

使用AWS Graviton降低Amazon SageMaker推理成本
电子说
描述
作者:Sunita Nadampalli
Amazon SageMaker(https://aws.amazon.com/sagemaker/)提供了多种机器学习(ML)基础设施和模型部署选项,以帮助满足您的ML推理需求。它是一个完全托管的服务,并与MLOps工具集成,因此您可以努力扩展模型部署,降低推理成本,在生产中更有效地管理模型,并减轻操作负担。SageMaker提供多个推理选项(https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html#deploy-model-options),因此您可以选择最适合您工作负载的选项。
新一代CPU由于内置的专用指令在ML推理方面提供了显着的性能提升。在本文中,我们重点介绍如何利用基于AWS Graviton3(https://aws.amazon.com/ec2/graviton/)的Amazon Elastic Compute Cloud(EC2)C7g实例(https://aws.amazon.com/blogs/aws/new-amazon-ec2-c7g-instances-powered-by-aws-graviton3-processors/),以帮助在Amazon SageMaker上进行实时推理(https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html)时将推理成本降低高达50%,相对于可比较的EC2实例。我们展示了如何评估推理性能并在几个步骤中将您的ML工作负载切换到AWS Graviton实例。
为了涵盖广泛的客户应用程序,本文讨论了PyTorch、TensorFlow、XGBoost和scikit-learn框架的推理性能。我们涵盖了计算机视觉(CV)、自然语言处理(NLP)、分类和排名场景,以及用于基准测试的ml.c6g、ml.c7g、ml.c5和ml.c6i SageMaker实例。
基准测试结果
AWS Graviton3基于EC2 C7g实例相对于Amazon SageMaker上的可比EC2实例,可以为PyTorch、TensorFlow、XGBoost和scikit-learn模型推理带来高达50%的成本节省,同时推理的延迟也得到了降低 。
为了进行比较,我们使用了四种不同的实例类型:
• c7g.4xlarge (https://aws.amazon.com/ec2/instance-types/c7g/)
• c6g.4xlarge (https://aws.amazon.com/ec2/instance-types/c6g/)
• c6i.4xlarge (https://aws.amazon.com/ec2/instance-types/c6i/)
• c5.4xlarge(https://aws.amazon.com/ec2/instance-types/c5/)
这四个实例都有16个vCPU和32 GiB内存。
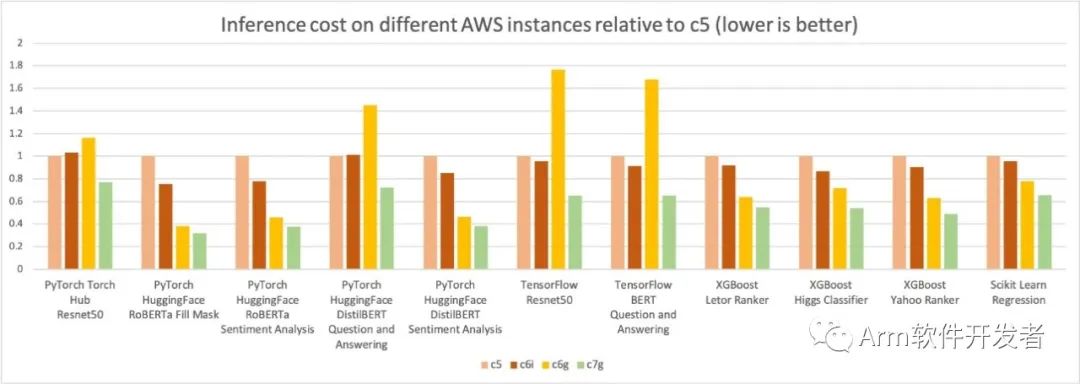
在下面的图表中,我们测量了四种实例类型每百万推理的成本。我们进一步将每百万推理成本结果归一化为c5.4xlarge实例,该实例在图表的Y轴上测量为1。您可以看到,对于XGBoost模型,c7g.4xlarge(AWS Graviton3)的每百万推理成本约为c5.4xlarge的50%,约为c6i.4xlarge的40%;对于PyTorch NLP模型,与c5和c6i.4xlarge实例相比,成本节省约30-50%。对于其他模型和框架,与c5和c6i.4xlarge实例相比,我们测得至少30%的成本节省。
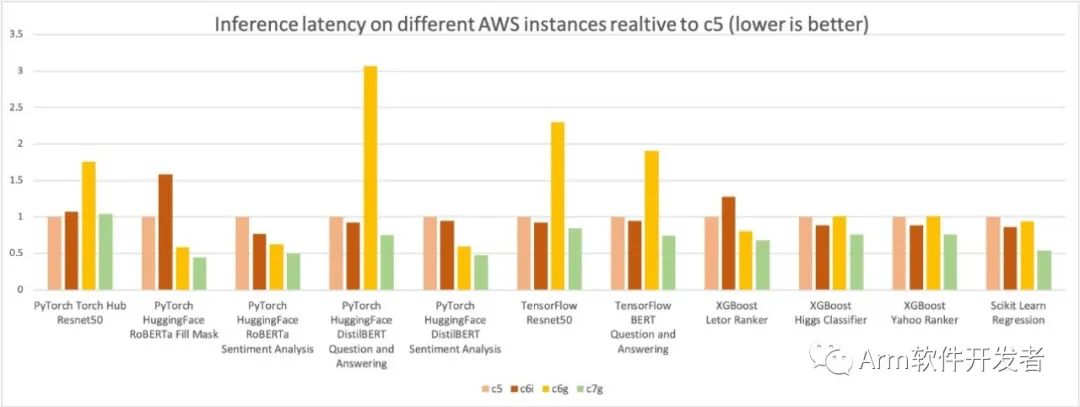
与前面的推理成本比较图类似,下图显示了相同四种实例类型的模型p90延迟。我们进一步将延迟结果标准化为c5.4xlarge实例,在图表的Y轴中测量为1。c7g.4xlarge(AWS Graviton3)模型推理延迟比在c5.4xlage和c6i.4xla格上测量的延迟高出50%。
迁移到AWS Graviton实例
要将模型部署到AWS Graviton实例,可以使用AWS深度学习容器(DLC)(https://github.com/aws/deep-learning-containers/blob/master/available_images.md#sagemaker-framework-graviton-containers-sm-support-only),也可以自带与ARMv8.2体系结构兼容的容器(https://github.com/aws/deep-learning-containers#building-your-image)。
将模型迁移(或新部署)到AWS Graviton实例很简单,因为AWS不仅为使用PyTorch、TensorFlow、scikit-learn和XGBoost托管模型提供容器,而且模型在架构上也是不可知的。您也可以带上自己的库,但请确保您的容器是用支持ARMv8.2体系结构的环境构建的。有关更多信息,请参阅构建自己的算法容器(https://sagemaker-examples.readthedocs.io/en/latest/advanced_functionality/scikit_bring_your_own/scikit_bring_your_own.html)。
