

分库分表的21条法则速来码住(上)
电子说
描述
(一)好好的系统,为什么要分库分表?
还是不着急实战,咱们先介绍下在分库分表架构实施过程中,会接触到的一些通用概念,了解这些概念能够帮助理解市面上其他的分库分表工具,尽管它们的实现方法可能存在差异,但整体思路基本一致。因此,在开始实际操作之前,我们有必要先掌握这些通用概念,以便更好地理解和应用分库分表技术。
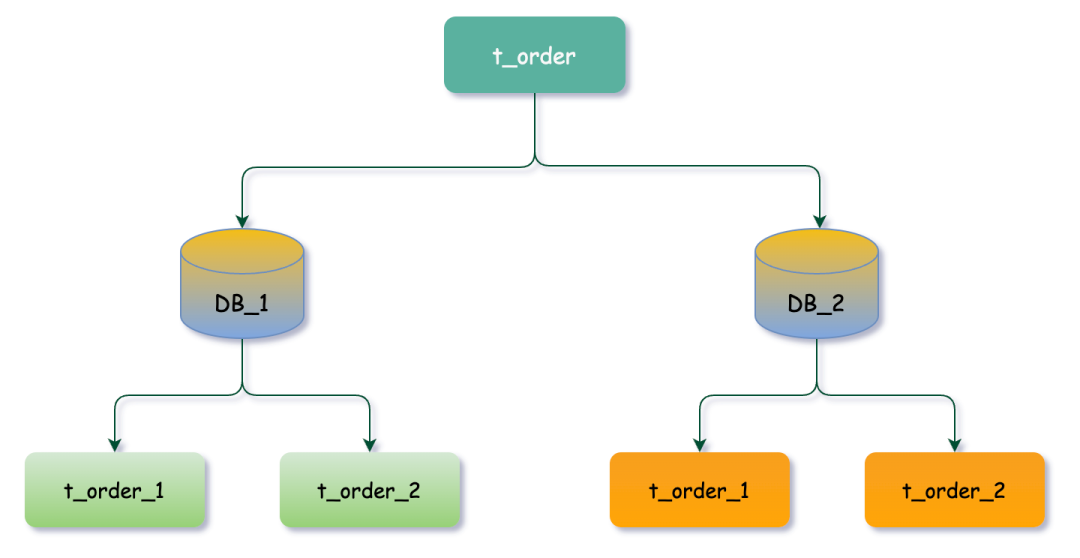
我们结合具体业务场景,以t_order表为例进行架构优化。由于数据量已经达到亿级别,查询性能严重下降,因此我们采用了分库分表技术来处理这个问题。具体而言,我们将原本的单库分成了两个库,分别为DB_1和DB_2,并在每个库中再次进行分表处理,生成t_order_1和t_order_2两张表,实现对订单表的分库分表处理。
数据分片
通常我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片它将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表(拆分表) t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据。

数据节点
数据节点是数据分片中一个不可再分的最小单元(表),它由数据源名称和数据表组成,例如上图中 DB_1.t_order_1、DB_2.t_order_2 就表示一个数据节点。

逻辑表
逻辑表是指具有相同结构的水平拆分表的逻辑名称。
比如我们将订单表t_order 分表拆分成 t_order_0 ··· t_order_9等10张表,这时我们的数据库中已经不存在 t_order这张表,取而代之的是若干的t_order_n表。
分库分表通常对业务代码都是无侵入式的,开发者只专注于业务逻辑SQL编码,我们在代码中SQL依然按 t_order来写,而在执行逻辑SQL前将其解析成对应的数据库真实执行的SQL。此时 t_order 就是这些拆分表的逻辑表。
业务逻辑SQL
select * from t_order where order_no='A11111'
真实执行SQL
select * from DB_1.t_order_n where order_no='A11111'
真实表
真实表就是在数据库中真实存在的物理表DB_1.t_order_n。
广播表
广播表是一类特殊的表,其表结构和数据在所有分片数据源中均完全一致。与拆分表相比,广播表的数据量较小、更新频率较低,通常用于字典表或配置表等场景。由于其在所有节点上都有副本,因此可以大大降低JOIN关联查询的网络开销,提高查询效率。
需要注意的是,对于广播表的修改操作需要保证同步性,以确保所有节点上的数据保持一致。
广播表的特点 :
- 在所有分片数据源中,广播表的数据完全一致。因此,对广播表的操作(如插入、更新和删除)会实时在每个分片数据源中执行一遍,以保证数据的一致性。
- 对于广播表的查询操作,仅需要在任意一个分片数据源中执行一次即可。
- 与任何其他表进行JOIN操作都是可行的,因为由于广播表的数据在所有节点上均一致,所以可以访问到任何一个节点上的相同数据。
什么样的表可以作为广播表呢?
