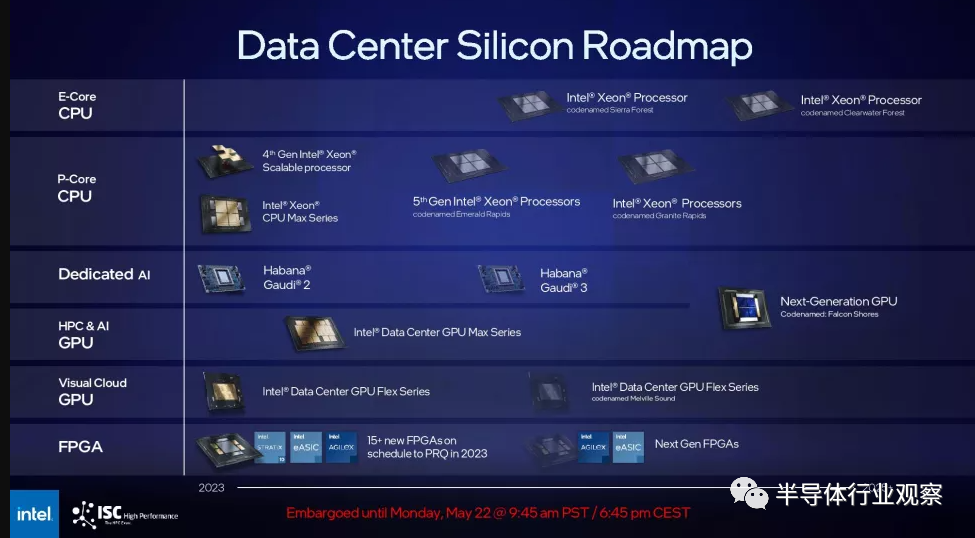
与此同时,英特尔还发布了新的 HPC 和 AI 路线图,其中没有显示 Gaudi3 处理器的继任者——相反,Gaudi 和 GPU 与 Falcon Shores GPU 合并,因为它继承了英特尔首屈一指的 HPC 和 AI 芯片。英特尔告诉我们,它“计划整合 Habana 和 AXG 产品 [GPU] 路线图”,但整合的细节很少。
Gaudi 计算架构与标准 GPU 有很大不同,因此其计算架构似乎无法完全集成到 GPU 中。因此,英特尔可以将Gaudi设计的较小部分(例如其网络接口或其他 IP 块)整合到其 GPU 中。回顾一下,英特尔为 Habana Labs 支付了 20 亿美元,并取消了其 3.5 亿美元收购 Nervana 的产品,以专注于 Gaudi 芯片。

然而,如上所示,Falcon Shores 的原始计划确实包括通过将不同数量的 CPU 或 GPU 块放入四块设计中来调整 CPU/GPU 的能力,从而允许它配置最佳混合各种工作量。此外,从设计上讲,处于前沿的超级计算机是针对手头任务的高度专业化设计,针对架构的软件调整只是运行超级计算机业务的常规部分。这些因素意味着 CPU/GPU 比率并不是英特尔从设计中移除 CPU 内核的唯一原因。
生成式 AI 和 LLM 将在科学计算中得到广泛采用,CPU 和 GPU 的解耦将为具有不同工作负载的客户提供更多选择。
“当您身处工作负载瞬息万变的动态市场时,您真的不想强迫自己走固定 CPU 与 GPU 的道路。你不想修复供应商甚至所使用的架构……x86,Arm。” McVeigh说。
CPU 和 GPU 的集成可以降低成本并节省电力,但它会将客户锁定在供应商和配置上。但这将随着新的 Falcon Shores 的出现而改变,McVeigh表示,他补充说:“我们只是觉得要对今天的市场进行清算,现在还不是整合的时候。”
虽然在不久的将来不会将 CPU 和 GPU 合并用于超级计算,但英特尔并没有放弃这个想法。
“我们会在合适的时间,”McVeigh说,并补充道,“当天气合适的时候,我们会这样做。我们只是觉得这不适合下一代。”
独立的 GPU 还将为供应商提供更大的灵活性,让他们可以使用具有 x86 以外的不同 CPU 的 GPU 构建系统。英特尔已达成协议,可能会在其工厂生产基于 Arm 的芯片。
服务器设计也有望随着 CXL(Compute Express Link)互连而改变,这鼓励组件解耦,因此 GPU、AI 芯片和其他加速器可以轻松访问大型存储和内存池。
