

百度飞桨PP-YOLOE ONNX 在LabVIEW中的部署推理(含源码)
描述
前言
PP-YOLOE是百度基于其之前的PP-YOLOv2所改进的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。如何使用python进行该模型的部署,官网已经介绍的很清楚了,但是对于如何在LabVIEW中实现该模型的部署,笔者目前还没有看到相关介绍文章,所以笔者在实现PP-YOLOE ONNX 在LabVIEW中的部署推理后,决定和各位读者分享一下如何使用LabVIEW实现PP-YOLOE的目标检测。
一、什么是PP-YOLO
- PP-YOLOE官方代码地址:https://github.com/PaddlePaddle/PaddleDetection
- PP-YOLOE论文地址:https://arxiv.org/pdf/2203.16250.pdf

PP-YOLOE是百度基于其之前的PP-YOLOv2所改进的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE,有更高的检测精度且部署友好。
PP-YOLOE基于anchor-free的架构,使用强大的backbone和neck,引入了CSPRepResStage,ET-head 和动态标签分配算法TAL。针对不同应用场景,提供了不同大小的模型。即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免了使用诸如Deformable Convolution或者Matrix NMS之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
PP-YOLOE-l在COCO test-dev2017达到了51.6的mAP, 同时其速度在Tesla V100上达到了78.1 FPS。
PP-YOLOE提供了一键转出 ONNX 格式,可顺畅对接 ONNX 生态。本文主要实现百度PP-YOLOE ONNX 在LabVIEW上的部署推理。
二、环境搭建
1、部署本项目时所用环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI视觉工具包:techforce_lib_opencv_cpu-1.0.0.73.vip
- onnx工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.16.vip【1.0.0.16及以上版本】
2、LabVIEW工具包下载及安装
- AI视觉工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/123656523 - onnx工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/124998746
三、模型的获取与转化
注意:本教程已经为大家提供了PP-YOLOE的模型,可跳过本步骤,直接进行步骤四-推理。若是想要了解PP-YOLO的onnx模型如何获取,则可继续阅读本部分内容。
PP-YOLOE并没有直接提供onnx模型,但是我们可以通过paddle2onnx实现onnx模型的导出。
1、安装paddle
- PPYOLO需要使用百度paddle框架,我们打开百度飞桨官网:https://www.paddlepaddle.org.cn/,在下方的快速安装选择适合自己版本的paddlepaddle

