

自训练Pytorch模型使用OpenVINO™优化并部署在AI爱克斯开发板
描述
完成人:深圳技术大学 黎逸鹏(中德智能制造学院2021级本科生)
指导教授:张阳(英特尔边缘计算创新大使,深圳技术大学中德智能制造学院副教授)
简介
本文章将依次介绍如何将 Pytorch 自训练模型经过一系列变换变成 OpenVINO IR 模型形式,而后使用 OpenVINO Python API 对 IR 模型进行推理,并将推理结果通过 OpenCV API 显示在实时画面上。
本文 Python 程序的开发环境是 Ubuntu20.04 LTS + PyCharm,硬件平台是 AIxBoard 爱克斯板开发者套件。
本文项目背景:针对2023第十一届全国大学生光电设计竞赛赛题2“迷宫寻宝”光电智能小车题目。基于该赛项宝藏样式,我通过深度学习训练出能分类四种不同颜色不同标记形状骨牌的模型,骨牌样式详见图1.1。
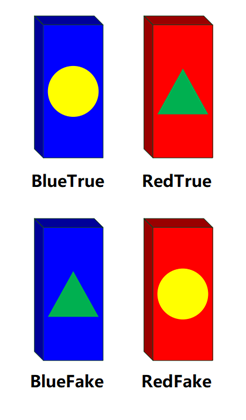
图1.1 四种骨牌类型
完整指导视频
1.2/Pytorch pth 模型转换成
OpenVINO IR模型
Pytorch是 一个基于 Torch 的开源 Python 学习库,是一个以 Python 优先的深度学习框架。Pth 模型文件是 Pytorch 进行模型保存时的一种模型格式,OpenVINO 暂不支持直接对 Pth 模型文件进行推理,所以我们要将 Pth 格式的模型先转换成 ONNX 格式文件,再通过 OpenVINO 自带的 Model Optimizer(模型优化器)进一步转变成 OpenVINO IR 模型。处理过程如下所示:
1. 通过 Pytorch 将 Pth 模型转换成 ONNX 模型
转换后的文件(Pth —> ONNX):
import torch.onnx
# SZTU LIXROBO 23.5.14 #
#******************************************#
# 1. 模型加载
model = torch.load('Domino_best.pth', map_location=torch.device('cpu'))
# 2. 设置模型为评估模式而非训练模式
model.eval()
# 3. 生成随机从标准正态分布抽取的张量
dummy_input = torch.randn(1,3,224,224,device='cpu')
# 4. 导出ONNX模型(保存训练参数权重)
torch.onnx.export(model,dummy_input,"Domino_best.onnx",export_params=True)
2. 通过终端来将 ONNX 模型转化成 OpenVINO IR 模型格式
在终端中输入(Terminal):
mo --input_model Domino_best.onnx --compress_to_fp16
# mo 启动OpenVINO 的Model Optimizer(模型优化器)
# input_model 输入您转换的ONNX模型内容根的路径
# compress _to_fp16 将模型输出精度变为FP16
等后一会,终端输出:

代表 ONNX 模型转换成 OpenVINO IR 模型成功。这里的信息告诉我们该 Model 是 IR 11 的形式,并分别保存在 .xml 和 .bin 文件下。
转换后的文件(ONNX —> IR 11):
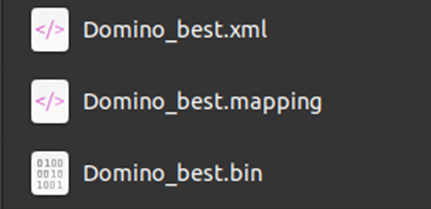
mapping 文件是一些转换信息,暂时不会用到该文件。
至此,我们模型转换的全部工作已经完成,接下来就是运用 OpenVINO Runtime 对 IR 11 模型进行推理。
1.3/用OpenVINO Runtime
对 IR 11 模型进行推理
在这一章节里我们将在 Pycharm 中使用 OpenVINO Runtime 对我们在1.2章中转换得来的 IR 11 模型进行推理,并将推理结果实时展现在摄像头画面中。
在开始之前,我们不妨了解推理程序的整个工作流程:
导入必要的功能库(如 openvino.runtime 以及 cv2和 numpy)
探测硬件平台所能使用的可搭载设备
创建核心对象以及加载模型和标签
输入图像进行预处理,正则化,转变成网络输入形状
将处理后的图像交由推理程序进行推理,得到推理结果和处理时间并显示出来
1.3.1. 导入功能包
import openvino.runtime as ov
import numpy as np
import cv2
import time
这里一共导入4个功能包
openvino.runtime 这是 openvino runtime 推理的主要功能包,也可用 openvino.inference_engine 进行推理,过程大体是一致的。
