

 YOLOv6在LabVIEW中的推理部署(含源码)
YOLOv6在LabVIEW中的推理部署(含源码)
电子说
描述
前言
前面我们给大家介绍了使用OpenCV以及ONNX工具包实现yolov5在LabVIEW中的部署,有英伟达显卡的朋友们可能已经感受过使用cuda加速时yolov5的速度,今天主要和大家分享在LabVIEW中使用纯TensoRT工具包快速部署并实现yolov5的物体识别, 本博客中使用的智能工具包可到主页置顶博客[https://blog.csdn.net/virobotics/article/details/129304465]
中安装 。若配置运行过程中遇到困难,欢迎大家评论区留言,博主将尽力解决。
以下是YOLOv5的相关笔记总结,希望对大家有所帮助。
| 【YOLOv5】LabVIEW+OpenVINO让你的YOLOv5在CPU上飞起来 | https://blog.csdn.net/virobotics/article/details/124951862 |
|---|---|
| 【YOLOv5】LabVIEW OpenCV dnn快速实现实时物体识别(Object Detection) | https://blog.csdn.net/virobotics/article/details/124929483 |
| 【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码) | https://blog.csdn.net/virobotics/article/details/124981658 |
一、关于YOLOv5
YOLOv5是在 COCO 数据集上预训练的一系列对象检测架构和模型。表现要优于谷歌开源的目标检测框架 EfficientDet,在检测精度和速度上相比yolov4都有较大的提高。本博客,我们以YOLOv5 6.1版本来介绍相关的部署开发。
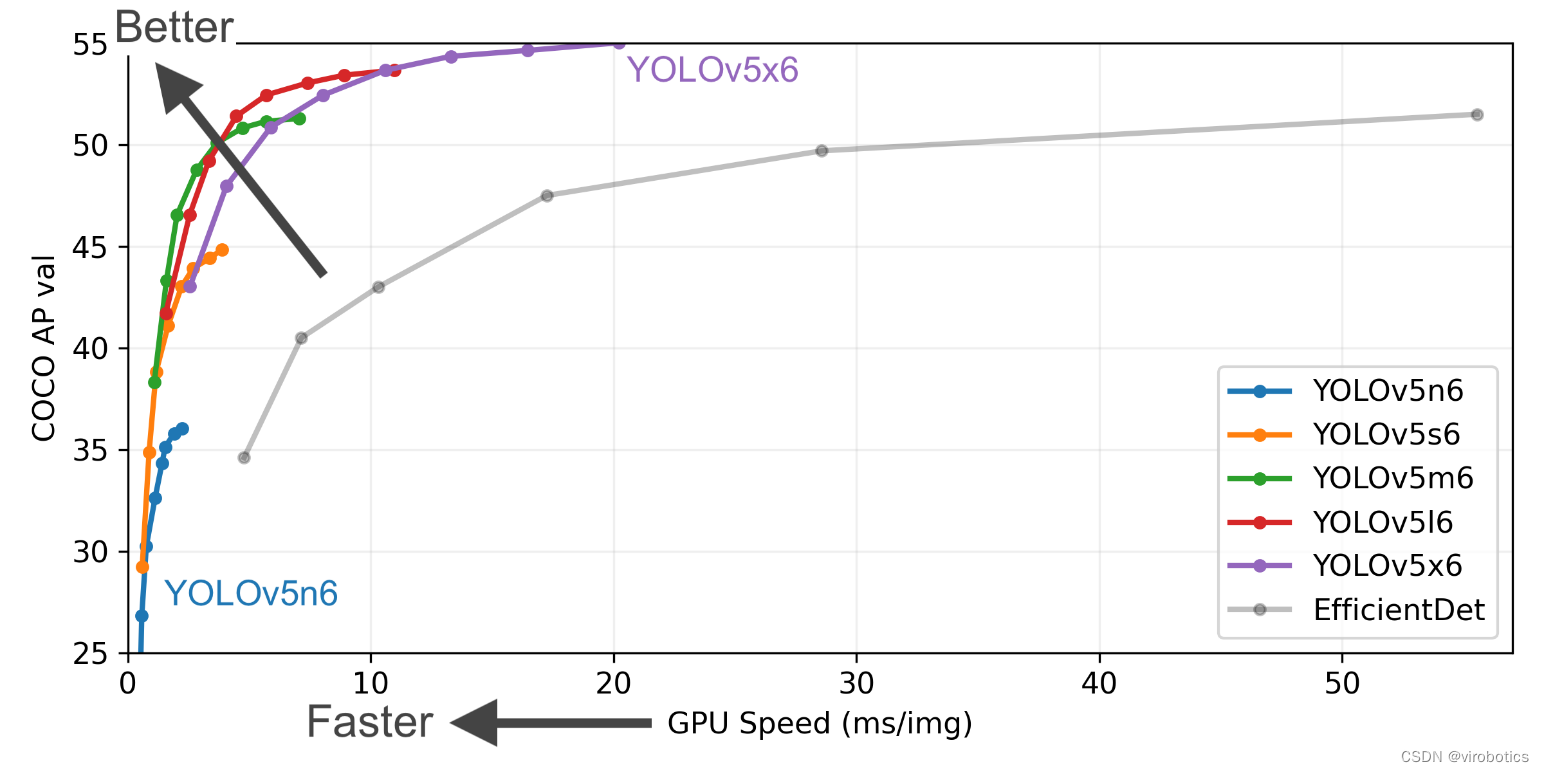
YOLOv5相比于前面yolo模型的主要特点是:
1、小目标的检测精度上有明显的提高;
2、能自适应锚框计算
3、具有数据增强功能,随机缩放,裁剪,拼接等功能
4、灵活性极高、速度超快,模型超小、在模型的快速部署上具有极强优势
关于YOLOv5的网络结构解释网上有很多,这里就不再赘述了,大家可以看其他大神对于YOLOv5网络结构的解析。
二、YOLOv5模型的获取
为方便使用, 博主已经将yolov5模型转化为onnx格式 ,可在百度网盘下载
链接:[https://pan.baidu.com/s/15dwoBM4W-5_nlRj4G9EhRg?pwd=yiku]
提取码:yiku
1.下载源码
将Ultralytics开源的YOLOv5代码Clone或下载到本地,可以直接点击Download ZIP进行下载,
下载地址:[https://github.com/ultralytics/yolov5]
2.安装模块
解压刚刚下载的zip文件,然后安装yolov5需要的模块,记住cmd的工作路径要在yolov5文件夹下:
打开cmd切换路径到yolov5文件夹下,并输入如下指令,安装yolov5需要的模块
pip install -r requirements.txt
3.下载预训练模型
打开cmd,进入python环境,使用如下指令下载预训练模型:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
