

在一个简单的Mean Teacher架构中双向复制粘贴标记和未标记的数据
描述
导读
在半监督医学图像分割中,标记和未标记数据分布之间存在经验不匹配问题。本文提出了一种简单的方法来缓解这个问题—在一个简单的 Mean Teacher 架构中双向复制粘贴标记和未标记的数据。

Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation
论文链接:https://arxiv.org/pdf/2305.00673.pdf
源码链接:https://github.com/DeepMed-Lab-ECNU/BCP
简介
从CT或MRI等医疗图像中分割内部结构对于许多临床应用至关重要。已经提出了各种基于监督学习的医疗图像分割技术,这通常需要大量标注数据。然而由于在标注医疗图像时手动轮廓绘制过程繁琐且昂贵,近年来,半监督分割越来越受到关注,并在医疗图像分析领域变得无处不在。
一般地,在半监督医疗分割领域,标签数据和无标签数据从相同分布抽取。但在现实世界中,很难从标记数据中估计准确的分布,因为它们数据很少。因此,在大量未标注数据和极少量标注数据宗师存在经验分布不匹配。半监督分割方法总是尝试以一致的方式对称地训练标注和未标注数据。例如子训练生成为标签,以伪监督方式监督未标注数据。基于Mean Teacher的算法采用一致性损失来监督具有强增强的未标注数据,类似于监督具有GT的标注数据。ContrastMask在标注数据和未标注数据上应用密集对比学习。但是大部分已有的半监督算法在不同学习范式下使用标注和未标注数据。
CutMix是一种简单但强大的数据处理方法,也被称为复制黏贴(CP),它有可能鼓励未标注的数据从标注数据中学习常见的语义,因为同一图中的像素共享的语义更接近。在半监督学习中,未标注数据的弱-强增强对之间的强制一致性被广泛使用,并且CP通常被用作强增强。但现有的CP方法未考虑CP较差未标注数据,或者简单地将标注数据中物体复制为前景并黏贴到另一个数据。它们忽略了为标记数据和未标记数据设计一致的学习策略,这阻碍了其在减少分布差距方面使用。同时,CP试图通过增加未标注数据的多样性来增强网络泛化能力,但由于CutMix图像仅由低精度伪标签监督,因此很难实现高性能。