订单管理系统中,往往需要查询统计某个城市地区的订单数据,这就会涉及到省份地区表t_city与订单流水表DB_n.t_order_n进行JOIN查询,因此可以考虑将省份地区表设计为广播表,核心理念就是 避免跨库JOIN操作 。
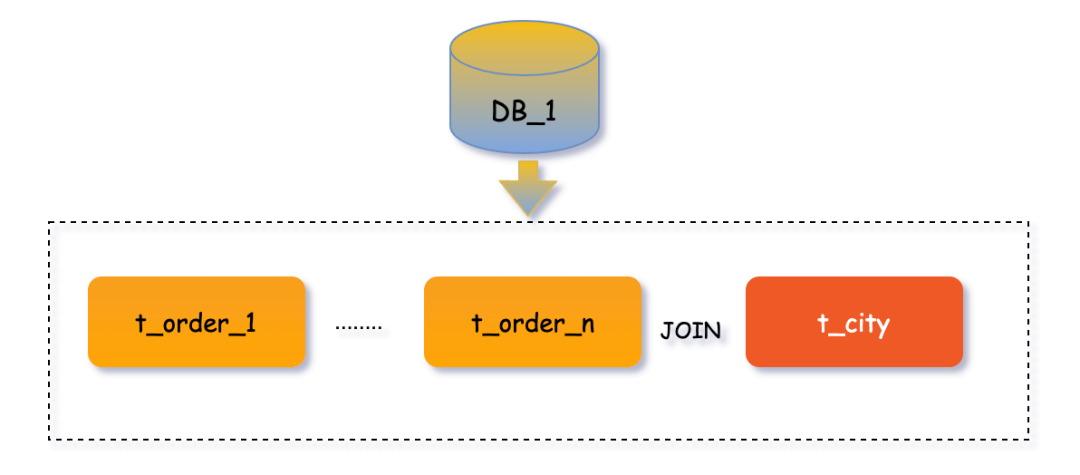
注意 :上边我们提到广播表在数据插入、更新与删除会实时在每个分片数据源均执行,也就是说如果你有1000个分片数据源,那么修改一次广播表就要执行1000次SQL,所以尽量不在并发环境下和业务高峰时进行,以免影响系统的性能。
单表
单表指所有的分片数据源中仅唯一存在的表(没有分片的表),适用于数据量不大且无需分片的表。
如果一张表的数据量预估在千万级别,且没有与其他拆分表进行关联查询的需求,建议将其设置为单表类型,存储在默认分片数据源中。
分片键
分片键决定了数据落地的位置,也就是数据将会被分配到哪个数据节点上存储。因此,分片键的选择非常重要。
比如我们将 t_order 表进行分片后,当插入一条订单数据执行SQL时,需要通过解析SQL语句中指定的分片键来计算数据应该落在哪个分片中。以表中order_no字段为例,我们可以通过对其取模运算(比如 order_no % 2)来得到分片编号,然后根据分片编号分配数据到对应的数据库实例(比如 DB_1 和 DB_2)。拆分表也是同理计算。
在这个过程中,order_no 就是 t_order 表的分片键。也就是说,每一条订单数据的 order_no 值决定了它应该存放的数据库实例和表。选择一个适合作为分片键的字段可以更好地利用水平分片带来的性能提升。