您需要完成三个步骤才能部署模型:
1.创建SageMaker模型。除其他参数外,它将包含有关模型文件位置、将用于部署的容器以及推理脚本的位置的信息。(如果已经在计算优化推理实例中部署了现有模型,则可以跳过此步骤。)
2.创建端点配置。这将包含有关端点所需的实例类型的信息(例如,对于AWS Graviton3,为ml.c7g.xlarge)、在上一步中创建的模型的名称以及每个端点的实例数。
3.使用在上一步中创建的端点配置启动端点。
有关详细说明,请参阅使用Amazon SageMaker在基于AWS Graviton的实例上运行机器学习推理工作负载(https://aws.amazon.com/blogs/machine-learning/run-machine-learning-inference-workloads-on-aws-graviton-based-instances-with-amazon-sagemaker/)。
性能基准管理方法
我们使用Amazon SageMaker Inference Recommender(https://docs.aws.amazon.com/sagemaker/latest/dg/inference-recommender.html)来自动化不同实例的性能基准测试。该服务根据不同实例的延迟和成本来比较ML模型的性能,并推荐以最低成本提供最佳性能的实例和配置。我们使用推理推荐器收集了上述性能数据。有关更多详细信息,请参阅GitHub回购。
您可以使用示例笔记本(https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-inference-recommender/huggingface-inference-recommender/huggingface-inference-recommender.ipynb)来运行基准测试并再现结果。我们使用以下模型进行基准测试:
1.PyTorch– ResNet50图像分类,DistilBERT情感分析,RoBERTa填充掩码和RoBERTa情感分析。
2.TensorFlow–TF Hub ResNet 50和ML Commons TensorFlow BERT。
3.XGBoost和scikit learn–我们测试了四个模型,以涵盖分类器、排序器和线性回归场景。
结论
相对于Amazon SageMaker上的可比EC2实例,AWS使用基于Graviton3的EC2 C7g实例测量了PyTorch,TensorFlow,XGBoost和scikit-learn模型推理高达50%的成本节省。您可以按照本文提供的步骤将现有推理用例迁移到AWS Graviton或部署新的ML模型。您还可以参考AWS Graviton技术指南(https://github.com/aws/aws-graviton-getting-started),该指南提供了优化库和最佳实践列表,可帮助您在不同工作负载上使用AWS Graviton实例实现成本效益。
如果您发现使用情况,在AWS Graviton上没有观察到类似的性能提升,请与我们联系。我们将继续添加更多性能改进,使AWS Graviton成为最具成本效益和高效的通用ML推理处理器。”
-
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用2022-08-31 3944
-
在AWS云中使用Arm处理器设计Arm处理器2022-09-02 4863
-
使用Arm服务器减少基因组学的时间和成本2022-10-09 4586
-
AWS机器学习服务GPU成本大幅度降低,高达18%2020-10-10 2553
-
AWS发布新一代Amazon Aurora Serverless2020-12-03 2642
-
AWS基于Arm架构的Graviton 2处理器落地中国2021-02-01 3912
-
中科创达成为Amazon SageMaker服务就绪计划首批认证合作伙伴2022-12-06 2320
-
使用AWS Graviton处理器优化的PyTorch 2.0推理2023-05-28 1621
-
Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例2023-11-01 2091
-
亚马逊云科技推出五项Amazon SageMaker新功能2023-12-06 1451
-
亚马逊云科技宣布基于自研Amazon Graviton4的Amazon EC2 R8g实例正式可用2024-07-15 1164
-
亚马逊云科技推出新一代Amazon SageMaker2024-12-10 911
-
Arm与AWS合作深化,AWS Graviton4展现显著进展2024-12-18 1297
-
亚马逊云科技发布新一代Amazon SageMaker2024-12-24 1111
-
力争百万 Tokens 推理成本降低百倍:云天励飞发布未来三年大算力芯片战略,首曝 DeepVerse 路线图2026-02-03 3395
全部0条评论

快来发表一下你的评论吧 !
