

中国研究人员提出StructGPT,提高LLM对结构化数据的零样本推理能力
电子说
描述
大型语言模型 (LLM) 最近在自然语言处理 (NLP) 方面取得了重大进展。现有研究表明,LLM) 具有很强的零样本和少样本能力,可以借助专门创建的提示完成各种任务,而无需针对特定任务进行微调。尽管它们很有效,但根据目前的研究,LLM 可能会产生与事实知识不符的不真实信息,并且无法掌握特定领域或实时的专业知识。这些问题可以通过在LLM中添加外部知识源来修复错误的生成来直接解决。
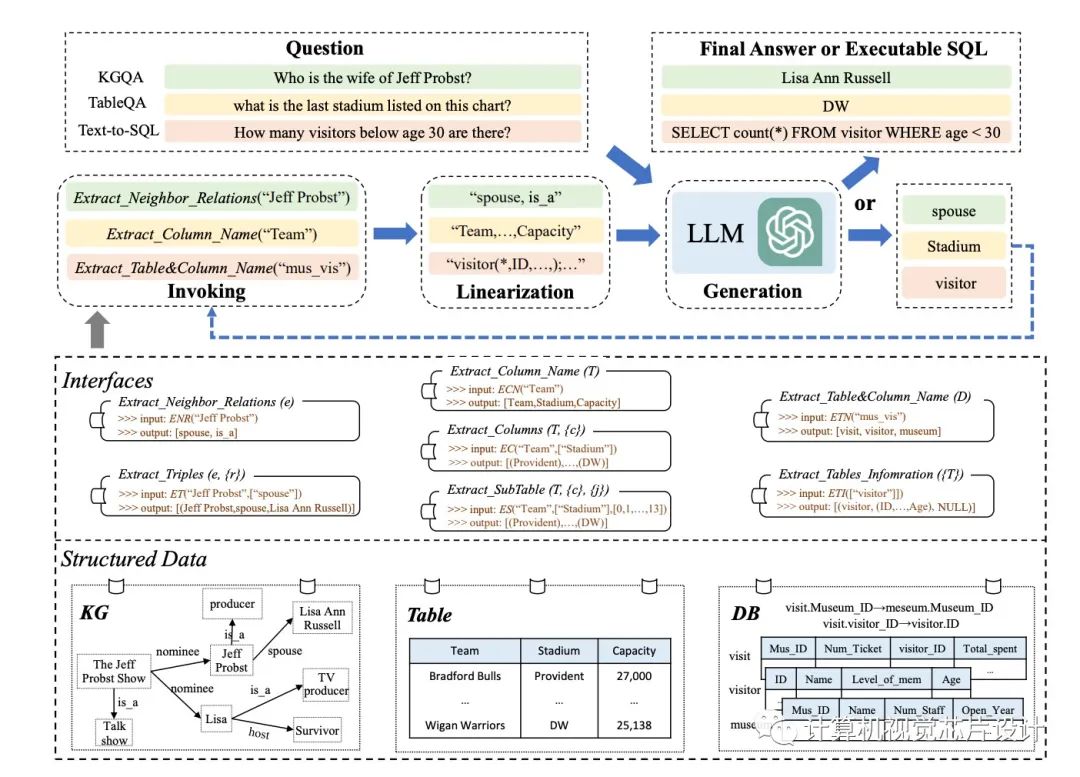
结构化数据,如数据库和知识图谱,已被常规用于在各种资源中携带 LLM 所需的知识。但是,由于结构化数据使用 LLM 在预训练期间未接触过的独特数据格式或模式,因此他们可能需要帮助才能理解它们。与纯文本相反,结构化数据以一致的方式排列并遵循特定的数据模型。数据表按行排列为列索引记录,而知识图 (KG) 经常组织为描述头尾实体之间关系的事实三元组。
尽管结构化数据的体量往往非常巨大,但不可能容纳输入提示中的所有数据记录(例如,ChatGPT 的最大上下文长度为 4096)。将结构化数据线性化为 LLM 可以轻松掌握的语句是解决此问题的简单方法。工具操作技术激励他们增强 LLM 解决上述困难的能力。他们策略背后的基本思想是使用专门的接口来更改结构化数据记录(例如,通过提取表的列)。在这些接口的帮助下,他们可以更精确地定位完成特定活动所需的证据,并成功地限制数据记录的搜索范围。
来自中国人民大学、北京市大数据管理与分析方法重点实验室和中国电子科技大学的研究人员在这项研究中着重于为某些任务设计合适的接口,并将它们用于 LLM 的推理,这些接口是应用界面增强方法需要解决的两个主要问题。以这种方式,LLM 可以根据从界面收集的证据做出决定。为此,他们在本研究中提供了一种称为 StructGPT 的迭代阅读然后推理 (IRR) 方法,用于解决基于结构化数据的任务。他们的方法考虑了完成各种活动的两个关键职责:收集相关数据(阅读)和假设正确的反应或为下一步行动制定策略(推理)。
据他们所知,这是第一项着眼于如何使用单一范式帮助 LLM 对各种形式的结构化数据(例如表、KG 和 DB)进行推理的研究。从根本上说,他们将 LLM 的阅读和推理两个过程分开:他们使用结构化数据接口来完成精确、有效的数据访问和过滤,并依靠他们的推理能力来确定下一步的行动或查询的答案。
对于外部接口,他们特别建议调用线性化生成过程,以帮助 LLM 理解结构化数据并做出决策。通过使用提供的接口重复此过程,他们可能会逐渐接近对查询的期望响应。