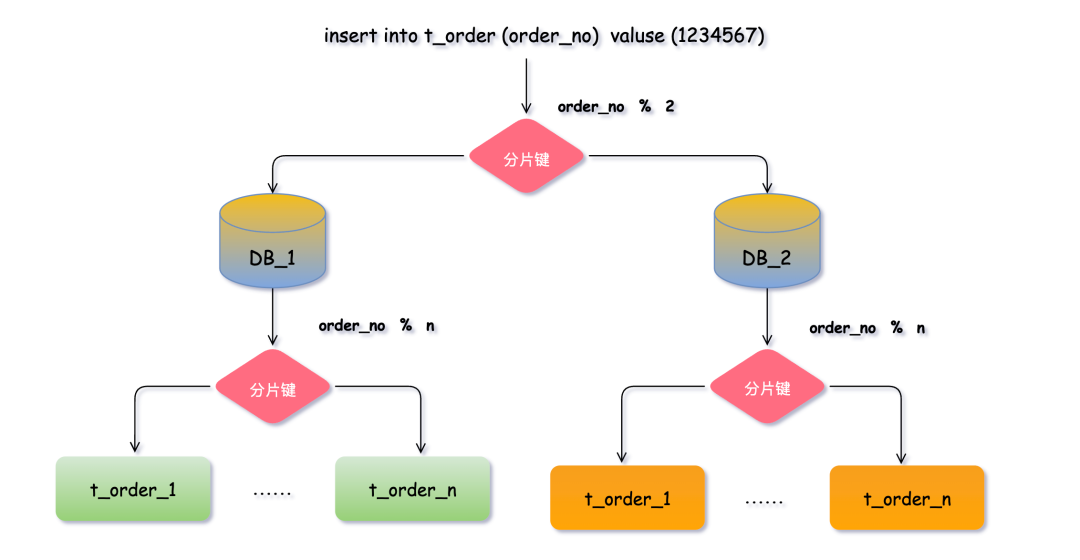
这样同一个订单的相关数据就会落在同一个数据库、表中,查询订单时同理计算,就可直接定位数据位置,大幅提升数据检索的性能,避免了全库表扫描。
不仅如此 ShardingSphere 还支持根据多个字段作为分片健进行分片,这个在后续对应章节中会详细讲。
分片策略
分片策略来指定使用哪种分片算法、选择哪个字段作为分片键以及如何将数据分配到不同的节点上。
分片策略是由分片算法和分片健组合而成,分片策略中可以使用多种分片算法和对多个分片键进行运算。
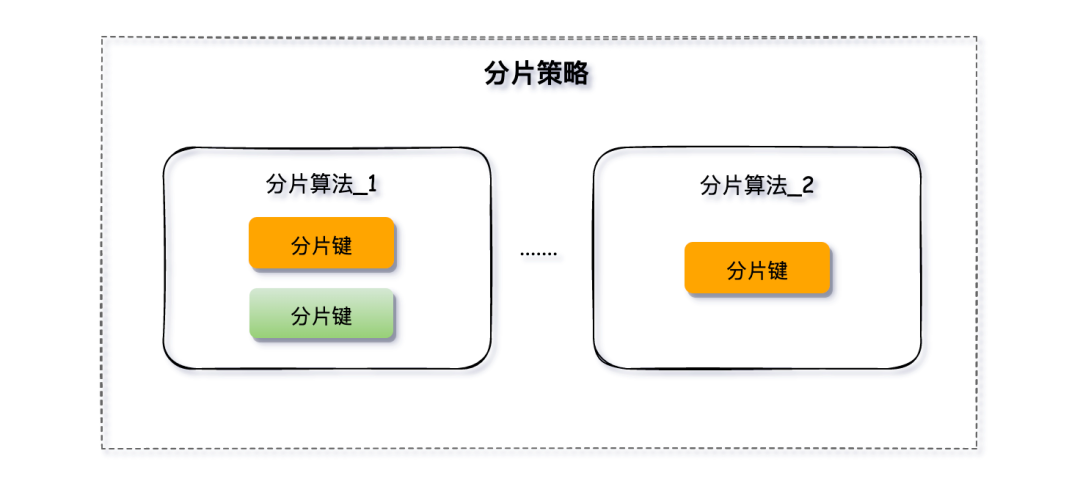
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。
分片算法
分片算法则是用于对分片键进行运算,将数据划分到具体的数据节点中。
常用的分片算法有很多:
- 哈希分片 :根据分片键的哈希值来决定数据应该落到哪个节点上。例如,根据用户 ID 进行哈希分片,将属于同一个用户的数据分配到同一个节点上,便于后续的查询操作。
- 范围分片 :分片键值按区间范围分配到不同的节点上。例如,根据订单创建时间或者地理位置来进行分片。
- 取模分片 :将分片键值对分片数取模,将结果作为数据应该分配到的节点编号。例如, order_no % 2 将订单数据分到两个节点之一。
- .....
