

使用可计算SSD加速云原生数据库
描述
背景
PolarDB是阿里云设计的云原生OLTP数据库,每个数据库实例由多个数据库节点和存储节点组成,节点间通过高速RDMA网络连接在一起。为了保证原子性,每个POLARDB实例同时仅允许一个数据库节点处理写请求,且通过Parallel-Raft协议在写入时同时向存储节点写入3个副本。
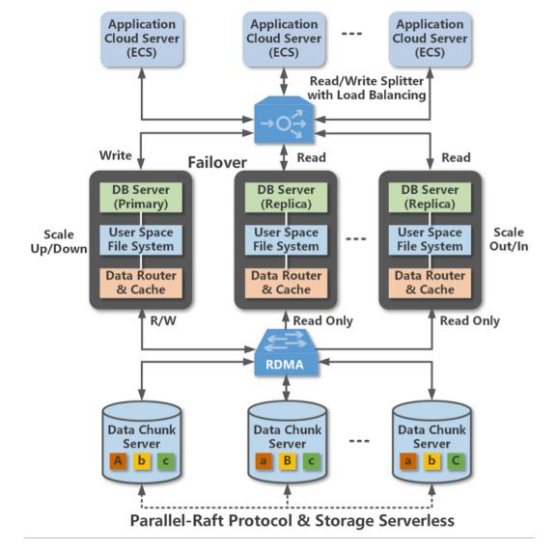
计算存储设备CSD是在具备基本存储功能同时具备数据处理能力的存储设备,相比使用CPU处理的模型,CSD采用的异构计算架构可以达到更好的性能和效率。但是CSD同时存在硬件成本更高、实际部署适配开发成本更高等问题。
动机
当前的POLARDB在数据库节点中处理表扫描任务,将扫操作下移到存储节点可以更好提升数据库处理分析型负载的性能、降低网络流量,而列存储需要扫描时更高的数据处理能力。
关键在于如何扩展存储节点使之支持处理额外的扫描任务。第一种方法是扩展存储节点的CPU,然而这会带来过高的成本问题;第二种方法是使用PCIe卡模式的FPGA扩展,但是这种方式同样存在:扫描作为数据密集型负载带来的数据传输流量过高导致的高功耗、负载间冲突,以及PCIe扩展卡带宽瓶颈等问题。最后一种是本文提出方式,即分布式异构架构,将表scan操作分散到每个存储设备中,由此带来的挑战包括:如何修改整个软件存储站以支持扫描操作下移;和如何降低FPGA的成本、提高FPGA并行性。
方法
本文首先解决了如何实现跨软件栈的扫描下移工作,包括了POLARDB的存储引擎、下层的分布式文件系统POLARFS以及可计算存储器CSD。
首先作者讲解了如何扩展POLARDB存储引擎,使得存储引擎可以将扫描任务传递给下层的POALRFS,并负责回收CSD返回的扫描结果,扫描任务的参数包括:被扫描数据的位置、被扫描表的结构以及扫描的条件。由于CSD难以支持所有的扫描条件(如LIKE),因此POLARDB的存储引擎在收到扫描请求时需要首先分析扫描条件,并将CSD可以处理的条件子集传递下去,并在收到CSD的结果后进行二次检查。
接着作者描述了如何扩展作为存储底层的分布式文件系统POLARFS,POLARFS负责管理所有存储节点上的数据。为了尽可能让文件的大部分数据块落在同一个CSD上,POLARFS采用了大粒度(4MB)条带,当出现极少数的一个压缩条带横跨两个CSD时,存储节点采用CPU处理对应的scan操作。在传递scan请求时,POLARDB存储引擎传递给POLARFS的是文件偏移表示的被扫描数据位置,而CSD仅能定位以LBA形式的数据位置,因此,POLARFS在收到POLARDB存储引擎的扫描请求书,会将横跨m个CSD的请求分割成m个扫描请求,并将扫描请求中的偏移转换到CSD的LBA。
之后作者描述了如何扩展CSD功能。CSD通过内核空间的驱动进行管理,每个CSD都暴露为一个块设备。驱动将收到的POLARFS转发的扫描请求分割成多个子任务,以解决大扫描任务长期占据NAND带宽,影响普通IO请求延迟性能的问题。同时,子任务有助于降低硬件资源的使用率,提高NAND访问的并行性,同时降低后台GC可能的过高延迟。