“问题是,这通常落在我们的 OEM 合作伙伴的肩上,他们希望如何将我们的 GPU 与其他供应商的 CPU 集成,但我们为实现这一目标敞开大门,并利用 PCI Express 等标准接口,和 CXL 等等,使我们能够非常有效地做到这一点,”McVeigh说。
但英特尔面临来自 AMD 的 Instinct MI300 的挑战,该产品预计将于今年晚些时候发货,并将为劳伦斯利弗莫尔国家实验室的 2 exaflops(峰值)超级计算机 El Capitan 提供动力。Nvidia 目前在商业生成人工智能市场占据主导地位,该公司的 H100 GPU 在谷歌、Facebook 和微软运营的数据中心运行。
英特尔将利用 Falcon Shores 的 GPU 编程模型,类似于 Nvidia 采用的 CUDA 编程框架。英特尔的 OneAPI 工具包有一系列编译器、库和编程工具,可以在 Falcon Shores GPU、Gaudi AI 处理器和英特尔将放入超级计算芯片的其他加速器上执行。
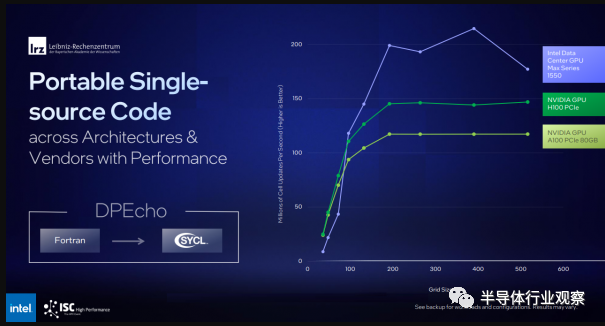
OneAPI 中名为 SYCL 的工具可以编译超级计算和 AI 应用程序,以在 Intel、Nvidia 和 AMD 的一系列硬件上运行。它还可以通过剥离特定于 CUDA 的代码来重新编译为 Nvidia GPU 编写的应用程序。例如,LRZ 从 Fortran 移植了 DPEcho 天体物理学代码,并且能够在 Intel 和 Nvidia GPU 上有效运行(下面的基准测试幻灯片)。
英特尔分享了除 GPU 课程修正之外的其他披露信息。
该芯片制造商为其 Aurora 超级计算机交付了超过 10,624 个采用 HBM 的 Xeon Max 系列芯片计算节点,其中包括 21,248 个 CPU 节点、63,744 个 GPU、10.9PB 的 DDR 内存和 230PB 的存储空间。
“在全面优化、交付代码和验收方面,我们还有很多工作要做。但这是一个至关重要的里程碑,我们……非常高兴能够实现,”McVeigh说。
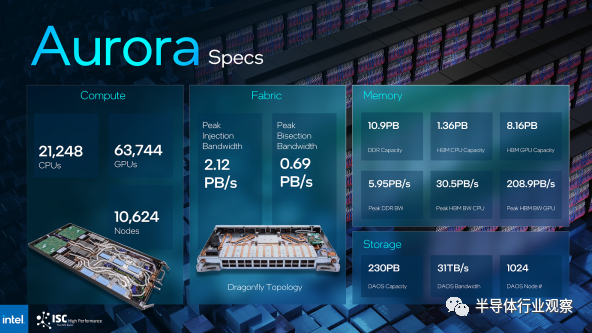
这个里程碑对英特尔来说很重要,因为 Aurora 的部署已经被推迟。这台有望突破 2 exaflops(峰值)门槛的超级计算机将无法跻身今年 5 月全球最快超级计算机 Top500 榜单。
“我们真正专注于推出整个系统……稳定并运行……获得真正的工作负载,而不仅仅是运行和运行的基准。我们预计到 11 月,我们将在 Top500 系统中提供强大的产品,”McVeigh 说。
最近在戴尔主办的网络研讨会上,Rick Stevens(阿贡实验室)分享说,Frontier 每年将为关键的科学工作负载贡献大约 7800 万个四 GPU 小时。
