

基于实体和动作时空建模的视频文本预训练
描述
摘要
尽管常见的大规模视频-文本预训练模型已经在很多下游任务取得不错的效果,现有的模型通常将视频或者文本视为一个整体建模跨模态的表示,显示结合并建模细粒度信息的探索并不多,本文提出了STOA-VLP,一种时间和空间维度上同时建模动态的实体和动作信息的video-language预训练框架,以进一步增强跨模态的细粒度关联性。
简介
细粒度的信息对于理解视频场景并建模跨模态关联具有很重要的作用。如图1-a中:基于视频生成对应的视频描述,需要关注其中的人、狗两个实体,随着时间的推移,两个实体之间的相对状态和空间位置发生了变化,模型需要对动态的实体信息和实体之间的交互进行建模,才能正确地生成对应的视频描述。更进一步地,如图1-b中:在同一个视频片段当中,视频中的实体,如猴子和猫之间的不同交互产生了多个不同的动作状态,而问题就是针对相关联的动作提出的,模型不但需要建模视频片段中的多个动作,感知动作状态的变化,还需要推理出动作状态之间的关联才能得到正确的答案。
 图1:例子
图1:例子
在本文中,我们提出了一个视频-文本预训练方法——STOA-VLP,通过显式地建模时序相关的实体轨迹和多个时空动作特征来更好地应对视频中实体的动态变化和实体交互。此外,我们设计了两个辅助预训练任务:实体-文本对齐(object text alignment, OTA)任务和动作集合预测(Action Set Prediction, ASP)任务以在与训练阶段利用文本特征辅助建模前述的实体轨迹和动作特征。
方法
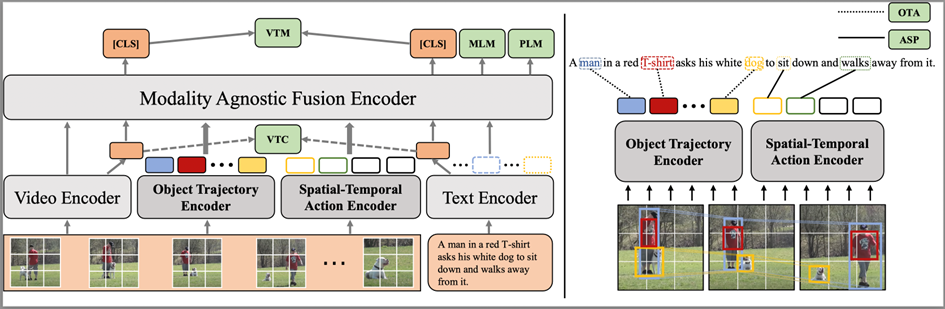 图2:模型整体架构
图2:模型整体架构
模型架构
模型的整体架构如图2左侧所示,模型整体结构包括模态相关编码器:视频编码器(Video Encoder)、文本编码器(Text Encoder)、和一个模态无关编码器(Modality-agnostic Fusion Encoder),文本和视频分别经过视频和文本编码器进行特征抽取。为了显式地建模动态的实体轨迹和时空动作特征,我们引入了两个新的特征编码器:实体轨迹编码器(Object Trajectory Encoder)和时空动作编码器(Spatial-Temporal Action Encoder),我们从视频帧中抽取实体的边界框(bounding box)信息,其中的实体bounding box、分类信息用于与视频特征结合生成对应的实体有噪标注,作为实体轨迹编码器和时空动作编码器的输入。最终,四个模态相关的编码器抽取的特征会同时进入模态无关编码器进行信息融合交互。所有的编码器都采用Transformer[1]结构。我们利用视频编码器和文本编码器分别得到对应的视频、文本特征和,其余各模块的具体介绍如下:
实体轨迹编码追踪器:正如前文例子所示,如果模型不能很好地建模视频帧之间实体的动态变化,在下游任务上可能无法获得最好的效果。因此,我们通过建模跨视频帧的有噪实体轨迹来解决这个问题:a. 使用离线的实体检测模型(VinVL[2])分别对每一帧进行实体检测。b. 每帧保留Top-K个不同的实体,并且留下其候选框和类别,通过RoIAlign方法[3] 得到top-K个实体的表征:,为视频编码器编码的视频特征的块(patch)级别的表征。c. 通过求和不同帧的候选实体检测分类置信分数,选取top-N个实体类别用作视频级需要建模轨迹的候选实体类别d. 我们将不同视频帧抽取得到的实体特征拼接,并合并时间和实体维度,得到对应的实体特征,针对步骤d中得到的Top-N实体类别,我们为每个类别构造一个mask ,mask位置为1,代表中对应位置的实体特征类别为。通过实体类别的mask和实体特征矩阵,我们能够掩码得到对应实体在不同帧的特征合成的特征轨迹,称之为实体轨迹序列。e. 对于每个视频,我们最终能够构造得到N个实体轨迹序列,我们将其输入实体轨迹编码器,最终取位置的特征,得到实体轨迹特征。
时空动作编码器:识别视频片段中动作的关键是,识别场景中的实体,并建模实体在视频场景中的移动和不同的交互。在此,我们显式建模多个动作特征,以捕捉视频片段中不同的动作信息。a. 我们假设视频片段中包含有M个不同的动作,为了获得每个动作的特征,我们构造M个动作特征请求(query),。b. 我们使用前述通过视频编码器和实体检测模型得到的视频特征和对应的实体表征,拼接得到包含场景和实体信息的视频特征。c. 我们利用动作特征query,通过注意力机制获得帧级别的动作特征线索:。d. 我们将每个动作特征序列输入到时空动作编码器当中,来建模不同帧之间包含的时序线索,最后,我们得到的动作特征编码。
模态无关交互编码器:通过拼接上游四个步骤的特征:视频表征、文本表征、实体轨迹特征、时空动作特征输入对应的编码器进行进一步的交互,最后,我们取和位置的输出作为视频和文本的整体表征。
训练目标
如图2所示,STOA-VLP的预训练过程包含四类训练目标:视频-文本对齐任务、条件语言建模任务,以及我们提出的两个辅助任务——动态实体-文本对齐(Dynamic Object-Text Alignment, OTA)和时空动作集合预测(Spatial-Temporal Action Set Prediction, ASP)。我们利用视觉-文本对比学习任务(Visual-Text Contrastive, VTC)和视觉-文本对齐任务(Visual-Text Maching)建模视频-文本的粗粒度对齐。利用掩码语言建模(MLM)和前缀语言建模(PLM)来增强模态无关编码器的语言理解和生成能力。为了进一步提升实体轨迹追踪编码器的效果,建立细粒度的跨模态对齐表示,我们通过OTA任务对齐候选实体轨迹和文本中相关文本,以进一步提高通过视频特征得到的实体轨迹和文本特征的相关性:
通过词性标注工具,抽取文本中的名词用作对齐候选,并使用对应的文本编码器输出对应的名词特征
使用轨迹追踪编码器输出的轨迹特征和名词特征的相似度为他们之间的关联权重