成功下载后如下图所示:
4.转换为onnx模型
将.pt文件转化为.onnx文件,在cmd中输入转onnx的命令(记得将export.py和pt模型放在同一路径下):
python export.py --weights yolov5s.pt --include onnx
如下图所示为转化成功界面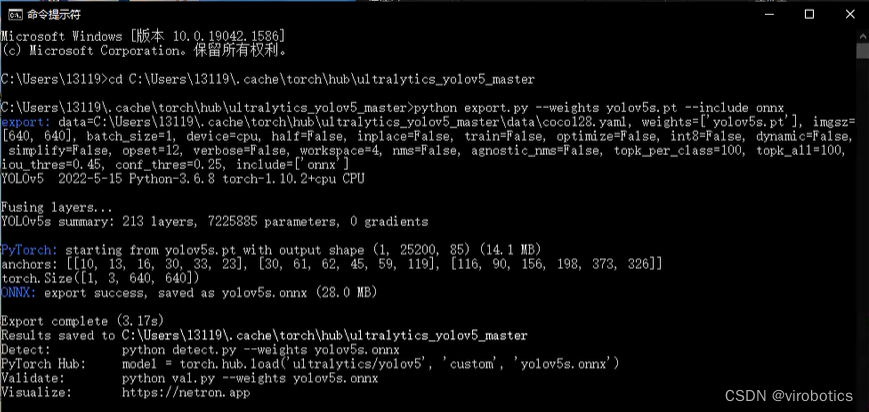
其中yolov5s可替换为yolov5myolov5myolov5lyolov5x
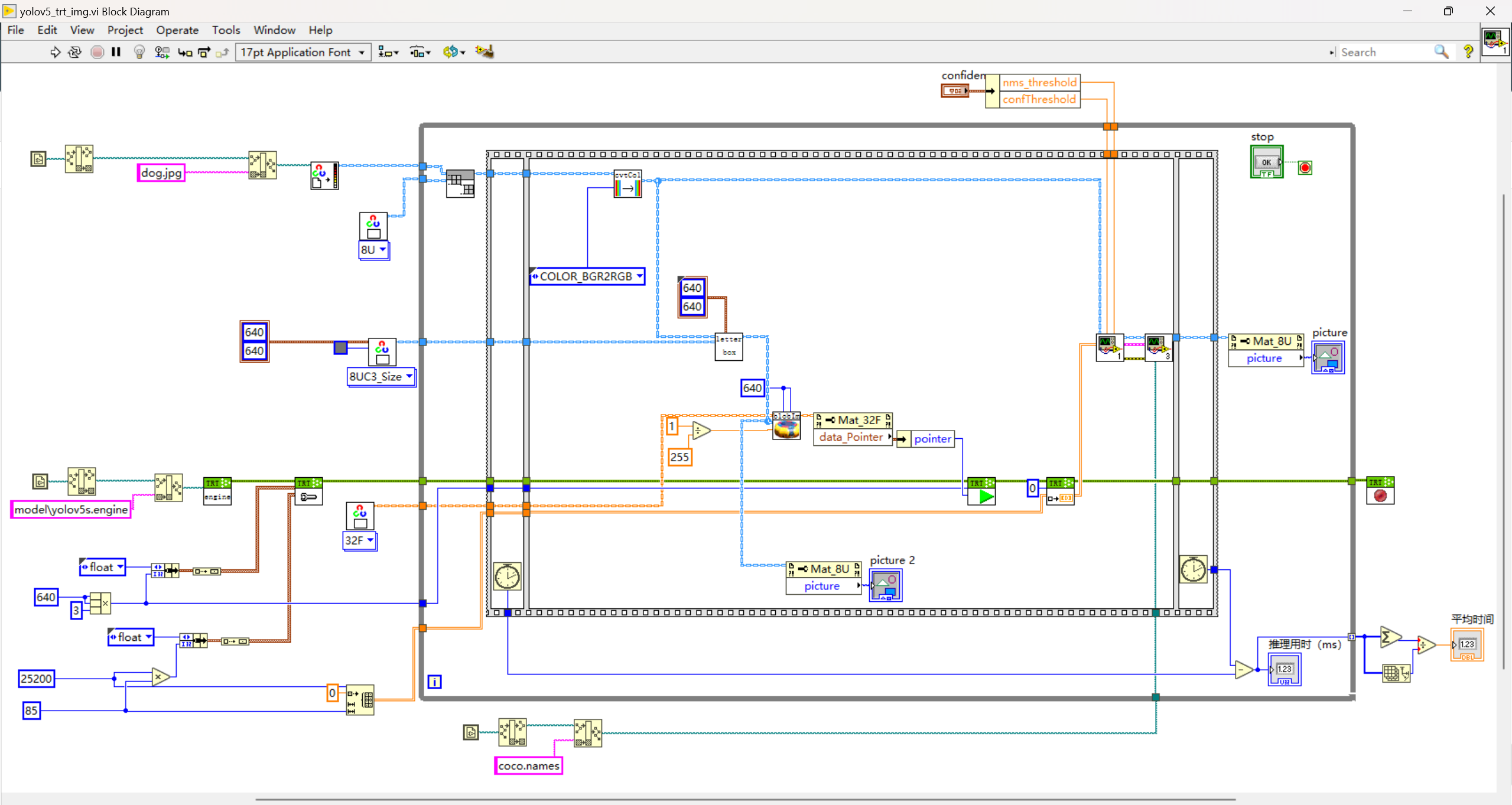
三、LabVIEW+TensorRT的yolov5部署实战(yolov5_trt_img.vi)
如需要查看TensorRT工具包相关vi含义,可查看:[https://blog.csdn.net/virobotics/article/details/129492651]
1.onnx转化为engine(onnx to engine.vi)
使用onnx_to_engine.vi,将该vi拖拽至前面板空白区域,创建并输入onnx的路径以及engine的路径,type即精度,可选择FP32或FP16,肉眼观看精度无大差别。(一般FP16模型比FP32速度快一倍)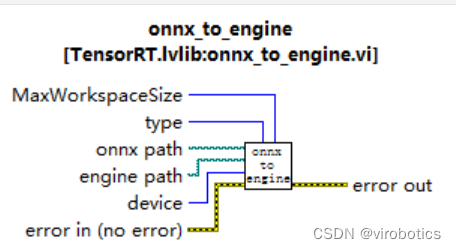
转换的完整程序如下: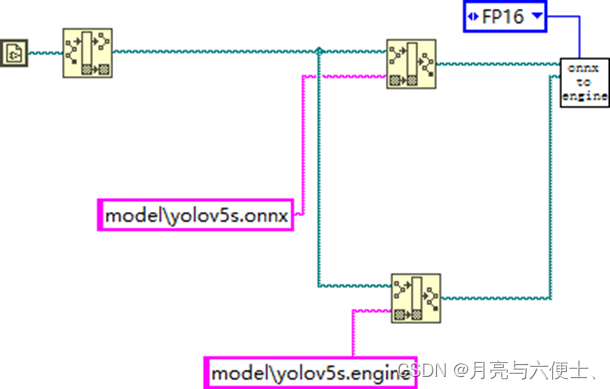
点击运行,等待1~3分钟,模型转换成功,可在刚刚设定的路径中找到我们转化好的mobilenet.engine.
