

大模型时代下,普通科研人怎么办?
描述
众所周知,随着ChatGPT的爆火,AI全面进入大模型时代,NLP、CV大有统一之势,回顾发布的各种大模型,Google BARD,openAI的GPT,Meta的SAM,百度的文心一言等等,这些基本都是有实力有技术的大公司引领着来研究的,但是作为一名普通的高校科研工作者,我们大多数基本上是没有这么多资源算力去开发这样的大模型的,但是大模型在各个方向效果精度几乎是碾压,导致很多领域方向就消失了,很多研究生也是很焦虑,可能在申的论文以及毕业答辩时肯定会comment你的性能差距大模型这么多,还有研究的必要吗?
所以,大模型时代下,作为一名普普通通,没有很多资源算力的科研人如何继续研究呢?
最近在arXiv上刷到一篇文章,也许能提供一些思路。
论文名称:
AV-SAM: Segment Anything Model Meets Audio-VisualLocalization and Segmentation
论文地址:
https://arxiv.org/abs/2305.01836

主要内容:
首先,Segment Anything Model(SAM)大模型是Meta提出的一种CV大模型,在1100万张图像中的10亿个masks上进行训练,并且在各种分割任务上具有很强的零样本性能,它在打破分割边界方面取得了重大进展,极大地促进了计算机视觉基础模型的发展,这个视觉基础模型由三个主要组件组成:图像编码器、提示编码器和掩码解码器。
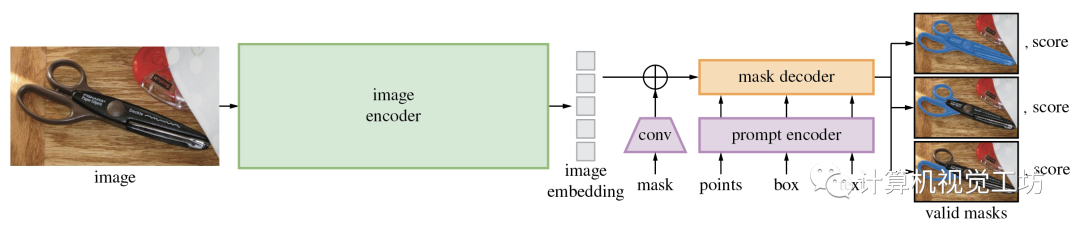

SAM的项目地址:https://github.com/facebookresearch/segment-anything
我们普通科研人如果想重新设计训练这样一个大模型显然不现实,那么这篇论文的作者另辟蹊径,虽然大模型的泛化性很好,在很多任务上做的不错,但是不可能面面俱到,往往是大而不精的,这篇论文就利用已经预训练好的SAM大模型去做更具体的下游任务——视听定位和分割。
视听定位和分割:
视听定位和分割是以热图或掩模的方式预测视频中单个声源的位置。
所以,这篇arXiv的论文提出了一个简单而有效的基于SAM大模型的视听定位和分割框架,即AV-SAM,它可以生成与音频相对应的发声对象掩码。具体而言,利用SAM中预先训练的图像编码器的视觉特征,把它和音频特征逐像素视听融合来聚合跨模态表示,然后将聚合的跨模态特征输入到提示编码器和掩码解码器以生成最终的视听分割掩码。
方向主要包括:3D视觉领域各细分方向,比如相机标定|三维点云|三维重建|视觉/激光SLAM|感知|控制规划|模型部署|3D目标检测|TOF|多传感器融合|AR|VR|编程基础等。
Methods
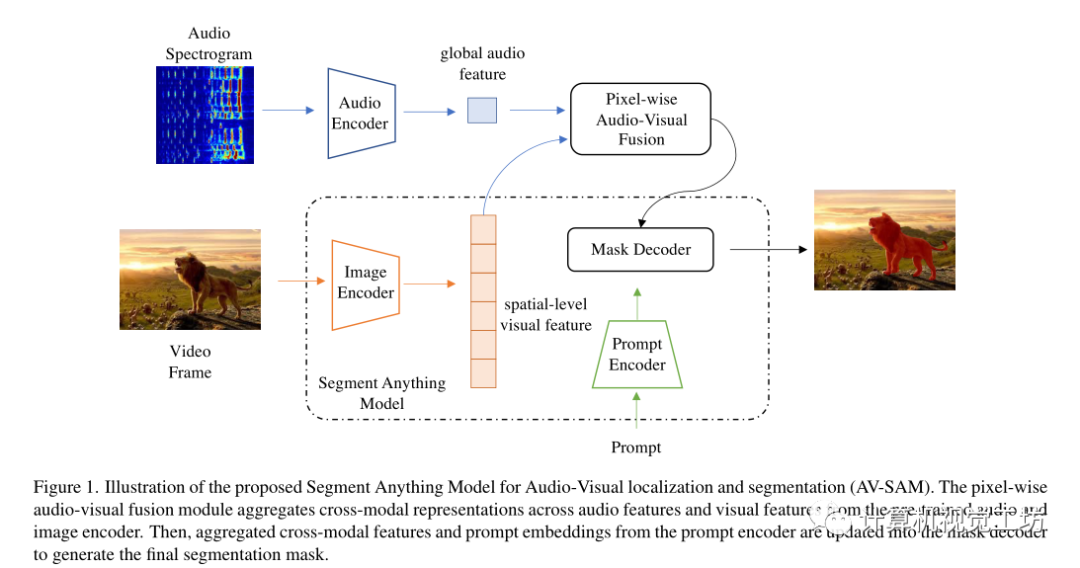
给定图像和音频,目标是预测图像上声音对象的像素掩码。主要由两个模块组成,像素级视听融合和视听掩码解码器。
让表示听觉和视觉数据对,T、F分别表示音频频谱图的时间和频率维度。
首先使用双流编码器和投影头对音频和视觉输入进行编码,分别表示为,音频编码器计算全局音频特征,视觉编码器为每s阶段生成多尺度空间级特征。
为了解决视听分割问题,引入了逐像素视听融合模块来对多尺度空间级视觉特征和全局音频表示进行编码,以更新输入到SAM的掩码解码器。在跨模态融合之后,第s阶段的视听特征被更新为:
其中,表示全局音频表示ai的复制版本,该复制版本在第s阶段重复次。这里表示1×1×1的卷积。通过这种特殊的视听融合,推动学习到的视觉标记嵌入与全局音频特征有区别地对齐。
利用逐像素视听融合的优势,使用多尺度特征图的最后阶段更新SAM中预训练图像编码器的原始视觉特征。然后这些更新的多级特征图被传递到SAM中的掩码解码器和提示编码器,以生成最终的输出掩码,以像素级标注Y作为监督,将预测和标签之间的二进制交叉熵(BCE)作为损失:
实验:
在VGG-Sound中使用144k对的子集进行训练,并在Flickr SoundNet测试集上用250对声音对象的视听对测试模型。
使用在ImageNet上预训练的ResNet50通过特征图的双线性插值来生成伪掩码。
对于输入视觉帧,分辨率调整为1024×1024。对于输入音频,使用长度为3s的对数频谱图,采样率为22050Hz。
使用轻量级的ResNet18作为音频编码器,并使用SAM发布的权重初始化视觉模型。该模型使用128的batch size,学习率为1e−4的Adam优化器进行了100个epochs的训练。