numpy 这是常用的一个 Python 开源科学计算库
cv2 也即 OpenCV,用来处理有关图像的一些信息
time 记录系统运行时间
1.3.2 设备检测以及模型载入
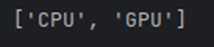
我们可以使用 Core 对象中的 available_devices 函数来获取当前硬件平台可供推理引擎使用的设备。
core = ov.Core()
print(core.available_devices)
如图所示我们能得到在 AlxBoard 爱克斯开发板上可供我们使用的推理设备有 CPU 和 GPU。
将模型进行载入:
# SZTU LIXROBO 23.5.19 #
#************************************#
# 1. 创建核心对象
core = ov.Core()
# 2. 规定IR 11模型的模型文件和权重文件
model = "Domino_best.xml"
weights = "Domino_best.bin"
# 3. 将模型文件和权重文件进行读取
model_ir = core.read_model(model= model,weights=weights)
# 4. 把模型加载到设备上
(此处使用HETERO插件进行异构,加载到GPU和CPU上)
com_model_ir= core.compile_model(model=model_ir,device_name="HETERO:GPU,CPU")
# 5. 获取模型输出层
output_layer_ir = com_model_ir.outputs[0]
# 6. 由于是简单模型,故label手动注入,也可使用导入标签文件等其他方式
label = ['BlueFake','BlueTrue','RedFake','RedTrue']
1.3.3 图像预处理
得到的图像我们需要做一些预先处理才能输入到推理引擎中进行推理并得到结果。这一小节我们将展示如何把图像进行处理。
#************************************#
# 图像预处理、归一化 #
def normalize(img: np.ndarray) ->np.ndarray:
# 1. 类型转换成np.float32
img = img.astype(np.float32)
# 2. 设置常用均值和标准差来正则化
mean =(0.485,0.456,0.406)
std =(0.299,0.224,0.255)
img /=255.0
img -=mean
img /=std
# 3. 返回处理后的img
return img
#************************************#
# 图像处理函数 #
def img_pre(img):
# 1. 对OV输入图像颜色模型从BGR转变成RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 2. 对图像进行裁切
res_img = cv2.resize(img, (224, 224))
# 3. 使用我们定义的预处理函数对图像进行处理
nor_img = normalize(res_img)
# 4. 将处理好的图像转变为网络输入形状
nor_input_img = np.expand_dims(np.transpose(nor_img, (2, 0, 1)), 0)
# 5. 返回处理结果
return nor_input_img
1.3.4 推理过程以及结果展示
在上一节中我们把输入图像所要进行的预处理图像进行了一个定义,在这一小节则是 OpenVINO Runtime 推理程序的核心。
#************************************#
# 推理主程序 #
def image_infer(img):
# 1. 设置记录起始时间
start_time = time.time()
# 2. 将图像进行处理
imgb = img_pre(img)
# 3. 输入图像进行推理,得到推理结果
res_ir = com_model_ir([imgb])[output_layer_ir]
# 4. 对结果进行归一化处理,使用Sigmod归一
Confidence_Level = 1/(1+np.exp(-res_ir[0]))
# 5. 将结果进行从小到大的排序,便于我们获取置信度最高的类别
result_mask_ir = np.squeeze(np.argsort(res_ir, axis=1)).astype(np.uint8)