最终使用匈牙利算法[4]得到二分图的最大匹配,模型的目标是尽力提高最大匹配的相似度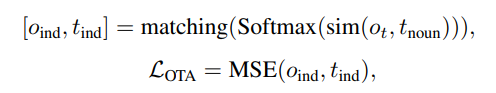 相比于利用抽取得到的特征直接预测有限的动作类别,我们在这里选择了一种更弹性的方法——从匹配文本中的动词集合中预测对应于当前动作特征的类别,以指导时空动作编码器的学习:
相比于利用抽取得到的特征直接预测有限的动作类别,我们在这里选择了一种更弹性的方法——从匹配文本中的动词集合中预测对应于当前动作特征的类别,以指导时空动作编码器的学习:
我们利用词性标注工具和文本编码器得到对应的动词特征集合。
我们并不能直接标注视频中包含的动作类别,也无法知道编码得到的动作特征和文本中包含动作的对应关系,因此我们同样在这里通过动作特征和文本动词特征之间的相似度作为关联权重,并将最大匹配视为当前的ground truth匹配关系,并最大化最大匹配的相似度: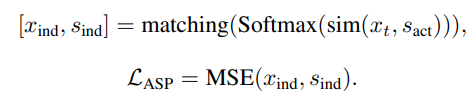 通过优化该目标,比我们编码的动作特征和文本中的动词特征距离将被拉近,动作编码器能够生成和文本特征更相关的特征。
通过优化该目标,比我们编码的动作特征和文本中的动词特征距离将被拉近,动作编码器能够生成和文本特征更相关的特征。
实验
实验细节
我们在WebVid-2M[5]数据集上进行模型的预训练,WebVid-2M包含了250万个从网络中收集的视频-文本对。我们利用CLIP-ViT-B/16[6]初始化我们的视频编码器,并用其顶层参数初始化实体轨迹编码器和时空动作编码器。文本编码器和模态编码器由CLIP文本编码器的前6层初始化。实体轨迹编码的数量为20,动作特征的个数为4。
下游任务
我们在三类常用的视频-文本理解和生成任务上进行了实验:视频描述生成,文本-视频检索和视频问答。
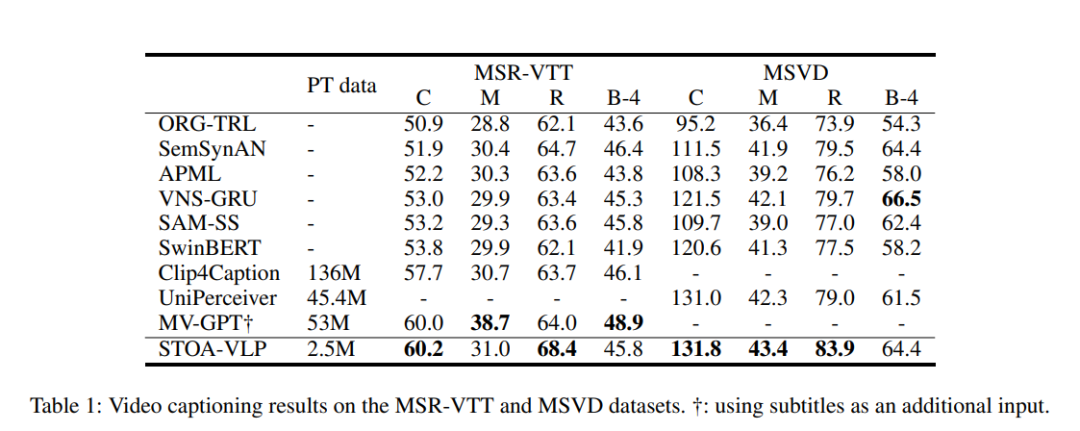 表1:视频描述生成的实验结果
表1:视频描述生成的实验结果
在使用更少的视频-文本预训练数据的情况下,我们的模型在视频描述生成上得到了更好的结果,在多数指标上都超过了其他的模型。通过显式地建模基于文本信息对齐的实体轨迹和动作信息,模型能够更好地利用其进行视频描述生成。
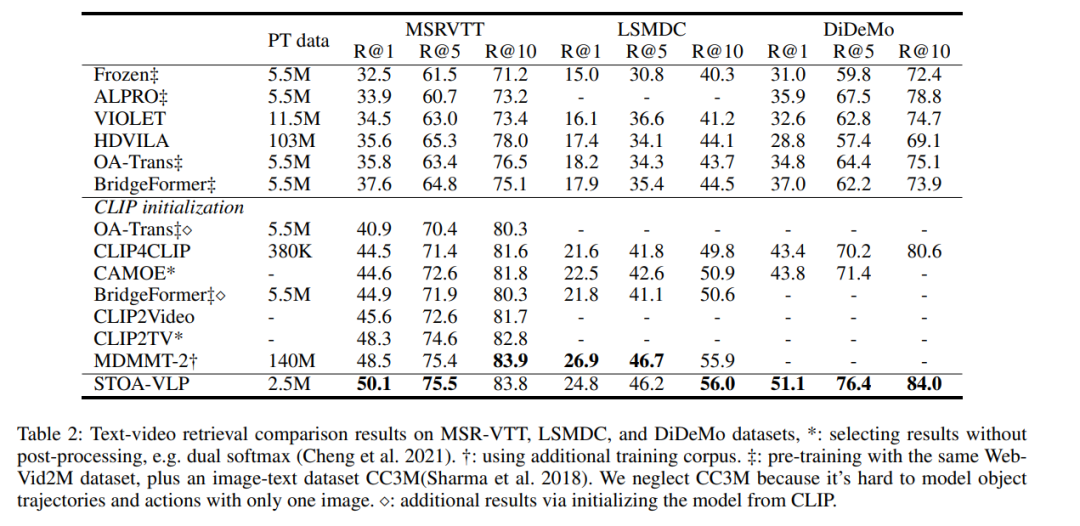 表2:文本-视频检索的实验结果
表2:文本-视频检索的实验结果
如表2所示,我们的模型在检索任务上的所有指标都超过了未基于CLIP初始化的模型,并且在大多数指标上均超过了基于CLIP初始化的模型。
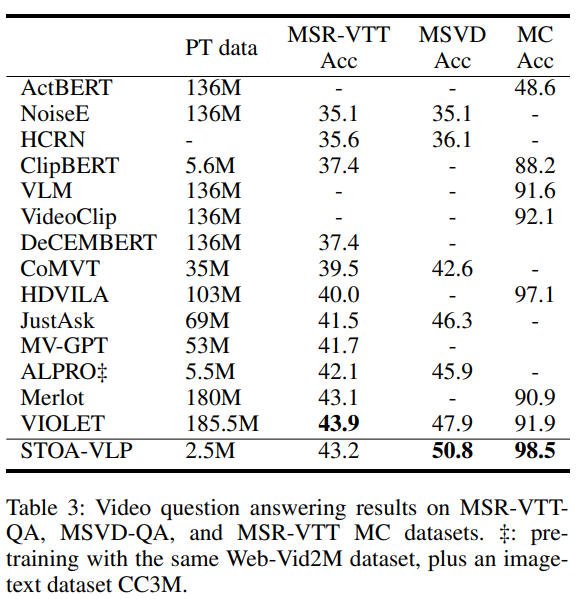 表3:视频问答的实验结果
表3:视频问答的实验结果
如表3所示,在视频问答任务上,我们的模型仅使用了2.5M的预训练数据,超越了MSVD-QA上的所有其他方法。与之前的SOTA,MSVD-QA的性能提高2.9%,MSR-VTT-MC的性能提高1.4%。我们推测,通过显式地建模实体轨迹和动作,在问题和视觉特征之间建立了更好的对齐,并观察和利用视频中的细粒度信息来更好地回答文本问题。