与SAM相比,在两个基准的所有指标方面都取得了最佳结果。
这表明了逐像素视听融合对聚合跨模态输入的重要性。

同时进行了消融研究以证明SAM冻结和微调预训练重量的效果。
在表2中冻结/微调每个模块(掩码解码器、提示编码器、图像编码器)参数。
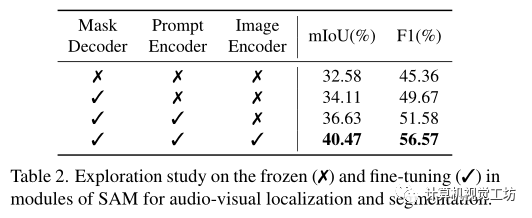
可以观察到,对掩码解码器进行微调会增加视听分割的结果,表明视听掩码解码器在从聚合的跨模态特征生成准确掩码方面的优势。同时微调提示编码器也提高了视觉声源在所有指标方面的分割性能。
总结:
本篇是一篇基于大模型来做研究的文章,针对大模型在视听定位和分割上不够鲁棒准确的问题,设计模块去聚合跨模态表示,显著提高了在这一具体任务上的性能。这也许可以给我们普通科研工作者一些启发,如果我们不能重新研究设计训练大模型情况下,我们可以在有限的资源算力下用大模型做一些具体的下游任务,扩展大模型的应用点,用他们已经预训练好的模型权重去做更具体的任务,原始的大模型不可能面面俱到,其中很多点还是可以去做的。思考大模型如何在自己的研究方向上发挥它的价值,如何融合进自己的研究。
审核编辑 :李倩
-
Altium Designer找不到元件怎么办?2013-07-19 38021
-
模型转换失败怎么办?2023-09-18 1017
-
ADL5205官网上没有spice模型 ,不能仿真怎么办?2023-11-17 742
-
诺基亚n70白屏怎么办2008-09-01 3785
-
主板坏了怎么办?2009-05-22 12395
-
显示桌面没了怎么办2010-01-18 4190
-
笔记本风扇噪音很大怎么办2010-01-21 2215
-
文件或目录损坏怎么办2010-02-25 1392
-
电池换新无法可依怎么办2019-03-19 1970
-
linux无法识别U盘怎么办2020-05-19 17909
-
linux下telnet不能使用怎么办2020-05-26 6455
-
键槽滚键了怎么办?2022-03-07 896
-
电机过热怎么办?2023-11-01 1872
-
pcb钻孔偏孔了怎么办?2023-11-22 6783
-
风机轴磨损怎么办2024-01-07 564
全部0条评论

快来发表一下你的评论吧 !