实际业务开发中分片的逻辑要复杂的多,不同的算法适用于不同的场景和需求,需要根据实际情况进行选择和调整。
绑定表
绑定表是那些具有相同分片规则的一组分片表,由于分片规则一致所产生的的数据落地位置相同,在JOIN联合查询时能有效避免跨库操作。
比如:t_order 订单表和 t_order_item 订单项目表,都以 order_no 字段作为分片键,并且使用 order_no 进行关联,因此两张表互为绑定表关系。
使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
当使用 t_order 和 t_order_item 表进行多表联合查询,执行如下联合查询的逻辑SQL。
SELECT * FROM t_order o JOIN t_order_item i ON o.order_no=i.order_no
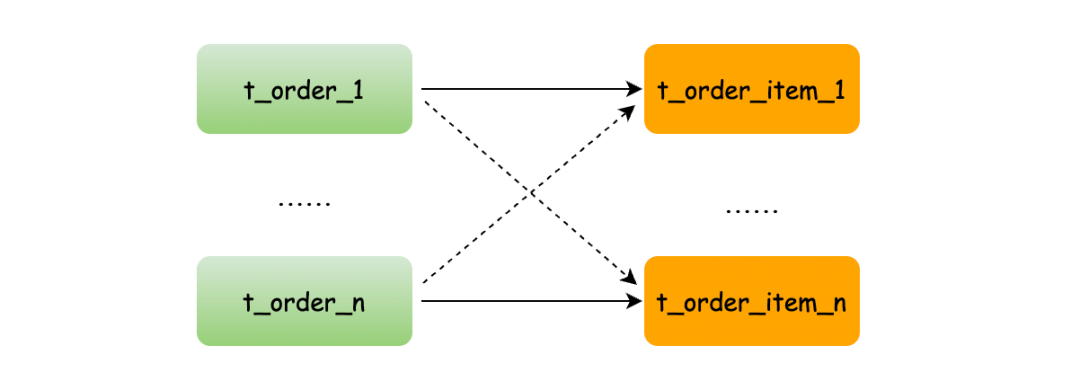
如果不配置绑定表关系,两个表的数据位置不确定就会全库表查询,出现笛卡尔积关联查询,将产生如下四条SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_no=i.order_no
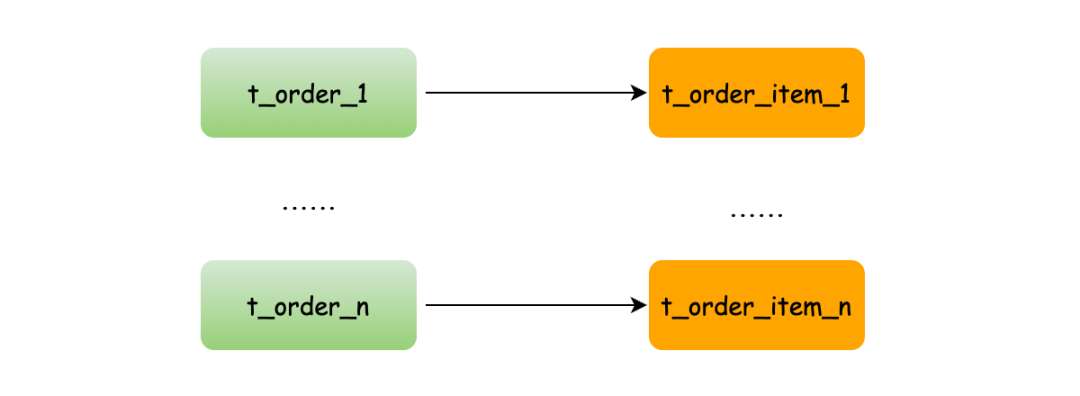
而配置绑定表关系后再进行关联查询时,分片规则一致产生的数据就会落到同一个库表中,那么只需在当前库中 t_order_n 和 t_order_item_n 表关联即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
注意 :在关联查询时
t_order它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item表的分片相关的计算也会使用t_order的条件,所以要保证绑定表之间的分片键要完全相同。
-
数据库分区、分库和分表2023-09-30 4488
-
新版架构师系列-ShardingJDBC分库分表mysql数据库实战2026-05-18 63
-
谈分布式数据库中间件之分库分表2018-08-02 2405
-
分库分表是什么?怎么实现?2019-10-25 1797
-
买大硬盘的6条法则2009-12-17 1342
-
利用Mycat实现MySQL读写分离、分库分表最佳实践2017-09-08 1288
-
数据库分库分表基础和实践2018-09-05 570
-
你们知道为什么要分库分表吗2021-08-16 2174
-
优化MySQL数据库中朴实无华的分表和花里胡哨的分库2021-08-26 1844
-
你是否知道分库分表需要哪些要素?2022-10-12 1620
-
什么是分库分表?为什么分库分表?什么情况下会用分库分表呢?2022-11-30 8763
-
分库分表的21条法则速来码住(下)2023-05-26 1173
-
分库分表后复杂查询的应对之道:基于DTS实时性ES宽表构建技术实践2024-06-25 1906
-
软件系统数据库的分库分表设计2024-08-22 1382
-
或许我们都被分库分表约束了思维2025-02-21 718
全部0条评论

快来发表一下你的评论吧 !