消融实验
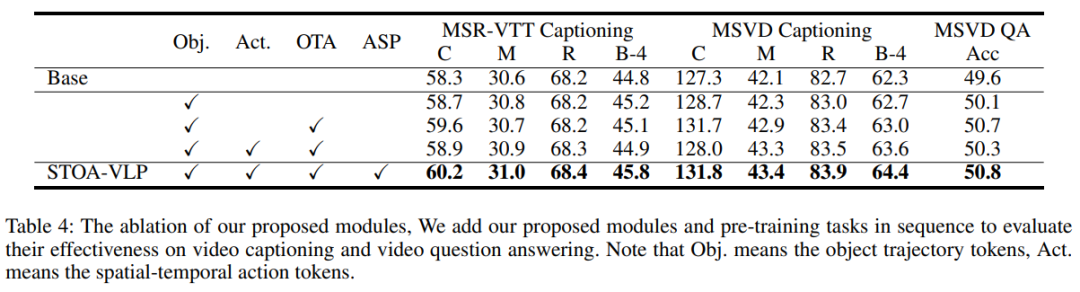 表4:不同模块的消融实验
表4:不同模块的消融实验
我们进一步分析了我们引入的时空特征和辅助任务的影响,并在视频描述生成和视频问答两个任务上验证,这两个任务在本质上需要更细粒度的信息和对视频场景时空信息的理解。Base模型删除了所有时空建模模块和辅助建模任务。与Base模型相比,仅仅引入基于时序的实体轨迹信息就可以为所有任务带来改进。我们的OTA任务进一步构建了实体轨迹和名词之间的细粒度对齐,文本模态的指导进一步提升了模型在下游任务当中的表现。我们还发现,不引入辅助任务ASP的情况下,添加一个时空动作建模模块引入时空动作token会使得下游任务的部分指标更差。我们认为,这可能是因为视频描述生成和视频问答任务需要对视觉部分进行细粒度的语义理解,如果没有ASP任务的指导,我们抽取的动作特征的含义是模糊的,其导致了性能下降。最后,连同我们提出的时空模块和两个辅助任务,我们在下游任务上取得了最好的结果,表明我们引入的细粒度时空信息和辅助任务能够提升预训练模型在下游任务的能力,一定程度上缓解了前述的问题。
结论
在本文中,我们通过在视频-文本预训练的过程中显式建模细粒度的时空特征来更好地构建跨模态的对齐。我们提出的STOA-VLP引入了两个新的模块,在时空维度上建模实体轨迹和动作特征。我们设计了两个辅助任务来建立由粗到细的跨模态对齐。仅仅使用中等规模的与训练数据,我们在下游任务上就观察到了较好的表现,该方法进一步增强了视觉特征和文本特征之间的关联性。
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1594
-
NLP中的迁移学习:利用预训练模型进行文本分类2023-06-14 943
-
ELMER: 高效强大的非自回归预训练文本生成模型2023-03-13 2637
-
预训练数据大小对于预训练模型的影响2023-03-03 2716
-
复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型2022-12-14 1842
-
基于VQVAE的长文本生成 利用离散code来建模文本篇章结构的方法2022-12-01 2986
-
利用视觉语言模型对检测器进行预训练2022-08-08 2533
-
文本预训练的模型架构及相关数据集2022-07-01 3284
-
如何实现更绿色、经济的NLP预训练模型迁移2022-03-21 3276
-
多模态图像-文本预训练模型2021-09-06 5090
-
怎样去增强PLM对于实体和实体间关系的理解?2021-06-23 1897
-
基于BERT的中文科技NLP预训练模型2021-05-07 1257
-
一种侧重于学习情感特征的预训练方法2021-04-13 1229
-
为什么要使用预训练模型?8种优秀预训练模型大盘点2019-04-04 24726
全部0条评论

快来发表一下你的评论吧 !