Q:为什么要转换模型,不直接调用ONNX?> A:tensorRT内部加载ONNX后其实是做了一个转换模型的工作,该过程时间长、占用内存巨大。因此不推荐每次初始化都加载ONNX模型,而是加载engine。
2.部署
模型初始化
- 加载yolov5s.engine文件
- 设置输入输出缓存
• 输入大小为13640640
• 输出大小为125200*85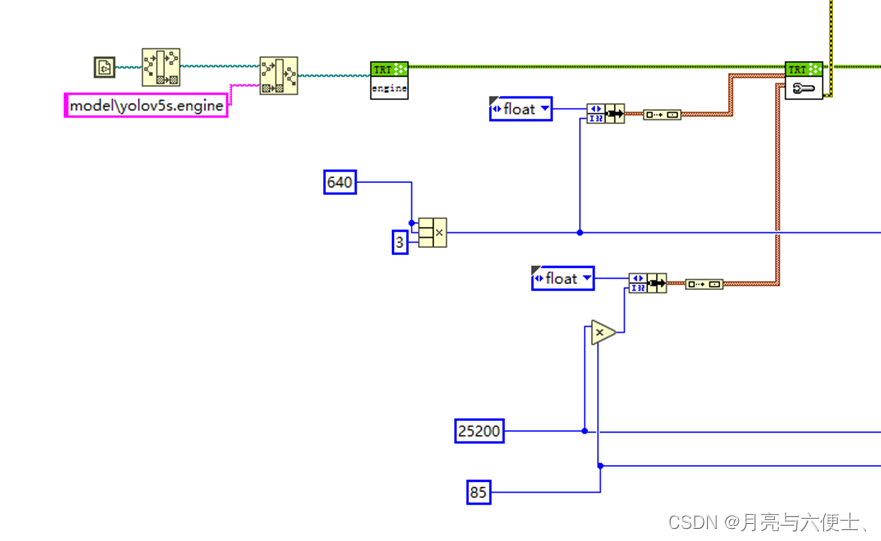

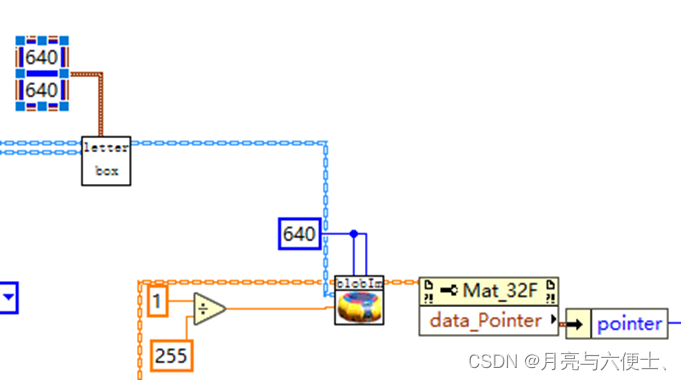
yolov5的预处理
- LetterBox
- blobFromImage,包含如下步骤:
1) img=img/255.0
2) img = img[None] #从(640,640,3)扩充维度至(1,640,640,3)
3) input=img.transpose(0,3,1,2) # BHWC to BCHW

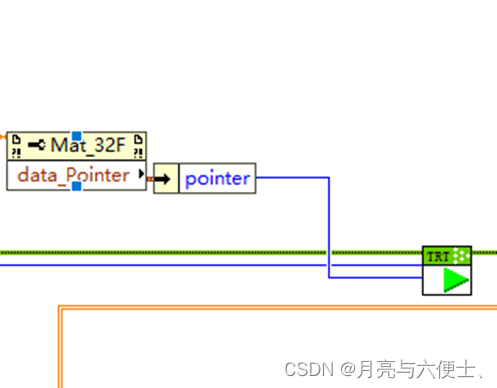
模型推理
- 推荐使用数据指针作为输入给到run.vi
- 数据的大小为13640*640

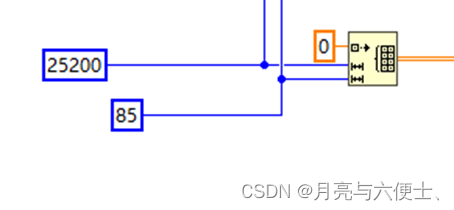
获取推理结果
- 循环外初始化一个25200*85的二维数组
- 此数组作为Get_Result的输入,另一个输入为index=0
- 输出为25200*85的二维数组结果
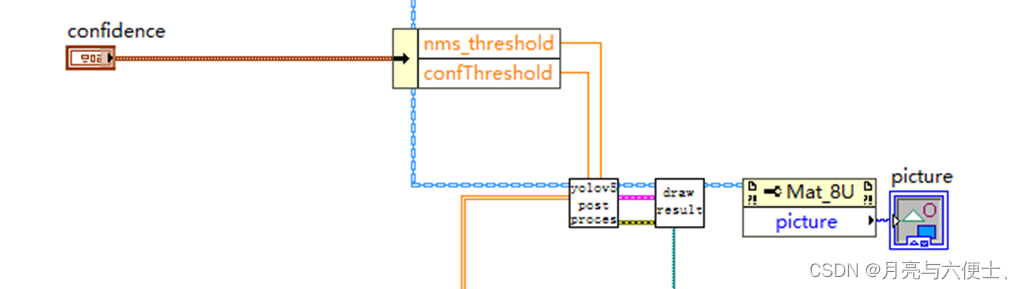
后处理
本范例中,后处理方式和使用onnx一样
完整源码
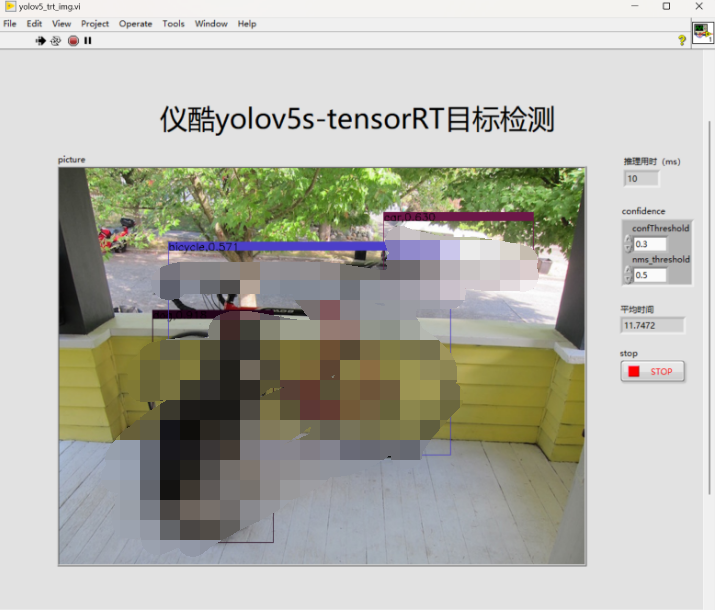
运行结果
项目源码
源码下载链接:https://pan.baidu.com/s/1y0scJ8tg5nzjJK4iPvNwNQ?pwd=yiku
附加说明
