

AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型
描述
《在AI爱克斯开发板上用OpenVINO加速YOLOv8分类模型》介绍了在AI爱克斯开发板上使用OpenVINO 开发套件部署并测评YOLOv8的分类模型,本文将介绍在AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型。 请先下载本文的范例代码仓,并搭建好YOLOv8的OpenVINO推理程序开发环境。 git clone https://gitee.com/ppov-nuc/yolov8_openvino.git 导出YOLOv8 目标检测OpenVINO IR模型 YOLOv8的目标检测模型有5种,在COCO数据集完成训练,如下表所示。 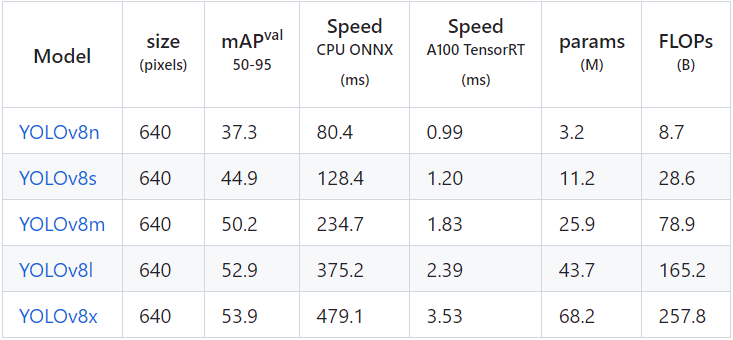 首先使用命令:yolo export model=yolov8n.pt format=onnx,完成yolov8n.onnx模型导出,如下图所示。
首先使用命令:yolo export model=yolov8n.pt format=onnx,完成yolov8n.onnx模型导出,如下图所示。 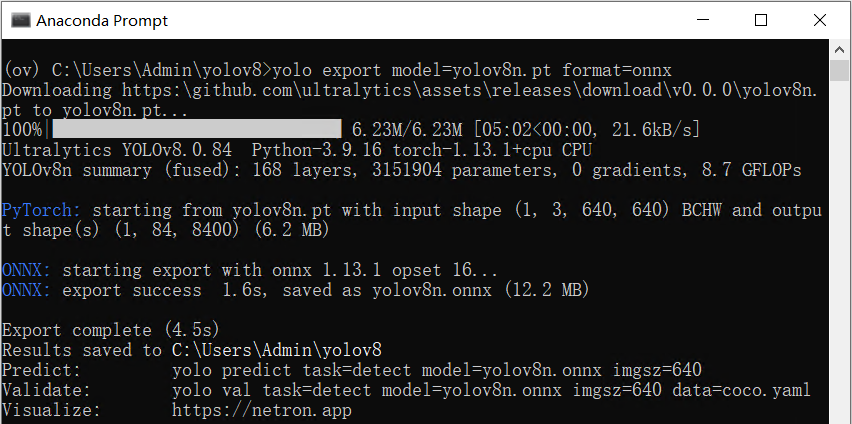 然后使用命令:mo -m yolov8n.onnx --compress_to_fp16,优化并导出FP16精度的OpenVINO IR格式模型,如下图所示。
然后使用命令:mo -m yolov8n.onnx --compress_to_fp16,优化并导出FP16精度的OpenVINO IR格式模型,如下图所示。 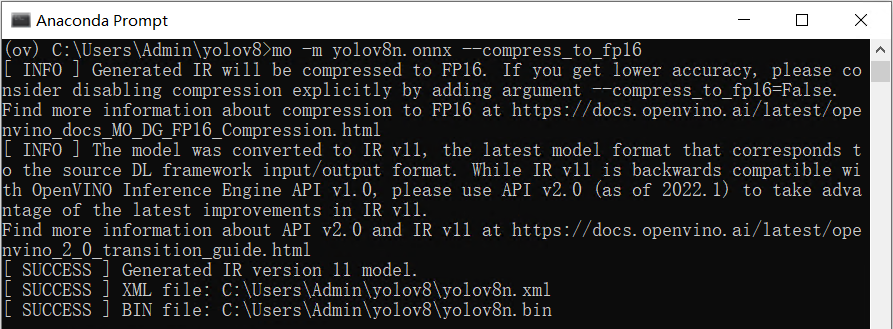 用benchmark_app测试yolov8目标检测模型的推理计算性能 benchmark_app是OpenVINOTM工具套件自带的AI模型推理计算性能测试工具,可以指定在不同的计算设备上,在同步或异步模式下,测试出不带前后处理的纯AI模型推理计算性能。 使用命令:benchmark_app -m yolov8n.xml -d GPU,获得yolov8n.xml模型在AI爱克斯开发板的集成显卡上的异步推理计算性能,如下图所示。
用benchmark_app测试yolov8目标检测模型的推理计算性能 benchmark_app是OpenVINOTM工具套件自带的AI模型推理计算性能测试工具,可以指定在不同的计算设备上,在同步或异步模式下,测试出不带前后处理的纯AI模型推理计算性能。 使用命令:benchmark_app -m yolov8n.xml -d GPU,获得yolov8n.xml模型在AI爱克斯开发板的集成显卡上的异步推理计算性能,如下图所示。 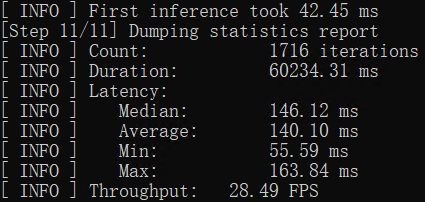 使用OpenVINO Python API编写YOLOv8目标检测模型推理程序 用Netron打开yolov8n.onnx,如下图所示,可以看到模型的输入是形状为[1,3,640,640]的张量,输出是形状为[1,84,8400]的张量,其中“84”的定义为:cx,cy,h,w和80种类别的分数。“8400”是指YOLOv8的3个检测头在图像尺寸为640时,有640/8=80, 640/16=40, 640/32=20, 80x80+40x40+20x20=8400个输出单元格。
使用OpenVINO Python API编写YOLOv8目标检测模型推理程序 用Netron打开yolov8n.onnx,如下图所示,可以看到模型的输入是形状为[1,3,640,640]的张量,输出是形状为[1,84,8400]的张量,其中“84”的定义为:cx,cy,h,w和80种类别的分数。“8400”是指YOLOv8的3个检测头在图像尺寸为640时,有640/8=80, 640/16=40, 640/32=20, 80x80+40x40+20x20=8400个输出单元格。 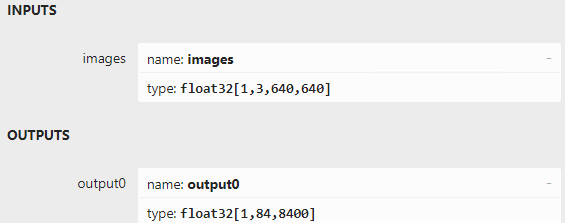 基于OpenVINO Python API的YOLOv8目标检测模型的范例程序:yolov8_od_ov_sync_infer_demo.py,其核心源代码如下所示:
基于OpenVINO Python API的YOLOv8目标检测模型的范例程序:yolov8_od_ov_sync_infer_demo.py,其核心源代码如下所示:
# 实例化Core对象
core = Core()
# 载入并编译模型
net = core.compile_model(f'{MODEL_NAME}.xml', device_name="AUTO")
# 获得模型输出节点
output_node = net.outputs[0] # yolov8n只有一个输出节点
ir = net.create_infer_request()
cap = cv2.VideoCapture("store-aisle-detection.mp4")
while True:
start = time.time()
ret, frame = cap.read()
if not ret:
break
# 图像数据前处理
[height, width, _] = frame.shape
length = max((height, width))
image = np.zeros((length, length, 3), np.uint8)
image[0:height, 0:width] = frame
scale = length / 640
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
# 执行推理计算
outputs = ir.infer(blob)[output_node]
# 推理结果后处理并显示处理结果
outputs = np.array([cv2.transpose(outputs[0])])
... ...
cv2.imshow('YOLOv8 OpenVINO Infer Demo on AIxBoard', frame)
yolov8_od_ov_sync_infer_demo.py运行结果,如下图所示: 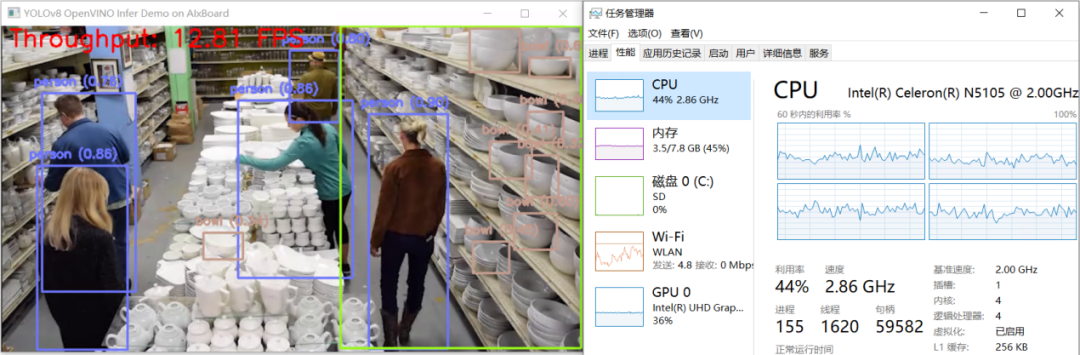 结 论 AI爱克斯开发板借助N5105处理器的集成显卡(24个执行单元)和OpenVINO,可以在YOLOv8的目标检测模型上获得相当不错的性能。通过异步处理和AsyncInferQueue,还能进一步提升计算设备的利用率,提高AI推理程序的吞吐量。
结 论 AI爱克斯开发板借助N5105处理器的集成显卡(24个执行单元)和OpenVINO,可以在YOLOv8的目标检测模型上获得相当不错的性能。通过异步处理和AsyncInferQueue,还能进一步提升计算设备的利用率,提高AI推理程序的吞吐量。
-
实战:在迅为iTOP-RK3576开发板上跑通yolov5目标检测2026-06-15 392
-
使用ROCm™优化并部署YOLOv8模型2025-09-24 1184
-
单板挑战4路YOLOv8!米尔瑞芯微RK3576开发板性能实测2025-09-12 3586
-
labview调用yolov8/11目标检测、分割、分类2025-04-21 7388
-
基于哪吒开发板部署YOLOv8模型2024-11-15 2144
-
基于YOLOv8的自定义医学图像分割2023-12-20 2025
-
【爱芯派 Pro 开发板试用体验】yolov8模型转换2023-11-20 1815
-
三种主流模型部署框架YOLOv8推理演示2023-08-06 4226
-
教你如何用两行代码搞定YOLOv8各种模型推理2023-06-18 5187
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 2248
-
YOLOv8版本升级支持小目标检测与高分辨率图像输入2023-05-16 15493
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2862
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8分类模型2023-05-05 2057
-
使用YOLOv8做目标检测和实例分割的演示2023-02-06 9445
全部0条评论

快来发表一下你的评论吧 !