为了缓解标注数据和未标注数据之间经验不匹配问题,一个成功的设计是鼓励未标注数据从标注数据中学习全面的公共语义,同时通过对标注数据和未标注数据的一致学习策略来促进分布对齐。本文通过提出一种简单但非常有效的双向复制黏贴(BCP)方法实现这一点。该方法在Mean Teacher框架中实例化。具体地,为了训练学生网络,本文通过将随机裁剪从标记图像(前景)复制黏贴到未标注图像(背景)来增加输入。繁殖将随机裁剪从五标注图像(前景)复制黏贴到标注图像(背景)来增加输入。学生网络由生成的监督信息通过来自教师网络的未标注图像伪标签和标注图像的标签图之间的双向复制黏贴进行监督。这两个混合图像有助于网络双向对称地学习标注数据和未标注数据间通用语义。
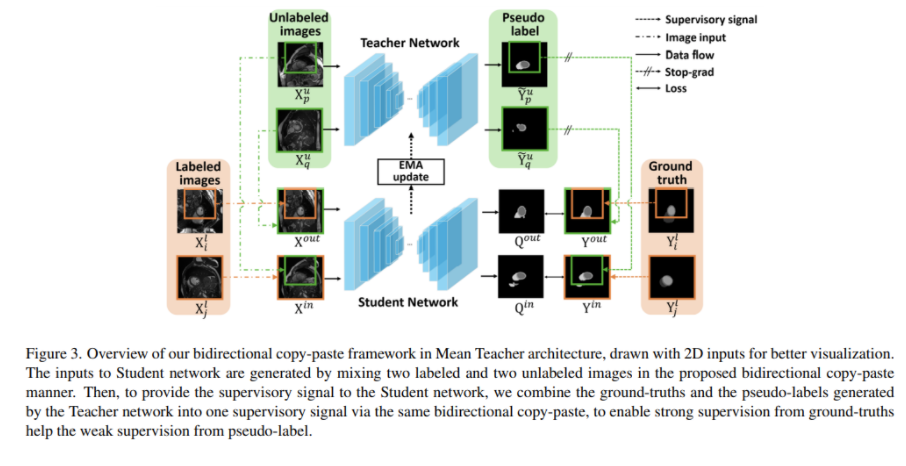
本文方法
定义三维医疗图像为。医疗图像半监督语义分割目标是预测每体素标签映射指示中背景和目标的位置。训练集包含个标注数据和个未标注数据(),即,,。
在本文的Mean Teacher架构中,随机选择两个未标注图像,两个标注图像。之后从复制黏贴一个随机块到生成混合图像,从到生成另一个混合图像。无标注图像能够从标注图像中从向内(inward)和向外(outward)方向学习全面的通用语义。图像和之后传入学生网络预测分割掩码和。通过双向复制黏贴来自教师网络的未标注图像预测和标注图像标签图来监督分割掩码。
Mean Teacher和训练策略
在本文BCP框架中,有一个教师网络和学生网络。学生网络由SGD优化,教师网络是学生网络的指数移动平均。本文的训练策略包括三个步骤:首先使用标注数据预训练一个模型,然后使用预训练模型作为教师模型为未标注图像产生伪标签。在每一个周期,首先使用SGD优化学生网络参数。最后使用学生参数的指数移动平均更新教师网络参数。
通过复制-黏贴预训练
本文对标注数据进行了复制黏贴增广来训练监督模型,监督模型在自训练过程中会为未标注数据生成伪标签。该策略已被证明能有效提高分割性能。
双向复制-黏贴
在一堆图像间执行复制黏贴,首先需要生成零-中心掩码,指示体素来自前景(0)或背景(1)图像。零值区域大小为。双向复制黏贴过程可以描述为:
双向复制黏贴监督信号
为了训练学生网络,监督信号也是由BCP操作产生。无标注的图像和传入教师网络,计算概率图:
初始的伪标签由一个通常的二值化分割任务的阈值0.5决定,或者多标签分割任务使用argmax操作。最后的伪标签由选择最大的连接组件,这操作可以有效地移除离群体素。之后提出双向复制-黏贴无标注图像伪标签和有标注GT标签获得监督信号。
损失函数
学生网络的每个输入图像由来自标注图像和未标注图像分量组成。直观地,标记图像的GT掩码通常比未标注图像的伪标记更准确。使用控制无标注图像像素对损失函数的影响:
教师网络参数更新:
实验
LA数据集