包括英特尔、HPE 和阿贡国家实验室在内的主要 HPC 参与者正在联手开发一种名为 AuroraGPT 的科学计算大型语言模型,该模型建立在 1 万亿个参数的基础模型之上,比 ChatGPT 大得多,后者是建立在 GPT-3 基础模型之上。
生成式人工智能技术将基于可用的科学数据和文本以及代码库,并像商业大型语言模型一样发挥作用。目前尚不清楚该技术是否会是多模态,并生成图像和视频。如果它是多模态的,一个例子可能是研究人员提出问题,人工智能提供响应,或者使用人工智能生成科学图像。
LLM将用于“推动科学发展并利用 Aurora 进行训练,其推论将成为系统部署方式的关键部分,”McVeigh 说。
AuroraGPT 可用于材料、癌症和气候科学的研究。基础模型包括 Megatron 和 DeepSpeed 变压器。
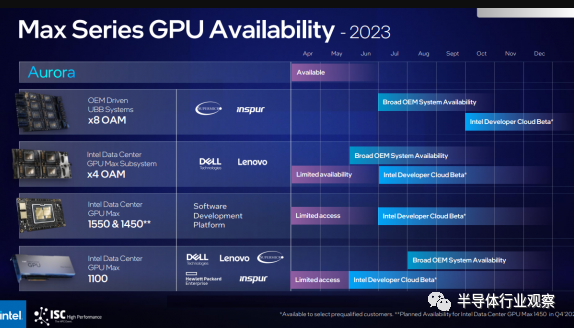
英特尔还宣布将推出一款通用基板 (UBB) 系统,该系统最初采用基于 Supermicro 和 Inspur 的设计,配备八个 Ponte Vecchio Max 系列 GPU(如标题图片所示)。这些服务器针对 AI 部署,McVeigh 表示支持 8-GPU 配置。该产品于今年早些时候推出,预计将在第三季度推出。
编辑:黄飞
-
英特尔下一代Max系列GPU芯片曝光,能否挑战英伟达?2023-05-25 4004
-
英特尔12月17日将预展下一代32纳米处理器2009-12-14 555
-
英特尔将推出下一代智能手机平台2010-01-13 682
-
英特尔下一代服务器芯片Westmere-EX将采用10核设计2010-06-23 822
-
英特尔计划明年推出Medfield下一代Atom处理器2010-08-16 718
-
英特尔公布下一代高性能计算平台的细节2011-11-16 895
-
英特尔下一代处理器细节参数曝光2011-12-06 1412
-
英特尔下一代通讯平台“Crystal Forest”2012-02-16 1099
-
英特尔发布专为移动设备设计的下一代凌动芯片2013-02-28 1081
-
英特尔的野心:下一代VR设备从基因里就带我的技术2016-11-05 584
-
“冯诺依曼”式PC已经到达极限 英特尔押宝量子计算和神经芯片2017-02-15 1181
-
在英特尔架构上启用下一代分析2020-05-31 3733
-
英特尔联手联发科 提供出色的下一代PC体验2019-11-28 838
-
下一代英特尔至强可扩展处理器将集成高带宽内存(HBM)。2021-07-01 9498
-
富士康联手英特尔,共造下一代AI基础设施2026-06-05 89
全部0条评论

快来发表一下你的评论吧 !