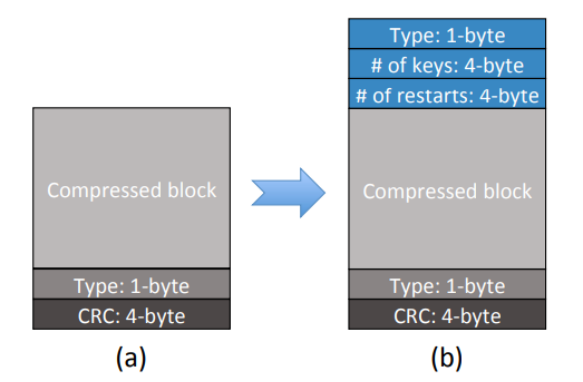
为了更好的降低成本,作者修改了POLARDB存储的数据块格式,以充分利用FPGA实现扫描功能。增加了1字节压缩类型,4字节的键值对数量和restarts键数量,这样使得CSD不需要POLARDB存储引擎传递块大小即可直接解压,同时可以高效处理restarts,并探测块结束情况。
由于FPGA难以实现多类型比较器,因此作者进一步修改POLARDB存储引擎,将所有数据都存储成同一的可比较格式,这样CSD只需要实现单一类型比较器,有助于降低FPGA资源开销。
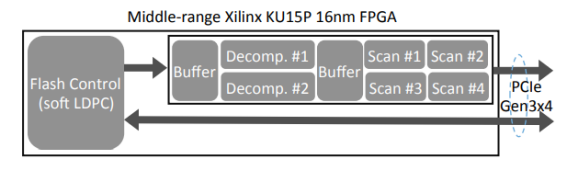
在实现时,作者采用了终端的FPGA同时用作闪存管理和存储计算单元,集成了软LDPC编码器,因此可以使用低成本的3D TLC/QLC以降低成本。作者使用FPGA实现了2个数据解压引擎和3个数据扫描引擎,支持 支持Snappy解压和=, ≠、>、≥、<、≤、NULL和!NULL条件。
评估
为了实际可用,CSD需要在满足存储计算的同时提供一流的IO性能,因此作者使用64层3D-TLC闪存,并支持了PCIe GEN3x4接口,达到了3.0GB/s和2.2GB/s的顺序读、写带宽,并做到在满盘、GC触发时590K/160K的4K随机读、写IOPS。在解压性能上,CSD的两个解压引擎实现了在60%和30%压缩率下,2.3GB/s和2.8GB/s的总解压吞吐量。
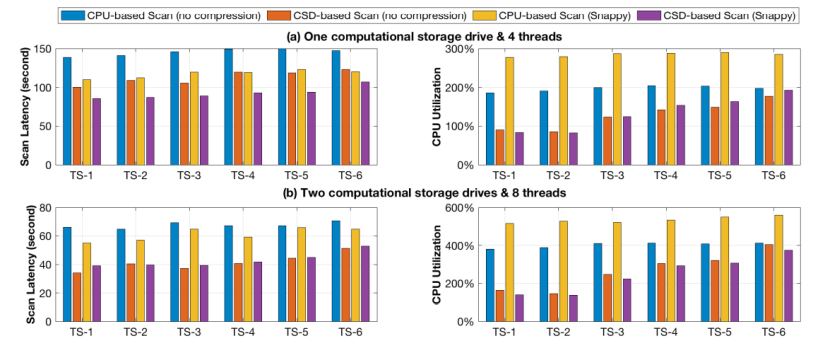
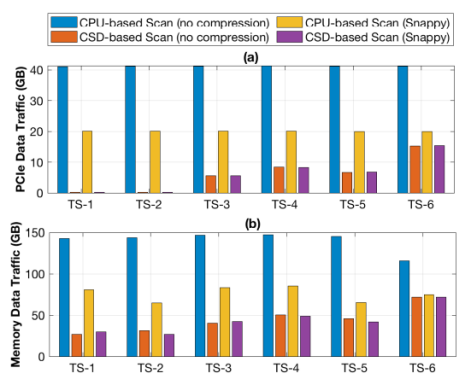
在使用TPC-H基准测试的LINEITEM表作为测试负载测试下,作者分别对比了下移扫描任务前后整体的扫描延迟和PCIe数据流量。对比项共有4个,分别是基于CPU、不进行压缩的扫描下移;基于CSD,无压缩的扫描下移;基于CPU有Snappy压缩的扫描下移以及基于CSD、有Snappy压缩的扫描下移。测试结果表明:相对于基于CPU的扫描下移,CSD将平均扫描延迟从55s降低到39s,同时CPU占用率从514%降低到140%,收益最低的TS-6测试项中,延迟依然从65s下降到53s,同时CPU利用率从558%降低到374%。测试同时发现,基于CSD的负载中,CPU负载与数据选择性正相关,即传输到CPU的数据越少,CPU负载越低,而基于CPU的扫描则与数据选择性无关。这说明基于CSD的扫描效率更高,且效率随着CSD规模增加可以扩展。
而从PCIe流量对比中可以发现,CSD的数据移动量更少,因此额外功耗更低。