- cmd中执行以下命令安装:
python -m pip install paddlepaddle-gpu==2.3.1.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
2、安装依赖的库
- 从github上下载PaddleDetection并解压到目录,下载地址:https://github.com/PaddlePaddle/PaddleDetection ,将paddledetection根目录添加到环境变量。
- 在PaddleDetection-release-2.4文件夹中打开cmd,输入以下指令安装需要的库
pip3 install -U pip && pip3 install -r requirements.txt
3、安装pycocotools
pip install pycocotools
若安装pycocotools时遇到ERROR: Could not build wheels for pycocotools ……,则可以使用以下指令来安装:
pip install pycocotools-windows
4、导出onnx模型
(1)导出推理模型
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --output_dir=output_inference -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
(2) 安装paddle2onnx
pip install paddle2onnx
(3) 转换成onnx格式
paddle2onnx --model_dir output_inference/ppyoloe_crn_l_300e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_crn_l_300e_coco.onnx
至此已成功导出PP-YOLOE ONNX模型
注意: ONNX模型目前只支持batch_size=1
四、在LabVIEW实现PP-YOLOE的部署推理
本项目整体的文件结构如下图所示,各位读者可在文章末尾链接处下载整个项目源码。如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们:705637299
1、LabVIEW调用PP-YOLOE实现目标检测pp-yolox_main.vi
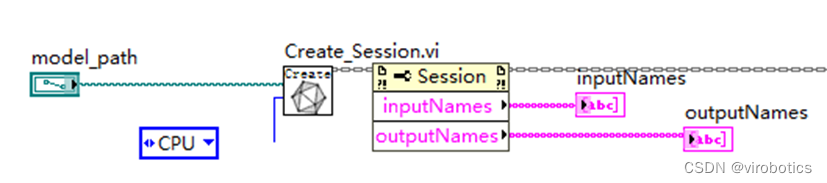
本例中使用LabvVIEW ONNX工具包中的Create_Session.vi载入onnx模型,可选择使用cpu,cuda进行推理加速。
(1)查看模型
我们可以使用netron 查看ppyoloe_crn_s_300e_coco.onnx的网络结构,浏览器中输入链接:https://netron.app/,点击Open Model,打开相应的网络模型文件即可。
查看模型属性,可看到模型的输入输出如下图所示:
我们发现,该模型有两个输入和两个输出,所以推理时候需要有两个输入,需要用到我们的多输入处理vi,run.vi
- 可以看到图片输入大小为640x640
- 第一个输出为8400x6[6分别为classese_id,cofidence,框]
(2)实现过程
- 读取图片并进行图像预处理(-1到1的归一化)
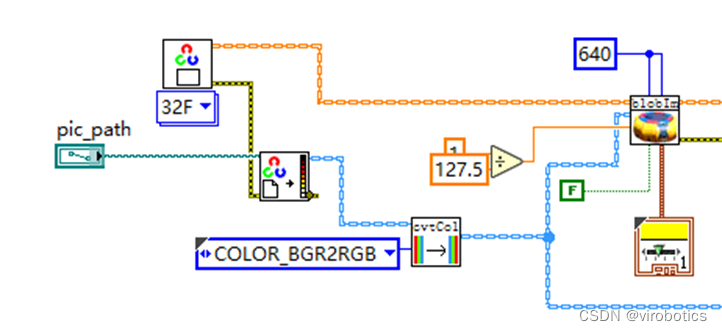
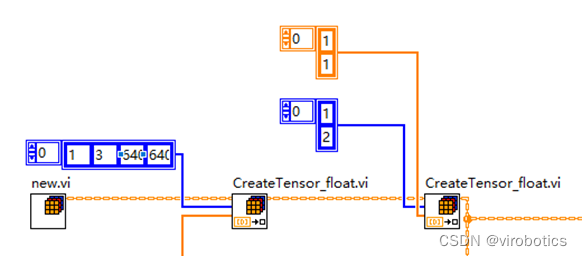
- 初始化一个Vector_Value,新增两个输入tensor(图片及scal_factor)
- 加载模型并选择加速类型(cpu、CUDA、tensorRt)
- 实现多输入推理
- 获取第一层的输出
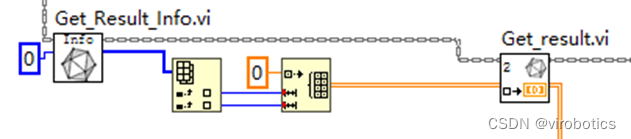
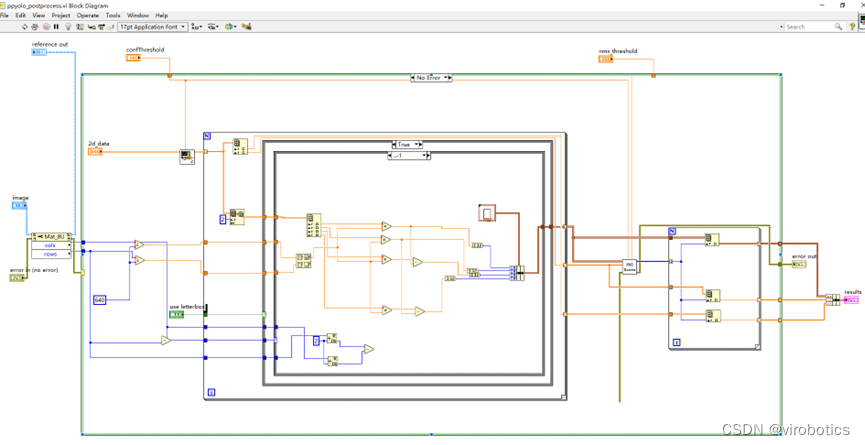
- 进行后处理
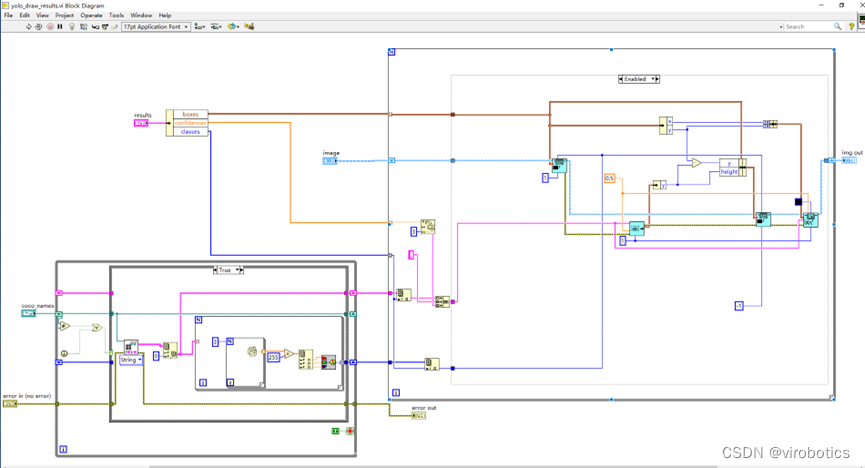
- 绘制检测出的目标及及置信度