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- 视觉工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
- LabVIEW TensorRT工具包:virobotics_lib_tensorrt-1.0.0.22.vip
- 运行结果所用显卡:RTX3060
审核编辑 黄宇
-
基于OpenCV DNN实现YOLOv8的模型部署与推理演示2024-03-01 3672
-
YOLOV7网络架构解读2023-11-29 3311
-
如何修改YOLOv8的源码2023-09-04 4132
-
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)2023-08-21 2396
-
三种主流模型部署框架YOLOv8推理演示2023-08-06 4211
-
YOLOv6模型文件的输入与输出结构2023-06-25 2244
-
使用LabVIEW实现 DeepLabv3+ 语义分割含源码2023-05-26 2137
-
LabVIEW+OpenVINO在CPU上部署新冠肺炎检测模型实战(含源码)2023-03-23 2772
-
【YOLOv5】LabVIEW+YOLOv5快速实现实时物体识别(Object Detection)含源码2023-03-13 3585
-
YOLOv6中的用Channel-wise Distillation进行的量化感知训练2022-10-09 4740
-
YOLOv5s算法在RK3399ProD上的部署推理流程是怎样的2022-02-11 3629
-
基于Tengine实现yolov4的cpu推理2022-01-26 878
-
Tengine 支持 NPU 模型部署-YOLOv5s2022-01-25 812
-
基于Tengine实现yolov4的cpu推理讲解2020-12-15 1565
全部0条评论

快来发表一下你的评论吧 !