之后作者进行了系统级评估,在POLARDB的云实例上运行TPC-H负载进行测试。每个实例运行32个SQL引擎容器,分布在7个数据库节点和3个后端存储节点上,每个存储节点包括12个3.7TB的CSD。分别考虑3个场景:1. 基准场景,即所有数据由存储节点传输到数据库节点进行处理;2. 基于CPU的下移场景,即扫描任务下移到存储节点的CPU上;3. 基于CSD的下移场景,即扫描任务下移到CSD上。
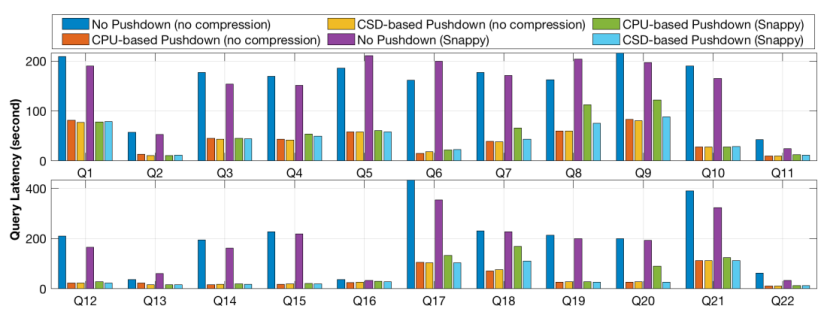
测试结果表明,随着请求数量增加,基于CSD的下移相比基于CPU的下移带来更多的延迟性能提升,这是由于随着并行请求数量增长,每个存储节点有更多的并行扫描任务,更利于硬件并行化;另外,基于CSD的下移在表进行压缩时表现出更高的性能提升,这是由于基于CPU的下移需要更多资源进行解压。
流量测试结果表明,基于CSD的扫描下移相比与基于CPU的扫描下移,在7个TPC-H并行查询时可以降低50%的PCIe流量,最大PCIe传输流量降低了97%,而12个并行TPC-H查询的网络总流量降低了70%。
总结
本文报告了跨软-硬件协同的阿里云关系型数据库POLARDBDA设计优化,以更高效处理分析型负载。其基本思想是将高开销的表扫描操作分发到CSD中,核心思想简单且与当前异构计算的工业趋势吻合。测试结果表明本文的设计在查询测试中可以获得超过30%的延迟性能提升,同时减少50%的存储-内存数据移动。作者表示,希望本工作可以激励更多关于如何在云基础设施更好利用CSD的探索。
The End
致谢
感谢本次论文解读者,来自华东师范大学的硕士生黄奕阳,主要研究方向为存储压缩、存储计算。
审核编辑:汤梓红
-
ICDE:POLARDB定义云原生数据库2018-04-20 3442
-
数据库厂商都怕低价竞争?阿里云说并不可惧2018-05-11 4077
-
重新定义数据库的时刻,阿里云数据库专家带你了解POLARDB2018-05-30 2766
-
云栖干货回顾 | 云原生数据库POLARDB专场“硬核”解析2019-10-15 2052
-
如何使用原生hqc连接MySQL数据库2020-06-08 1756
-
企业如何选择云计算数据库?2018-06-04 1207
-
OLAP数据库将全面地进入云原生时代,实现会数据库就会大数据2020-09-23 4612
-
阿里云PolarDB数据库将云原生进行到底!业内首次实现三层池化2021-10-20 2849
-
NVIDIA引入云原生超级计算架构2021-11-21 2966
-
华为云云原生数据库,激发数据活力2023-01-12 1362
-
深耕数据库根技术,华为云云原生数据库推动汽车产业数智升级2023-06-29 1015
-
云原生数据库GaiaDB架构设计解析2023-12-14 1463
-
华为云原生多模数据库 GeminiDB 架构与应用实践2024-04-08 2008
-
云原生和数据库哪个好一些?2024-11-29 1089
-
瀚高数据库深度参编国家标准《信息技术 云原生关系数据库管理系统技术要求》正式发布2026-04-15 459
全部0条评论

快来发表一下你的评论吧 !