心房分割挑战[39]数据集包括100个带标签的三维钆增强磁共振图像扫描(GE MRI)。
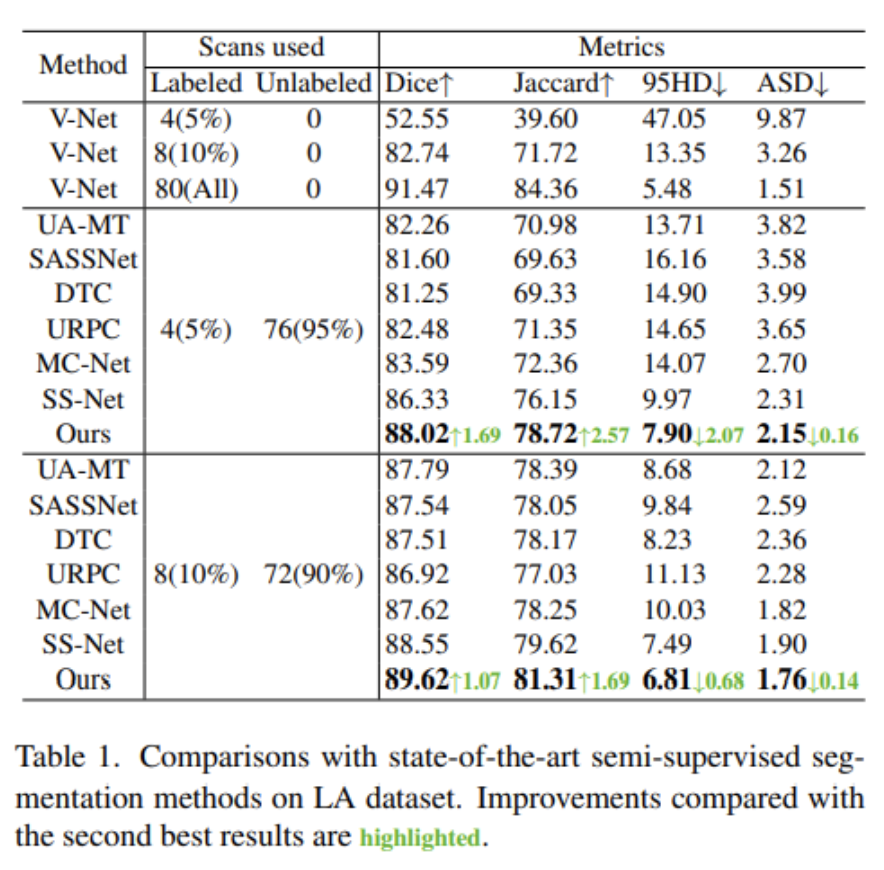
这里选择UA-MT,SASSNet,DTC,URPC,MC-Net,SS-Net作为比较模型。这里给出了不同标签率下的实验结果。表1给出了相关实验结果。可以看出本文方法在4个评价指标上都获得最高的性能,大幅度超过比较模型。
Pancreases-NIT数据集
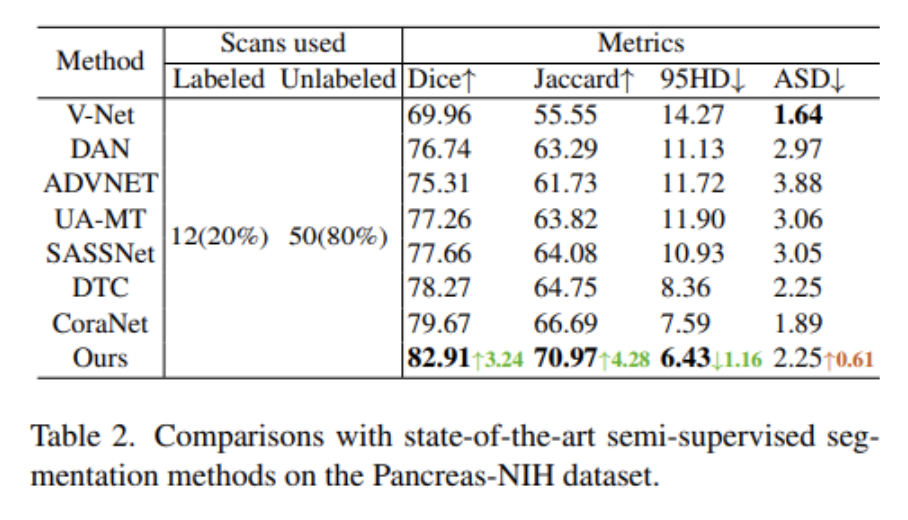
82个人工绘制的腹部CT增强体积。这里选择V-Net,DAN,ADVNET,UA-MT,SASSNet,DTC和CoraNet作为比较算法。表2给出了相关实验结果。本文方法BCP在Dice、Jaccard和95HD指标上实现了显著的改进(即分别以3.24%、4.28%和1.16的优势超过第二好)。这些结果没有进行任何后期处理以进行公平比较。
ACDC数据集
四类(即背景、右心室、左心室和心肌)分割数据集,包含100名患者的扫描。表3给出了相关实验结果。BCP超越了SOTA方法。对于标记比率为5%的设置,我们在Dice指标上获得了高达21.76%的巨大性能改进

审核编辑 :李倩
-
微软win10的复制粘贴功能再迎升级2021-02-22 2440
-
Edge浏览器复制粘贴出错的原因和方法2020-12-15 9435
-
如何快速复制粘贴导线?2019-09-25 1921
-
直接复制粘贴到另一个PCB里面去为什么网络标识会没有?2019-04-22 6067
-
一种基于关键点的复制粘贴盲检测算法2017-12-11 722
-
***的内电层怎样复制粘贴?2017-07-06 4357
-
可双向复制粘贴图片 向日葵Windows客户端9.0.3发布2017-06-27 1951
-
基于非负矩阵分解的图像复制粘贴伪造检测2017-01-07 807
-
JAVA教程之使用剪贴板的复制粘贴程序2016-03-31 568
-
labview 如何把excel 的内容(包括格式)复制粘贴?2015-11-29 8001
-
multisim12:为什么电路复制粘贴到另一个文件中仿真时就会报错?2015-09-27 16312
-
dxp2004 复制粘贴 就死机2012-08-11 14174
-
[请教] 可否使用简单的复制粘贴,将多块pcb合成一块,多谢!2011-01-29 4470
全部0条评论

快来发表一下你的评论吧 !