# 6. 用CV2的putText方法将置信度最高对应的label以及其置信度绘制在图像上
img = cv2.putText(img,str(label[result_mask_ir[3]])+' '+ str(Confidence_Level[result_mask_ir[3]]),(50,80), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2,cv2.LINE_AA)
# 7. 记录推理结束时间
end_time = time.time()
# 8. 计算出摄像头运行帧数
FPS = 1 / (end_time - start_time)
# 9. 将帧数绘制在图像上
img = cv2.putText(img, 'FPS ' + str(int(FPS)), (50, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2,cv2.LINE_AA)
# 10. 返回图像
return img
以上推理函数编写已经完成。以下是运行主程序:
#********************主程序***********************#
# 1. 获取摄像头
cap = cv2.VideoCapture(0)
# 2. 循环判断
while 1:
# 1. 获得实时画面
success,frame = cap.read()
# 2. 把实时画面交由推理函数进行推理
frame = image_infer(frame)
# 3. 将画面显示在窗口
cv2.imshow("img",frame)
cv2.waitKey(1)
当我们运行该程序时,会得到如下画面。
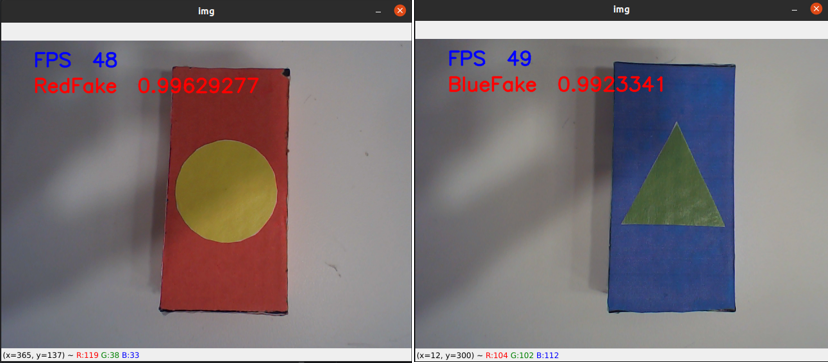
如图所示,我们的 Pytorch 模型成功在 OpenVINO 的优化以及推理下成功部署在 AlxBoard 爱克斯开发板,帧数在40-60之间,推理的结果非常好,很稳定。
1.4 /与 Pytorch 模型
CPU 推理进行比较
原先推理的过程我们是通过 torch 功能库进行推理,我们将两者进行比较。
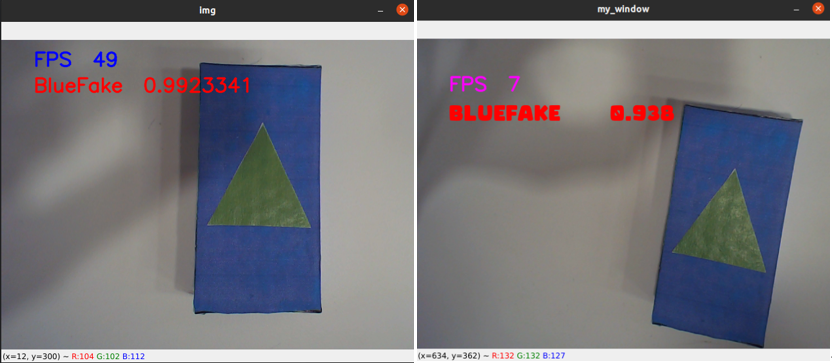
(左为 OpenVINO 优化推理,右为 torch 推理)
如图所示 OpenVINO 优化推理过后的结果从实际帧数上看大约有5-8倍的提升,推理精度也有少许加强。
1.5结论
自训练 Pytorch 模型在通过 OpenVINO Model Optimizer 模型优化后用 OpenVINO Runtime 进行推理,推理过程简单清晰。推理仅需几个核心函数便可实现基于自训练 Pytorch 模型的转化以及推理程序。
OpenVINO 简单易上手,提供了强大的资料库供学者查阅,其包含了从模型建立到模型推理的全过程。
审核编辑:汤梓红
-
使用OpenVINO™ 2021.4将经过训练的自定义PyTorch模型加载为IR格式时遇到错误怎么解决?2025-03-05 374
-
C#集成OpenVINO™:简化AI模型部署2025-02-17 3139
-
使用OpenVINO Model Server在哪吒开发板上部署模型2024-11-01 1496
-
基于Pytorch训练并部署ONNX模型在TDA4应用笔记2024-09-11 579
-
【KV260视觉入门套件试用体验】Vitis AI 构建开发环境,并使用inspector检查模型2023-10-14 12115
-
基于OpenVINO在英特尔开发套件上实现眼部追踪2023-09-18 1657
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2987
-
如何将Pytorch自训练模型变成OpenVINO IR模型形式2023-06-07 3519
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 2239
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 2962
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2853
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8分类模型2023-05-05 2054
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 12552
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5207
全部0条评论

快来发表一下你的评论吧 !
