

PrimeSimSPICE:异构计算模型实现数量级性能突破
描述
作者:Srinivas Kodiyalam,Samad Parekh
随着对更高计算性能的需求不断增加,HPC 行业正朝着异构计算模型发展,其中 GPU 和 CPU 协同工作以执行通用计算任务。在这种异构计算模型中,GPU 充当 CPU 的加速器,以减轻 CPU 的负载并提高计算效率。为了利用这种计算模型和大规模并行的GPU架构,需要重新设计应用软件。Synopsys 和 NVIDIA 的工程师一直在合作,使用 GPU 来加速电路仿真技术。
IC设计的复杂性继续呈指数级增长。就在过去十年中,随着工艺技术从平面技术发展到鳍式场效应晶体管技术,器件数量和寄生效应显著增加。现代工艺技术还需要对更多的工艺、电压和温度角落进行验证,导致设计复杂性增加几个数量级。在此期间,CPU 性能的提升在很大程度上趋于平稳,而 GPU 性能一直在增长,并继续远远超出摩尔定律。随着时间的推移,这些趋势只会进一步扩大两种计算方法之间的差距。GPU 在应对电路仿真挑战方面具有显著优势,包括大量的浮点运算和内存带宽使用,以及具有大型布局后电路的大量独立计算作业。
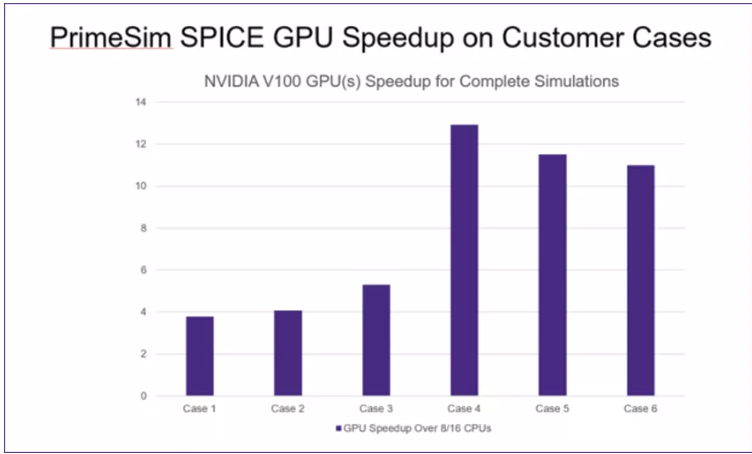
这是一个由一流的 SPICE 和 FastSPICE 技术组成的统一工作流程,可加速模拟、射频、混合信号、定制数字和存储器设计的创建。PrimeSim Continuum解决方案建立在创新的SPICE和FastSPICE架构之上,为设计团队提供10倍的仿真速度,同时保持签核准确性。PrimeSim的下一代架构采用独特的GPU技术,可提供执行全面的模拟和RF设计分析所需的显著性能改进,同时满足签核精度要求。在 NVIDIA DGX 系統上運行的測試模型顯示,多核 CPU 的加速速度範圍為 4-12 倍。虽然各种电路类型的性能都有所提高,但在运行大型布局后仿真时,可以看到最好的改进。当与较长的瞬态运行时间相结合时,性能改进更加明显。
PrimeSim 通过利用 CUDA GPU 的大规模并行性实现了最令人印象深刻的性能提升。涉及的核心技术有:
异构 GPU 和 CPU 架构上的同步并行计算
鲁棒稀疏求解器,用于求解方程的电路仿真系统
准确高效的 IC 元件建模
紧凑高效的 GPU 数据模型和管理,以及
快速电路仿真数据库构建和数据处理
纳米级 IC 仿真的复杂性和爆炸式的模型尺寸需要多个具有极快互连的 GPU。NVIDIA DGX 系統和 HGX™ 平台整合了 NVIDIA GPU、NVIDIA NVLink®、NVIDIA Mellanox® InfiniBand® 網路的全部功能,以及完全優化的 NVIDIA® AI 和 HPC 軟體體閣,以提供最高的應用應用效能。
审核编辑:郭婷
-
【一文看懂】什么是异构计算?2024-12-04 4534
-
请问模型推理只用到了kpu吗?可以cpu,kpu,fft异构计算吗?2023-09-14 593
-
异构计算真就完美无缺吗2021-12-21 2930
-
异构计算的前世今生2021-12-17 6042
-
OPPO开发者大会2021 关于异构计算2021-10-27 3995
-
异构计算在人工智能什么作用?2019-08-07 3743
-
异构计算,你准备好了么?2018-09-25 830
-
异构计算:架构与技术2018-09-18 1285
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 23660
-
基于FPGA的异构计算是趋势2018-04-25 11806
-
【产品活动】阿里云GPU云服务器年付5折!阿里云异构计算助推行业发展!2017-12-26 3532
-
FPGA异构计算现状及优化2017-11-15 9188
-
异构计算芯片的机遇与挑战2017-09-27 1549
全部0条评论

快来发表一下你的评论吧 !