(3)项目运行
配置本项目所需环境。在文章末尾链接处下载整个项目源码,将我们已经转化好的onnx模型放置到model文件夹中,打开pp_yolo_main.vi,在前面板中修改程序中加载的模型路径为实际模型路径,本项目中已经将PP-YOLOE onnx模型【ppyoloe_crn_s_300e_coco.onnx】放置到了model文件夹中,如需其他模型,读者也可自行放置到model文件及下,实现模型的加载。修改检测图片的路径为实际图片路径,运行程序,可得到目标检测的结果。
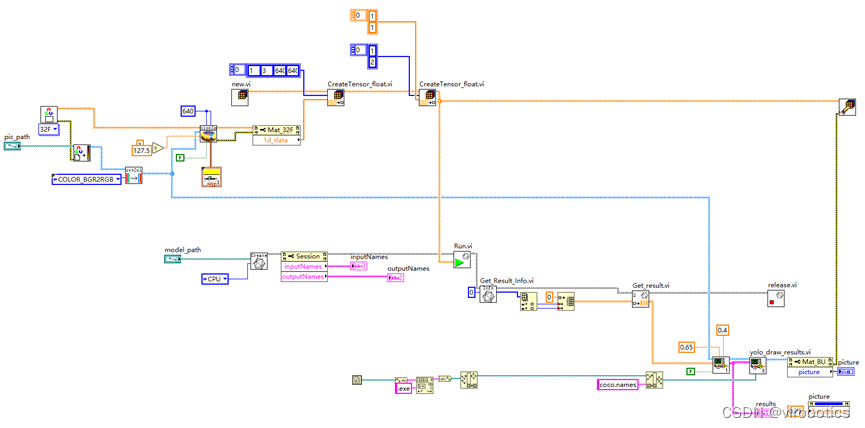
- 主程序源码如下:
- 运行结果如下:
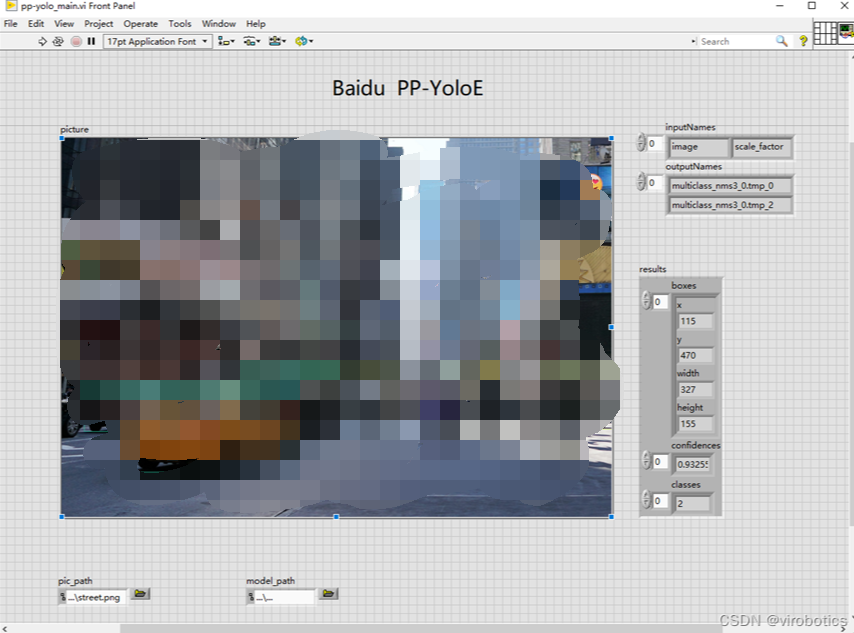
大家也可以检测其他图片来测试检测效果。


2、LabVIEW调用PP-YOLOE实现实时目标检测ppyolo_camera.vi
实时检测过程,我们可以选择使用CUDA实现推理加速,整个程序的实现过程和加载图片进行检测基本一致。
(1)LabVIEW调用PP-YOLOE实时目标检测源码

(2)LabVIEW调用PP-YOLOE实现实时目标检测结果

可以看到使用CUDA进行推理加速,速度还是很快的。
五、完整项目下载链接
链接:https://blog.csdn.net/virobotics/article/details/126231434?spm=1001.2014.3001.5501
总结
以上就是今天要给大家分享的内容,希望对大家有用。如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦。
**如果文章对你有帮助,欢迎✌关注、
审核编辑 黄宇
-
瀚博半导体宣布深度参与百度飞桨黑客松生态活动2026-04-11 862
-
一键搞定!PP-OCRv5模型转ONNX格式全攻略,解锁多平台无缝部署2025-09-05 3183
-
百度飞桨框架3.0正式版发布2025-04-02 1348
-
【米尔RK3576开发板评测】+项目名称百度飞桨PP-YOLOE2025-02-15 1780
-
YOLOv6在LabVIEW中的推理部署(含源码)2024-11-06 1743
-
图为科技联合百度飞桨、英伟达共同推出AI软硬一体快速部署方案2022-12-20 1998
-
【报名有奖】Imagination+百度飞桨模型部署实战 Workshop 邀您参加2022-09-28 1528
-
Imagination+百度飞桨模型部署实战 Workshop 邀您参加2022-09-23 1583
-
NVIDIA携手百度飞桨 共创多元AI开发生态2022-05-27 3171
-
Graphcore携手百度飞桨 共建全球软硬AI生态2022-05-23 2366
-
百度飞桨在Graphcore IPU上实现训练与推理全面支持2021-12-13 836
-
不是“重复”造轮子,百度飞桨框架2.0如何俘获人心 精选资料分享2021-07-23 2282
-
芯微AI芯片加持百度飞桨,携手加速AI应用落地2020-07-06 1214
全部0条评论

快来发表一下你的评论吧 !