他们对各种任务(例如基于知识图谱的问答、基于表的问答和基于数据库的文本到 SQL)进行了全面试验,以评估其技术的有效性。八个数据集的实验结果表明,他们建议的方法可能会显着提高 ChatGPT 在结构化数据上的推理性能,甚至达到与全数据监督调优方法竞争的水平。
• KGQA。他们的方法使 KGQA 挑战的 WebQSP 上的 Hits@1 增加了 11.4%。借助他们的方法,ChatGPT 在多跳 KGQA 数据集(例如 MetaQA-2hop 和 MetaQA-3hop)中的性能可能分别提高了 62.9% 和 37.0%。
• 质量保证表。在 TableQA 挑战中,与直接使用 ChatGPT 相比,他们的方法在 WTQ 和 WikiSQL 中将标注准确度提高了大约 3% 到 5%。在 TabFact 中,他们的方法将表格事实验证的准确性提高了 4.2%。
• 文本到SQL。在 Text-to-SQL 挑战中,与直接使用 ChatGPT 相比,他们的方法将三个数据集的执行准确性提高了约 4%。
作者已经发布了 Spider 和 TabFact 的代码,可以帮助理解 StructGPT 的框架,整个代码库尚未发布。
审核编辑 :李倩
-
结构化布线系统有哪些难题2016-05-19 3203
-
泰克仪器助力研究人员首次通过太赫兹复用器实现超高速数据传输2018-08-31 2066
-
TrustZone结构化消息是什么?2019-03-20 2119
-
结构化设计分为哪几部分?结构化设计的要求有哪些2021-12-23 2052
-
白光LED结构化涂层制备及其应用研究2022-03-29 10997
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3290
-
形状感知零样本语义分割2023-04-28 1801
-
一个通用的自适应prompt方法,突破了零样本学习的瓶颈2023-06-01 1764
-
基准数据集(CORR2CAUSE)如何测试大语言模型(LLM)的纯因果推理能力2023-06-20 3537
-
什么是零样本学习?为什么要搞零样本学习?2023-09-22 3931
-
跨语言提示:改进跨语言零样本思维推理2023-11-08 1964
-
什么是LLM?LLM的工作原理和结构2024-07-02 20278
-
LLM大模型推理加速的关键技术2024-07-24 3656
-
使用ReMEmbR实现机器人推理与行动能力2024-11-19 2027
-
详解 LLM 推理模型的现状2025-04-03 1949
全部0条评论

快来发表一下你的评论吧 !
